- (가상 면접 사례로 배우는 대규모 시스템 설계 1 시리즈 바로가기)
- 가상 면접 사례로 배우는 대규모 시스템 설계 2 - 5장. 지표 모니터링 및 경보 시스템
5장. 지표 모니터링 및 경보 시스템
이번 장에서는 서버의 여러가지 지표를 수집하고 알림을 주는 시스템을 설계해본다.근데 이제 이미 다 만들어져있는... 서버 지표는 크게 두 종류로 나눌 수 있다. 애플리케이션 레벨과 인프라 레벨이다. 애플리케이션 로그는 엑세스 로그나 에러 로그와 같이 네트워크 레이어 7(L7)에서 일어나는 지표를, 인프라 로그는 메모리 및 CPU 사용량 등의 지표를 의미한다.
지표 모니터링 시스템은 서버가 죽어도 멀쩡하게 살아남아서 데이터를 처리할 수 있어야 한다. 물론 지표 모니터링 시스템 자체가 죽을 수도 있기 때문에 이를 방지하기 위해 수평적 규모 확장, 이중화 등의 장치가 필요하다.
데이터 접근 형태
언제나 그랬듯, 책에서는 지표 데이터에 접근하는 형태를 먼저 생각해본다. 지표 데이터에는 write 가 read 보다 압도적으로 많이 발생한다. 밀리초 단위로 수많은 트래픽이 발생하더라도 실시간으로 지표 데이터를 잘 수집하는게 이 서비스의 미션이다. 데이터 read는 관리자가 알림을 받거나 취미 삼아서 모니터링 UI에 접근할 때, 그리고 경보 시스템이 데이터를 읽을 때 일시적으로 많이 발생할 것이다. 정리하자면 write는 빈번하게 일어나고 read는 spike 형태로 나타난다.
