
데이터 중심 애플리케이션 설계, 마틴 클레프만 지음. OREILLY.
2부에서는
1부에서는 데이터베이스가 1개일 때만 생각했다. 2부에서는 스케일이 좀 더 커진다. 데이터베이스가 여러개인 경우를 다룬다. 왜 데이터베이스가 여러개 필요한지, 여러 데이터베이스를 어떻게 관리하는지, 그 방법의 장단점은 무엇이 있는지 등을 얘기할 것이다. 말로만 듣던 분산 시스템을 맛볼 수 있는 좋은 기회다. 😇
(학부 과목 중에 '분산 시스템' 과목이 있었는데 교수님이 너무 뛰어나신 분이라 감히 들을 엄두를 못 내고 졸업해버려 아쉬움이 남아 있었다.)
앞으로 이런 내용이 나올 것이다.
- 비공유 메모리 아키텍처
- 복제와 파티셔닝
- 트랜잭션과 분산 시스템의 한계
공유/비공유 아키텍처
구글에 'instargram user number'라고 검색하면 바로 나오는 화면이다. 밀리언도 아니고 빌리언이다. 이정도 규모의 사용자가 있다면 당연히 서버나 데이터베이스 1대로 서비스를 유지할 수 없을 것이다. 끊임없이 발생하는 부하를 견디려면 더 많은 트래픽을 처리할 수 있도록 시스템을 확장해야 한다. 확장하는 방식에는 2가지 방식이 있다.
- 수직 확장: CPU, 메모리, 디스크 등 더 강력한 장비를 구입하는 것이다. 수직 확장을 하면 공유 메모리 아키텍처(shared-memory architecture) 혹은 공유 디스크 아키텍처 등을 만들게 된다. 하나의 운영체제 위에서 시스템이 작동한다.
- 수평 확장: DB 자체를 여러개 만드는 것이다. 즉, 서로 다른 운영체제 위에서 각자의 시스템이 작동한다. DB를 실행시키는 각각의 장비를 노드라고 부른다. 수평 확장을 하면 비공유 아키텍처(shared-nothing)를 만들게 된다.
책의 2부에서는 비공유 아키텍처에 중점을 둔다. 이유는 다음과 같다.
비공유 아키텍처가 모든 사용 사례에 가장 좋은 선택이라기보다는 비공유 아키텍처를 사용할 애플리케이션 개발자가 반드시 주의해야 하는 점이 있기 때문이다.
복제와 가정
그럼 이제 본격적으로 5장 내용을 보자. 5장의 주제는 "복제"다. 복제는 말 그대로 데이터의 복사본을 저장해놓는 것이다. 컴퓨터 3대를 사용한다면 3대에 모두 똑같은 데이터가 저장된다.
CS에서 뭔가를 발전 시켜 나갈 때 쓰는 접근법 중 하나로 '비현실적인 가정을 세우고 시작해서 점점 줄여나가기' 기법이 있다. 비현실적인 가정을 세우는 이유는, 그 가정이 성립하면 우리가 생각하는게 훨씬 편해지기 때문이다. 운영체제 시간에 나왔던 예시로는 '컴퓨터 메모리 크기가 무한대라고 가정한다.'가 있었다. 이러면 메모리 크기에 대한 조건은 생각하지 않고 다른 한계점에 대한 해결책만 찾으면 된다. 해결책을 찾으면 그 다음으로 '컴퓨터 메모리 크기가 무한대'라는 가정을 없애고 메모리 크기도 같이 고려하는 것이다. 이렇게 점점 현실에 가까워지도록 가정을 줄여나가면 된다.
책에서 복제에 대한 내용을 설명할 때도 이 기법을 사용할 것이라고 한다. 5장에서 세운 가정은 '장비 1대에 모든 데이터를 저장할 수 있다'이다. 데이터의 용량, 컴퓨터의 용량 한계는 고려하지 않을 것이다. 6장에서는 이 가정을 없애고 데이터 크기가 너무 커서 장비 여러대가 있어야만 모두 저장할 수 있는 상황에 대처하는 방식이 나온다.
