- (가상 면접 사례로 배우는 대규모 시스템 설계 1 시리즈 바로가기)
- 가상 면접 사례로 배우는 대규모 시스템 설계 2 - 6장. 광고 클릭 이벤트 집계
오 사실 광고 클릭 이벤트를 집계하는 것 자체에는 큰 흥미가 없다. (ㅋㅋ. 어느 사이트든 무슨 게임이든 달려있는 광고에 질려버렸기 때문인거같다.) 대신 이걸 달성하기 위해 어떤 기법을 썼는지는 재밌어보이니까 그래도 한번 읽어보자. 데이터 처리가 중요한 장인만큼 전체적인 구조는 크게 복잡하지 않다. 대신 이번 장에서는 이런 내용을 위주로 살펴볼 것이다.
- 이벤트 로그 데이터의 특징
- 그 특징을 고려해서 데이터를 '잘' 처리하기 위한 기법
- 클릭 이벤트 로그를 '잘' 저장하는 방법과 그 시점
- 그리고 기타 재밌어보이는 내용
광고 101
광고 도메인에 종사하는 사람이 아니다보니 그동안 몰랐던 중요한 사실을 알게 되었다. 광고로 돈을 번다는건 광고 지면을 소유하고 그 지면에 대한 점유권을 판매하는 것을 의미한다. (지금까지 알고 있던 ‘개발자로써 광고로 돈 벌기 방법’은 모바일 앱 만들어서 거기에 광고 붙이는거밖에 없었던 내게는 완전히 새로운 정보였다.)
디지털 광고의 핵심 프로세느는 RTB(Real-Time Bidding), 즉 실시간 경매라 부른다. 이 경매 절차를 통해 광고가 나갈 지면을 거래한다.
광고 도메인에서 클릭 로그의 중요성은 한 단어로 요약할 수 있다. 돈 때문이다. 사람들이 광고를 얼마나 클릭했고 그 후 어떤 행위를 했는지 등에 따라 광고주가 내야 할 비용이 결정된다.
따라서 우리의 임무는 로그를 잃어버리지 않고 꼼꼼히 기록하는 것이다. 돈 벌어야지!
