12장 채팅 시스템 설계
서론: 채팅 시스템의 종류
휴대폰에 채팅 어플 하나 없는 사람은 드물 것 같다. 당장 카카오톡만 해도 4500만명이 사용 중이라고 한다. 이번 장에서는 채팅 시스템을 설계해본다. 설계부터 하기 전에 어떤걸 만들지 먼저 정해야 한다. 채팅 시스템의 종류가 다양하기 때문이다.
- 1:1 채팅 시스템: 페이스북 메신저, 위챗, 왓츠앱
- 그룹 채팅 중심 업무용 앱: 슬랙
- 대규모 그룹의 음성 채팅: 디스코드
채팅 시스템의 클라이언트도 다양하다. 만드려는 시스템이 1:1 채팅 앱인지 그룹 채팅 앱인지, 모바일 앱인지 데스크톱 앱인지 등을 정하고 시작할 필요가 있다. 책에서 설계하는 시스템은 1:1과 그룹 모두를 지원하는 채팅 앱이다.
채팅 시스템 큰 그림 그리기
우선 채팅 시스템의 전반적인 내용을 알아보고 상세 설계로 들어가보자. 채팅 시스템의 특징은 다음과 같다.
- 클라이언트는 서로 직접 통신하지 않는다. 대신 채팅 서비스와 통신한다.
- 즉, 내가 친구와 1:1 채팅을 하고 있다면 내가 보낸 메세지는
나 -> 채팅 서비스 -> 친구순서로 전파된다. 곧바로나 -> 친구로 가지 않는다.
- 즉, 내가 친구와 1:1 채팅을 하고 있다면 내가 보낸 메세지는
- 일반적인 API 서버가 필요한 부분이 있고, 그렇지 않은 부분이 있다.
- 채팅 메세지를 처리하는 서버는 일반적인 API 서버와 다르게 동작해야 한다. 낮은 latency를 보장해야 하기 때문이다.
- 나머지 부분(회원가입, 로그인, 프로필 관리 등)은 전통적인 API 서버처럼 동작하면 된다.
