
1장. 어디선가 주워듣던 얘기를 넓고 얕게 하는 장이다. 사용자 수에 따른 규모 확장성. 이번 장에서는 수평적 규모 확장의 필요성과 이를 달성하기 위한 여러 시스템 컴포넌트를 살펴본다.
단일 서버로 부족한 이유
왜 확장성을 고려해야 하나?
- 사용자가 늘어나면 혼자서는 트래픽 감당이 안 돼서
그렇다면 규모 확장을 어떻게 해야 하나?
-
규모 확장에는 2가지 방법이 있다.
- 수직적 규모 확장 scale up
- 수평적 규모 확장 scale out
-
수직적 규모 확장 방식에는 한계가 있다.
- 서버 한 대에 CPU, memory 등 자원을 무한대로 증설할 방법이 없다.
- 장애에 대한 복구 방안이 없다. 내가 죽으면 그냥 끝이다.
-
결론: 수평적 규모 확장.
수평적 규모 확장을 위해
웹 이외의 계층
데이터베이스
- 데이터베이스 복제: master-slave 방식, 리더 없는 분산 방식 등 데이터베이스 서버를 분산하여, 같은 데이터를 저장는 것
- 같은 데이터를 여러개 복붙해서 저장해놓기 때문에 성능, 안정성, 가용성 면에서 장점이 있다.
- 안정성: 데이터 유실 걱정이 없음
- 가용성: 언제나 DB를 사용할 수 있음 (즉, 하나가 죽어도 나머지 DB가 있기 때문에 든든하다.^^)
- 같은 데이터를 여러개 복붙해서 저장해놓기 때문에 성능, 안정성, 가용성 면에서 장점이 있다.
- 데이터베이스 샤딩: 데이터베이스를 샤드라고 부르는 작은 단위로 분할하는 것. 모든 샤드는 같은 스키마를 쓰지만 서로 다른 샤드에 보관되는 데이터 사이에는 중복이 없다.
- 관건: 샤딩 키(=파티션 키) 정하는 방식
- 이 키를 통해 데이터가 어떻게 분산되는지가 결정되기 때문.
무슨 필드를 기준으로 데이터를 분리할 것인가?
- 이 키를 통해 데이터가 어떻게 분산되는지가 결정되기 때문.
- 샤딩 도입 시 고려해야 할 문제
- 데이터의 resharding 정책
- 유명인사 문제 (=핫스팟 키):
유명한 사람들이 하나의 샤드에 몰려서 저장된다면? - 조인과 비정규화: 한번 샤드 서버로 쪼갠 다음에는 여러 샤드에 걸친 데이터를 조인하기가 힘들다.
- 관건: 샤딩 키(=파티션 키) 정하는 방식
-
로드밸런서: load balancing set에 속한 웹 서버에게 트래픽을 고르게 분산하는 역할
- 클라이언트는 웹 서버 각각의 IP(private IP다.)는 모른 채 L4 로드밸런서의 IP로 요청을 보낸다.
-
캐시: 웹 서버와 DB 사이의 계층으로, 애플리케이션의 성능에 영향을 줌
-
단, 아래 사항을 고려해야 한다.
- 언제 사용할 것인지: 데이터 갱신 횟수 <<<<<<<< 참조 횟수일 때
- 어떤 데이터를 저장할 것인지: 캐시는 휘발성이다.
- 데이터 만료 정책
- 일관성 유지 방법: 데이터 저장소의 원본과 캐시 내의 사본이 같게 만들어야 한다.
- 장애 대처 방법: 캐시 서버가 1대만 있으면 SPOF가 될 가능성이 있다.
SPOF: 해당 지점에서의 장애가 전체 시스템의 동작을 중단시켜버릴 수 있는 지점.
- 캐시 메모리 사이즈
- 데이터 방출 정책
-
-
CDN: 정적 콘텐츠를 전송하는데 쓰이는 네트워크. 지리적으로 원본 서버와 분리된다.
웹 계층
상태를 들고 있지 않으면 확장이 쉬워진다.