시계열 데이터 모델 101
모든 시계열 데이터는 다음 정보로 구성된다.
| 이름 | 자료형 | 예시 |
|---|---|---|
| 지표 이름 | 문자열 | http_error_count |
| 태그/레이블 집합 | <키:값> 쌍의 리스트(List) | {”method”:”POST”, “url”: “/v2/test”} |
| 지표 값 및 그 타임스탬프의 배열 | <값, 타임스탬프> 쌍의 배열(Array) | [”10, 1999283472”, “0, 19999284877”, “29, 1999285863”] |
큰 그림
지표 모니터링 및 경보를 위해 시스템을 크게 다섯 부분으로 나눌 수 있다.
- 데이터 수집
- 데이터 전송
- 데이터 저장소
- 경보 시스템
- 시각화 시스템
각 지표 서버에서 보내는 지표는 지표 수집기를 통해 데이터 저장소로 들어가고, 경보 시스템과 시각화 시스템이 질의 시스템을 통해 데이터 저장소의 정보를 조회하는 형태다.
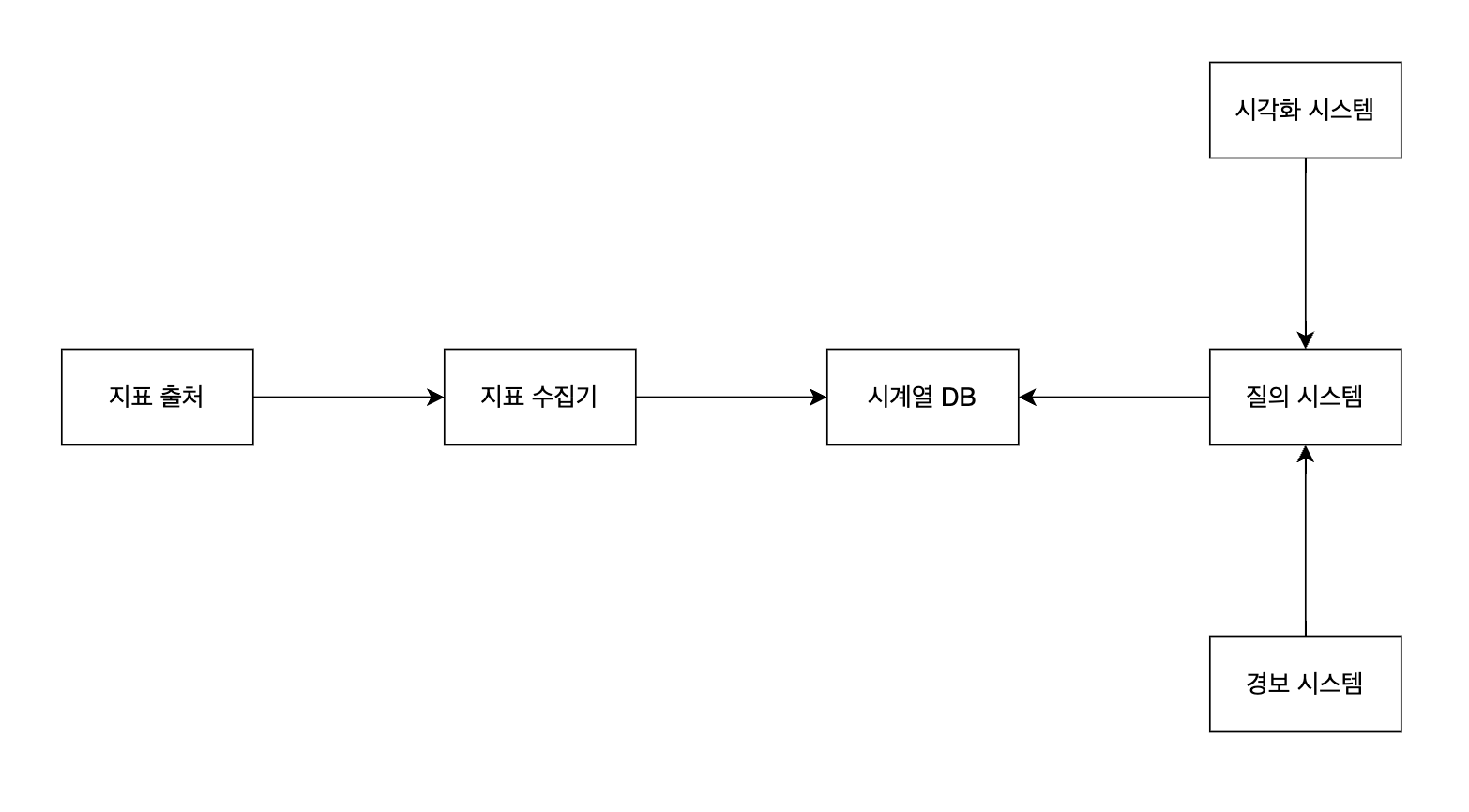
이번 글에서는 지표 모니터링을 효과적으로 하기 위해 위 그림을 어떻게 발전시킬 수 있는 지 정리할 것이다. 화살표 몇 군데를 고치고 몇 가지 요소를 추가하면 이런 그림이 된다.
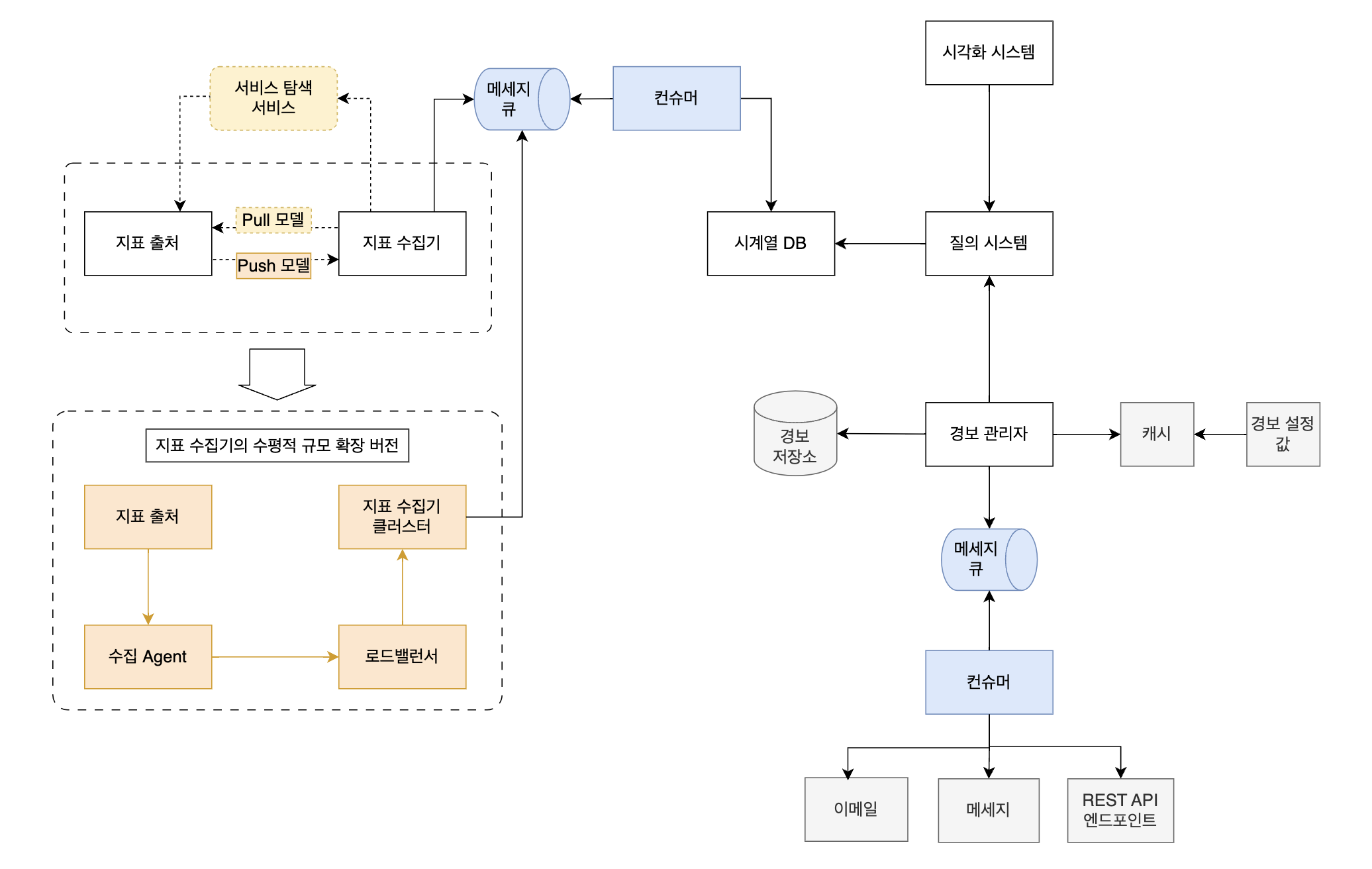
한 눈에 이 그림을 이해할 수 있으면 좋겠지만 그러지 않아도 괜찮다. 한 부분씩 떼어내서 살펴보자.
