13장 검색어 자동완성 시스템 설계
검색어 자동완성 기능은 영어로 autocomplete, typeahead 기능이라고도 한다. 언뜻 보기엔 별거 아닌 것 같지만 빠른 속도를 보장하기 위해 제대로 된 설계가 필요하다. 이번 장에서는 검색어 자동완성 시스템 설계를 해본다.
개략적 규모 추정
개략적 규모 추정은 어떤 설계가 요구사항을 만족하는지 보기 위해 시스템 용량이나 성능 등을 계산하는 작업이다. 사실 이전 장에서도 계속 등장했는데, 언제까지 피하기만 할 수는 없어서 이번 장에서는 따라가보기로 했다. 이 부분을 건너뛰어도 자동완성 시스템 구조를 이해하는데는 문제가 없다.
이번 작업에서 대답해야하는 질문은 다음과 같다.
- 초당 몇 건의 질의가 발생할 것인가?
질의가 얼마나 발생할 것인지는 사용자 수에 달려있다. 신규 데이터가 얼마나 추가될지도 사용자의 질의 횟수에 달려있다. 그래서 책에서 가장 먼저 하는 일은 일간 능동 사용자(DAU, Daily Active User)를 천만 명으로 가정하는 것이다. 사용자별로 검색하는 횟수가 다를텐데, 이를 일일이 정할 수는 없으니 평균적으로 사용자 한 명은 매일 10건의 검색을 수행한다고 가정했다.
여기서 조금 더 생각해보자. 사용자가 입력하는 검색어 길이는 서로 다를 것이다. 책에서는 평균적으로 20바이트를 입력한다고 가정한다. 그 근거는 다음과 같다.
- 문자 인코딩 방법으로 ASCII를 사용한다고 가정하면, 1문자 = 1바이트이다.
- 질의문은 평균적으로 단어 4개로 이루어지고, 각 단어는 평균적으로 단어 5개로 구성된다고 가정한다.
- 결론: (단어 4개) * (문자 5개) = (문자 20개) = (20바이트)
이제 위 질문에 대답할 준비가 되었다.
- 초당 몇 건의 질의가 발생할 것인가?
- (DAU 천만명) (매일 일어나는 질의 10건 / 일 / 24시간 / 3600초) (문자 20개) = 약 24000건
- 문자 20개를 다 곱하는 이유는, 사용자가 문자 1개를 입력할 때마다 백엔드로 질의가 전송될 것이기 때문이다.
- (DAU 천만명) (매일 일어나는 질의 10건 / 일 / 24시간 / 3600초) (문자 20개) = 약 24000건
위 과정을 다시 훑어보면 대부분 수치들이 가정이라는 사실을 알 수 있다. 책에 따르면 개략적 규모 추정 작업 자체가 그런 작업이라고 한다. 시스템과 관련된 보편적인 값을 가지고 미래의 일을 예측하는 것이다.