- 위 기준에 따라 사용하는 DB의 종류도 달라진다. 자세한 내용은 아래에서 다룰 것이다.
- 3가지 부분으로 나눌 수 있다: 무상태(stateless) 서비스, 상태 유지(stateful) 서비스, 제3자 서비스 연동
- 무상태 서비스: 로그인, 회원가입, 프로필 등 위에서 말한 일반적인 API 서버처럼 동작하는 부분은 무상태 서비스로 설계할 것이다. 수평 규모 확장이 용이하기 때문이다.
- 상태 유지 서비스: 사용자들이 주고받는 메세지를 관리하는 채팅 서비스는 상태 유지 서비스로 만들 것이다. 각 클라이언트가 채팅 서버와 독립적인 네트워크 연결을 유지해야 하기 때문이다.
- 제3자 서비스 연동: 푸시 알림 서비스
전체 흐름 파악하기
사용자가 로그인한 뒤 채팅방에 들어가는 방법
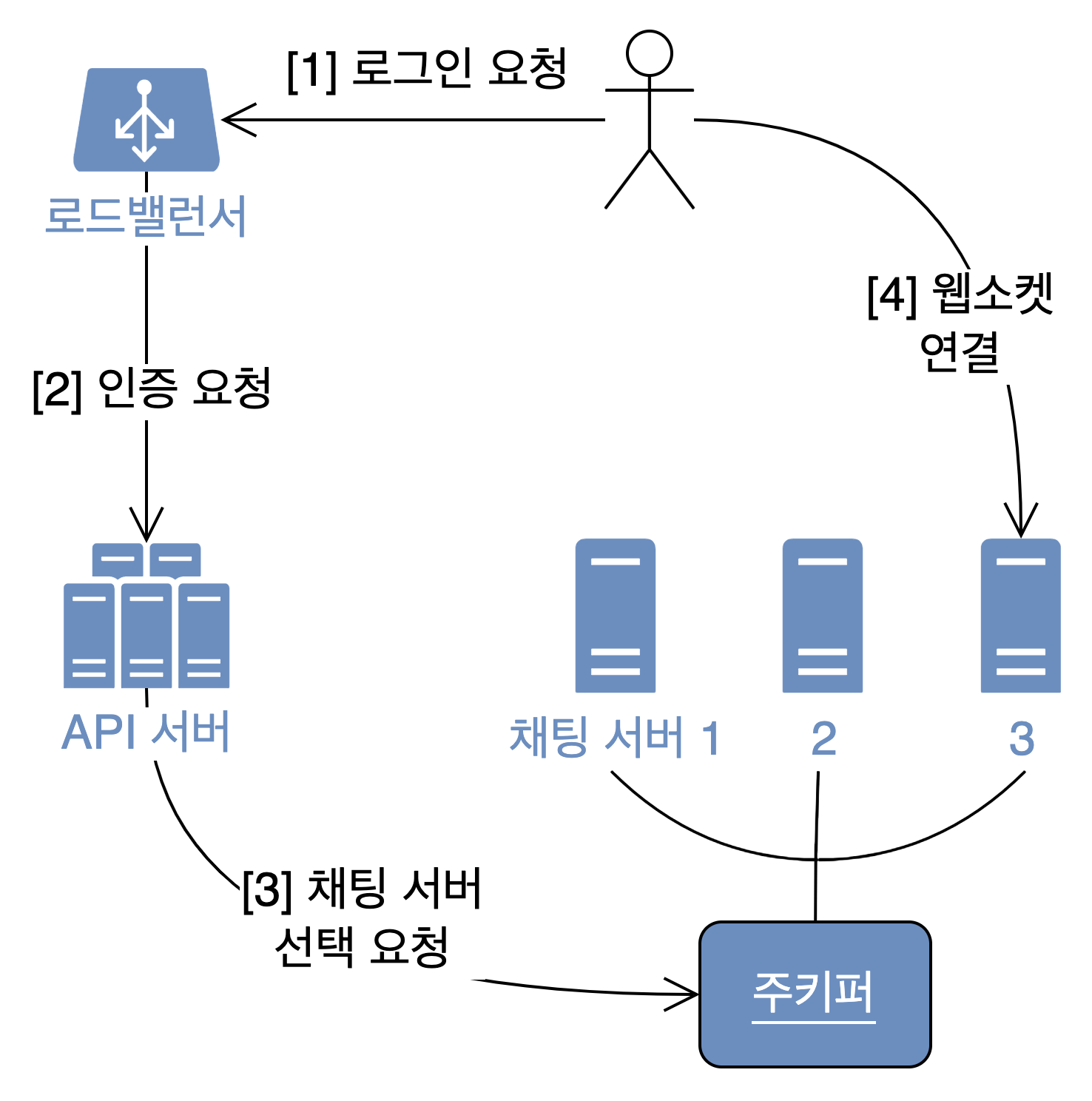
- 사용자는 API 서버로 로그인 요청을 보낸다. 이 때 노출되는 엔드포인트는 사실 로드밸런서의 주소다.
- 로드밸런서에서 API 서버로 로그인 요청이 전달된다.
- 정상 로그인 되었다면, 서비스 탐색(service discovery)용 컴포넌트로 요청을 하나 보낸다. 채팅 서버 여러개 중 어떤 서버에다가 웹소켓 연결을 추가해야 부하가 잘 분산될지 물어보는 것이다.
- 서비스 탐색 기능을 제공하는 가장 대표적인 솔루션으로 아파치 주키퍼(Apache ZooKeeper)가 있다.
- 선택된 채팅 서버로 클라이언트가 직접 웹소켓 연결을 시도한다. 성공적으로 연결 되었다면 채팅방에 들어가기 완료!