큰 그림 뜯어보기
다양한 지표 출처
지표 출처는 여러가지 형태가 될 수 있다. 웹서버나 API서버와 같은 애플리케이션 서버가 될 수도 있고, 데이터베이스 서버나 메세지큐 서버가 될 수도 있다.
지표 출처가 메세지큐인 경우는 그 메세지큐 자체가 궁금할 때일 수도 있고, 메세지큐가 메세지를 받아오는 그 이전 서버가 궁금할 때일 수도 있다. 예를 들어 스프링 서버가 남기는 로그를 좀 더 견고하게 전송하기 위해 카프카를 사용할 수 있다. 자신의 지표를 전송하려는 서버와 지표 수집기 사이에 메세지 큐를 두면 메세지 유실 가능성을 줄이고 좀 더 유연하게 지표를 전송할 수 있다. 여기서 서버의 부하를 좀 더 줄이려면 Filebeat 파일비트를 사용할 수도 있다. (이 내용은 주제에서 약간 벗어나기 때문에 더이상 길게 적지는 않겠다.)
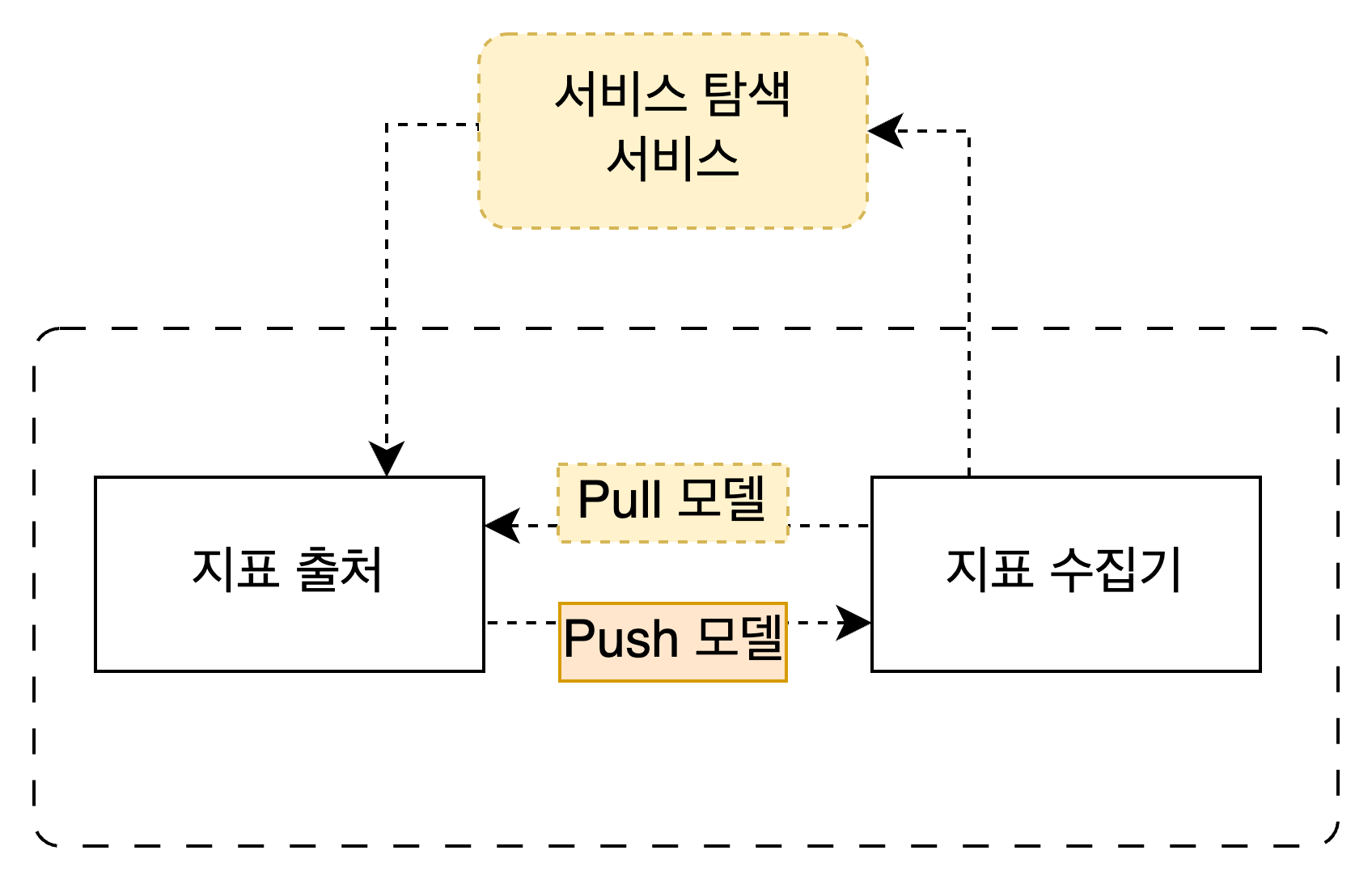
지표 수집기: Pull 모델과 Push 모델
지표 수집기가 데이터를 확보하는 방법은 2가지가 있다. 하나는 지표 수집기가 서버에게 데이터를 요청해서 가져오는 것이고, 다른 하나는 서버가 지표 수집기로 직접 데이터를 밀어넣어주는 것이다. 전자는 Pull 모델, 후자는 Push 모델이다.
둘 중 어떤 모델이 뛰어난지는 가릴 수 없다. 실제로 엔터프라이즈 수준의 지표 수집기 서비스 중에는 pull 모델을 쓰는 것도 있고 push 모델을 쓰는 것도 있다. 책에서는 두 모델의 장단점을 health check, 네트워크 구성, 데이터 신빙성 등 여러가지 측면에서 비교한다.
- pull 모델: Prometheus 프로메테우스
- push 모델: Amazon CloudWatch 아마존 클라우드와치, Graphite 그래파이트
