
6장. 분산 키-값 저장소 설계
이전에 읽었던 데이터 중심 애플리케이션 설계에서 나왔던 개념이 많이 나오고 있다. 혹시나 데이터 중심 애플리케이션 설계가 좀 무섭게 생겨서 두려운 사람은 이 책을 먼저 읽어보는걸 강력히 추천한다. 나도 이걸 먼저 읽었더라면 머리를 부여잡는 일이 적었을 것 같다. 😇
이번에는 이 장의 첫 파트이자 데이터 중심 애플리케이션 설계에서 주구장창 얘기했던 개념 3가지만 짧게 적어보려한다.
CAP 정리
6장 제목은 분산 키-값 저장소 설계지만, 이 정리는 대부분의 분산 시스템에 적용되는 정리다.
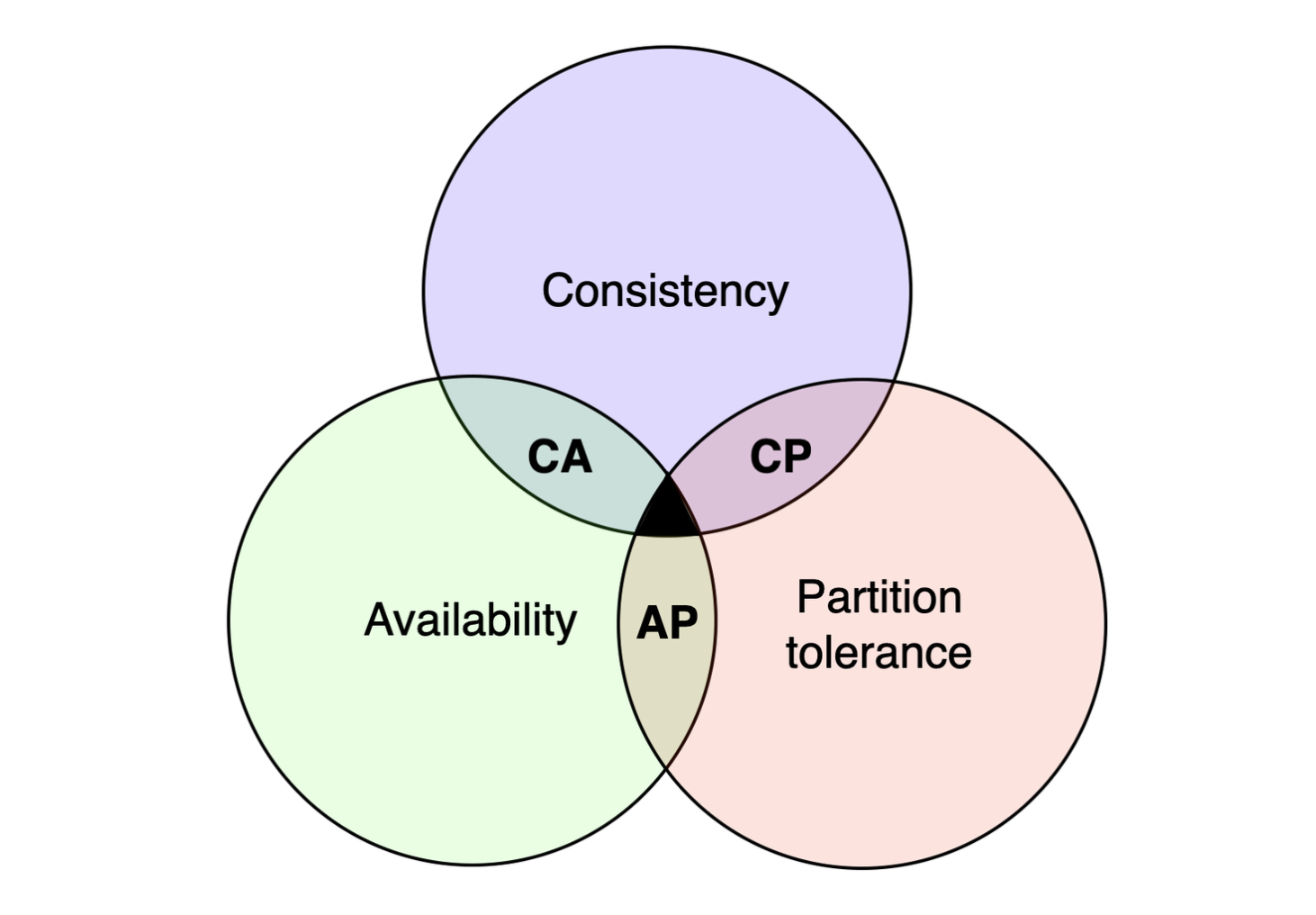
= Consistency, Availability, Partition tolerance 3가지를 동시에 만족하는 분산 시스템을 설계하는 것은 불가능하다는 정리. 즉, 이 정리에 따르면 위 그림에서 가운데 검은 영역에 들어가는 시스템은 존재할 수 없다.