1:1 채팅 메세지가 전달되는 방법
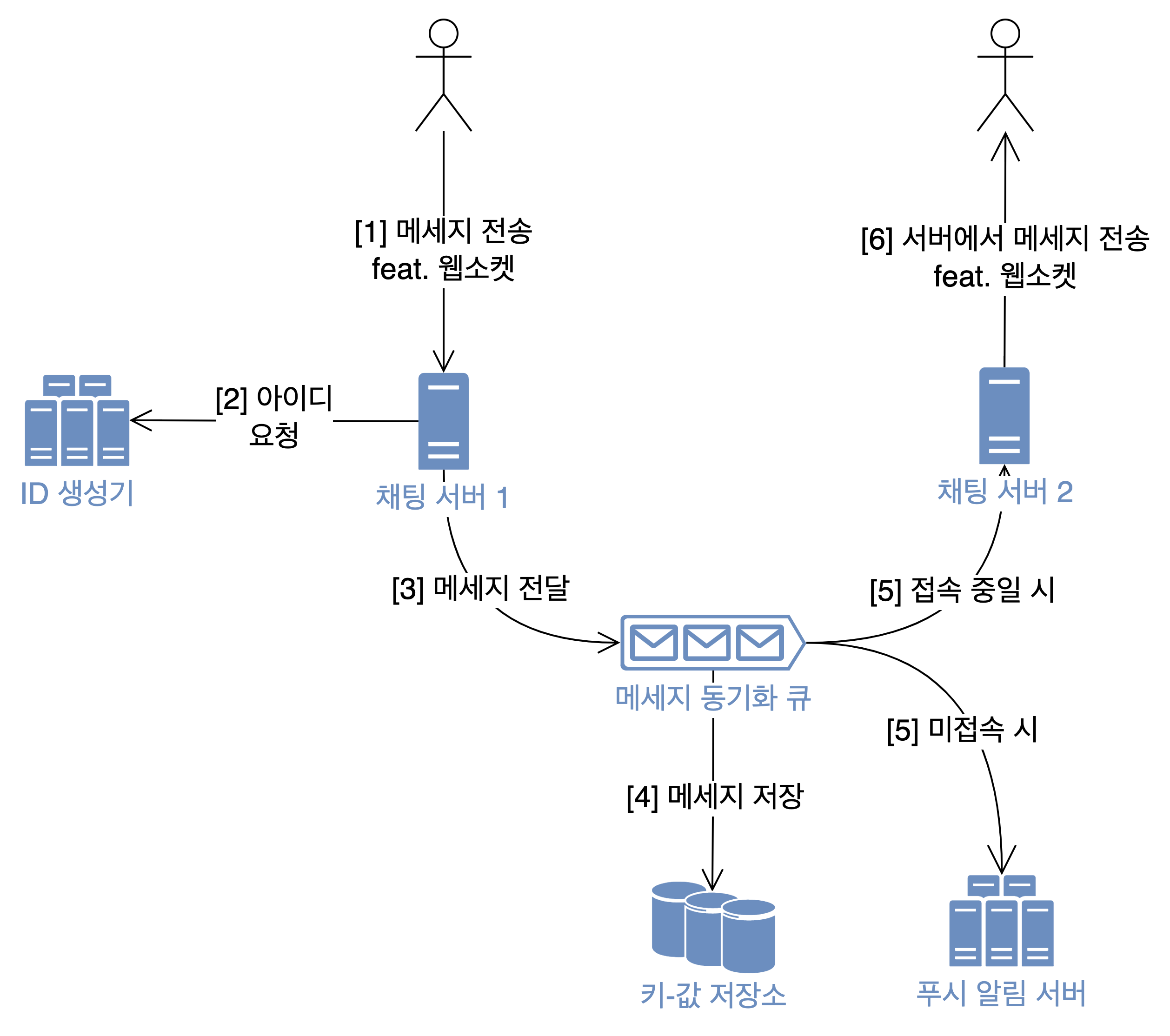
- 웹소켓(혹은 HTTP 요청)을 통해 메세지가 채팅 서버로 전달된다.
- 책 내용으로는 메세지 전송 시에 HTTP를 사용해도 큰 문제가 없다고 하며 HTTP의
keep-alive헤더를 소개하고 있다. 이 헤더에 대해서는 아래에서 더 자세히 나온다.
- 책 내용으로는 메세지 전송 시에 HTTP를 사용해도 큰 문제가 없다고 하며 HTTP의
- 메세지에 붙일 아이디를 생성한다.
- ID를 왜 별도로 생성하는지는 가장 아래 ‘채팅 이력의 ID 관리’에 있다.
- 아이디와 메타 데이터를 추가한 채로 메세지 동기화 큐에 전달한다.
- 키-값 저장소에 메세지를 저장하고
- 동시에 이를 수신자에게도 전파해야 한다.
- 만약 수신자가 접속 중이라면 해당 클라이언트가 웹소켓 연결을 생성한 채팅 서버로 메세지를 전달한다.