큰 그림에서 Pull 모델을 사용하는 경우는 노란색, Push 모델을 사용하는 경우는 주황색으로 표시했다. 이제 각 모델을 어떤식으로 발전시킬 수 있는지 살펴보자.
Pull 모델 발전시키기: 서비스 탐색 서비스
- '서비스 탐색 서비스' 라니. 정체가 무엇인가?
- 서비스 탐색 "서비스"다. 일단 추상화된 특정 기능을 수행하는 서버다.
- 그렇다면 무슨 기능을 수행하는가?
- '서비스 탐색' 서비스다. 즉, 다른 서비스를 찾아내는 역할을 한다.
- 이게 대체 왜 필요한가?
- Pull 모델에서 이 서비스가 필요하다.
- 지표 출처가 여러개인 경우를 위해서다. 대규모 트래픽을 받는 서버는 보통 수평 분산되어 있고 하나의 엔드포인트로 묶여 있다.
- 일시적으로 몰려드는 트래픽을 수용하기 위해 잠깐 확장을 한 뒤 트래픽이 빠지면 다시 축소시키는 등 서버가 수시로 추가/삭제될 수 있다.
- 우리가 하고싶은건 그 엔드포인트 하나의 지표만 수집하는게 아니라, 그 뒤에서 실제 트래픽을 받아 처리하는 여러 서버의 지표도 함께 수집하는 것이다.
- 따라서 모든 서버 엔드포인트의 IP 정보와 가용성 등을 트래킹하고 관리하는 서비스가 필요하다.
- 그러면 이건 어떻게 만들 수 있을까?
- 를 고민하기에는 이미 상용화 된 솔루션이 있고 우리에겐 시간이 얼마 없다. (아직 지표 수집기 부분도 다 뜯어보지 못했다!)
- 책에서는 etcd, Apache ZooKeeper 를 언급했다. (실제로도 많이 쓰인다. 특히 etcd는 k8s 에서 pod 목록을 관리하기 위해 사용한다.)
∴ Pull 모델에서 지표 수집기가 어느 서버에게 데이터를 요청해서 가져올 지 알아내기 위해 서비스 탐색 서비스가 필요하며, 상용 서비스로는 etcd 와 아파치 주키퍼가 있다.
