4장. 분산 메세지 큐
4장 내용은 카프카 동작 방식과 유사하기 때문에 자세한 내용을 적지 않을 것이다. 대신 가상 면접 사례로 배우는 대규모 시스템 설계 기초 1권에 나왔던 메세지 큐가 들어간 설계 예시를 살펴보면서 어떤 경우에 메세지 큐를 사용하면 좋은지 알아보려 한다. 1권 내용을 읽으면서 ‘메세지 큐라니 도대체 이게 뭐지? 진짜 그냥 Queue 자료구조? 엄청 간단해 보이는데 역할도 꽤 크고 자주 등장하네’ 라고 생각했었는데 일하면서 카프카를 사용하다보니 그렇지 않다는걸 깨달았다. (이걸 깨달았다는 점을 깨달으면서 그동안 시간을 헛되이 보내진 않았구나 하는 생각도 해본다.🤗)
메세지 큐, 뭐가 좋을까
- 결합도 완화(decoupling): 컴포넌트 사이의 강한 결합이 사라지므로 각각 독립적으로 갱신할 수 있다. 대부분의 장점은 결합도를 완화시킴으로써 자연스럽게 얻을 수 있다.
- 규모 확장성 개선: 생산자와 소비자 시스템 규모를 트래픽 부하에 맞게 독립적으로 늘릴 수 있다.
- 가용성 개선: 특정 컴포넌트에 문제가 발생해도 다른 컴포넌트는 큐와 계속 상호작용을 이어갈 수 있다.
- 성능 개선: 생산자와 소비자는 서로를 기다리지 않고 각자 할 일을 하면 된다.