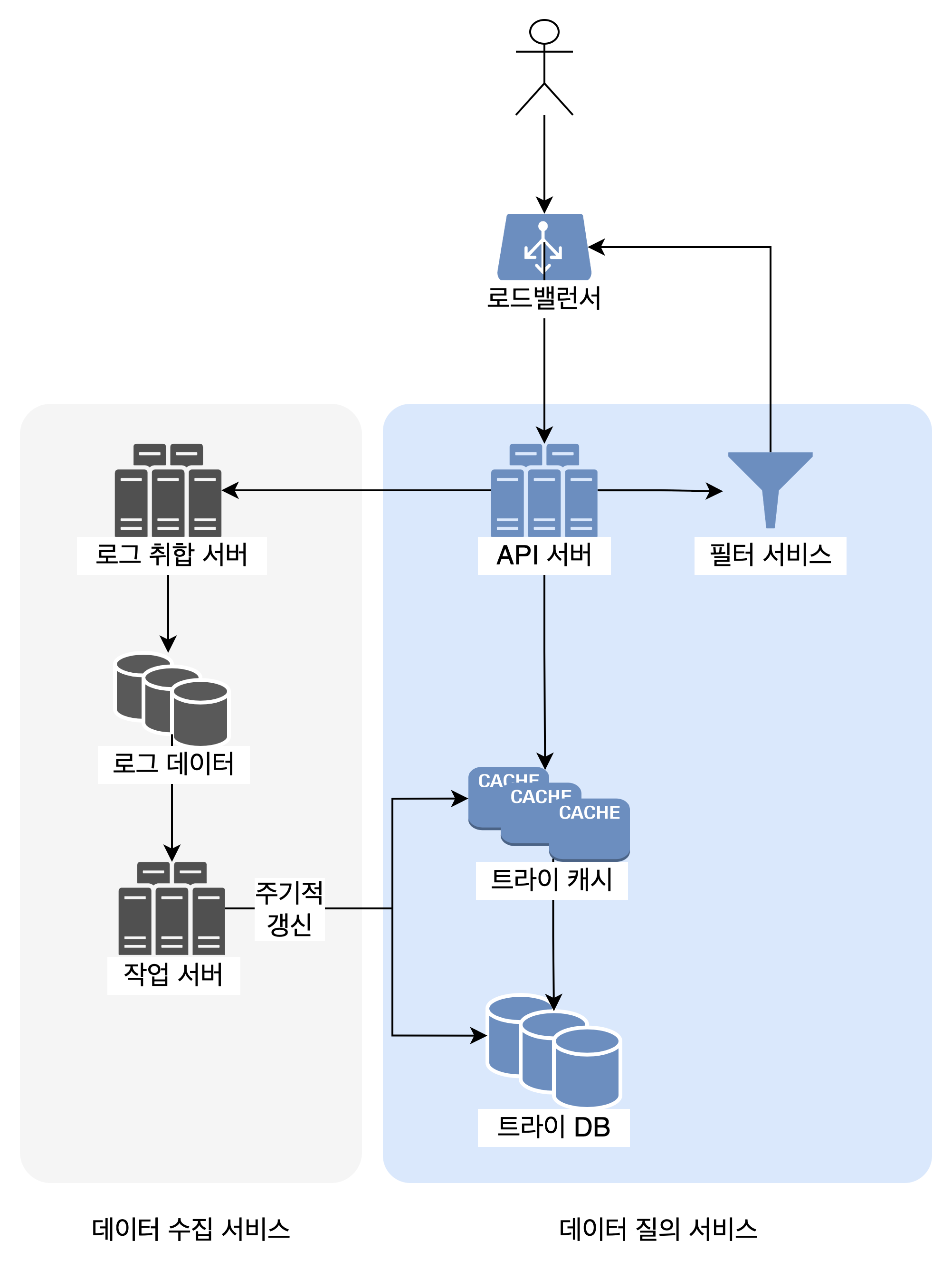
전체 구조
이제 본격적인 설계로 들어가보자. 검색어 자동완성 시스템은 크게 2부분으로 나눌 수 있다.
- 질의 서비스: 사용자의 검색어를 받아서 어떤 검색어를 보여줄지 결정한다.
- 이 때, 사용자가
twitter라는 검색어를 입력한다면 질의 서비스 API는 총 7번 실행되어야 한다.t로 시작하는 단어,tw로 시작하는 단어,twi로 시작하는 단어, …, 마지막으로twitter로 시작하는 단어까지 총 7번이다.
- 이 때, 사용자가
- 데이터 수집 서비스: 사용자가 입력한 검색어를 수집한다.