- 그렇지않다면 푸시 알림을 주기 위해 알림 서버로 메세지를 전달한다.
- 만약 수신자가 접속 중이라면 채팅 서버로 전달된 메세지가 웹소켓을 통해 클라이언트에게 전송된다.
- 일반적인 HTTP 연결과는 달리 웹소켓 연결이기 때문에 서버에서 먼저 메세지를 보낼 수 있다. (HTTP에서는 항상 클라이언트가 요청을 먼저 보내야 했다.)
소규모 그룹 채팅 메세지가 전달되는 방법
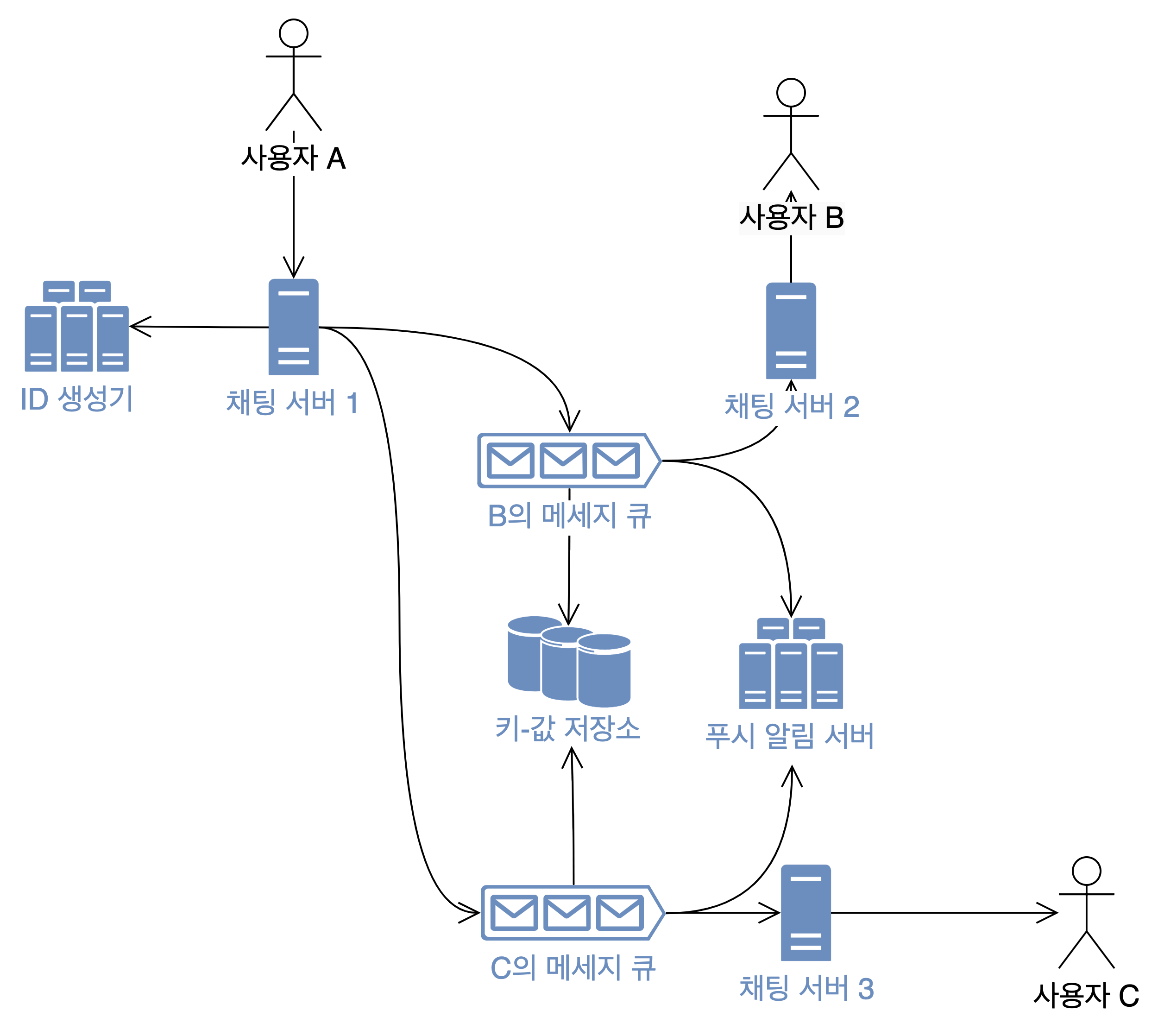
그룹 채팅이라고 해서 크게 다른건 없다. 사용자별로 메세지 큐가 따로 있다는 점만 다르다. 새로운 메세지가 왔는지 읽어야 할 때에는 로직이 간단해진다. 자신의 큐만 확인하면 되기 때문이다. 그러나 누군가 메세지를 1개 보냈다면 그 채팅방에 있는 다른 모든 사람의 메세지 큐로 똑같이 들어가야한다. 메세지 1개에 대한 복제본이 참여자 수만큼 늘어나야하는 것이다.
