
Release의 모든 것: 대규모 웹 분산 시스템을 위한 운영 고려 설계(2판), 마이클 나이가드 지음, 박성철 역, 한빛미디어, 2023 (『Release It 릴리스 잇』(위키북스, 2007)의 2판이다.)
업무를 하면서 경험적으로만 알고 있던 지식을 체계적으로 정리해주는 책이었다. 읽는 내내 마치 조각조각 흩어진 퍼즐을 맞추는 느낌이 들었다. 기술적인 선택 뒤에 숨은 운영, 비용, 리스크 관점까지 상기시켜주기 때문에 시스템 설계·운영 경험이 쌓일수록 다르게 보일 것 같다.
어떻게 읽었나
- 기간: 2025.08.12 - 2025.10.21
- 분량: 총 17장, 종이책 455페이지.
- 방식: 일주일에 1-3장
- 누구와 함께: 2025년 11월 기준, 벌써 26개월 째(!) 함께하고 있는 랜선 스터디원
- 사실 혼자 읽으면서 중간 즈음부터 손을 안 대고 있었는데 스터디를 통해 완독할 수 있었다. 최고^^!
구성
책은 총 네 부분으로 구성되어 있으며, 현대 소프트웨어 운영의 전 과정을 단계적으로 다룬다. 각 부의 주제와 키워드를 정리하면 다음과 같다.
- 1부. 안정성 구축: 시스템이 작동을 유지하면서 멈추지 않게 할 방법에 대해.
- 시스템 장애, 연쇄 반응, 스레드 블로킹, 회복력 중심의 설계 원칙
- 2부. 운영 고려 설계: 복잡한 현대 운영 환경에서 살아남기
- 기반 → 인스턴스 → 연결 → 제어 평면 → 운영으로 이어지는 계층 구조로 설명하며, 투명성, 로그, 배포 환경 구성에 대해 다룬다.
- 이 책에서 가장 많은 내용을 담고 있는 부분이다.
- 3부. 시스템 전달: 배포를 고려한 설계, 서로 다른 종류의 서버 사이를 조정하는 방법.
- 배포 전략, 스키마 변경, 다양한 서버 간 조정 문제
- 참고로 3부에 “배치 고려 설계” 라는게 나오는데 여기서 말하는 “배치”란 놀랍게도 batch 가 아니라 deployment 다. 의미가 완전히 다르니 주의해서 읽자. (개인적으론 ‘배포’라고 번역했으면 혼선이 덜 했을 것 같다..)

- 4부. 체계적 문제 해결: 지속적인 시스템을 위해
- 카오스 공학, 지속 가능한 시스템 운영, 개선 주기, 서비스 품질 관리
🆕 INPUT
책을 읽으면서 이런 내용을 새롭게 알 수 있었다.
개념적으로 배운 내용
- 우리는 가장 정보가 부족한 순간에 가장 중요한 결정을 내린다.
- 설계가 바뀌는 건 자연스럽고, 그걸 부끄러워하지 말아야 한다는 메시지가 크게 와닿았다. 놀랍게도 책을 읽기 전에는
가장 정보가 부족한 순간에설계 작업을 한다는 사실을 눈치채지 못하고 있었다!!! 그래서 계속 그렇게 바뀌었구나!!! - 그렇기 때문에 설계 전에는 현 상황을 제대로 파악하는 것이 중요해보인다. 이런 부분에 부족함을 느끼고 있었는데, 앞으로 좀 더 신경을 써야겠다.
- 설계가 바뀌는 건 자연스럽고, 그걸 부끄러워하지 말아야 한다는 메시지가 크게 와닿았다. 놀랍게도 책을 읽기 전에는
- JVM 애플리케이션은 SIGQUIT을 받아도 바로 종료되지 않을 수 있다는 사실.
- 운영 환경에서 이 미묘한 차이가 문제를 더 복잡하게 만들 수 있다. 특히 k8s 환경을 쓰는 지금은 더더욱..
- 장애 원인의 상당수는 결국 블록된 스레드 + 공유 자원 병목에서 시작된다는 점.