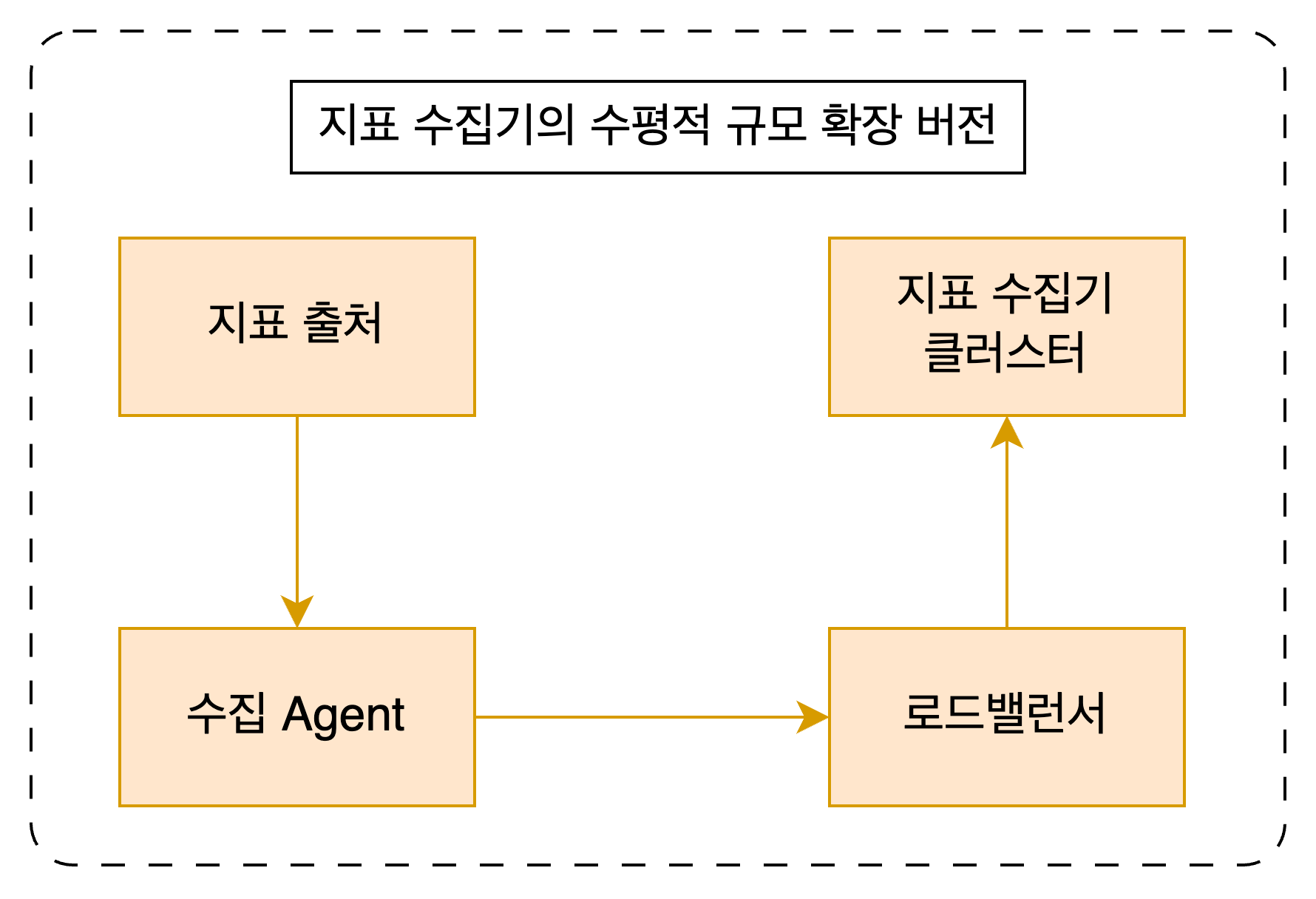
Push 모델 발전시키기: 수평적 규모 확장
Push 모델에서는 조금 다른 고민을 하게 된다. 대규모 트래픽을 감당하는 서버에서 몰려드는 대규모 지표를 지표 처리기는 어떻게 처리해야 좋을까? 당연히 지표 수집기 서버가 하나만 있으면 엄청난 부하가 생기고 시스템은 제대로 동작하지 못할 것이다. 수직적 규모 확장 방식은 언제나 한계에 부딪히기 마련이고 비용도 많이 든다.
그보다는 서버 여러대를 두고 하나의 엔드포인트로 묶어주는 수평적 규모 확장 방법을 택하는게 좋다. 지표를 수집하는 Agent를 따로 두고 여기로 지표를 보내게 한다. Agent 에서는 여러 서버로 구성된 지표 수집기 클러스터로 통하는 로드밸런서에게 데이터를 보낸다. 지표 수집기가 필요한만큼 서버를 더 늘리기만 하면 된다.
∴ Push 모델에서 대량 트래픽을 처리하기 위해서는 수평적 규모 확장을 생각해볼 수 있다.