복제의 필요성 4가지
- 고가용성: 시스템을 구성하는 장비의 일부(혹은 전체)가 다운되더라도 시스템이 계속 동작해야 할 때
- 네트워크 중단: 네트워크가 잠시 중단되더라도 시스템이 계속 동작해야 할 때
- 확장성: (엄청나게/단일 장비로는 해결하기 힘들 정도로) 많은 양의 읽기 작업을 처리해야 할 때
- 지연 시간: 사용자가 전세계에 있어서, 지리적으로 사용자와 데이터가 가까이 위치해야 할 때
복제가 어려운 이유
변경 처리 방식 때문이다. 그냥 원본과 복사본을 유지하면 될 것 같지만, 실제로는 처리 방식에 따라 서로 다른 어려움이 생긴다. 해결책도 달라진다. 복제 방식에는 3가지가 있다.
복제 방식에 따른 분류
리더의 개수에 따라 분류할 수 있다. 리더의 역할은 가장 먼저 쓰기 요청을 받고, 이를 나머지 팔로워들에게 전파하는 것이다. 그림을 그려보면 마치 나무가지처럼 리더에서 팔로워로 데이터가 뻗어나가는 형태가 된다. 리더는 0개, 1개, N개가 될 수 있다. 책에서는 각 방식별로 동작 방식과 장단점, 발생 가능한 문제점과 해결책을 제시하고 있다. 각각에 대해 키워드만 알아보자.
리더 기반 복제(leader-based replication)
리더가 1개다. 팔로워는 N개다. Active-passive replication, master-slave replication이라고도 부른다. 리더 기반 복제에서는 리더 장애와 팔로워 장애가 나타날 수 있으며 이에 따라 적절한 대처 방법도 제시되어 있다.
리더 기반 복제 아키텍처를 쓸 때, 사용자가 실제로 쿼리문을 던지는 곳은 리더 한 군데뿐이다. 새로운 데이터나 변경사항이 들어오면 리더에서 적용하고, 팔로워는 리더를 따라간다. 리더 한 곳에서만 read/write가 모두 일어나고, 나머지 모든 팔로워에서는 read만 일어나는 것이다. 그래서 이를 "읽기 확장 아키텍처"라고도 부른다.
다중 리더 복제(multi-leader replication)
리더가 여러개다. 팔로워도 N개다. 그래서 얘기가 좀 더 복잡해진다. 책에서는 리더 기반 복제 방식과 차이점을 비교해놓았다. 리더 기반 복제와 비교했을 때 다중 리더 복제의 가장 대표적인 위험성은 쓰기 충돌이다. 리더 기반 복제에서는 쓰기 작업이 일어나는 곳이 1곳인 반면 다중 리더 복제에서는 쓰기 작업을 할 수 있는 리더가 여러개이기 때문이다.
다중 리더 복제를 사용하는 사례로는 데이터 센터가 여러개인 경우, 캘린더나 메모 앱처럼 오프라인 작업이 동기화 되어야 하는 서비스를 만들 때, 실시간 협업 편집 툴을 만들 때 등이 있다.
리더 없는 복제(leaderless replication)
리더 없는 복제 방식은 한동안 잊혀졌던 키워드라고 한다. 관계형 데이터베이스 출현 이후 거의 잊혀졌다가 아마존에서 dynamoDB를 만든 뒤로 다시 부활했다. DynamoDB의 정신을 이어받아 만들어진 데이터베이스가 여러개 있는데 이들을 dynamo style DB라고도 부른다.
여기서도 쓰기 충돌이 일어날 수 있다. 모두가 팔로워이기 때문에 모두가 쓰기 작업을 할 수도 있는 것이다. 하지만 실제로 "모두"가 쓰기 작업을 하면 충돌이 어마어마 할 것이기 때문에 몇 대까지 쓰기 작업을 할 수 있는지를 정해야 한다. 이를 read/write 정족수를 통해 정한다. 이 정족수를 구하는 방식도 책에 자세히 설명되어 있다. 이외에도 읽기 복구, 안티 엔트로피 처리에 대한 내용이 있다.
