
3장. 구글 맵
- 1장에서는 지도 데이터를 효과적으로 저장하는 방법을 알아보았고
- 2장에서는 그 데이터를 바탕으로 실시간 서비스를 만드는 방법을 중점적으로 다뤘다.
- 3장에서는 우리가 일반적으로 사용하는 ‘지도 서비스’를 구현하는데 필요한 요소를 살펴본다.
요구사항
- 지도가 보여야 한다.
- 사용자 위치가 지도에 표시되어야 하고 갱신되어야 한다.
- ETA(Estimated Time of Arrival, 예상 도착 시간) 서비스를 포함한 경로 안내가 되어야 한다.
- 모바일 클라이언트를 지원한다. 따라서 데이터와 배터리 사용량을 최소화해야 할 필요가 있다.
큰 그림
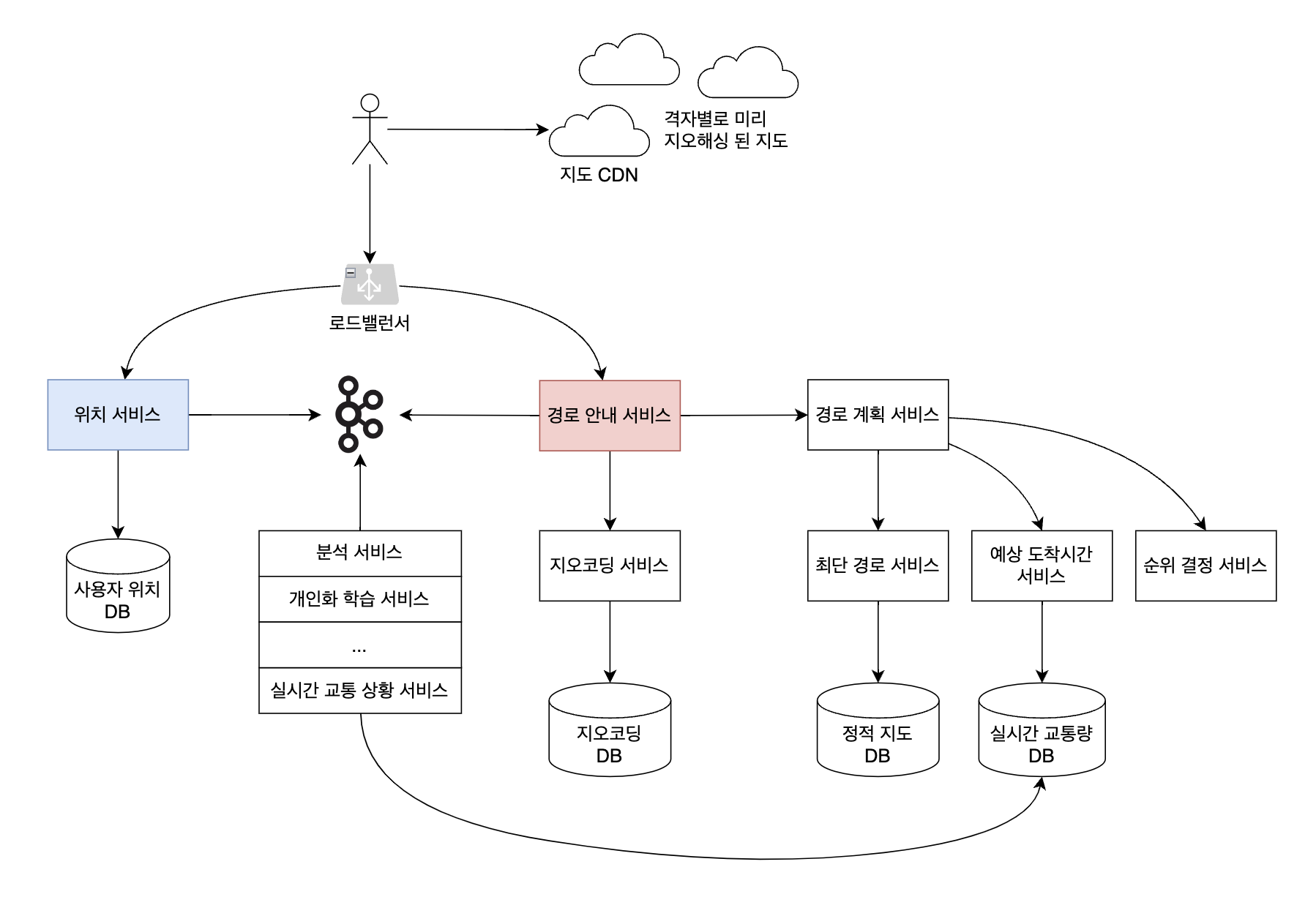
1장 근접성 서비스, 2장 주변친구에서와 봤던 구조와 비슷하다. 역시나 크게 2개의 서비스 (위치 서비스, 경로 안내 서비스)로 전체 기능을 나눈 뒤 앞에 로드밸런서를 두었다. 1장에서는 로드밸런서 뒤에 위치 기반 서비스와 사업장 서비스가 있었고 2장에서는 위치 정보를 실시간으로 업데이트하는 웹소켓 서버와 나머지 친구 기능을 처리하는 API서버가 있었다. 3장에서도 위치를 다루는 서비스를 다른 서비스와 별개로 분리하였다.