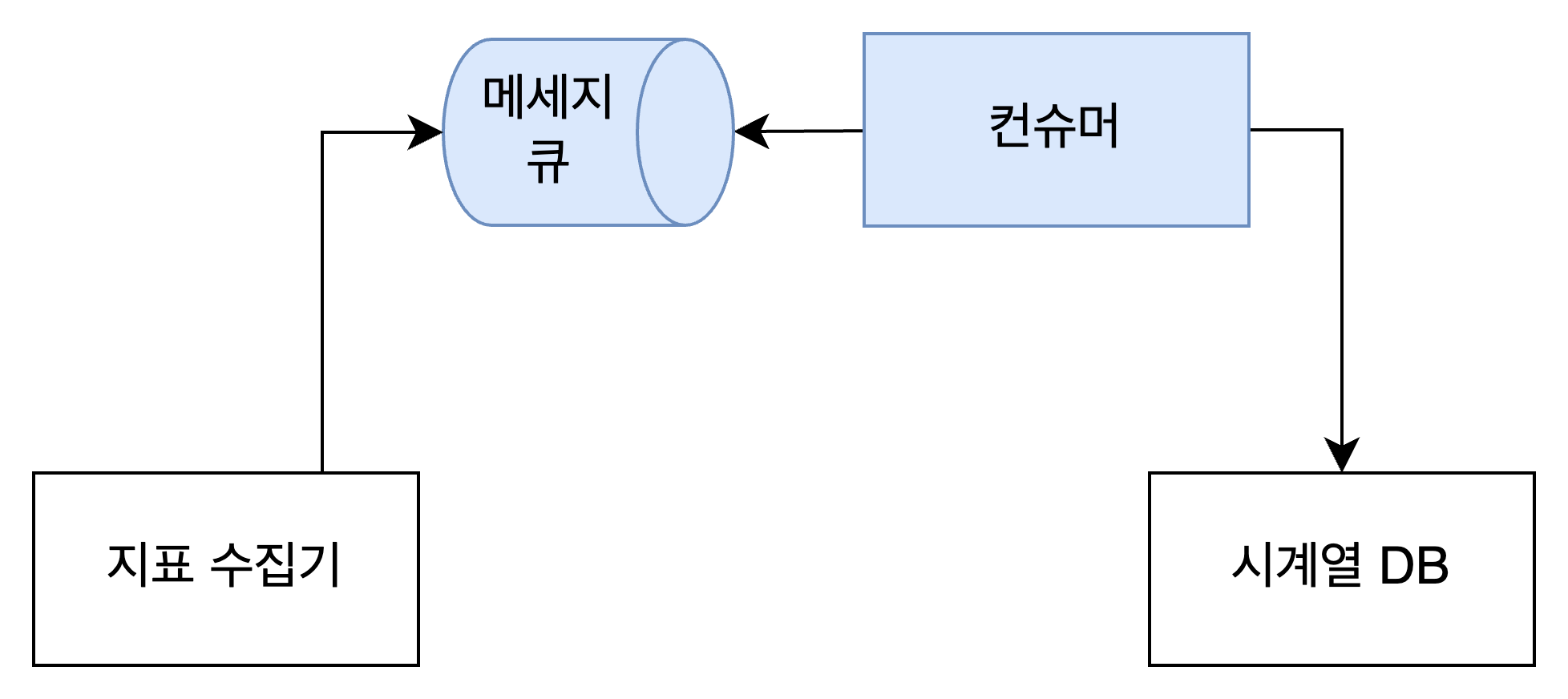
지표 전달: 메세지 큐
이렇게 수집한 지표를 데이터베이스에 저장해야 한다. Push 모델을 쓰든 Pull 모델을 쓰든, 지표 데이터가 아주 많이 들어온다는건 알겠다. (책에서는 일간 능동 사용자 수 1억명, 서버 풀 1천개, 풀 당 서버 100개로 로잡 고있다. 그냥.. 엄청 많다.) 이걸 그냥 하나씩 DB에 때려넣다가는 아무리 성능 좋은 데이터베이스라고 해도 문제가 생길 것이다. 부하가 너무 많아서 유실되는 데이터가 있을 수도 있다.
이럴 때 지표 수집기와 데이터베이스 중간에 메세지 큐와 컨슈머를 두는게 좋다. 지표 수집기는 한 번에 N개씩, 혹은 M초마다 한 번씩 지표를 한꺼번에 모아서 메세지 큐로 전송한다. 컨슈머도 메세지를 하나씩 소비하지 않고 한 번에 여러개씩, 혹은 몇 초 간격으로 메세지를 소비해서 데이터베이스에 넣는다. 네트워크 연결 비용을 최소화하고 부하를 줄이기 위함이다. 물론 몇 개씩 혹은 몇 초씩 묶어서 보내야 할지는 트래픽에 따라 다르고, 운영해보면서 적정한 수치를 찾아가게 된다.