-
각 검색어별로 몇 번 검색되었는지를 저장한다. 그러니까 이런 테이블이 하나 생길 것이다.
query frequency twich 2 twitter 4 twillo 1
-
하지만 실제로는 데이터를 이런 형태로 저장하지 않는다. 사용자가 문자 1개를 입력할 때마다 DB 검색 연산을 해야하는데, 방대한 데이터를 갖고 수많은 사용자를 커버해야 하는 시스템을 이런식으로 만들 수는 없다. 좀 더 효율적인 방법이 필요하다. 이는 트라이 자료구조로 해결할 수 있다.
세부 컴포넌트
트라이 trie 자료구조
검색어 추천을 어떻게 빠르게 할 수 있을까? 여기서 말하는 검색어 추천이란 ‘사용자 입력을 접두어로 하는 단어 중, 가장 자주 검색된 단어를 보여주는 것’을 의미한다. 대부분 검색어 추천 시스템은 트라이 trie 자료구조를 사용한다.
트라이는 트리 자료구조다. 각 노드에는 1글자 이상의 문자를 저장한다. 노드에 저장되는 문자는 접두어일수도 있고 단어일수도 있다. 트라이 자료구조의 장점과 시간복잡도 등은 구글, 유투브 등에 검색하면 잘 나온다. https://ko.wikipedia.org/wiki/트라이_(컴퓨팅)
트라이는 접두어 트리 prefix tree라고도 한다. 검색어 자동완성 시스템을 만들 때 대부분 트라이를 사용한다. 몇가지 최적화 과정만 거치면 특정 접두어에 대한 인기 검색어 k개를 찾는데 느는 비용이 O(1)이 되기 때문이다.
데이터 수집 서비스
데이터 수집 서비스의 역할은 위에서 본 트라이에 들어갈 데이터를 모으고 분석하는 것이다. 그렇다면 ‘사용자가 twitter를 검색하면 트라이가 7번 갱신되겠군.’ 이라고 생각하기 쉽다. 하지만 이 방식은 별로 실용적이지 않다. 매일 수천만건의 질의가 입력될 것이기 때문이다. 또한 책 내용에 따르면 “일단 트라이가 만들어지고 나면 인기 검색어는 그다지 자주 바뀌지 않을 것이다.”
자주 바뀌지 않는다는 구체적은 근거는 들어주지 않지만, 생각해보면 그럴듯한 말이긴 하다. 예를 들어 tre까지 입력한 사용자가 갑자기 trexyz, trexxxxxxx, treeeeeeeez 등을 검색할 일은 잘 없을 것이기 때문이다. 즉, 사람들이 사전에도 등록되지 않은 이상한 외계어를 자주 입력할 일은 거의 없을 것이다. 우리가 일상에서 사용하는 말이나 전문용어 등을 검색할 것이기 때문이다. 또한 시대문화별 상황 등에 따라 사람들이 자주 사용하는 단어가 있을 것이고 그 단어들이 주로 검색에 쓰일 것이다.
그래서 책에서는 실시간이 아닌 주기적으로 트라이를 갱신하는 방법을 소개한다.
- 사용자가 검색창에 입력하는 원본 데이터를 보관한다.
- 로그 취합 서버에서 위 데이터를 취합하고
- 작업 서버에서 그 데이터를 보며 매주 트라이를 갱신한다.
- 이와 함께 캐시 계층도 같이 갱신한다.
질의 서비스
질의 서비스는 데이터 수집 서비스가 만든 트라이에 실제로 검색 연산을 보내는 서비스다. 이 서비스는 “번개처럼 빨라야”한다. 이를 위해 책에서는 몇가지 최적화 방안을 제안한다.
- AJAX 요청: 이제는 당연한게 되어버렸다. 대부분 웹 애플리케이션은 AJAX 방식을 쓰고 있고 그 덕분에
twitter라는 검색어를 입력할 때 새로고침을 7번이 아닌 0번 해도 된다. - 브라우저 캐싱: 브라우저에 검색어 제안 결과를 캐싱해놓는 것이다. 구글이 이 방식을 사용한다.