목표 & 요구사항
- 1순위: 집계 결과 정확성.
- 더불어 부분적인 장애를 견딜 수 있어야하고 지연/중복 메세지 처리도 할 수 있어야 한다.
- 집계 기능
- 지난 N분 동안 특정 광고의 클릭 수
- 매 분 가장 많이 클릭된 상위 100개 광고 아이디 조회
- 여러 속성별 필터링
큰 그림
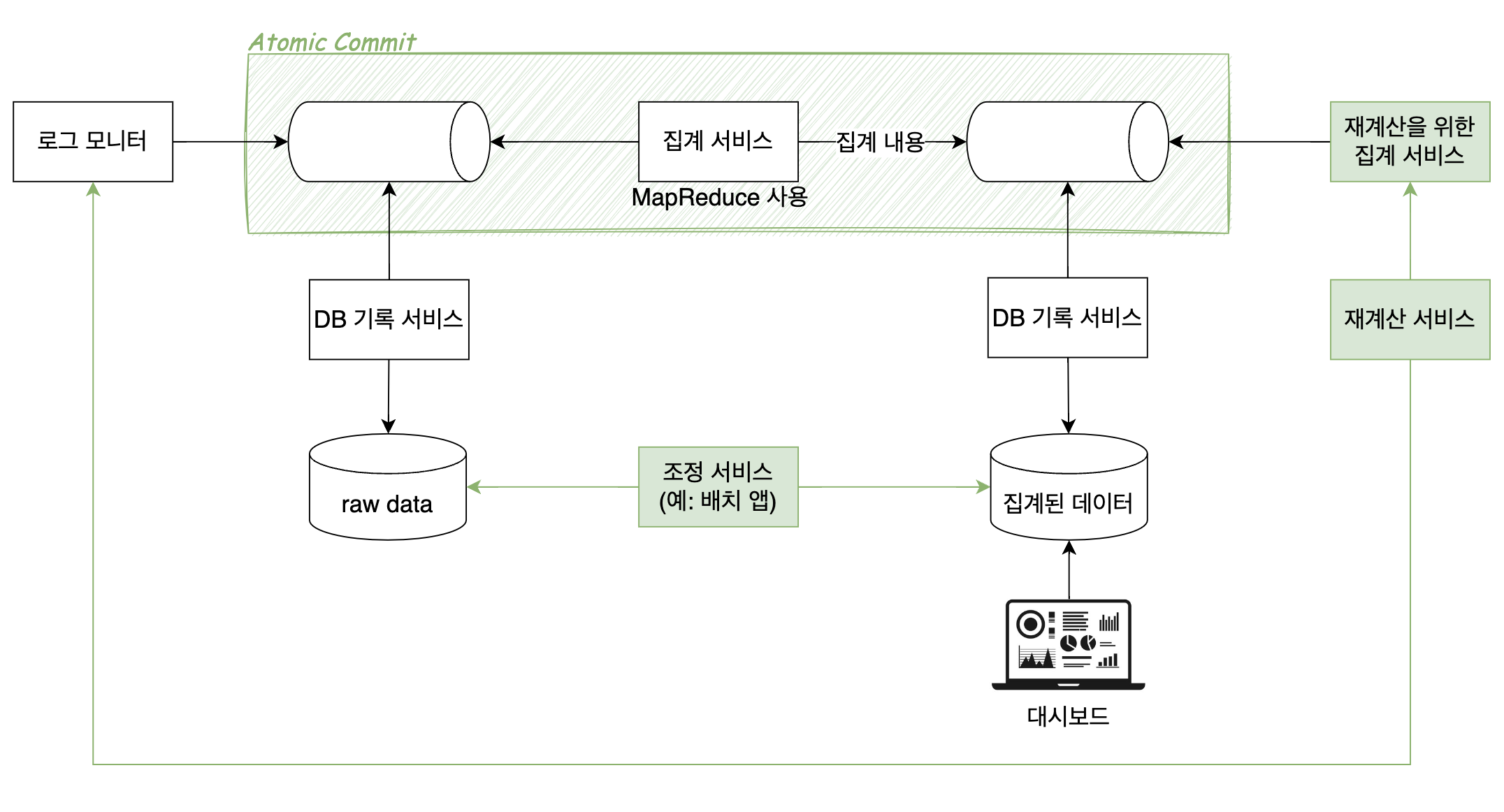
초록색 부분이 모두 데이터 정확성을 위한 안전장치다. 그러니까 원래 로그 수집을 위해서는 로그 데이터를 넘기는 역할과 DB에 저장하고 그걸 보여주는 역할만 있으면 되는데 데이터 유실을 막기 위해 더 많은 기능이 추가된거라고 보면 된다.
- 메세지큐를 사용한 atomic commit
- 사실 atomic commit, exactly once 전송 등이 진짜로 가능한지 아닌지에 대한 논의가 많이 일어났다고 알고 있다. 이 주제는 다른 포스팅에서 따로 다루려한다.
- 집계가 잘못되었을 경우를 대비한 재계산 서비스와 그 전용 집계 서비스
- 그림의 가장 오른쪽에 있는 두 서비스의 본체는 재계산 서비스다.
- 집계 데이터가 잘못되었을 경우를 대비한 조정 서비스
- 보통 일정 간격으로 실행되는 배치 서버를 만들어서 진짜로 모든 데이터를 집계한게 맞는지 확인하고 조정하는 역할을 맡긴다.
왼쪽의 raw data 를 사용하지 않고 집계된 데이터를 따로 만들어서 대시보드에 보여준다는걸 기억하자. 즉, 위에서 이루어지는 모든 작업은 제대로된 집계 데이터를 만들고 이를 보여줌으로써 데이터를 관리하고 비용을 책정할 수 있도록 하기 위함이다.