그래서 이 구조는 소규모 그룹 채팅일 때에 적절하다. 위챗이 이 방식을 쓰고 있는데, 그룹 채팅방의 최대 참여자 수는 500명이라고 한다. 대규모 그룹 채팅일 때 어떤 방식이 좋은지는 아쉽게도 책에 나와있지 않았다.
대신 구글링해보면 라인 기술 블로그의 LINE LIVE 채팅 기능의 기반이 되는 아키텍처라는 글이 나온다. 여기서는 유저 수에 따라 채팅방이 분할되고, 같은 채팅방이라도 여러 서버에 분산될 수 있다. “같은 채팅방이라도 여러 서버에 분산될 수 있다”니, 그럼 메세지가 뒤죽박죽 섞일 수도 있지 않나? 라는 생각이 들었지만 레디스 Pub/Sub 기능을 사용해 동기화를 처리하고 있다고 한다. 이외에도 흥미로운 내용이 많으니 한번 읽어보면 좋을 것 같다.
채팅 메세지 전달 방식
메세지 송신 방식: HTTP keep-alive 헤더
네트워크 상에서 데이터를 전달하는 가장 전통적인 방법은 HTTP 통신이다. 하지만 HTTP 통신 특성상 연결 1개 당 요청 1개만을 보낼 수 있다. 그러니까 우리가 단타로
오늘
밥
뭐
먹을래
?라고 보내면 무려 5개의 HTTP 연결이 생성되어야 하고 handshake도 5번 일어나야 하는 것이다. 이런 무시무시한 일을 막기 위해 keep-alive 헤더가 나왔다. 이 헤더를 달면 서버와 계속 연결된 상태를 유지할 수 있다. HTTP 1.1에서는 기본 설정이며 주어진 timeout 시간이 되기 전까지 최대 max 개의 request를 보낼 수 있는 연결이 만들어진다.
메세지 수신 방식
채팅 시스템에서 메세지 수신은 실시간으로 이루어져야 한다. ‘실시간’을 구현하기 위한 방법이 3가지 정도가 있다. 폴링 polling, 롱 폴링 long polling, 웹소켓 WebSocket이다. 뒤로 갈수록 점점 단점이 개선된다.
폴링 polling
HTTP 연결은 클라이언트만 시작할 수 있으며 한 번 맺으면 요청을 1개만 보낼 수 있다. 폴링은 이 제약사항을 그대로 받아들여서 만든 단순한 방식이다. 클라이언트만 시작할 수 있으니 클라이언트가 계속 확인하러 가는 것이다. 일정한 시간 간격을 두고 서버에게 계속 물어본다. “새 메세지가 없나?”
단점은 아주 명확하다. Latency와 리소스라는 trade-off가 분명하게 존재한다. 폴링을 자주 보낼수록 latency는 낮아지지만 서버와 클라이언트 자원은 올라간다.
롱 폴링 long polling
폴링을 보완한게 롱 폴링이다. 이름에서 짐작할 수 있듯이 폴링을 좀 길게 하는 것이다. 길게 하는 주체는 서버다. 클라이언트가 “새 메세지 없나?” 요청을 보내면 서버는 곧바로 응답을 주지 않고 일정 시간동안 기다린다. 타임아웃 되기 전까지 새 메세지가 도착했으면 클라이언트에게 해당 메세지를 전달한다. 하지만 그렇지 않다면 서버에서 먼저 타임아웃 시그널을 보내고, 클라이언트가 곧바로 연결을 끊는다.