- Consistency 데이터 일관성: 클라이언트가 어떤 노드에 접속했느냐에 관계 없이 언제나 같은 데이터를 봐야 한다.
- Availability 가용성: 일부 노드에 장애가 발생하더라도 항상 클라이언트에게 응답을 줄 수 있어야 한다.
- Partition tolerance 파티션 감내성: 네트워크에 파티션이 생기더라도 시스템은 계속 동작해야 한다.
- Partition 파티션: 두 노드 사이에 통신 장애가 발생한 것.
- DB 샤딩, 파티셔닝 할 때 나오는 그 파티션과는 완전히 다른 개념이다.
따라서 어떤 분산 시스템은 가운데 교집합을 제외한 곳 중 한군데에 위치하게 된다. 하지만 실세계에 존재하는 시스템은 아래 2가지뿐이다.
- CP 시스템: 가용성을 희생하고 일관성과 파티션 감내를 지원한다.
- AP 시스템: 데이터 일관성을 희생하고 가용성과 파티션 감내를 지원한다.
그렇다면 왜 CA 시스템은 존재하지 않을까? CA 시스템은 파티션 감내를 지원하지 않는다. 즉, 네트워크 장애에 대한 내성을 갖지 않는 시스템이다. 하지만 통상적인 네트워크 장애는 우리가 피한다고 피할 수 있는게 아니다. 따라서 분산 시스템은 파티션 문제를 반드시 대응할 수 있도록 설계되어야 하는데, CA 시스템은 이걸 지원하지 않기 때문에 실제 세계에서는 사용되지 않는 것이다.
가용성이나 일관성을 희생한다는게 무슨 소리일까
예를 들어보자. 서버 A, B, C가 있다. 각 서버에 기록된 데이터는 자동으로 나머지 다른 서버에 동기화된다. 즉, 복제가 일어나고 있다. 그런데 만약 네트워크 파티션 문제가 일어났다고 해보자. 서버 C가 죽어서 더이상 A, B로부터 데이터 변경 사항을 전달받을 수 없다. 서버 C만 갖고 있고 아직 A, B로 전달되지 않은 데이터 역시 전파될 수 없다.
이 때 가용성을 희생하고 일관성을 택한 경우에는 더이상 서버에 읽기/쓰기 연산을 할 수 없다. 일관성을 택했다는건 ‘언제, 무슨 일이 있어도 각 서버에 있는 모든 데이터가 동기화 됨’을 보장하겠다는 뜻이기 때문이다. 서버 C가 죽은 상태에서는 데이터 일관성을 유지할 수 없기 때문에 상황이 해결될 때까지 서버는 계속 에러를 보낼 것이다.
일관성을 희생하고 가용성을 택한 경우에는 서버에 연산을 할 수 있다. 즉, 서버가 요청에 대해 정상적으로 반응하면서 ‘사용 가능’한 상태로 남아있을 것이다. 대신 각 서버에 저장된 데이터는 조금씩 다를 것이다. 각 서버는 변경사항을 임시로 들고 있다가 파티션 문제가 해결되면 데이터 동기화를 시작해 다시 일관성을 유지하려 할 것이다. 즉, 어느 특정 시점에는 데이터가 일치하지 않을 수 있기 때문에 일관성을 희생한다는 것이다.
결론
분산 키-값 저장소 역시 분산 시스템이기 때문에 위 3가지 요구사항을 한번에 만족할 수는 없다는 점을 염두에 두자. 언제나 trade-off는 존재한다.