클릭 이벤트 로그 처리 방법
데이터 특징
클릭 이벤트 로그는 시계열 데이터다. 5장에서 나왔던 로그 시스템이 수집했던 그 로그 데이터와 마찬가지로 이걸 전문적으로 다루는 DB가 따로 있고 그걸 쓰면 마음이 편안-해질 수 있다. 여기에 더불어 광고 클릭 이벤트이기 때문에 좀 더 신경써줘야 할 부분이 있는데, 바로 집계 및 모니터링을 위한 데이터 가공이다. 5장에서는 이 부분을 ‘상용 소프트웨어한테 맡기면 ok~~’라고 하며 넘어갔는데, 이번 장에서는 아주아주 조금 더 발을 담가본다.
정의: ‘잘’ 처리하는 것
광고 클릭 이벤트 로그를 ‘잘’ 처리해보자. 잘 한다의 기준이 뭘까? 일단 이 서비스를 쓰는 사람들에게 데이터를 적절한 형태로 가공해서 보여줄 수 있어야 한다.
- 지난 M분동안 각
ad_id에 발생한 클릭 수 집계 - 지난 M분동안 가장 많은 클릭이 발생한 상위 N개
ad_id목록 반환 - 다양한 속성을 기준으로 집계 결과를 필터링하는 기능 지원
사용자가 대시보드에 접근할 때마다 이 집계를 만들어낸다고 가정해보자. 1초당 수만, 수백만, 혹은 그 이상의 트래픽이 들어오고 그걸 다 저장하고 있다면 위 요구사항에 따라 집계하는데만 한 세월이 걸릴 것이다.
우리는 데이터를 적절하게 가공하되, 빠른 속도와 높은 정확도를 보장해야 한다.
저장 방법
데이터 중복 저장
로그 데이터를 그대로 저장하는 원시 데이터 DB와 그걸 가공한 집계 결과 데이터 DB가 등장한다. 큰 그림에서 각각 raw data, 집계된 데이터로 표시된 데이터베이스다. 왜 이걸 두개 다 저장할까? 둘 다 장단점이 있는데 둘 다 저장하면 상호보완이 되기 때문이다.
- 원시 데이터만 저장하면
- 👍: 원본 데이터를 손실 없이 보관할 수 있다. 데이터 필터링 및 재계산을 할 수 있다.
- 👎: 데이터 용량이 막대하다. 따라서 조회 쿼리 성능도 낮아진다.
- 집계 데이터만 저장하면
- 👍: 데이터 압축을 통해 용량을 절감할 수 있다. 조회 쿼리 성능이 높아진다.
- 👎: 데이터가 손실될 수 있다. 원본 데이터가 아닌 한 번 압축/집계된 데이터이기 때문이다.
평소 대시보드에 노출할 데이터를 가져올 때에는 집계 결과 DB를 찾아간다. 네트워크를 통해 건너가는 데이터가 유실되거나 중복으로 전송되는 등 잘못된 데이터가 발생했다는걸 감지하기 위해 배치성 애플리케이션을 돌려 데이터 조정 작업을 해준다. 이 때 ‘잘못된 데이터’임을 판단하기 위한 기준은 원시 데이터가 저장된 DB가 된다.
시점
그렇다면 언제 원시 데이터를 가공해서 저장하면 좋을까? 만들기에 따라 다르겠지만 책에서 말하는 최적의 방법은 메세지 큐를 사용해 새로운 로그가 들어올 때마다 비동기적으로 처리하는 것이다.
어차피 실시간으로 가공할거면 중간에 메세지큐는 왜 넣었을까? 로그를 던지는 쪽과 그걸 받아서 처리하는 쪽의 처리량 차이가 있을 수 있기 때문이다. 아니, 있는게 일반적이라고 보는게 맞을 것 같다. 사용자 TPS가 1만, 2만, 3만으로 점점 늘어나는 상황에서 실시간으로 그만큼의 처리량을 보장하는 시스템은 내가 알기론 없다. 받는쪽 최대 처리량이 초당 2만건인데 갑자기 3만건이 되었다고 해서 그 서버가 알 수 없는 미지의 힘을 발휘해 서버가 폭발하지 않고 갑자기 초당 3만건까지 처리할 수 있게 되는 경우는 없단말이다.