이 방식에서는 서버가 클라이언트의 연결 종료 여부를 알 수 있는 좋은 방법이 없다는 단점이 있다. 또한 Latency와 리소스라는 trade-off를 완벽히 해결하지 못했다. 타임아웃이 되면 클라이언트는 다시 새 연결을 만들 것이기 때문이다.
웹소켓 WebSocket
웹소켓은 위 2가지 방식과 결이 다르다. 좀 더 정확히는 HTTP 연결은 클라이언트만 시작할 수 있으며 한 번 맺으면 요청을 1개만 보낼 수 있다. 라는 제약사항을 완전히 깬 방식이다. 웹소켓 연결에서는 서버가 먼저 클라이언트에게 데이터를 보낼 수 있고, 연결이 끊어지기 전까지 계속해서 양방향 통신을 할 수 있다. 물론 가장 처음에는 클라이언트가 서버로 요청을 보내 HTTP handshake를 해야 한다. 무려 익스플로러를 포함한 오늘날 대부분의 브라우저, iOS와 Android까지 웹소켓을 지원할 정도로 널리 퍼져있는 방식이다.
웹소켓 연결 시 주의할 점은 서버 리소스 관리를 잘 해야 한다는 것이다. 한 번 맺어진 연결을 일부러 끊지 않는 이상 계속 유지되기 때문이다.
저장소
저장소 종류
데이터의 종류에 따라 어떤 DB를 쓸 것인지 잘 선택해야 한다. 채팅 시스템이 다루는 데이터는 2가지로 나뉜다.
- 일반적인 데이터: 사용자 프로필, 설정, 친구 목록
- 조금 특이한 데이터: 채팅 이력 데이터
일반적인 데이터는 다른 시스템 설계 때와 비슷하게 가용성과 규모 확장성을 염두에 두고 저장소를 선택하면 된다. 책에서는 데이터 안정성을 보장하는 관계형 데이터베이스를 선택했다.
반면 채팅 이력 데이터는 조금 다른 특징을 갖는다.
- 대량 데이터: 페이스북 메신저나 왓츠앱은 매일 600억개의 메시지를 처리한다.
- 최신성: 사용자는 보통 최근에 주고받은 메시지를 빈번하게 사용한다.
- 무작위 접근: 하지만 사용자가 검색을 하거나, 특정 메시지로 점프하는 등 무작위적인 데이터 접근을 하는 일도 있다.
- 1:1 채팅의 경우 읽기:쓰기 비율은 대략 1:1이다.
책에서는 key-value 저장소를 추천한다. 규모 확장이 쉽고, latency가 낮기 때문이다. 채팅 이력처럼 데이터 양이 많아질 때 RDB를 사용하면 무작위 접근을 처리하는 비용이 상대적으로 높아진다. 이미 채팅 이력을 관리하기 위해 페이스북 메신저는 HBase, 디스코드는 Cassandra를 사용하고 있다.
채팅 이력의 ID 관리
Key-value 저장소를 쓰기로 했으니 메세지 1개에 대한 아이디도 별도로 생성할 필요가 있다. RDB에서 지원하는 auto_increment 옵션을 제공하지 않는 이유도 있지만, 메세지 순서를 정하는데 ID가 쓰일 수도 있기 때문이다. created_at 을 기준으로 메시지 순서를 정하기에는 서로 다른 두 메세지가 동시에 만들어질 수 있기 때문에 적절하지 않다. 채팅 이력의 ID는 다음을 만족해야 한다.
- 고유한 값을 가져야 한다.
- 정렬 가능해야 한다.
- 정렬했을 때 시간순으로 나열되어야 한다.
이를 위해 2가지 방법을 쓸 수 있다. 첫번째는 스노플레이크와 같은 전역적 ID 생성기를 사용하는 것이고 두번째는 지역적 순서 번호 생성기(local sequence number generator)를 사용하는 것이다. 지역적이란 말은 ID의 유일성이 특정 그룹 내에서만 보장된다는 것이다. 예를 들어 채팅방 1, 2가 있을 때 각 채팅방에서 생성되는 메세지 ID의 유일성은 해당 채팅방 내에서만 유일하면 그만이다. 전체적으로 보면 서로 다른 1번 메세지가 각 채팅방 개수만큼 2개 존재할 수 있는 것이다.