지도 서비스에는 이런 기능이 들어가는데…
- 지도 표시
- 사용자 위치 갱신
- 경로 안내
먼저 지도 CDN에서 사용자 주변 지도 데이터를 받아와서 지도를 표시한다. 위치 서비스에서는 사용자 위치 갱신을 하고, 그 갱신된 데이터를 바탕으로 경로 안내 서비스가 경로를 안내해준다. 사용자 위치가 갱신되었음을 알리기 위해 책에서는 카프카를 사용했다. 경로 안내 서비스 외에도 분석 서비스, 개인화 학습 서비스 등 애플리케이션 동작에 필요한 다른 서비스도 사용자 위치 토픽을 consume 한다. 카프카 consumer 중 실시간 교통 상황 서비스는 교통 데이터를 수집하여 실시간 교통량 DB에 저장하는데, 이 데이터를 경로 안내 시 예상 도착 시간을 계산하는 서비스가 참조한다. 즉, 위치 서비스에서 produce 하는 데이터는 단순히 사용자 위치를 갱신하는 것뿐만 아니라 데이터 분석 및 경로 안내 등 다양한 곳에 사용된다.
상세 구조 살펴보기
지도 서비스 특) 미리 만들어놓음
구글맵처럼 전세계 모든 지역의 지도를 보여주려면 어떻게 해야 할까? 지도 데이터를 보여주는 방법은 2가지가 있다. 첫 번째는 클라이언트가 요청할 때마다 데이터를 가공해서 보여주는 것이고, 두 번째는 미리 모든 데이터를 가공해서 저장해놨다가 클라이언트한테 던져주는 것이다. 당연히 첫 번째 방법은 쓸 수 없다. 클라이언트에 많은 부하가 걸리기 때문이다. 클라이언트가 요청할 때마다 새롭게 데이터를 계산해서 줘야 하는 서버에게도 부담이 많이 된다. 클라이언트 수가 늘어날수록 서버 부하도 커진다.
