
7장 분산 시스템을 위한 유일 ID 생성기 설계
이번 글에서 말하는 ‘서버’는 API 서버가 아닌 DB 서버이다.
Auto-increment로는 부족하다
왜냐하면 분산 시스템을 구축하고 있기 때문이다. Auto-increment가 유효한 경우는 단일 서버 환경일 때의 얘기다. 데이터가 추가될 때마다 아이디 값이 그냥 1씩 늘어나기만하면 서버 내의 ID가 서로 겹칠 일이 없다. 하지만 서버가 여러대라면? 각 서버 내에서는 아이디의 유일성이 보장되겠지만 서버 전체 범위에서는 보장되지 않는다.
또 다른 문제가 있다. 분산 시스템을 구축하는 경우는 서버로 들어오는 트래픽이 너무 많아서 수평 확장을 한 경우일 것이다. 따라서 하나의 서버에서 auto-increment 방식으로 생성한 아이디를 나머지 각 서버에 전파해주는 방식도 통하지 않을 것이다. 서버 한 대로는 아이디 생성 요청량을 감당할 수 없을 것이다.
따라서 분산 시스템 환경에서는 아이디의 유일성을 보장해주기 위한 방법도 고민할 필요가 있다. (물론 상용 DB에서 이걸 해주고 있을 것이다. DB를 만드는 개발자가 아니라면 직접 이를 구현할 일은 드물 것 같다. 😇)
유일한 ID를 생성하는 4가지 케이스
Multi-master replication 다중 마스터 복제
다중 마스터 복제는 ID를 생성하는 방법이 아니라, DB 복제 방법의 이름이다. 제목을 ‘4가지 방법’이 아닌 ‘4가지 케이스’라고 적은 이유는 이 부분 때문이다.
다중 마스터 복제 방식에서는 N개의 리더와 M개의 팔로워가 존재한다. 리더가 1개 이상이기 때문에, 쓰기 연산을 할 수 있는 서버가 여러 개다. 책에서 소개한 방법은 다중 마스터 복제 방식에서 auto-increment를 사용하되 1씩 올리지 않고 N씩 올리는 것이다. 예를 들어 복제 서버가 총 3개일 때 서버 1이 관리하는 아이디는 0, 3, 6, 9, …, 서버 2가 관리하는 아이디는 1, 4, 7, 10, …, 서버 3이 관리하는 아이디는 2, 5, 8, 11, … 이 된다. 이렇게하면 auto-increment를 써도 아이디 중복이 일어나지 않는다.
하지만 단점이 있다.
- 서버를 추가/삭제할 경우 N 값이 바뀌기 때문에 잘 동작하기 어렵다.
- ID 값이 시간의 흐름에 따라 커짐을 보장할 수 없다.
- 예를 들어 위 예제에서 데이터 A, B, C가 순서대로 각각 서버 1, 1, 2에 저장된 경우
- A의 아이디: 0, B의 아이디: 3, C의 아이디: 1
- …이 되기 때문에 데이터가 저장된 순서와 아이디 값의 크기가 맞지 않다. 이상적인 경우는 저장된 순서대로 (A의 ID) < (B의 ID) < (C의 ID)가 되는 것이다.
- 예를 들어 위 예제에서 데이터 A, B, C가 순서대로 각각 서버 1, 1, 2에 저장된 경우
Universally Unique Identifier UUID
UUID는 128비트로 구성된 ID로, 여러 버전을 갖는다. UUID 하나에는 어떤 버전으로 생성된 아이디인지 알 수 있는 숫자가 포함되고 그 버전과 variation에 따라 아이디 생성 방법이 다르다. 주로 타임스탬프나 ID를 생성한 서버의 MAC 주소, 호스트 정보 등을 기반으로 만들어지며 아래와 같은 형태를 띈다.