- 결론: 각자 따로 놀 수 있게 해 준다. 따로 놀게 된 덕분에 규모, 가용성, 성능 측면에서 모두 이점이 있다.
하지만! 네트워크 실패 위험성은 올라간다.ㅎ- 네트워크와 관련해서 꽤나 흥미로운 주제가 있다. “Exactly Once는 가능할까?” 라는 주제다. 언제 무엇이 어떻게 실패할지 모르는 네트워크 세계에서, 아무리 ACK를 보내고 데이터 누락을 방지하는 처리를 해도 결국 네트워크상으로 전송되는 데이터에 있어 완벽한 “Exactly Once” 전송은 불가능하다고 하는 쪽과 그렇지 않다고 하는 쪽이 있다. 나는 아직 확답을 찾지 못했다.
메세지큐의 구성 요소와 흐름
- 메세지를 만드는 Producer, 메세지를 저장 및 관리하는 Broker, 메세지를 소비하는 Consumer 로 구성된다.
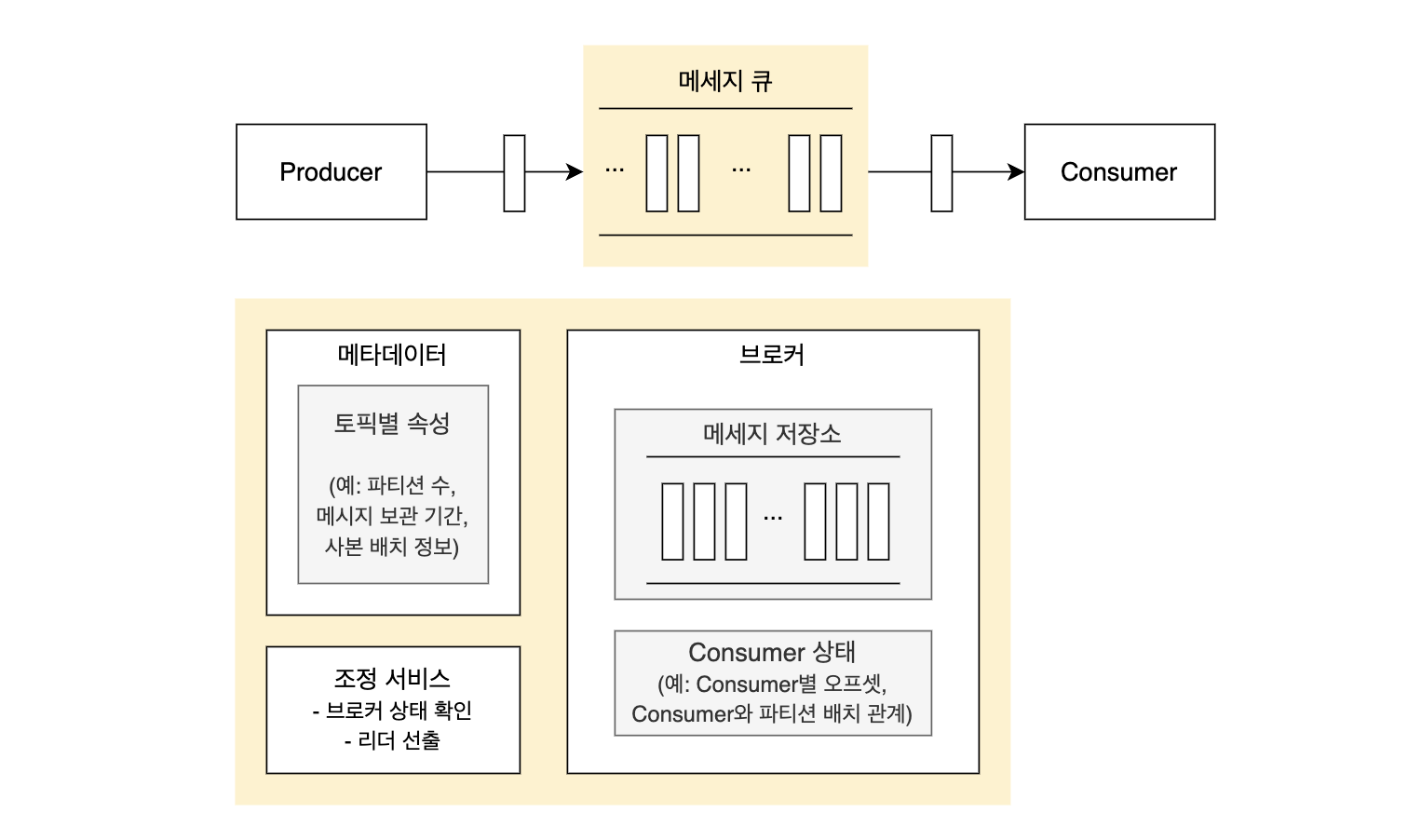
- 주키퍼를 사용하는 카프카는 이렇게 생겼다.
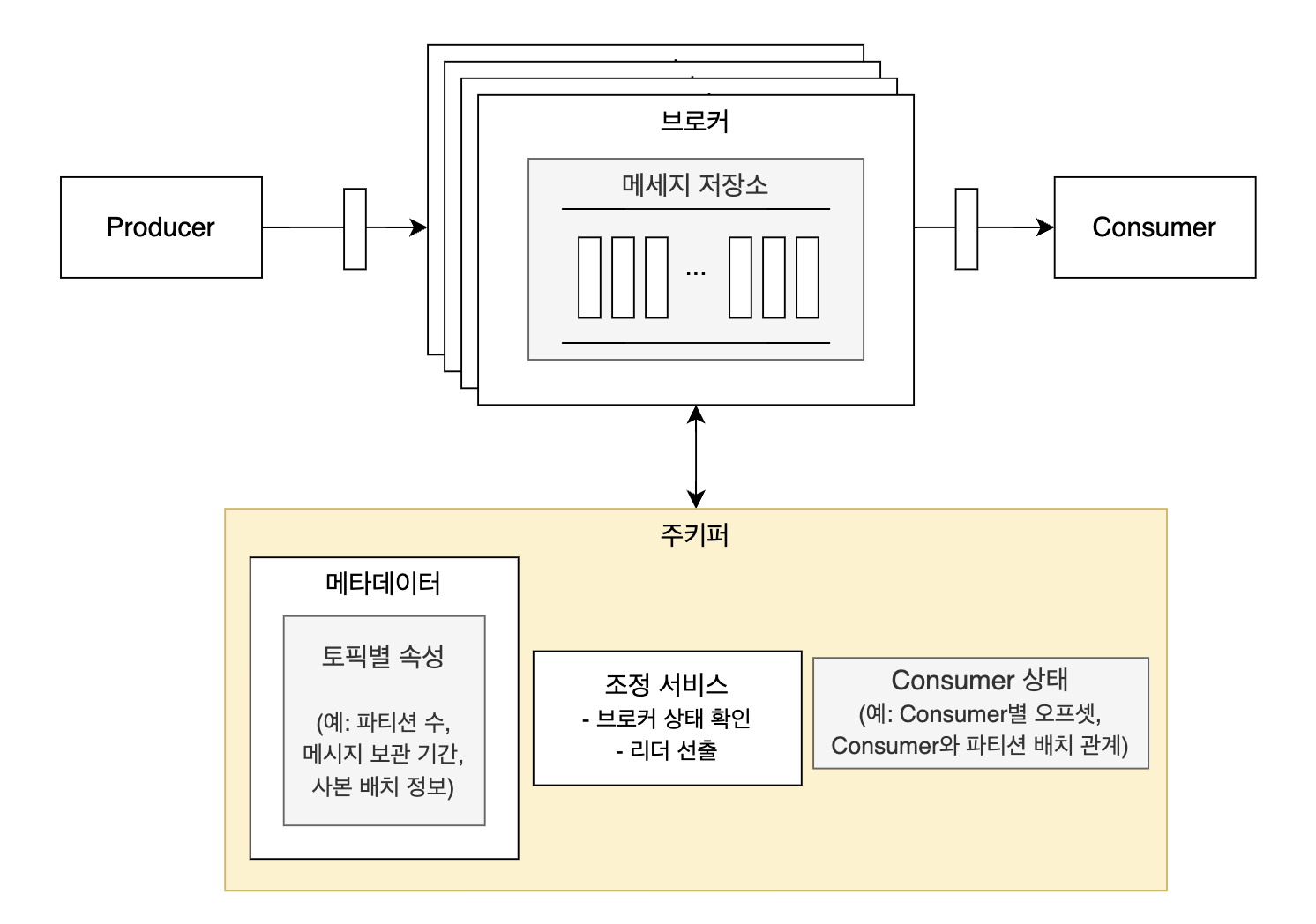
Produce 흐름
- 메세지 큐로 메세지를 전송한다.
- 메세지 큐를 구성하는 서버 여러개 중 정확히 누구한테 보내야할 지 결정해야 한다.
