
2장. 주변 친구
문제 인식
‘1장 근접성 서비스’와 비슷하면서도 꽤 다르다. 공통점은 모두 위치 데이터를 다루는 서비스란 점이다. 하지만 1장에서는 그 위치 데이터가 고정되어있는 반면, 2장에서는 계속해서 바뀐다. 업데이트를 해줘야 한다. 친구들의 위치는 건물이나 상점과 달리 실시간으로 바뀔 수 있기 때문이다.
요구사항
- 사용자는 모바일 앱에서 활성 상태인 주변 친구를 확인할 수 있어야 한다.
- 즉, 현재 앱에 접속 중인 친구만 표시해준다.
- 주변 친구는 5마일(8km) 반경 내에 있는 친구로 정의한다.
- 친구 목록은 30초마다 한 번씩 갱신되어야 한다.
- 수치
- 1억 DAU
- 동시 접속 사용자는 10%
- 사용자는 30초마다 자기 위치를 시스템에 전송한다.
- → 따라서 위치 정보를 시스템으로 전달하는 QPS는 (1억 * 10%) / 30초 = 약 334,000 이 된다.
- 사용자별 평균 친구 수는 400명이라고 가정한다.
- 그 중 활성 상태인 주변 친구는 10%라고 가정한다.
- → 따라서 위치 정보를 다른 사람에게 전달하기 위한 QPS는 (동시접속자가 자신의 위치를 시스템으로 보내는 약 334,000) (한 명당 평균 친구 수 400명 활성 상태 친구의 비율 10%) = 14,000,000 이 된다.
설계도
이제 설계도를 그려보자. 이번 장의 핵심은 위와 같이 큰 수치의 QPS를 실시간으로 잘 처리해내는 것이다. 이를 위해 웹소켓과 레디스를 사용할 것이다.
큰 그림
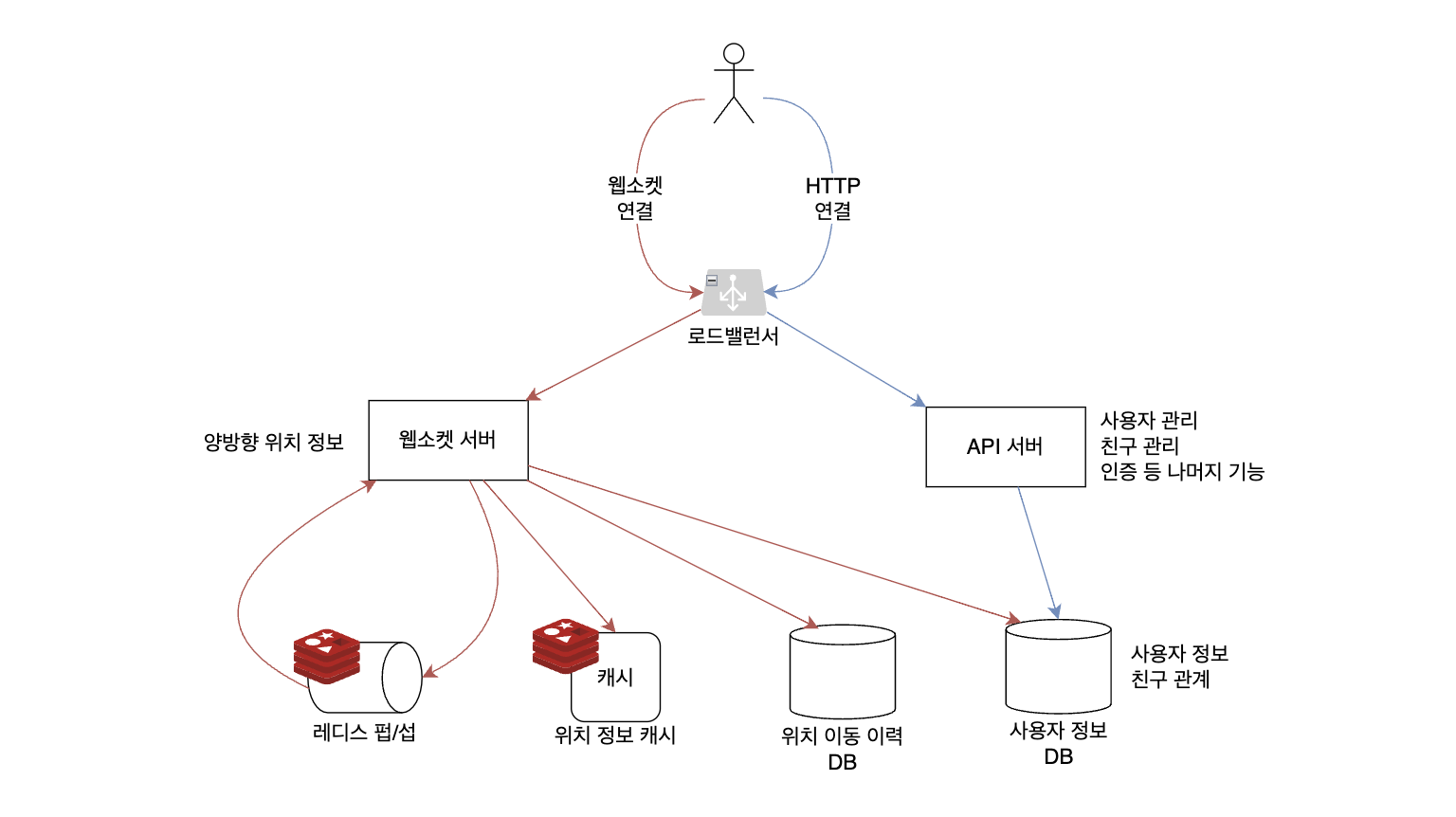
클라이언트가 보내는 요청은 두가지로 나뉜다. 웹소켓 연결을 통한 요청과 HTTP 연결을 통한 요청. 웹소켓 서버는 자신의 위치 데이터를 갱신하고 주변 친구의 위치를 실시간으로 업데이트 하는데 쓰인다. 이 때 자신의 위치가 변했음을 알리기 위해 자기 토픽의 발행자(publisher)가 될 것이고, 각 친구들의 위치가 변했음을 알기 위해 친구들의 레디스 펍/섭 채널을 구독(subscribe)할 것이다. HTTP 연결은 API 서버와 맺는다. 이 서버에서 위치 정보 업데이트를 제외한 나머지 기능 - 사용자 관리, 친구 관리 등 - 을 처리한다.
