-
Where절
-> 조건을 사용하는 구문
-> 원하는 값을 도출하기 위해 사용 -
구문
SELECT [DISTINCT/ALL] 칼럼명 [ALIAS명]
FROM 테이블명
WHERE 조건식;- 예제
select first_name,department_id
from employees
where department_id = 100;
-- where 구문을 사용해서 조건을 설정
-- department_id의 값이 100인 데이터 중 first_name과 department_id 열을 출력
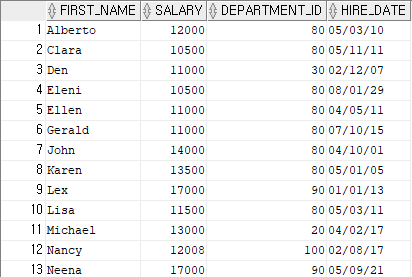
select first_name, salary
from employees
where salary > 15000;
-- salary의 값이 15000 이상인 데이터를 출력- 결과
위 결과를 보면 department_id가 100인 데이터를 도출한 것을 볼 수 있다.
이 뿐 아니라 크고 작은 다양한 연산자들을 넣어서 다양하게 활용이 가능하다.
| 연산자 | 설명 |
|---|---|
| = | 같다 |
| >,< | 크다,작다 |
| >=,<= | 크거나 같다, 작거나 같다 |
| <>,!=,^= | 같지 않다 |
| BETWEEN AND | 특정 범위에 포함되는지 비교 |
| LIKE / NOT LIKE | 문자 패턴 비교 |
| IS NULL / IS NOT NULL | NULL 여부 비교 |
| IN / NOT IN | 비교 값 목록에 포함/미포함 되는지 여부 비교 |
비교 연산자
-> 표현식 간 관계 비교 목적으로 사용, 비교 결과는 논리 결과 중에 하나 출력 (TRUE/FALSE/NULL)
-> 단, 비교하는 두 컬럼 값/표현식은 서로 동일 데이터 타입일 것.
연결 연산자
-> 연결 연산자는 ||를 사용하여 여러 컬럼을 하나의 컬럼인 것처럼 연결하거나 컬럼과 리터럴을 연결할 수 있다.
비교 연산자 - BETWEEN AND
-> 비교하려는 값이 지정한 범위에 포함되면 TRUE를 리턴하는 연산자
(비교값 포함)
작은 따옴표 : 문자열을 감싸주는 용도
큰 따옴표 : 컬럼명을 감싸주는 용도비교 연산자 - LIKE
-> 비교하려는 값이 지정한 특정 패턴을 만족시키면 TRUE를 리턴하는 연산자로 %와 _를 와일드 카드로 사용 가능
와일드 카드 : 대체해서 사용할 수 있는 것
_ : 한문자 , % : 모든 것을 의미비교 연산자 - NOT LIKE
-> LIKE와 사용법은 동일하며 비교하려는 값과 일치하지 않는 것을 검색
비교 연산자 - IS NULL / IS NOT NULL
-> NULL 여부를 비교하는 연산자
비교 연산자 - IN
-> 비교하려는 값 목록에 일치하는 값이 있으면 TRUE를 반환하는 연산자
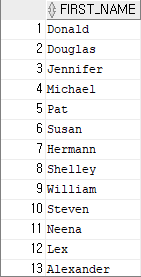
예제 1)
select first_name
from employees;
-- employees 테이블 중 first_name 열 출력결과 1)
예제 2)
select first_name, salary, department_id
from employees
where first_name = 'Den';
-- 문자나 날짜의 경우에는 홑 따옴표를 붙여야 한다.
-- first_name이 Den인 데이터를 출력 (데이터 완전히 일치)
-- 홑 따옴표를 붙이지 않을 경우 에러 발생하며, 대소문자 구분한다.결과 2)