리더가 팔로워에게 "전파"하는 방법
리더의 역할은 write를 수행하고 이를 팔로워에게 전파하는 것이라고 했다. '전파'라니. 추상적인 단어다. 전파를 구현하는 방식도 여러가지가 있다.
- 쿼리 기반 복제: 리더가 수행했던 쿼리문을 그대로 팔로워에게 보낸다. 팔로워는 해당 쿼리문을 수행한다.
- 장점: 리더와 팔로워 간 전송되는 데이터 크기(=쿼리문의 크기)가 작다.
- 단점: 쓰기 지연이 발생한다. 즉, 리더쪽에서 수행하는데 오래 걸린 쿼리문은 팔로워에서도 똑같이 오래 걸린다.
- 쓰기 전 로그 배송: 데이터베이스에서 쓰기 요청을 받으면 최적화를 위해 로그를 남긴다. 리더는 이 로그를 보고 디스크에 데이터를 저장하고, 동시에 팔로워에게 보낸다.
- 논리적(row 기반) 로그 복제: 위 방식과 비슷하지만, 복제 로그를 저장소 엔진 내부와 분리할 수 있다. row 단위마다 로그를 끊어서 팔로워에게 보낸다.
- 트리거 기반 복제: 특정 이벤트가 발생 했을 때마다 테이블 변경 내용을 팔로워에게 보낸다.
복제 하는 타이밍에 따른 분류
리더 -> 팔로워가 되었든, 팔로워 -> 팔로워가 되었든 한쪽에서 변경사항이 생기면 다른 쪽으로 변경사항을 전달해야 한다. 이 전달을 언제 하느냐에 따라서도 분류 할 수 있다. 리더 -> 팔로워로 변경사항을 전달할 때를 생각해보자.
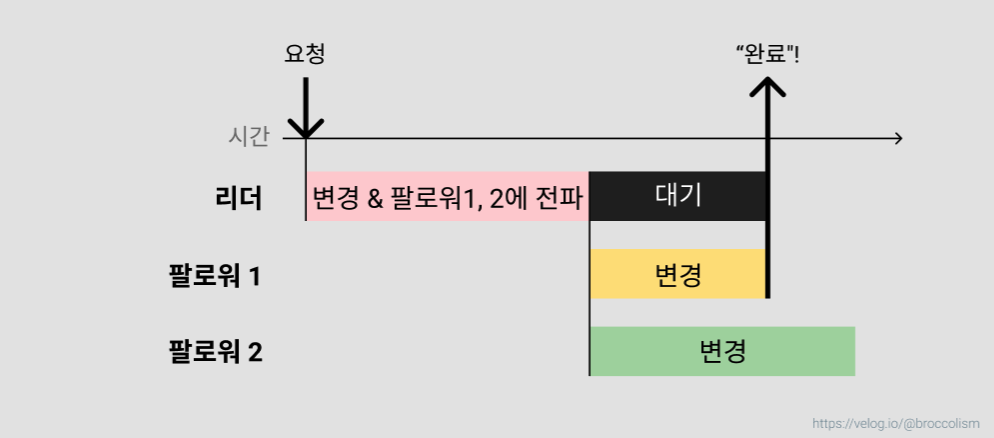
동기식 복제
리더는 모든 팔로워가 변경 사항을 저장했음을 확인한 다음에 완료 처리를 한다. 안정성이 높은 대신 대기 시간이 발생한다.