- 대량 메세지 처리를 위해 메세지 1개마다 네트워크를 통해 전송하지 않고, N개씩 모아서 한번에 보낸다.
- 이 때, 지연 시간과 대역폭의 trade-off 가 생긴다.
- N이 커질수록 대역폭은 커지지만 그만큼 대기 시간이 늘어나기 때문에 메세지 하나가 consume 되기까지의 지연 시간이 길어진다.
- 이 때, 지연 시간과 대역폭의 trade-off 가 생긴다.
Consume 흐름
- 두 가지 모델이 있다. Pull model 을 주로 사용한다.
- Push model: 브로커는 메세지를 받는 즉시 바로 consumer 한테 전달한다.
- 따라서 consumer는 소비 속도를 조절할 수 없다.
- 대신 브로커는 편하다. 메세지가 들어오는 즉시 바로 내보내면 되기 때문이다.
- Pull model: 브로커는 consumer의 ‘메세지 전송 요청’을 받으면 메세지를 전달한다.
- 따라서 consumer는 소비 속도를 조절할 수 있다.
- Consumer에 장애가 발생해도 괜찮다. 다시 이전 오프셋부터 읽기 요청을 보내면 된다.
- 이 때 폴링 방식을 쓰면 자원 낭비가 클 수 있다. 보통은 롱 폴링을 지원한다.