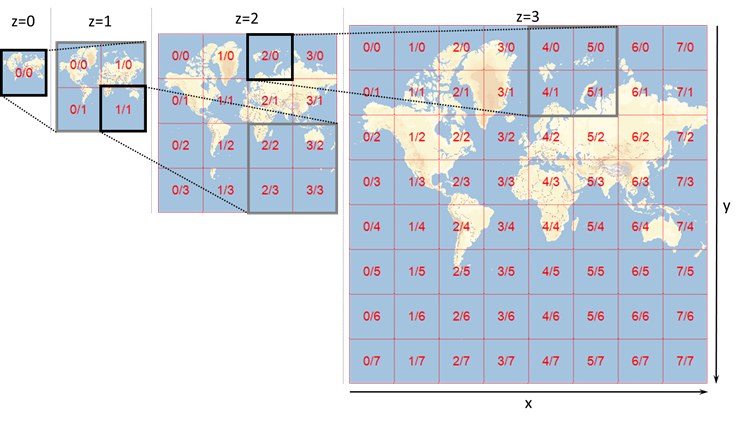
지도 데이터는 잘 변하지 않는다. 적어도 1초에 한 번씩 업데이트 되거나 하는 데이터가 아니라는 점에서 그렇다. 따라서 우리는 지도 데이터를 미리 만들어놓을 것이다. 줌 인-아웃 기능을 지원해야 하기 때문에 각 해상도별로 복사본을 만들어놓을 것이다. (그래서 지도 프로그램을 써보면 부드럽게 스크롤 되면서 줌 인-아웃 되는 것처럼 보이지만, 보통 연속된 해상도가 아닌 이산적 해상도를 갖는다. 뚝뚝 끊기면서 확대 혹은 축소된다.) 위 사진은 https://xserver2-dashboard.cloud.ptvgroup.com/dashboard/Content/TechnicalConcepts/Rendering/DSC_Map_Tile_API.htm 에서 가져왔다. 사이트에 들어가보면 전세계 지도를 각 해상도별로 확대, 축소할 수 있다.
이처럼 지도를 원하는 해상도에 맞게 사각형으로 잘라놓은 칸 하나를 지도 타일이라고 한다. 전 세계 지도 이미지를 여러개 복사해서 저장하면 용량이 모자라지 않느냐는 질문을 할 수도 있지만, “지구 표면 가운데 90%는 인간이 살지 않는 자연 그대로의 바다, 사막, 호수, 산간 지역임에 유의하자. 이들 지역의 이미지는 아주 높은 비율로 압축할 수 있다.” 지도 타일 용량이 하나의 서버에 저장할 수 없을 정도로 크지는 않다. 지도 타일 이미지는 클라이언트가 바로 연결할 CDN 서버에 저장하고 캐싱을 하거나 별도 서버를 두어서 좀 더 빠르게 제공할 수 있다.
지도 이미지를 보여주는 것 외에 길찾기 용도로 지도를 저장해야 한다. 이를 위해서는 그래프를 사용한다. 아래와 같이 교차로는 노드(node), 교차로가 아닌 도로는 간선(edge)로 표현하여 저장한다.
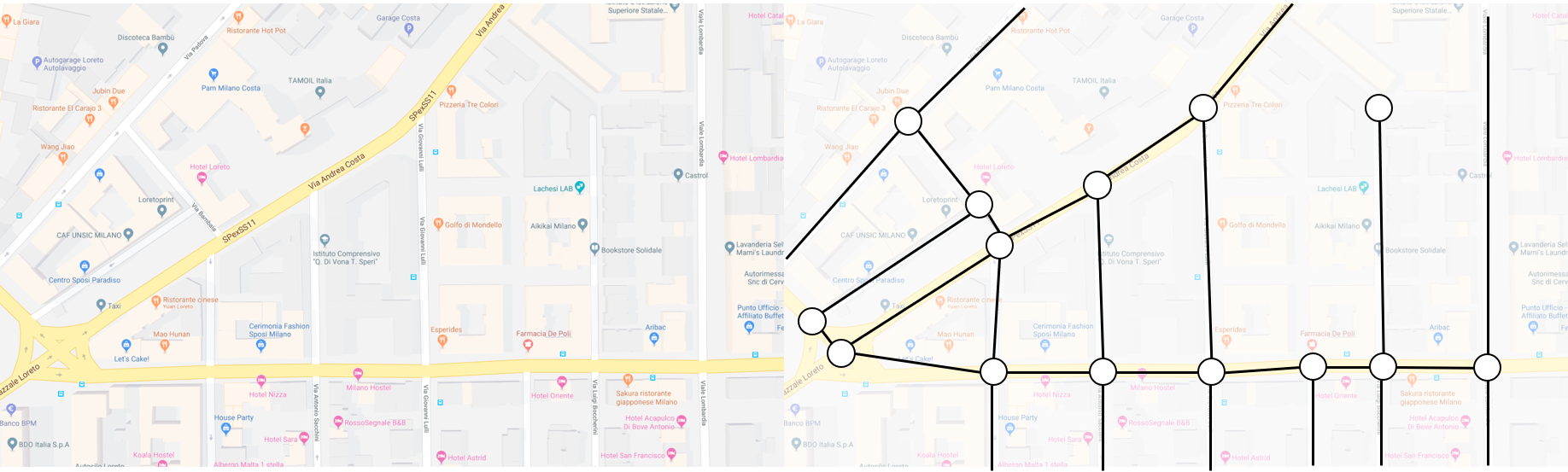
(그림 출처: https://magazine.impactscool.com/en/speciali/google-maps-e-la-teoria-dei-grafi/)
그래프 데이터는 경로 안내 서비스가 참조할 정적 지도 DB에 저장된다. 바이너리 데이터에 불과하기 때문에 이 데이터 역시 용량이 생각보다 크지 않다.