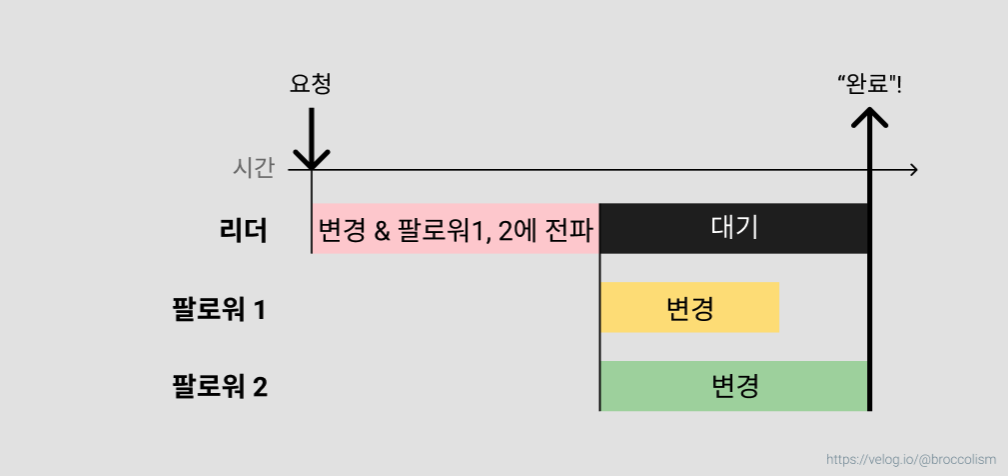
비동기식 복제
리더는 팔로워가 변경 사항을 저장하든 말든 신경쓰지 않는다. 대기 시간이 줄어드는 대신 안정성이 보장되지 않는다.
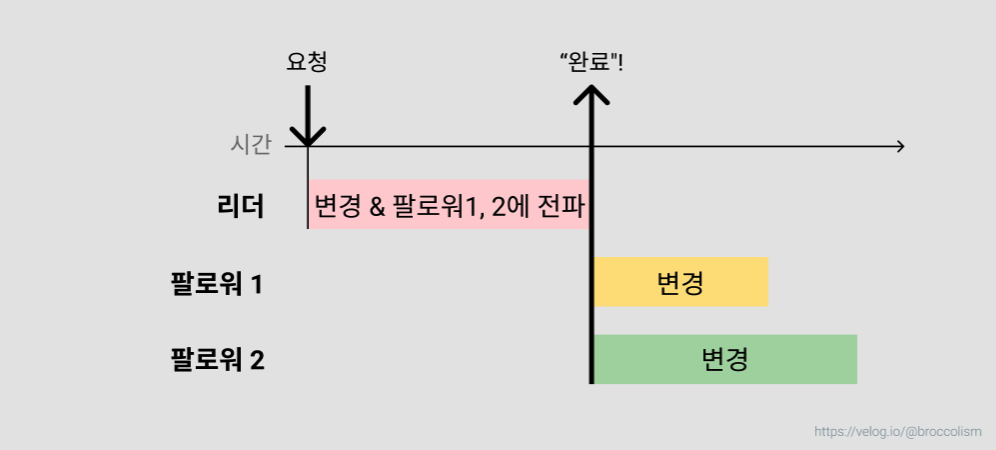
반동기식 복제
리더는 팔로워 하나만 기다린다. 하나라도 변경이 완료되었음을 확인하면 완료 처리를 한다. 대기 시간과 안정성을 모두 어느정도 잡을 수 있다.
위 3가지 방법에서 trade-off는 대기 시간과 안정성임을 알 수 있다.
복제 지연과 해결 방법 3가지
위에서 살펴본 리더의 대기 시간을 비롯해서, 복제 작업이 끝나기 전까지 발생하는 딜레이를 '복제 지연'이라고 한다. 책에서는 복제 지연 때문에 생길 수 있는 문제와 해결책 3가지를 제시한다. 아래 3가지 상황은 모두 비동기식 혹은 반동기식 복제 방법을 쓸 때 생길 수 있는 문제점이다.
문제: 보장해야 하는 성질 형식으로 적었다. 보장해야 하는 성질은 말 그대로 성질이다. 이 성질을 구현하는 방식은 여러가지가 있다. 즉, 문제에 대해 다양한 해결책이 있을 수 있다.
자신이 쓴 내용 읽기: read-after-write consistency(read-your-write) 보장 필요
SNS에서 내 프로필을 편집했다. 리더쪽으로 write 요청이 간다. 리더가 write를 완료했고, 팔로워쪽으로도 변경 내역을 전송했다. 내용이 잘 편집되었는지 보기 위해 다시 내 프로필 화면으로 돌아간다. 이 때, 비동기식 복제 방식을 쓰고 있었다고 생각해보자. 변경이 완료되지 않은 팔로워쪽으로 read 요청이 갔다면? '뭐야, 앱 잘못 만들었네'라는 소리를 들을지도 모른다.