- 따라서 consumer는 소비 속도를 조절할 수 있다.
- Push model: 브로커는 메세지를 받는 즉시 바로 consumer 한테 전달한다.
이걸 어디다 써먹나?
이제 1권에서 나왔던 설계를 하나씩 다시 꺼내볼 차례다. 언제 무엇을 위해 메세지 큐를 사용했을까? 메세지큐를 사용한 설계는 총 15장 중 5개 장에서 등장한다. 1권 초중반부 내용이 ‘규모 확장성’, ‘개략적인 규모 추정’, ‘안정 해시 설계’ 등 기초적인 내용이고, 이를 응용해서 하나의 온전한 서비스를 만드는 장이 후반부터 나온다는걸 생각해보면 꽤나 많이 쓰였다고 볼 수 있다.
- 10장 알림 시스템 설계
- 11장 뉴스 피드 시스템 설계
- 12장 채팅 시스템 설계
- 14장 유튜브 설계(라고 쓰고 영상 시청 부분은 고려하지 않은 동영상 업로드 시스템 설계라고 읽는다.)
- 15장 구글 드라이브 설계
왜 써먹었나?
위 5개 장을 하나씩 다시 되짚어보자.
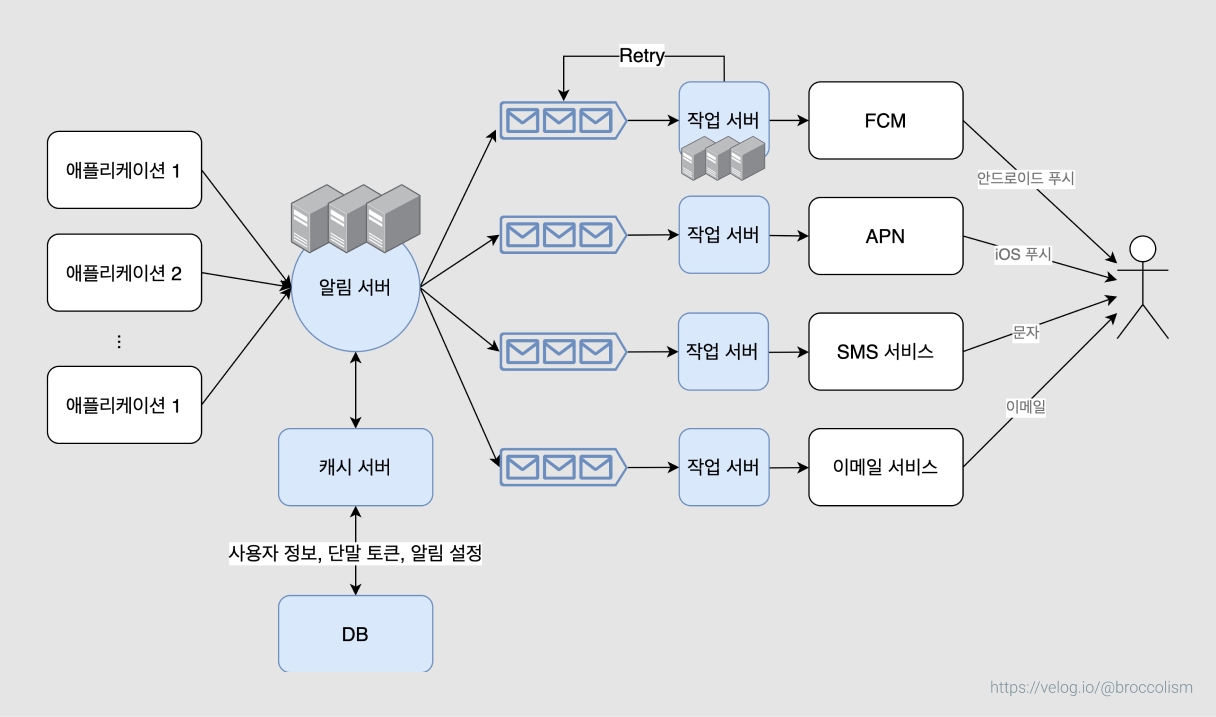
- 10장 알림 시스템 설계: 알림 서버가 SPOF(Single Point of Failure)가 되는 것을 방지하기 위해 각 작업 서버 앞에 메세지 큐를 놓았다.