서로 다른 일을 하고, 서로 다른 프레임워크에서 동작하는 두 서버의 처리량을 완전히 동일하게 일치시킬 수는 있겠지만 굳이 그렇게 할 필요는 없다. 대신 아파치 카프카 같은 메세지큐를 도입해서 중간에 잠깐 메세지를 저장해놓고, 받아가는 쪽의 처리량에 맞게 메세지를 던져주도록 하는게 좀 더 유연하고 합리적이다.
실제로 카프카 → 로그스태시 → 엘라스틱서치 구조에서, 샤딩 설정을 안 해서 ES 성능이 안 나오는 상황에는 카프카 lag 이 많이 쌓이다가 샤딩 설정을 제대로 하니 다시 lag 이 해소되는 경험을 한 적이 있다. 만약 카프카가 없었다면 밀려드는 트래픽을 감당 못하고 로그스태시든 ES든 터지고 말았을 것이다.
더 알아보기
맵리듀스
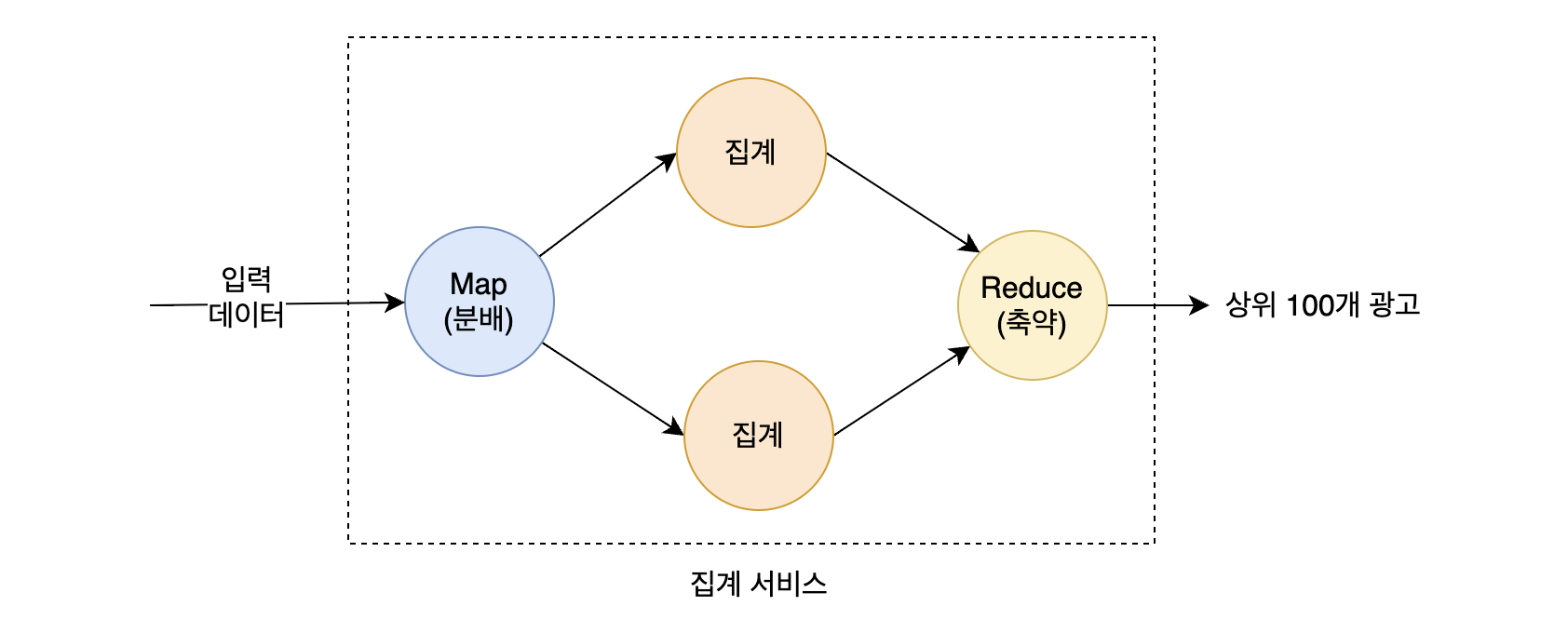
책에서는 집계 데이터를 만들기위해 맵리듀스라는 기법을 사용한다. 궁금하니까 좀 더 알아보자.
“MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.”
= Map 연산 + Reduce 연산 (함수형 프로그래밍의 그 map, reduce 에서 착안된 모델이 맞다.)
= Map 연산(filtering, sorting) + Reduce 연산(summary operation)
그러니까 이번 장에다 적용시키면 이렇게 동작한다. 아래는 지난 1분간 가장 많이 클릭된 광고 3개를 뽑아내기 위해 Map Reduce를 사용한 그림이다.
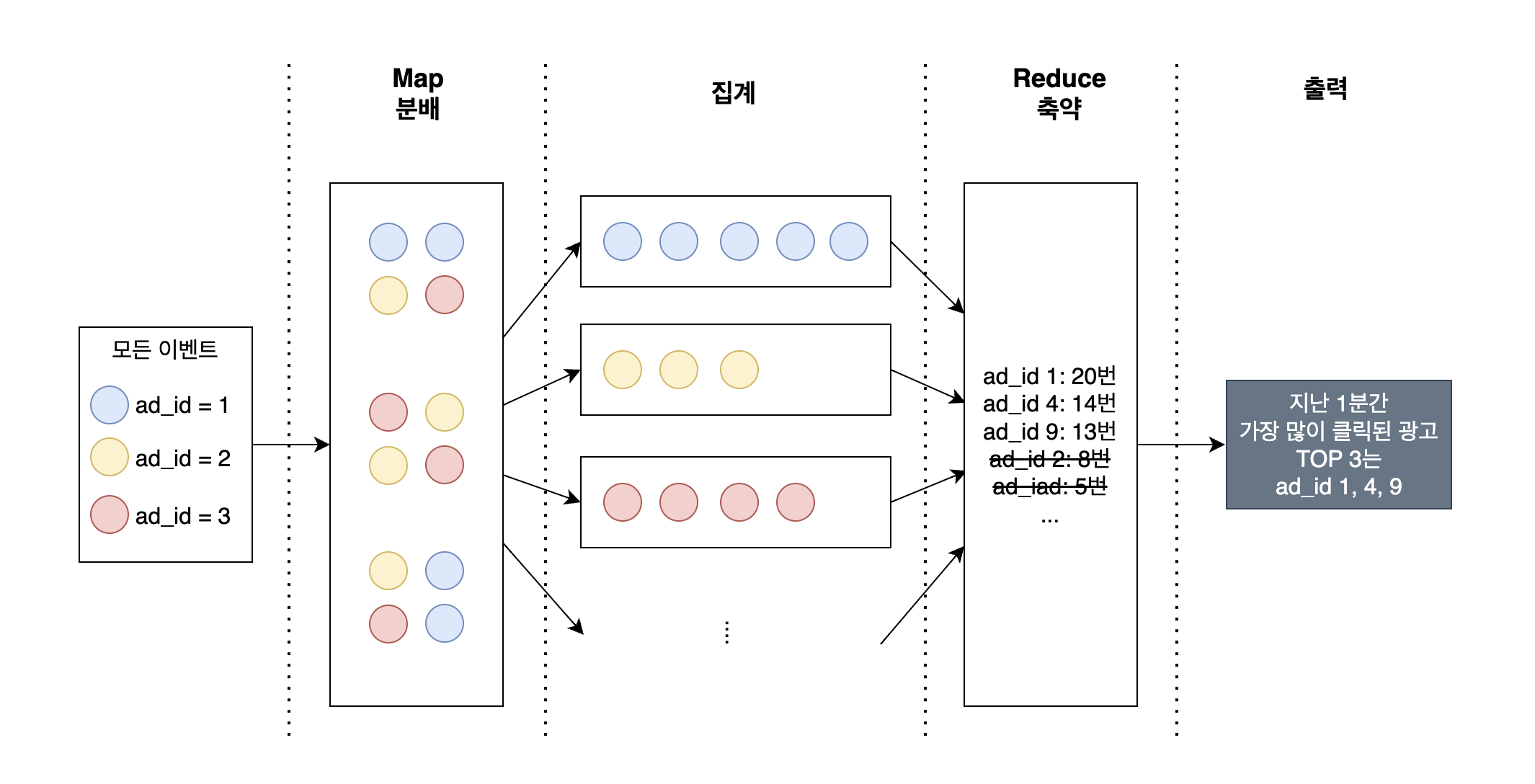
단, 맵리듀스 방식은 대규모 데이터를 분산 + 병렬 + 제대로 된 셔플 처리 할 때 효과가 있다. 싱글 스레드 환경에서는 맵리듀스를 써봤자 그냥 전통적인 방식으로 처리하는거랑 성능이 비슷하다고 한다.