위치 서비스
이제 위치 서비스를 자세히 들여다보자.
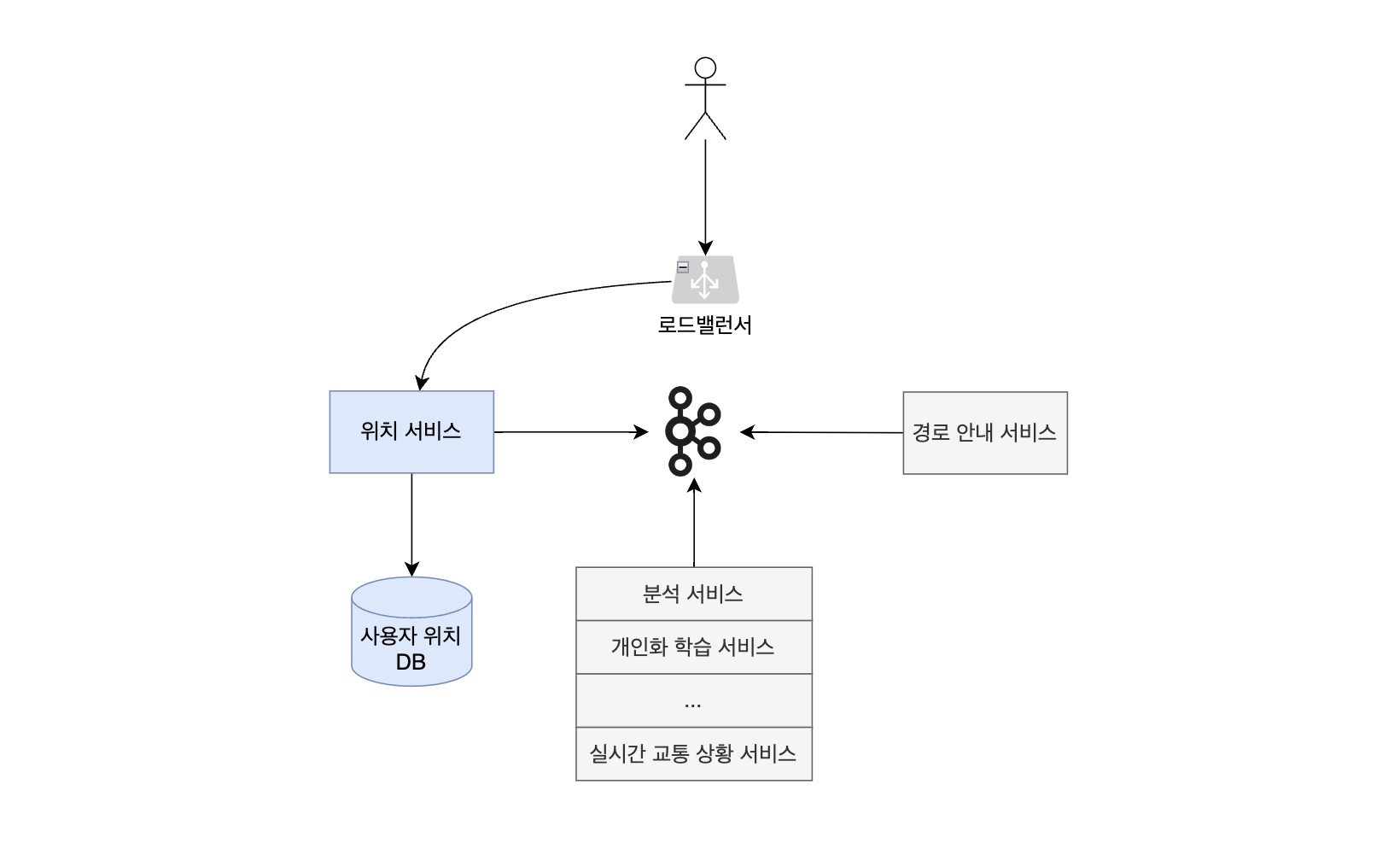
여기서 주로 살펴볼 건 위치 서비스와의 연결 방식과 데이터베이스다. 사용자 위치 정보는 자주 갱신된다. 얼마나 자주인지는 정하기 나름이겠지만 보통 수 초 단위일 것이다. 몇 초마다 한 번씩 수많은 클라이언트가 자신의 위치 갱신 요청을 한다고 생각해보자. 모든 요청 하나 하나가 새로운 HTTP 커넥션이라면 위치 서비스 서버는 굉장히 피곤할 것이다. 따라서 HTTP keep-alive 옵션을 사용해서 연결을 생성하고 끊는 비용을 줄이는게 좋다.
데이터베이스쪽도 따로 고려할게 있다. 몇 초 간격으로 클라이언트의 위치 정보가 갱신된다는 의미는 DB에 수많은 쓰기 연산이 가해진다는 뜻이다. 대신 위에서 언급한 것처럼 몇몇 데이터가 유실되어도 무방하다. 책에서는 여기에 가장 적합한 데이터베이스로 카산드라를 꼽고 있다. 일관성은 보장하지 않아도 되지만 높은 가용성과 분할 내성을 필요로 하기 때문이다. 사용자 아이디 user_id를 파티션 키로 사용해서 데이터 파티셔닝을 하고, 데이터 생성 시간 timestamp를 클러스터링 키로 해서 정렬 기준 필드로 사용하면 된다.