- 그러면 알림 서버에 잠깐 장애가 생기더라도 작업 서버는 영향을 받지 않을 수 있고
- 작업 서버에서 처리 도중 오류가 생기더라도 retry를 할 수 있다.
- 11장 뉴스 피드 시스템 설계: 누군가 포스팅을 작성했을 때 그 사람의 친구 모두에게 글을 보내주는 팬아웃(fanout) 기능에 사용했다. 새 포스팅이 생기면 차단하지 않은 친구 목록과 포스팅 ID를 메세지 큐에 넣고, 팬아웃 담당 서버가 메세지 읽고 캐싱, 복사, 전파 등 작업를 처리하는 구조다.
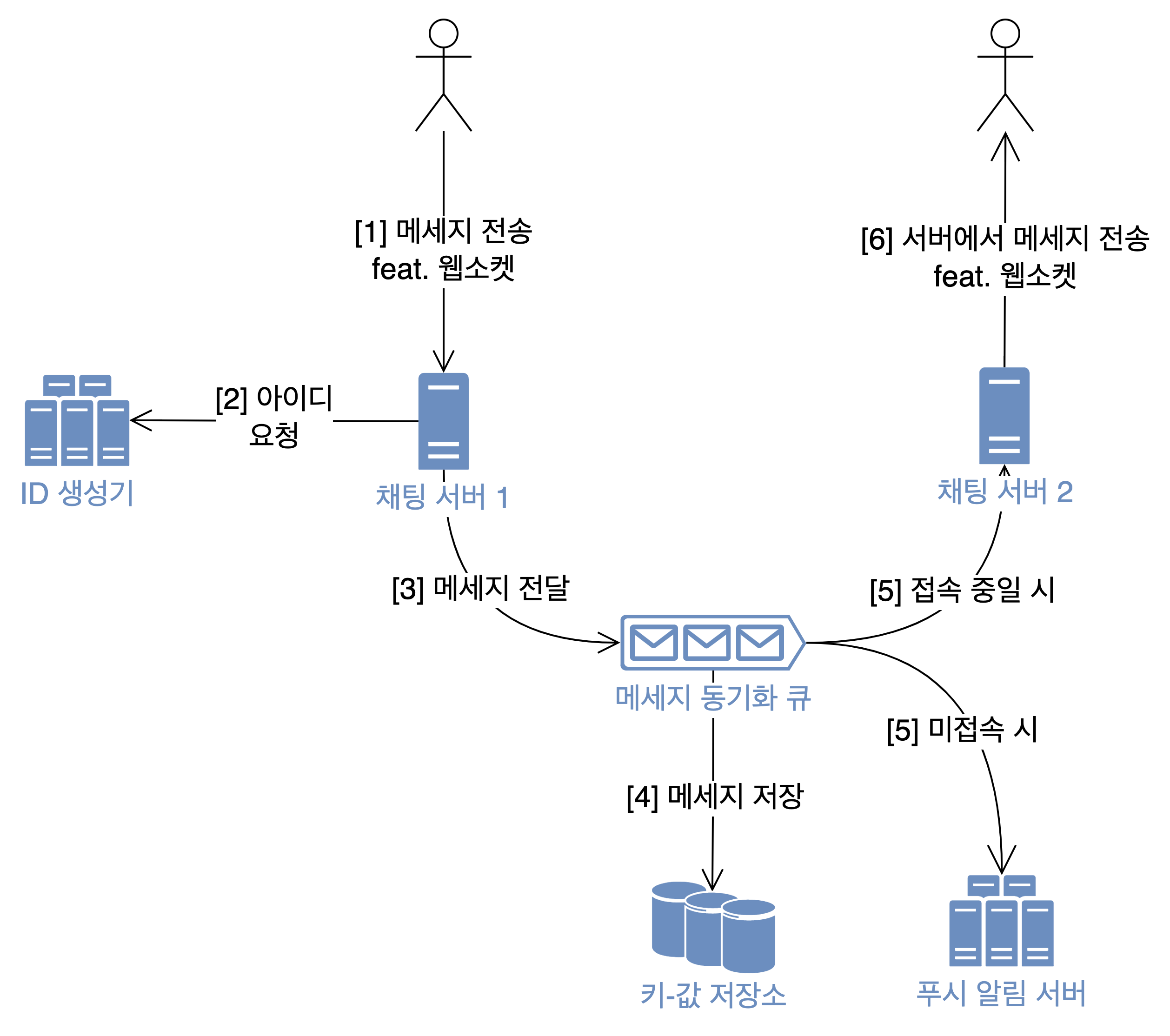
- 12장 채팅 시스템 설계: 각 사용자별로 메세지 큐 1개를 만들어줬다. 실시간으로 생성되는 대량 메세지의 주인이 누구인지 구분하고(그래서 사용자는 자신의 메세지 큐만 바라보면 되도록), 유실 없이 보관하는 역할을 했다.
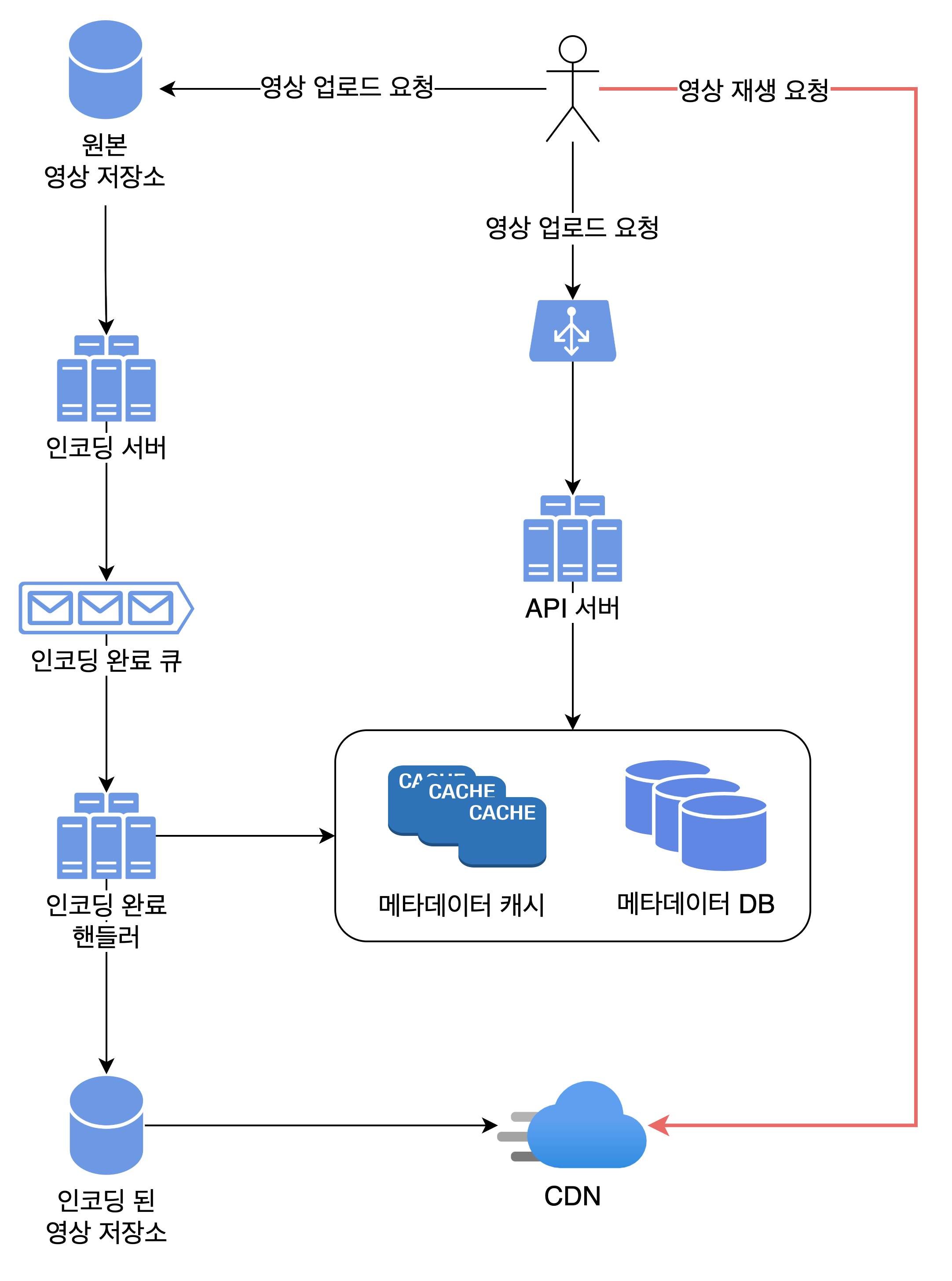
- 14장 유투브 설계: 큰 그림을 보면 인코딩 완료 큐에 등장하고, 상세 그림을 보면 인코딩 작업 도중에 항상 쓰였다.