-
stateless 웹 계층: 상태 정보를 갖고 있지 않는 웹 계층. (예: 사용자 세션 데이터)
-
stateless vs. stateful 웹
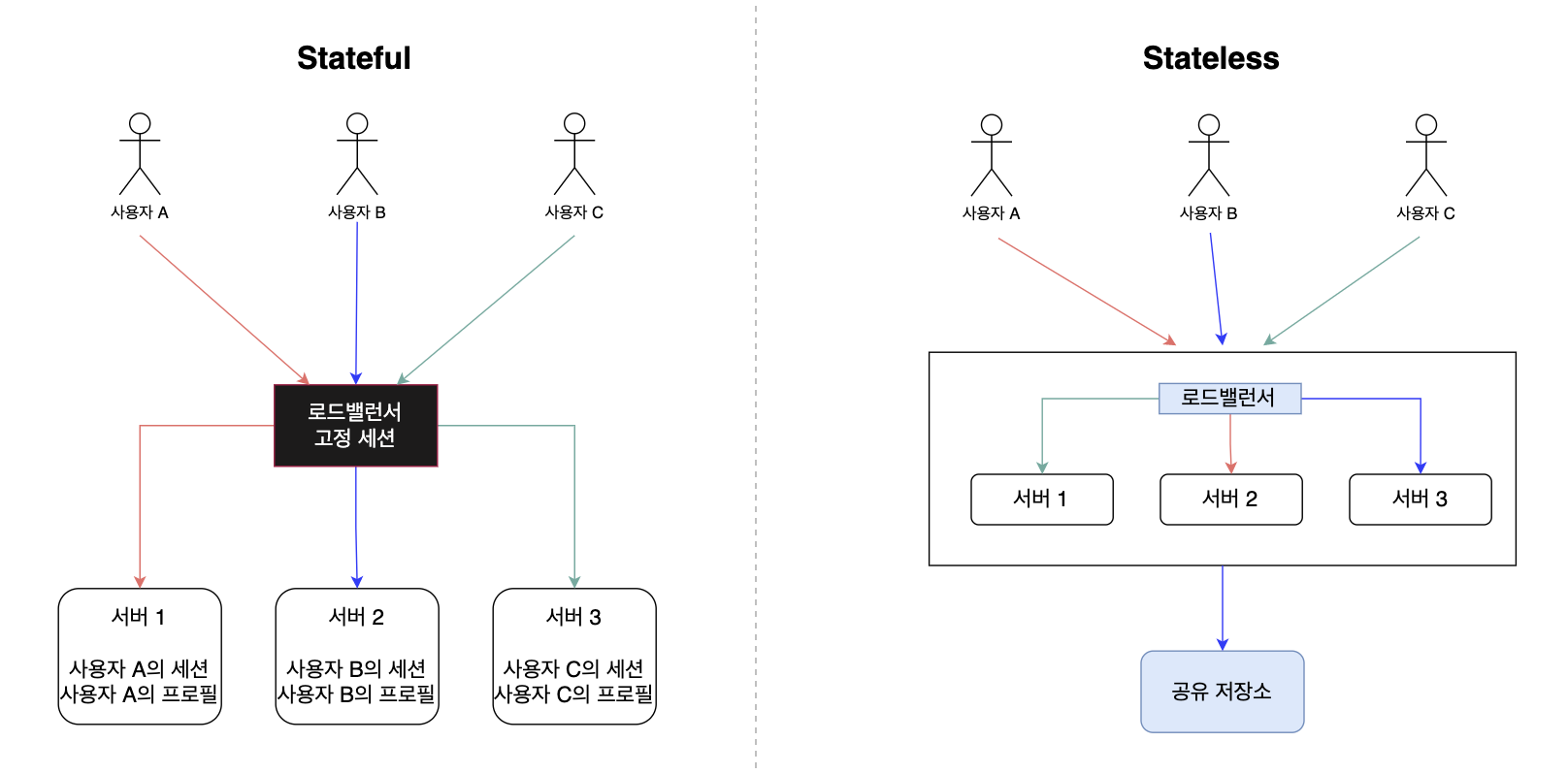
stateful 웹을 사용하면 이런 문제가 있다.
- 고정 세션 사용으로 인한 로드밸런서의 부담
- 웹서버 증설, 제거가 까다로움
결론: 웹 계층을 stateless 하게 만들자.
그리고 여러가지 추가 컴포넌트들
데이터 센터
도 분산이 필요하다.
- geoDNS: 사용자의 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정하게 해주는 DNS 서비스.
- 장애 발생에 대응하기 위해서는 아래 문제를 고려해야한다.
- 트래픽 우회: 살아있는 데이터센터로 트래픽을 보내는 가장 효과적인 방법은?
- geoDNS가 어느정도 해결해주는 듯.
- 데이터 동기화: 각 데이터센터마다 들고있는 정보가 다른 상황에서 장애가 난 경우
- 테스트와 배포: 이를 위해 자동화된 배포 도구가 중요하다.
- 트래픽 우회: 살아있는 데이터센터로 트래픽을 보내는 가장 효과적인 방법은?
메시지 큐
: pub/sub 구조로, 비동기 통신을 지원하는 메세지 버퍼 역할을 한다.
- 장점: 서비스/서버 간 결합이 느슨해져서 규모 확장성을 보장하면서 안정적으로 애플리케이션을 구성할 수 있다.
- (뭔소리?) -> 생산자는 소비자가 죽어도 메시지를 발행할 수 있고, 소비자는 생산자가 불가용한 상태라도 메시지를 수신할 수 있다.
- 예) 사진 보정 애플리케이션. 사진 편집 작업은 시간이 오래 걸리기 때문에 비동기적으로 수행하면 좋다.
로그, 메트릭, 자동화
- 로그: 에러 로그 모니터링을 위해서
- 메트릭: 사업 현황에 관한 정보를 얻고 + 시스템의 현재 상태를 파악하기 위해서
- 호스트 단위 메트릭: CPU, 메모리, 디스크 I/O 등
- 종합 메트릭: DB 계층의 성능, 캐시 계층의 성능 등
- 핵심 비즈니스 메트릭: daily active user, 수익, 재방문율 등
- 자동화: 개발 생산성을 위해서
- CI/CD 툴을 활용, 개발자가 만드는 코드를 검증하게 해서 미리 문제를 막거나 + 빌드-테스트-배포 절차 자동화
결론
-
전략은 매번 바뀐다.
-
웹은 stateless로
-
모든 계층에 다중화 도입
-
가능한 많은 데이터를 캐시할 것
-
정적 콘텐츠는 CDN 사용
-
여러 데이터 센터를 지원할 것
-
데이터 계층은 샤딩을 통해 규모 확장
-
각 계층은 독립적 서비스로 분할
-
시스템을 지속적으로 모니터링하고, 자동화 도구 활용

설계를 좋아합니다. 코드도 적고 그림도 그리고 글도 씁니다. 넓고 얕은 경험을 쌓고 있습니다.