웹소켓 서버의 역할을 먼저 살펴보자. 친구들의 위치가 변했다면 그 친구가 나와 가까운지 아닌지 판단해야 한다. 이를 위해 나의 위치 정보가 필요하다. 현재 나의 위치 정보는 레디스 캐시 서버에 저장하고, 이동 이력을 저장하기 위해서는별도 DB를 두어서 영구적으로 저장한다. 저장되는 데이터는 1장에서 살펴봤던 것처럼 2차원 위치 데이터를 1차원 값으로 변환시킨 값이 될 것이다. 사용자 정보 DB는 친구 관계를 확인하는데 사용한다. 책에서 따로 언급은 하지 않지만 필요하다면 이 DB에 대한 캐시 계층을 따로 둘 수도 있을 것이다.
API서버는 책에서 깊이 다루지 않는다. 지금까지 우리는 이런 서버를 너무나도 많이 접했기 때문이다. (심지어 이번 책 1장에서도 똑같이 나왔다. 사업장 서비스 서버말이다.)
이 구조를 왠지 어디서 한 번 본 것 같다면 맞다. 1장 근접성 서비스에 봤던 전체 설계도와 비슷하게 생겼다. 아래 그림에서 왼쪽은 1장 근접성 서비스, 오른쪽은 2장 주변 친구 서비스의 전체 설계도다. 사용자 요청을 받아서 종류에 따라 적절한 서버로 보내서 처리한다는 공통점이 있다. 각 서버는 자기가 잘 하는 기능 하나만 담당하는 것이다. 또 다른 공통점은 인메모리 스토리지인 레디스를 사용한다는 점이다. 다만 1장에서는 레디스를 캐시 용도로만 사용했고, 2장에서는 캐시뿐 아니라 메세지 채널로도 사용했다. 아래에서 좀 더 자세히 알아보자.

레디스를 써보자
핵심 기능인 위치 정보 갱신을 어떻게 구현할 것인지 생각해보자. 위 요구사항에 나왔던 것처럼 많은 양의 데이터 갱신이 지연 없이 이루어져야 한다. 이를 위해 웹소켓 서버를 사용한다. 또한 한 사람의 위치 데이터가 갱신되면 그 사람과 친구 관계인 모든 사람에게 그 사실이 알려져야 한다. 즉, ‘위치 정보 변화’라는 이벤트가 생기면 그 이벤트를 N개 클라이언트가 바로 반응해야 한다. 따라서 이벤트 기반 아키텍처를 채택한다. 이를 구현하기 위해 레디스 펍/섭을 사용할 것이다.
레디스 펍/섭
Redis Pub/Sub 의 특징은 다음과 같다.
- 메세지 브로커 역할을 한다. 토픽을 관리하고 토픽별 발행자와 구독자를 등록할 수 있다.
- 이번 장에서 발행자는 위치 정보가 바뀐 사람, 구독자는 그 사람의 친구들이 된다.
- 메세지 채널을 만드는 데 드는 비용이 아주 저렴하다.
- 한 번 발행된 이벤트 구독자에게 전달만 하고 따로 저장하지 않는다.
- 토픽을 구독하는 모든 subscriber 서버에게 메세지가 전달된다.
이벤트 채널로 많이 사용하는 다른 오픈소스로 아파치 카프카가 있다. 위 특징을 카프카와 비교하자면 이렇게 된다.
- 카프카에서는 한번 발행된 이벤트가 각 파티션에 저장된다.