- 큰그림) 영상 업로드 전체적인 과정에서, 인코딩 작업을 비동기로 처리하기 위해 사용되었다. 즉, 인코딩 서버에서 작업이 완료된 영상을 곧바로 영상 저장소 및 캐시에 저장하지 않고 중간에 메세지 큐를 두었다. 이렇게 하면 인코딩 작업 속도와 무관하게 전체 흐름이 끊임 없이 진행될 수 있다.
- 작은 그림) 인코딩 과정을 나타낸 그림이다. DAG 스케줄러에서 비디오 하나를 처리하기 위해 어떤 스텝이 필요한지 결정하고, 각 스텝은 자원 관리자의 작업 큐에 들어간다. 자원 관리자는 작업 큐, 작업 서버 큐, 실행 큐 총 3개의 큐를 사용한다.
- 큰그림) 영상 업로드 전체적인 과정에서, 인코딩 작업을 비동기로 처리하기 위해 사용되었다. 즉, 인코딩 서버에서 작업이 완료된 영상을 곧바로 영상 저장소 및 캐시에 저장하지 않고 중간에 메세지 큐를 두었다. 이렇게 하면 인코딩 작업 속도와 무관하게 전체 흐름이 끊임 없이 진행될 수 있다.
- 15장 구글 드라이브 설계: 오프라인 사용자가 만든 편집 내용을 임시로 저장하는 역할로 메세지 큐를 사용했다. 작업 내용을 큐에 저장했다가 사용자가 온라인 상태가 되면 이를 동기화하는 방식이다.

각 장에서 메세지큐를 도입한 주된 이유를 찾아보자.
- 10장 알림 시스템 설계: 위험 감내성. SPOF 를 막기 위해서.
- 11장 뉴스 피드 시스템 설계: 규모 확장성. 실시간으로 생기는 ‘포스팅 전송’ 이벤트를 관리하기 위해서.
- 12장 채팅 시스템 설계: 버퍼링(임시 저장). 실시간으로 생기는 ‘채팅 메세지 전송’ 이벤트를 관리하기 위해서.
- 14장 유튜브 설계: 성능. 영상 인코딩 작업이 다른 작업의 속도에 영향을 주지 않도록 하기 위해서.
- 15장 구글 드라이브 설계: 버퍼링(임시 저장). 오프라인 유저의 데이터를 잠깐 들고 있기 위해서.
메세지 큐를 도입함으로써 결합도를 낮춘 덕분에 위험 감내성과 규모 확장성, 그리고 성능을 챙길 수 있다. 조금 결이 다른 용도로는 데이터를 잠깐 저장하기 위해서도 사용할 수 있다.