The use of this model is beneficial only when the optimized distributed shuffle operation (which reduces network communication cost) and fault tolerance features of the MapReduce framework come into play. Optimizing the communication cost is essential to a good MapReduce algorithm.
맵 노드가 필요한 이유
그런데 과연 맵 노드는 필수일까? 카프카 파티션이나 태그를 구성한 다음에 집계 노드가 카프카를 직접 구독하도록 하면 안 되는걸까? 에 대한 대답이다.
1. 입력 데이터를 정리하거나 정규화해야 하는 경우에는 맵 노드가 필요하다.
2. 데이터가 생성되는 방식에 대한 제어권이 없는 경우에는 동일한 ad_id를 갖는 이벤트가 서로 다른 카프카 파티션에 입력될 수도 있기 때문이다.
집계 노드의 정체
맵리듀스 패러다임에서 사실 집계 노드는 리듀스 프로세스의 일부이다.
왜냐하면 맵 프로세스는 데이터를 그룹으로 묶어서 나누는 역할을 하고, 리듀스 프로세스에서 그 나눠진걸 합치는 연산을 하기 때문이다. 집계 노드에서는 맵 노드에서 나눈 데이터를 요약하는 역할을 하기 때문에 리듀스 단계의 일부라고 보는 것 같다.
일반적인 이야기
올바른 데이터베이스를 선택하려면 다음과 같은 사항을 평가해 보아야 한다.
- 데이터는 어떤 모습인가? 관계형 데이터인가? 문서 데이터인가? 아니면 이진 대형 객체(Binary Large Object, BLOB)인가?
- 작업 흐름이 읽기 중심인가 쓰기 중심인가? 아니면 둘 다인가?
- 트랜잭션(transaction)을 지원해야 하는가?
- 질의 과정에서 SUM이나 COUNT 같은 온라인 분석 처리(OLAP) 함수를 많이 사용해야 하는가? - 6장 2단계: 개략적 설계안 제시 및 동의 구하기
→ DB 선택 과정에서는 데이터의 형태, 작업 흐름, 필요한 연산에 대해 생각해봐야 한다.
동기식 시스템의 경우, 특정 컴포넌트의 장애는 전체 시스템 장애로 이어진다. - 6장 2단계: 개략적 설계안 제시 및 동의 구하기
세 가지 유형의 시스템 비교 - 6장 3단계: 상세 설계
| 서비스 (온라인 시스템) | 일괄 처리 시스템 (오프라인 시스템) | 스트리밍 시스템 (준실시간 시스템) | |
|---|---|---|---|
| 응답성 | 클라이언트에게 빠르게 응답 | 클라이언트에게 응답할 필요 없음 | 클라이언트에게 응답할 필요 없음 |
| 입력 | 사용자의 요청 | 유한한 크기를 갖는 입력. 큰 규모의 데이터 | 입력에 경계가 없음. (무한 스트림) |
| 출력 | 클라이언트에 대한 응답 | 구체화 뷰, 집계 결과 지표 등 | 구체화 뷰, 집계 결과 지표 등 |
| 성능 측정 기준 | 가용성, 지연 시간 | 처리량 | 처리량, 지연 시간 |
| 사례 | 온라인 쇼핑 | 맵리듀스 | 플링크(Flink) |