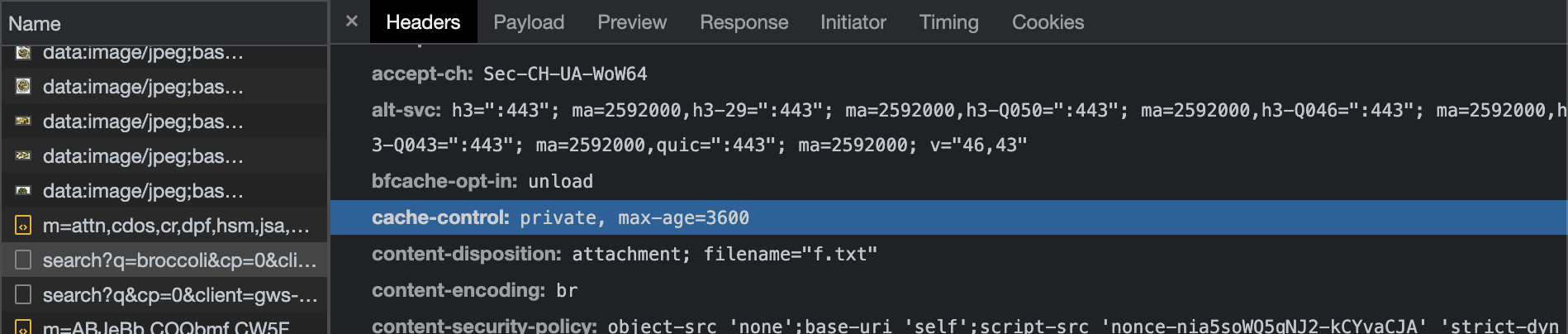
broccoli라는 검색어를 입력했을 때, response header의 cache-control을 보면 1시간동안 캐싱해놓는다는 것을 알 수 있다. 왜인지 모르겠지만max-age가 구글 계정으로 로그인했을 때는 안 보이지만 게스트로 검색하면 보인다.- 시크릿 모드일때도 브라우저 캐싱은 사용하도록 되어있다.
max-age는 똑같이 1시간으로 되어 있었다.
- 데이터 샘플링: 위에서 봤던 데이터 수집 서비스는 사용자의 검색어 로그를 분석하여 트라이를 갱신하는 일을 한다고 했다. 질의가 너무 많을 경우, 모든 로그를 기록하지 않고 N개 요청 중 1개만 골라서 로깅하는 것도 하나의 방법일 수 있다.
결론적으로 서버쪽 최적화만 가능한게 아니라 클라이언트쪽에서도 최적화 기법을 사용할 수 있음을 알 수 있다.
검색어 삭제
혐오성이 짙거나 폭력적인 검색어 등이 검색어 추천 목록에 올라가서는 안 될 것이다. 이를 막기 위해 트라이 캐시와 API 서버 사이에 필터 계층을 둘 수 있다.
결론: 전체 설계도

4개의 댓글

great work
https://mybalncenowguide.cc/mybalancenow-check-your-target-gift-card-balance-now/
https://mykfcexperience.org/mykfcexperience-take-kfc-survey-at-www-mykfcexperience-com/
https://dunkinrunsonyou.xyz/dunkinrunsonyou-take-survey-at-www-dunkinrunsonyou-com/
https://mybkexperience.cc/mybkexperience-take-bk-survey-at-www-mybkexperience-com/
https://getmyoffer.cc/getmyoffer-capitalone-com/
https://mcd-voice.com/mcdvoice-take-the-mcdonalds-review-at-www-mcdvoice-com/
https://getmyoffers.org/getmyoffer-capitalone-com-enter-reservation-number-and-access/

The company was first known as Sanders Court and Cafe; KFC wasn't even a brand name until much later. It was among the first of its kind and mostly catered to foreign tourists.https://mykfcxprience.shop/
very nicely you answered Broccolism. I impressed with your helpful reply.
Mybkexperience