- 잘 굴러가던 서버가 뭔가 이상하다면 이걸 먼저 떠올려보자.
- 운영 고려 설계의 5단계 관점: 기반 → 인스턴스 → 연결 → 제어 평면 → 운영
- 책에서는 이런 그림으로 표현했다. 아래로 갈수록 추상화 정도가 낮은 레벨, 위로 갈수록 높은 레벨이다. ‘잘 작동하는’ 소프트웨어를 만들기 위해 고려해야 할 점을 계층화한 것이다. 책의 2부에서 각 계층별 내용을 깊게 다룬다.
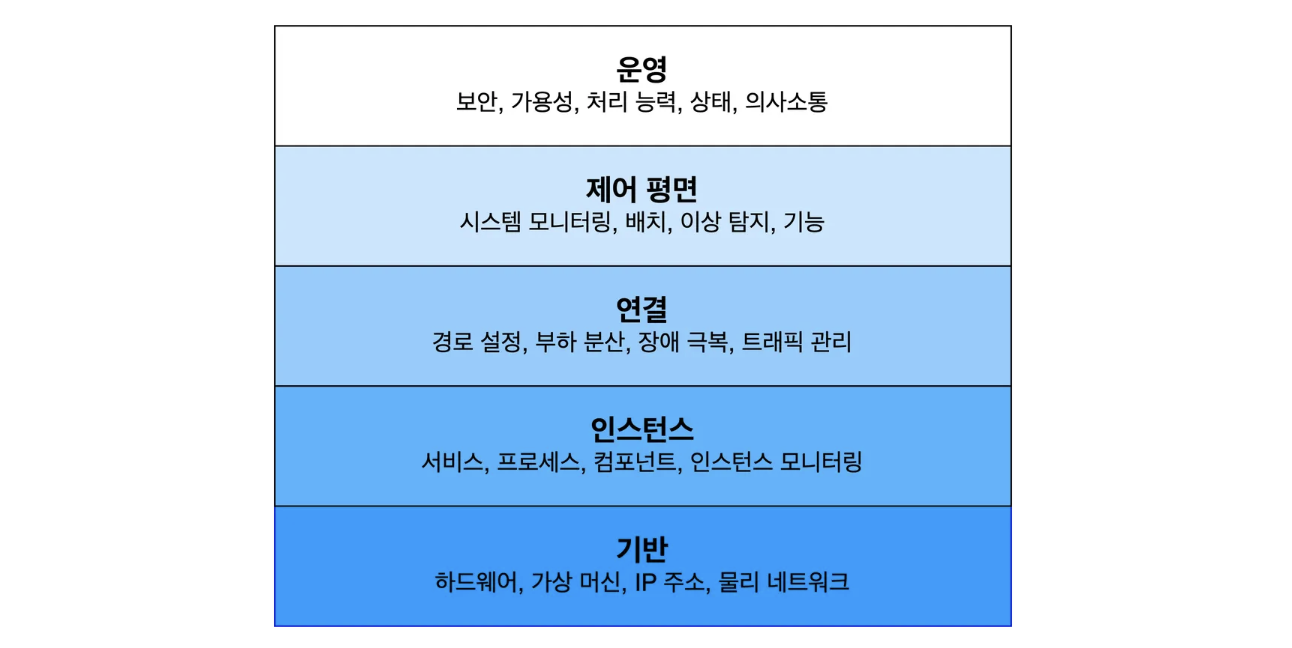
- 책에서는 이런 그림으로 표현했다. 아래로 갈수록 추상화 정도가 낮은 레벨, 위로 갈수록 높은 레벨이다. ‘잘 작동하는’ 소프트웨어를 만들기 위해 고려해야 할 점을 계층화한 것이다. 책의 2부에서 각 계층별 내용을 깊게 다룬다.
- 백프레셔, 조속기, 서킷브레이커 등 요청/응답 흐름을 ‘통제’하는 기술이 단순한 옵션이 아니라 설계의 일부라는 점.