메세지큐를 두면 단순히 부하를 줄일 수 있는 것뿐만 아니라 메세지 유실 가능성도 줄여준다. 컨슈머가 DB에 넣는데 실패한 데이터가 생기더라도 그냥 없어지지 않기 때문이다. 컨슈머가 메세지 큐에서 다시 데이터를 읽어들이면 된다.
지표 저장: 시계열 데이터베이스
지표 데이터를 저장하기 위해 고려해야 할 특성을 알아보자.
- 시계열 데이터 형태로 저장된다.
값 집합에 타임스탬프가 붙은 형태로 기록한다는 뜻이다.(163p.)
- 특정 태그나 레이블에 대한 질의를 빠르게 할 수 있어야 한다.
- 예) 초당 CPU 사용량,
GET /v1/testAPI 요청 이력 중 특정 시간대에 발생한 5xx 에러의 비율
- 예) 초당 CPU 사용량,
- 앞서 살펴봤듯이 연산은 write가 압도적으로 많이 일어나고 read는 특정 시점에 spike된다.
이런 특징 때문에 책에서는 저장소 시스템을 직접 설계하거나, 범용 저장소 시스템을 사용하는 선택지 가운데 그 어떤 것도 추천하지 않는다. MySQL이든 NoSQL이든, 범용 데이터베이스를 사용했을 때 시계열 데이터를 처리할 수는 있지만 우리가 원하는만큼의 성능을 이끌어내기가 아주 어렵다고 한다. 또한 이미 시장에 시계열 데이터에 최적화된 저장소는 많이 나와있기 때문에 이런걸 그대로 사용하기를 권장한다. 예시로 OpenTSDB, InfluxDB, Prometheus 가 있다.
또 다른 특성으로, 데이터의 유통기한이 있다는 점이 일반적인 데이터와 다르다.
- 과거의 데이터보다 최근 데이터를 더 자주 조회하게 된다.
페이스북에서 내놓은 연구 논문에 따르면 운영 데이터 저장소에 대한 질의의 85%는 지난 26시간 내에 수집된 데이터를 대상으로 한다.(논문의 1817 페이지 참고)
지표 데이터 양이 워낙 많은데다가 이런 read 패턴을 보이기 때문에 시계열 DB에서는 저장 용량 최적화 기능을 지원한다.
- 데이터 인코딩 및 압축: 데이터를 원본 형식 그대로 저장하지 않고 좀 더 압축된 형태로 저장
- 다운샘플링(downsampling): 데이터의 해상도를 낮춰 용량을 줄임
- 예) 7일 이내 데이터는 샘플링을 적용하지 않고, 30일 이내 데이터는 1분 해상도로 낮추고, 1년 이내 데이터는 1시간 해상도로 낮춰 보관
- 냉동 저장소(cold storage): 잘 사용되지 않는 비활성 상태 데이터를 보관하는 별도 저장소 지원