나머지 키워드
키워드로 짧게 살펴보자.
- 복제와 사본 동기화: 리더, 팔로워, 커밋, ACK 설정
- 메세지 전달 방식: At most once, at least once, exactly once
- Consumer rebalancing (Consumer 재조정): round-robin, sticky, cooperative sticky, …
책 내용 더 알아보기
분산 서버를 관리하는 주키퍼, etcd
아파치 주키퍼나 etcd가 보통 컨트롤러 선출을 담당하는 컴포넌트로 널리 이용된다. - 4장 3단계: 상세 설계
→ 주키퍼는 카프카 쓰느라 익숙한데, etcd 는 처음 들어본다. 근데 무려 k8s 가 이걸 쓴다고 한다. https://tech.kakao.com/2021/12/20/kubernetes-etcd/ 여기에 설명이 잘 되어 있다. “예를 들어, 클러스터에 어떤 노드가 몇 개나 있고 어떤 파드가 어떤 노드에서 동작하고 있는지가 etcd에 기록됩니다.“
주키퍼 특) 빠르면서 일관성까지 챙겨줌.
소비자 상태 정보 데이터가 이용되는 패턴은 다음과 같다.
- 읽기와 쓰기가 빈번하게 발생하지만 양은 많지 않다.
- 데이터 갱신은 빈번하게 일어나지만 삭제되는 일은 거의 없다.
- 읽기와 쓰기 연산은 무작위적 패턴을 보인다.
- 데이터의 일관성(consistency)이 중요하다.
(…) 데이터 일관성 및 높은 읽기/쓰기 속도에 대한 요구사항을 고려하였을 때, 주키퍼(Apache ZooKeeper) 같은 키-값 저장소를 사용하는 것이 바람직해 보인다.
→ 읽기/쓰기 속도가 높으면서도 일관성이 중요할 때는 주키퍼! 아니 근데 이거 2개를 어떻게 동시에 보장하지?? 라는 생각이 들어서 급 찾아본 글 (https://zookeeper.apache.org/doc/r3.4.5/zookeeperOver.html#:~:text=ZooKeeper is replicated.&text=They maintain an in-memory,to a single ZooKeeper server.)
트리 형태로 key-value를 저장하고, 인-메모리에 write, 디스크에 스냅샷 및 로그를 기록한다. znode (ZooKeeper data Node) 라는 개념을 사용하는데 각 노드별로 데이터 및 ACL, 타임스탬프를 기록한다. 애초에 오케스트레이션 목적으로 만들어진거라 각 노드에 저장되는 데이터 크기가 작다는 가정 하에 만든 스토리지인 듯. 자세히 보진 않았지만 read/write 할 때 데이터 접근 방식이 좀 특이한 것 같다.
카프카가 주키퍼를 버리고 KRaft를 도입한 이유
- 원문(영어)는 Medium 유료 결제가 필요하다: https://towardsdatascience.com/kafka-no-longer-requires-zookeeper-ebfbf3862104
- 번역본: https://psm1782.medium.com/동물원을-탈출한-카프카-zookeeper-less-kafka-a71cba58d5d9
주키퍼의 의존성을 제거하는 것은 카프카를 위한 거대한 한걸음 입니다. 사실, 이번의 KRaft mode는 Apache Kafka의 확장성을 훨씬 더 증대시켜줄 것이며 더 이상 카프카를 다뤄보기 위해 ZooKeeper까지 공부할 필요없이 러닝 커브를 완만하게 만들어 줄 혁신이 아닐 수 없습니다. 이는 또한 kafka의 configuration과 배포를 더 쉽고 효율적으로 만들어 줄 것입니다.
→ 즉, 카프카의 외부 라이브러리 의존성을 제거하고 카프카 전용 컨트롤러를 도입함으로써 1) 확장성을 높이고 2) 러닝 커브 및 실수 발생 가능성을 줄이기 위해 주키퍼를 벗어났다.