이 문제는 read-after-write consistency (read-your-write consistency라고도 부른다.)를 보장하면 해결된다. 사용자가 페이지를 재로딩 했을 때 항상 자신이 제출한 모든 갱신을 볼 수 있음을 보장하는 것이다. 다른 사용자에 대해서는 보장하지 않아도 된다. 책에서는 이를 구현할 수 있는 다양한 방식을 제시한다. 그 중 기억나는 2가지는 다음과 같다.
- 자신이 수정할 수 있는 데이터는 모두 리더에서만 읽기. 나머지는 팔로워에서 읽기.
- 예) 내 프로필 데이터는 모두 리더에서만 읽기. 다른 사람 프로필을 볼 때는 팔로워에서 읽기.
- write 요청을 보낸 후 특정 시간동안은 리더에서만 읽기. 그 이후에는 팔로워에서 읽기.
시간이 거꾸로 가는 현상: monotonic read 보장 필요
누군가의 게시글에 댓글을 다는 상황을 생각해보자. 내가 단 댓글은 리더 DB에 먼저 전달되어서 저장될 것이다. 리더는 팔로워에게도 댓글 정보를 넘겨준다. 이 때, 팔로워가 2개이고 한쪽 팔로워에게는 빠르게 변동사항이 전달되었지만 다른쪽에는 비교적 느리게 갔다고 생각해보자. 그리고 댓글 정보를 읽을 때 처음에는 빠른 팔로워 DB, 나중에는 비교적 느린 팔로워 DB에게 각각 read 요청을 보낸 상황을 가정해보자.
처음에는 내가 적었던 댓글이 잘 보일 것이다. 새로고침을 눌렀다. 비교적 느린 팔로워 DB에게 read 요청을 보냈는데, 아직 이 팔로워는 내가 적은 댓글 정보 처리를 완료하지 못했다면? 내가 쓴 댓글이 보이지 않게 된다.
자신이 쓴 내용 읽기 문제와의 차이점은 '저장 내역을 한 번이라도 본 적이 있다'는 점이다. 분명히 내가 쓴 댓글을 잘 확인했다. 그런데 새로고침을 하니 내 댓글이 사라지고 마치 시간이 거꾸로 간 것처럼 느껴지는 것이다. 이런 현상을 막기 위해서는 '단조 읽기'라고 번역되는 monotonic read를 보장해야 한다. 이전에 새로운 데이터를 읽은 후에는 예전 데이터를 읽지 않게 하는 것이다. 예를 들어, 각 사용자별로 무조건 하나의 팔로워 DB만 접근하도록 구현하는 방법이 있다.
인과성 위반 우려: consistent prefix read 보장 필요
꽤 복잡한 이유로 인해, 쿼리를 전송한 순서가 꼬일 수 있다. 실제 변경 요청은 query A -> query B 순서로 들어갔지만 리더와 팔로워 간 지연이 일어나면서 실제로 데이터를 보는 사람에게는 마치 B -> A 순서로 보일 수 있다는 것이다. 책에 나온 그림이 워낙 잘 되어 있어서, 책을 보면 어떤 상황인지 바로 파악할 수 있을 것이다. 만약 책이 없는 분이라면 위쪽 'consistent prefix read' 글자에 걸어놓은 링크에 들어가면 된다. 책에 있는 그림과 같은게 나와있다.
이 현상을 막기 위해서는 consistent prefix reads가 필요하다.련의 쓰기가 특정 순서로 발생한다면 이 쓰기를 읽는 모든 사용자도 같은 순서로 쓰여진 내용을 보게 됨을 보장하는 것이다. 샤딩과도 연관되어 있어서 다음 장에서 한번 더 설명할 것이라고 한다.
이제 슬슬 내용이 심화되는 것 같다. 그러면서도 다양한 상황과 기법이 등장해서 점점 재밌어지는 것 같다. 각종 '일관성'에 대한 위키피디아 페이지도 찾았는데, 언젠가 이 문서를 편안-한 마음으로 읽을 수 있게 되면 좋겠다.