- 컨슈머 그룹이라는 개념이 있어서, 하나의 그룹에 N개 서버가 묶일 수 있다. 이 때 카프카 메세지는 하나의 그룹 당 1개만 전달되기 때문에 하나의 서버만 메세지를 받을 수 있다.

책에서 주변 친구 기능을 구현하기 위해 레디스 펍/섭을 선택한 이유를 레디스 펍/섭의 특징을 통해 알아보자.
- 메세지 채널을 만드는 데 드는 비용이 아주 저렴하다.
- 얼마나 저렴하냐면, 사용자 한 명당 채널 하나를 만들어도 될 만큼! 그래서 사용자 수만큼 만들 것이다.
- 사용자 A의 친구 400명은 모두 채널 A를 구독한다. 이래도 되냐고? 된다. 그만큼 비용이 적게 든다.
- 한 번 발행된 이벤트를 저장하지 않는다.
- 예를 들어 구독자가 없는 어떤 채널로 메세지가 보내졌을 때 해당 메세지는 구독자가 생길 때를 대비해서 저장되거나 하지 않고 그대로 버려진다.
- 덕분에 설계가 아주 단순해진다.
- 어떤 사용자의 활성 상태 친구가 0명이 되더라도 별도의 ‘채널 삭제’ 같은 행위를 하지 않아도 된다. 그냥 그대로 두면 된다.
- 마찬가지로 어떤 사용자를 구독하기 전에 그 사용자가 활성 상태인지 아닌지 확인할 필요가 없다.
- 토픽을 구독하는 모든 subscriber 서버에게 메세지가 전달된다.
- 따라서 사용자 A의 채널을 구독하고 있는 사람들은 모두 메세지를 수신할 수 있다.
- 만약 카프카를 쓰고 컨슈머 그룹을 달아놓는다면 각 서버 1개당 컨슈머 그룹을 1개씩 만들어야 했을 것이다.
레디스 캐시
왜 위치 정보를 저장하기 위해 DB를 쓰지 않고 레디스를 썼을까? 데이터가 유실될 수도 있는데말이다. 사실은 이 점을 노리고 일부러 레디스를 사용했다. 지금 필요한 것은 ‘영구적으로 저장되는 나의 위치 변화’가 아니라 ‘지금 현재 내가 있는 곳의 위치 데이터 1개’이기 때문이다. 데이터 유실의 위험이 있는 반면 레디스는 인메모리 스토리지이기 때문에 데이터를 빠르게 읽을 수 있는 장점이 있다. 즉, 약간의 데이터 유실이 있어도 되지만 지연 시간은 짧아야 할 때 레디스를 캐시 서버로 활용하면 유용하다.
Stateful Server 의 규모 확장
우리는 서버를 이렇게 2가지로 분류할 수 있다. 상태(stateful) 서버와 무상태(stateless) 서버. 레디스 펍/섭은 stateful 서버라고 할 수 있다.
- 아니 레디스 펍/섭에 한번 발행된 메세지는 메모리나 디스크에 저장하지 않고 그냥 버린다면서요? 아무 상태도 안 갖고 있는거 아닌가?라고 생각할 수 있겠지만
- 펍/섭이기 때문에 토픽과 발행자, 구독자 정보를 갖고 다닌다.
- 만약 토픽 T1 을 처리하고 있던 서버 1이 죽는다면, 다른 서버 2에게 T1에 대한 발행자와 구독자 정보를 넘겨주고 죽어야 한다.
따라서 레디스 펍/섭은 상태 서버 클러스터라고 간주하는게 좋다. 수평적 규모 확장을 할 때 조심스럽게 해야 하는 것이다. 보통 이런 이유에서 오버 프로비저닝을 한다고 한다. 얼마나 필요할 지 정확히 모르겠지만 일단 넉넉하게 준비해놓는 것이다. 만약 클러스터 규모 확장이 필요하다면 해시 링 전략을 사용할 수 있다.
결론
- 이럴 땐 웹소켓! 1) stateful 연결이 필요하고 2) 연결을 오래 유지하며 3) 서버와 클라이언트가 주고받을 내용이 있는 상황
- 레디스 펍/섭을 사용해 실시간으로 위치 정보를 갱신했다.
- 현재 위치를 저장하기 위해 레디스를 캐시 계층으로 사용했다.
번외)
우리가 필요로 하는 것은 막대한 쓰기 연산 부하를 감당할 수 있고, 수평적 규모 확장이 가능한 데이터베이스다. 카산드라(Cassandra)는 그런 요구에 잘 부합한다. - 2장 2단계: 계략적 설계안 제시 및 동의 구하기
→ https://cassandra.apache.org/_/cassandra-basics.html 주요 특징: NoSQL, master 없이 모두가 Primary, P2P
각 사용자의 위치 정보는 서로 독립적인 데이터이므로, 사용자 ID를 기준으로 여러 서버에 샤딩하면 부하 또한 고르게 분배할 수 있다. - 2장 3단계: 상세 설계
→ 하나의 데이터가 다른 데이터와 관계가 없는 독립적인 데이터는 샤딩하기 편하다.