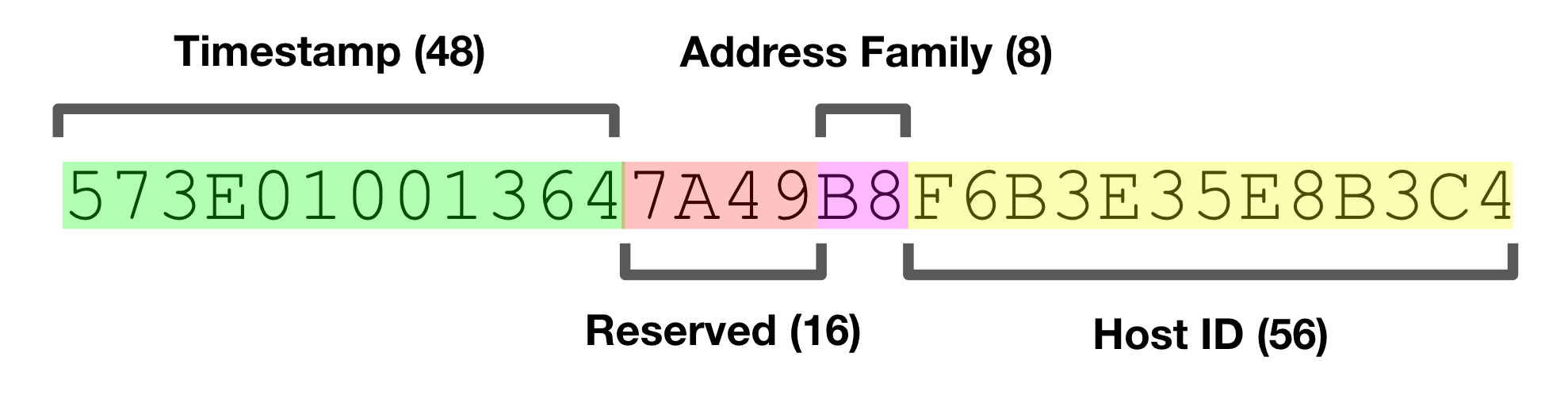
따라서 UUID를 만드는 단순하다. 아이디 하나를 만들기 위해 각 서버끼리 통신할 일이 없다. 그냥 서버 하나에서 만들어내면 끝이다. 또한 이론적으로 UUID값이 중복될 일이 없다. 그래서 분산 컴퓨팅 환경에서 표준으로 채택되기도 했다.
중복 UUID가 1개 생길 확률을 50%로 끌어 올리려면 초당 10억개의 UUID를 100년동안 계속해서 만들어야 한다.
https://en.wikipedia.org/wiki/Universally_unique_identifier#Collisions
하지만 UUID에도 단점이 있다. 일단 아이디 크기가 크다. 128비트이기 때문에 그보다 작은 크기의 아이디가 필요하다는 요구사항은 만족시킬 수 없다. UUID 역시 시간순으로 아이디를 정렬할 수 없다. 또한 아이디에 숫자만 들어가야한다면 UUID는 사용할 수 없다.
Ticket server 티켓 서버
티켓 서버는 초반에 잠깐 나왔던 방식과 같은 방법을 쓴다. 티켓 서버라고 불리는 서버 1대가 auto_increment로 모든 웹서버가 사용할 아이디를 생성하는 것이다. 이 방법도 UUID처럼 구현하기 쉽다. 숫자로만 구성된 ID도 만들 수 있다.
하지만 앞에서 언급했듯이 서비스 규모가 커지면 티켓 서버 하나만으로 모든 아이디 생성 요청을 처리할 수 없게된다. 또한 티켓 서버가 SPOF가 될 수 있다.
Twitter’s Snowflake 트위터의 스노플레이크
책에서 갑자기 왜 트위터의 ID 생성 기법을 콕 찍어 소개하는지 궁금해서 찾아봤는데, 그냥 스노플레이크 ID라고만 쳐도 포스팅이나 발표 자료가 많이 나오는걸로 봐선 꽤 유명한 기법인 것 같다.(따라서 여기서는 ID 생성 방식을 자세히 적지는 않겠다. 타임스탬프와 서버 정보 등을 조합해 만들며 여러 variation이 있다.) 그리고 왜 하필 이름이 스노플레이크인지 궁금해서 찾다가 이런걸 발견했다.
우리는 현재 대부분의 온라인 데이터를 저장하기 위해 MySQL을 사용합니다. 처음에 데이터는 하나의 작은 데이터베이스 인스턴스에 있었으며 차례로 하나의 큰 데이터베이스 인스턴스가되고 결국에는 많은 큰 데이터베이스 클러스터가되었습니다. … 여러 가지 이유로 이러한 시스템 중 상당수를 Cassandra 분산 데이터베이스 또는 수평으로 분할 된 MySQL (Gizzard 사용)으로 교체하기 위해 노력하고 있습니다.
MySQL과 달리 Cassandra에는 고유한 ID를 생성하는 기본 제공 방법이 없습니다.
https://darkstart.tistory.com/147
일단 DB인데 고유 아이디 생성 방식을 기본 제공하지 않는다는 것에 놀랐고, 그게 회사에서 많이 듣던 카산드라라는 것에 두번 놀랐다. 서비스 개발자도 분산 환경에서의 유일 ID 생성 방식을 아예 쓸 일이 없는 건 아닐 것 같다는 생각이 들었다.
결론
분산 시스템에서 유일 ID를 생성하는 기법은 꽤 다양하다. 책에서 다루지 않은 기법도 많을 것이다. 어느 컴포넌트가 그렇듯, 요구사항을 가장 잘 만족시킬 수 있는 방법을 선택하는게 좋을 것 같다.