위치 서비스에서는 데이터를 DB로 갱신할 뿐만 아니라 카프카로도 보낸다. 이렇게 보낸 데이터를 분석 서비스나 개인화 학습 서비스, 실시간 교통 상황 서비스 등 필요한 서비스에서 consume 하는 구조다. 곧 살펴볼 경로 안내 서비스에서도 실시간 사용자 위치를 받아와서 새로운 경로를 추천하는 데에 이 데이터를 활용한다.
경로 안내 서비스
경로 안내 서비스는 또다시 서비스 여러개로 쪼갤 수 있다. 경로 안내를 하기 위해 필요한 기능별로 서비스를 나누는 것이다.
그림에 표시한 번호는 사용자에게 추천 경로를 보여주기 위해 필요한 작업을 순서대로 나타낸 것이다.
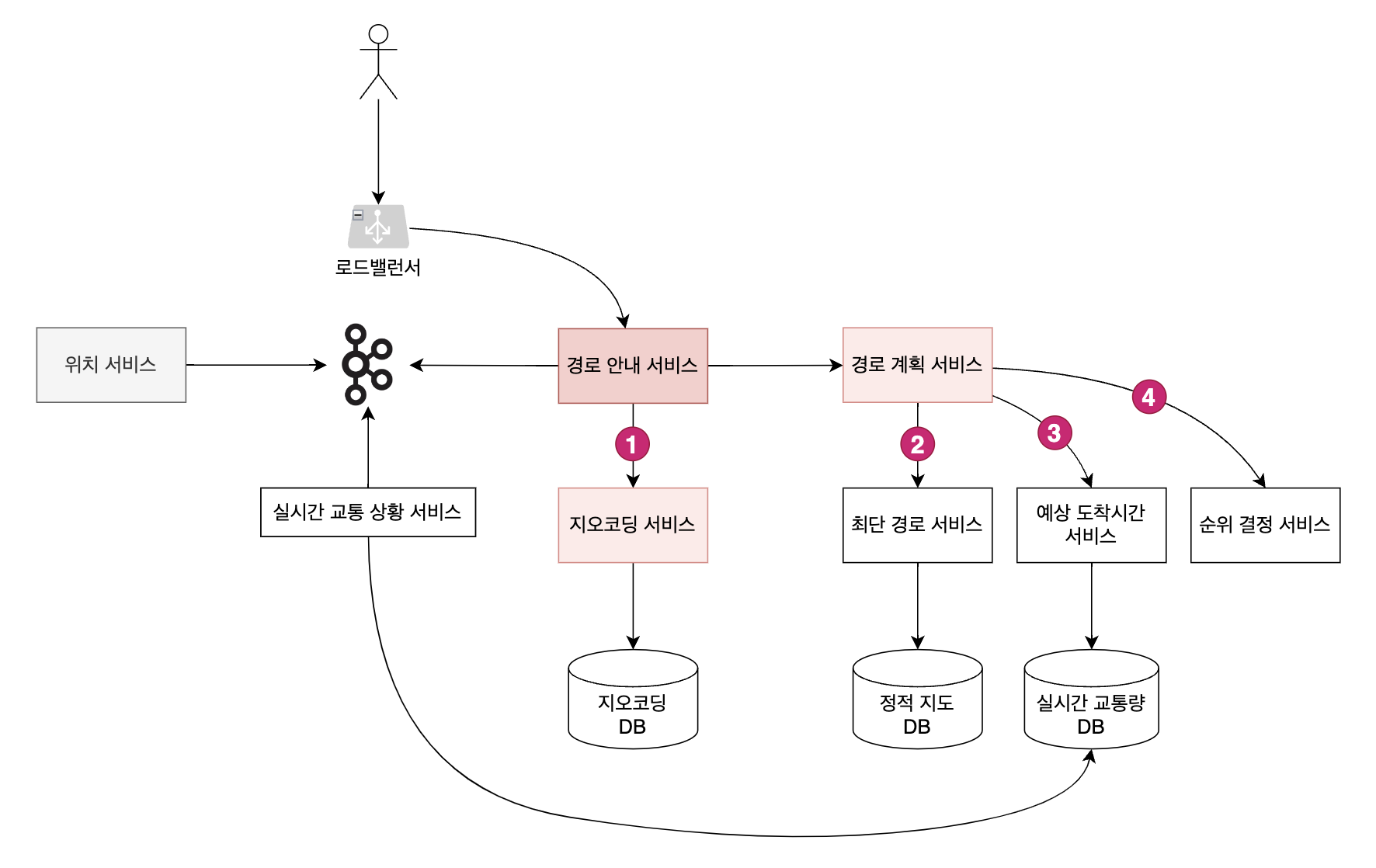
1. 지오코딩 서비스
지오코딩(Geocoding)은 주소를 지리적 측위 시스템의 좌표로 변환하는 프로세스다. 예를 들어 미국 내 주소 ‘1600 Amphitheatre Parkway, Mountain View, CA’의 지오코딩 결과는 (위도 37.423021, 경도 -122.083739) 가 된다.
즉, 사용자가 입력한 목적지 주소를 위도와 경도로 변환시키는 역할을 한다. 경로 안내 서비스는 지오코딩 서비스에서 변환한 주소를 들고 경로 계획 서비스에 요청을 보낸다.
2. 최단 경로 서비스
앞서 살펴봤던 지도 그래프 데이터를 이 서비스가 참조한다. 다익스트라 알고리즘, A* 알고리즘 등을 응용한 최단 경로 알고리즘을 사용해서 목적지까지의 경로를 뽑아낸다.
3. 예상 도착시간 서비스
최단 경로에서 뽑아낸 경로별로 예상 도착 시간을 계산한다. 실시간 교통량에 따라 최단 경로라고 생각했던게 오히려 더 오랜 시간이 걸릴 수 있기 때문이다. 이 때 실시간 교통량은 앞서 살펴본 위치 서비스에서 카프카로 produce 한 데이터를 기반으로 한다.
4. 순위 결정 서비스
경로 길이와 예상 도착 시간 외에 나머지 추가 정보를 고려해서 최종 순위를 결정한다. 예를 들어 통행 요금이나 고속도로 선호 등 사용자가 따로 입력한 데이터도 함께 고려하여 순위를 결정하는 것이다.