실무 경험과 연결된 내용
- “정기 배포를 한다면 2년 동안 재부팅 없는 안정성은 크게 중요하지 않다”
- 우리 팀 서버도 1년 넘게 원인 모를 메모리 증가가 있었는데, 2주마다 진행하는 정기배포로 버티고 있었다. 물론 결국 고치긴 했지만 다른 업무보다 우선순위를 낮춰서 진행되었다.
- 서버마다 로그 레벨 운영 방식이 완전히 다르다는 점도 ‘투명성’ 챕터를 읽으며 다시 생각해볼만했다.
- 게이트웨이 서버처럼 warn 레벨 로그가 아주 많은 서버, API 서버처럼 정상 상태에서는 아무 로그도 보이지 않는 서버 등..
- 그동안 실무에서 했떤 인덱스 변경 방식이나 스키마 변경 전략이 책의 권장 패턴과 거의 동일해서 반가웠다.
: 하위 호환을 지킨 read/write → 배포 → 마이그 → 레거시 제거 방식.
마음에 들었던 문장들
우리는 가장 정보가 부족한 순간에 가장 중요한 결정을 내린다.장애가 나는 모든 시스템은 어딘가에 정체가 생기는 대기열로 시작한다.- 메시지 큐, 비동기 아키텍처가 왜 중요한지 한 문장으로 요약하는 말이다.
모든 해법은 새로운 문제를 만들어낸다.- 이와 비슷한 말로
우리가 코드를 만드는 순간 레거시가 된다가 있다. - 문제가 없는 해법은 없다. 다만 얼마나 수용 가능한 문제인지에 따라 해법이 채택되는 것 같다.
- 이와 비슷한 말로
자신이 하는 일에는 보수주의자가 되고, 외부를 수용할 때는 자유주의자가 되어야 한다. (포스텔의 원칙)- 실제로 외부 API의 예상치 못한 응답 포맷 때문에 장애가 났던 경험이 있어 크게 공감이 되었다.
새로운 관점
- 장애 대응은 ‘트러블슈팅’이 아니라 사전 예방 구조를 설계하는 일이라는 관점.
- 자동화는 좋은 것이지만 전면 자동화가 반드시 최선은 아니라는 점.
- 카오스 공학은 단순한 장애 테스트가 아니라 불확실성을 시스템이 얼마나 견딜 수 있는지 실험하는 프레임워크라는 점도 배웠다.
📤 OUTPUT
책에 나온 내용 중 실무에 적용해볼만한 액션 아이템도 뽑아봤다.
당장 해볼만한 것
- 외부 API 연동 시 예상치 못한 응답 포맷 테스트 강화. 상상력을 발휘해보자.
- 서비스별로 WARN/ERROR 로그 레벨을 정리해보기.
언젠가! 도전해보고 싶은 것
- WebFlux에서의 백프레셔 적용 실험을 테스트 환경에서 시도해보기.
- 팀 단위로 작은 카오스 실험(장애 유도 실험)을 해보는 것.
- 컨슈머/프로듀서, 서버, 미들웨어 등 공유 자원 의존도를 정리해 병목 구간 파악하기
- 특히 이건 팀 내 시스템 전체 설계도를 그리는 작업을 하면서 함께 정리해보고 싶다.
👍 총평
- 추천 대상: 약간의 서버 운영 경험이 있으면서 그동안 경험한 것을 체계적으로 정리하고 싶은 개발자, 큰 그림을 보고 싶거나, 봐야 하는 사람
지식의 수준이 아니라 운영 경험의 밀도에 따라 난이도가 달라지는 책 같았다. 그렇다고 단순 운영 노하우만 나열한 것도 아니고, 설계 측면에서 어떻게 견고한 프로그램을 만들 수 있을지도 다루고 있어 재밌게 읽었다.
운영 경험이 더 쌓이면 안정성, 제어 평면, 장애 대응 챕터들이 훨씬 다르게 보일 것 같아서 몇 년 후에 다시 한번 읽어보고싶다. 언젠가 정말 이 책이 Release의 “모든 것”을 다룬 책인지 판단할 수 있게 되지 않을까?

설계를 좋아합니다. 코드도 적고 그림도 그리고 글도 씁니다. 넓고 얕은 경험을 쌓고 있습니다.