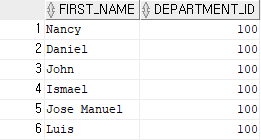
예제 3)
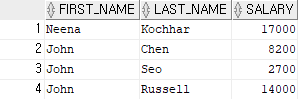
select first_name, last_name, salary
from employees
where first_name in ('Neena', 'John');
-- first_name이 Neena, John인 사람의 정보를 출력
-- in 연산자는 속도가 빠르다.결과 3)
예제 4)
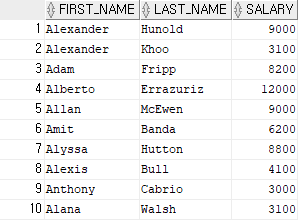
select first_name, last_name, salary
from employees
where first_name like 'A%';
-- first_name이 대문자 A로 시작하는 모든 사람들을 출력결과 4)
예제 5)
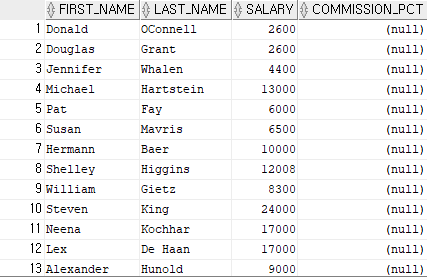
select first_name, last_name, salary, commission_pct
from employees
where commission_pct is null;
-- commission_pct에서 데이터의 값이 null인 값들을 출력
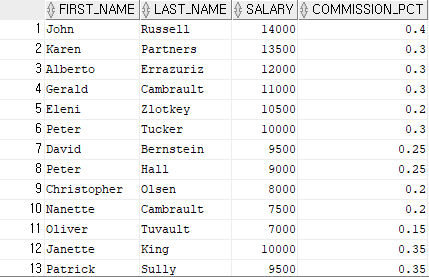
select first_name, last_name, salary, commission_pct
from employees
where commission_pct is not null;
-- commission_pct의 데이터가 null이 아닌 모든 데이터의 값들을 출력.결과 5)
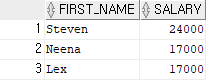
예제 6)
select first_name, salary
from employees
where salary > 20000;
-- salary가 20000보다 큰 데이터의 값들을 employees 테이블에서 찾아서 출력결과 6)

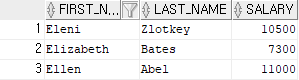
예제 7)
select first_name, last_name, salary
from employees
where first_name like 'E%';
-- first_name의 데이터 중에 앞 글자가 E로 시작하는 모든 데이터의 값들을
employees 테이블에서 찾아 출력.
결과 7)
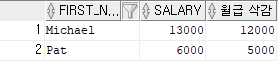
예제 8)
select first_name, salary, salary-1000 as "월급 삭감"
from employees
where department_id = 20;
-- department_id의 값이 20인 데이터를 employees 테이블에서 찾아서
-- salary의 값과 salary에서 1000을 차감한 값, first_name을 출력.결과 8)
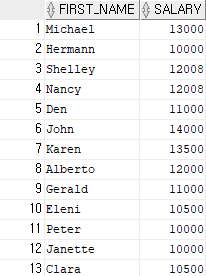
예제 9)
select first_name, salary
from employees
where salary between 10000 and 15000;
-- salary의 값이 10000이상 15000 이하인 데이터의 값들을 employees 테이블에서 찾아서 출력.결과 9)
예제 10)
select first_name, salary, department_id
from employees
where salary >10000
and department_id = 100;
-- and 연산자를 사용해서 salary의 값이 10000이상인 동시에 department_id가 100인 데이터를 출력결과 10)

연산자 우선 순위
-> 여러 연산자를 사용할 경우 우선순위를 고려해서 사용 해야한다.
1. 산술
2. 연결
3. 비교
4. IS NULL / IS NOT NULL , LIKE , IN / NOT IN
5. BETWEEN AND / NOT BETWEEN AND
6. 논리 (NOT)
7. 논리 (AND)
8. 논리 (OR)
※ 1 ~ 8로 갈수록 우선 순위가 낮다ORDER BY
-> SELECT한 결과물에 대해 정렬을 할 때 사용하는 구문
-> SELECT 구문의 가장 마지막에 작성하며, 실행순서도 가장 마지막에 수행
표현식
SELECT 컬럼1,컬럼2,컬럼3...
FROM 테이블명
WHERE 조건절
ORDER BY 컬럼명|별칭|컬럼순서 정렬방식데이터 정렬 방법
| NUMBER | CHARACTER | DATE | NULL |
|---|---|---|---|
| ASC | 작은수->큰수 | 빠른날->늦은날 | 맨아래 행 (NULL이 맨 아래) |
| DESC | 큰수->작은수 | 늦은날->빠른날 | 맨 위 행(NULL이 맨 위) |
※ ASC : 오름차순 (DEFAULT)
-> 지정한 컬럼 기준으로 오름차순으로 정렬
-> default : ASC 정렬
※ DESC : 내림차순
-> 지정한 컬럼 기준으로 내림차순으로 정렬
예제)
select first_name, salary, department_id, hire_date
from employees
where salary>10000
order by first_name;
-- order by 구문을 사용하여 오름차순 정렬
-- first_name 기준으로 오름차순 정렬※ order by는 컬럼명을 지정해도 되지만, 숫자로도 지정이 된다.
ex) select 구문이 3개 선언이 되었을 때 order by 1 = 첫번째 컬럼명 기준(SELECT 구문 범주 내)
결과)