- 일반 저장소에 비해 저장 비용이 적게 든다.
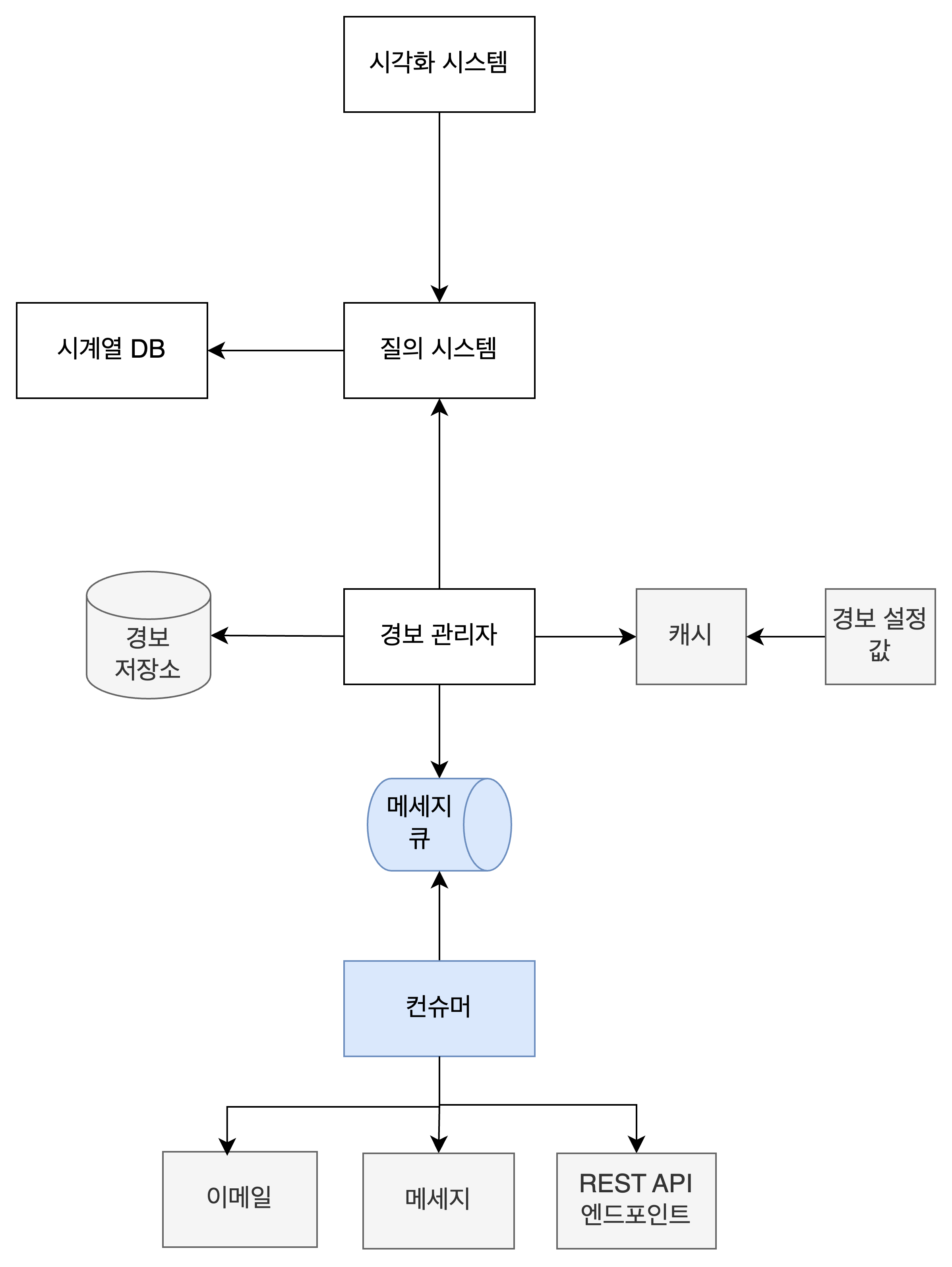
지표 조회/경보 시스템과 질의 시스템
시계열 DB의 데이터를 읽는 서비스는 2개다. 사람이 읽을 수 있도록 지표를 보여주는 시각화 시스템과 실시간으로 이상을 감지하여 알림을 보내는 경보 서비스다. 책에서는 이 두가지 서비스가 곧바로 시계열 DB에 질의를 하지 않고 질의 시스템을 통해 데이터를 조회하는 구조를 만들었다. 이렇게 하면 질의 시스템 내부에 질의 결과에 대한 캐시를 두어서 DB 부하를 낮추고 질의 성능을 높일 수 있다.
하지만 질의 서비스가 필요 없는, 혹은 오히려 있으면 곤란한 경우도 있다. 대부분의 상용 시각화 및 경보 시스템은 이미 시계열 데이터베이스와의 연동을 처리하는 플러그인 기능을 잘 지원하기 때문이다. 이럴 때에는 별도 캐시를 도입할 필요가 없다.
시각화 및 경보 서비스 자체도 상용 서비스를 쓰는걸 권장하고 있다. 대표적으로 Grafana 그라파나가 있는데, https://grafana.com/grafana/dashboards/ 에 들어가면 모니터링하려는 대상의 종류별로 미리 만들어진 지표 대시보드를 제공하고 있다.
경보 관리자쪽을 살짝 살펴보자. 여기서도 캐시를 사용할만한 곳이 있는데 바로 ‘알림을 받을 조건’에 대한 것이다. 어떤 케이스에 알림을 받기로 했는지만 저장하고 나머지 지표 데이터는 캐싱하면 안 된다. 당연히 실시간 데이터를 보고 알림을 전송할 지 말 지 판단해야 하기 때문이다. 대시보드에서 어느 시점에 경보가 울렸는지를 표시하기 위해 ‘경보가 울렸음’을 저장하는 경보 저장소도 따로 있을 것이다. 경보가 발생했다면 이 사실이 유실되지 않도록 중간에 메세지 큐와 컨슈머를 두어서, 알림 전송에 실패하더라도 재시도 할 수 있도록 만들었다.
결론
- 지표 모니터링 및 경보 시스템을 설계할 때, 저장소를 비롯한 여러 구성 요소는 이미 시장에 나와있는 상용 서비스를 활용하는게 좋다.
- 실시간으로 몰려드는 대규모 트래픽을 감당하기 위해 push 모델인지 pull 모델인지는 크게 걸림돌이 되지 않으며 각 모델에 맞는 규모 확장 방식을 선택하면 된다.

예시에서 Graphite하고 Prometheus가 서로 바뀌었네요. Graphite는 push, Prometheus는 pull 입니다.