결론
- 지도 이미지를 저장하기 위해 지도 타일을 사용하고, 도로를 저장하기 위해 그래프를 사용한다.
- 사용자 위치 데이터베이스에는 쓰기 연산이 자주 일어나기 때문에 일관성보다는 가용성, 분할 내성을 더 중요하게 생각해야 한다.
- 경로 안내 서비스에서는 지오코딩 데이터와 정적 지도, 실시간 교통량 데이터를 사용해서 경로를 추천한다.
번외) 일반적인 이야기
선택지 1: 클라이언트의 위치, 현재 클라이언트가 보는 지도의 확대 수준에 근거하여 필요한 지도 타일을 즉석에서 만드는 방안
사용자 위치 및 확대 수준의 조합은 무한하다는 점을 감안하면, 이 방안에는 몇 가지 심각한 문제가 있다.
- 모든 지도 타일을 동적으로 만들어야 하는 서버 클러스터에 심각한 부하가 걸린다.
- 캐시를 활용하기가 어렵다.
선택지 2: 확대 수준별로 미리 만들어 둔 지도 타일을 클라이언트에 전달하기만 하는 방법
(CDN을 사용하여 캐싱한다.)이 접근법은 규모 확장이 용이하고 성능 측면에서도 유리하다. 사용자에게 가장 가까운 POP(Point of Presence)에서 파일을 서비스하기 때문이다. - 3장 2단계: 개략적 설계안 제시 및 동의 구하기
→ 클라이언트가 해도 되고 서버가 해도 되는 작업을 누가 할 지 결정할 때에는 1) 작업 부하가 어느정도로 걸리는지 2) 캐시를 활용할만한 상황인지 를 고려해보자.
클라이언트는 CDN에서 지도 타일을 가져올 URL을 어떻게 결정할까? (…) 앞에서 서술한 대로 지오해시 계산은 클라이언트가 수행해도 된다. 하지만 해당 알고리즘을 클라이언트에 구현해 놓으면 지원해야 할 플랫폼이 많을 때 문제가 될 수 있음은 주의하자. (…) 고려해 볼 만한 다른 한 가지 선택지는 주어진 위도/경도 및 확대 수준을 타일 URL로 변환하는 알고리즘 구현을 별도 서비스에 두는 것이다. (…) 운영 유연성이 높아지는 이점이 있으므로 고려할 가치가 있다. 장단점을 면접관과 논의해 보면 아주 흥미로울 것이다. - 3장 2단계: 개략적 설계안 제시 및 동의 구하기
→ 동일한 알고리즘을 여러 종류의 클라이언트가 써먹어야 할 때에는 별도 서버로 빼는게 유용하다. 운영 유연성도 챙길 수 있다.(하지만 단점도 있겠지? 이 서버 죽으면 클라이언트는 이 기능 못 씀.)
초당 백만 건의 위치 정보 업데이트가 발생한다는 점을 감안하면 쓰기 연산 지원에 탁월한 데이터베이스가 필요하다. NoSQL 키-값 데이터베이스나 열-중심 데이터베이스(column-oriented database)가 그런 요구사항에 적합하다. - 3장 3단계: 상세 설계
→ NoSQL 키-값 DB나 열-중심 DB가 쓰기 연산을 잘 한다.
CAP 정리에 따르면 일관성, 가용성, 분할 내성 모두를 만족시킬 방법은 없다. 그러므로 주어진 요구사항에 근거하여, 본 설계안은 가용성과 분할 내성 두 가지를 만족시키는 데 집중한다. 그리고 이 요구사항에 가장 적합한 데이터베이스 가운데 하나는 카산드라다. - 3장 3단계: 상세 설계
→ 카산드라는 일관성 버리더라도 가용성과 분할 내성이 중요할 때 유용하다.
카프카는 응답 지연이 낮고 많은 데이터를 동시에 처리할 수 있는 데이터 스트리밍 플랫폼으로, 실시간 데이터 피드(data feed)를 지원하기 위해 고안되었다. - 3장 3단계: 상세 설계
