함수 (Function)
-> 하나의 큰 프로그램에서 반복적으로 사용되는 부분들을 분리하여 작성해 놓은 작은 서브 프로그램.
->호출하여 값을 전달하면 수행 결과를 리턴하는 방식으로 사용
값 전달 및 호출 -> 작업 수행 -> 결과값 리턴
함수의 유형
-
단일 행 함수 : 각 행 마다 반복적으로 적용되어 입력 받은 행의 개수만큼 결과를 반환
-
그룹 함수 : 특정한 행들의 집합으로 그룹이 형성되어 적용 됨(그룹당 1개의 결과를 반환)
문자 처리 함수
| 구분 | 입력값 타입 | 리턴값 타입 | 설명 |
|---|---|---|---|
| LENGTH | 문자열의 길이를 반환 | ||
| LENGTHB | 문자열의 바이트 크기를 반환 | ||
| INSTR | 특정 문자의 위치를 반환 | ||
| INSTRB | 특정 문자의 위치 바이트 크기를 반환 | ||
| LPAD | 문자열을 지정된 숫자만큼의 크기로 설정하고, 지정한 문자를 왼쪽부터 채워서 생성된 문자열 리턴 | ||
| RPAD | 문자열을 지정된 숫자만큼의 크기로 설정하고, 지정한 문자를 오른쪽부터 채워서 생성된 문자열을 리턴 | ||
| RTRIM | 왼쪽부터 지정한 문자를 잘라내고 남은 문자를 리턴 | ||
| LTRIM | CHARACTER | NUMBER | 오른쪽부터 지정한 문자를 잘라내고 남은 문자를 리턴 |
| TRIM | 왼쪽/오른쪽/양쪽부터 지정한 문자를 잘라내고 남은 문자를 리턴 | ||
| SUBSTR | 지정한 위치에서 지정한 길이만큼 문자를 잘라내어 리턴 | ||
| SUBSTRB | 지정한 위치에서 지정한 바이트만큼 문자를 잘라내어 리턴 | ||
| LOWER | 전달받은 문자/문자열을 소문자로 변환하여 리턴 | ||
| UPPER | 전달받은 문자/문자열을 대문자로 변환하여 리턴 | ||
| INITCAP | 전달받은 문자/문자열의 첫 글자를 대문자로, 나머지 글자는 소문자로 변환하여 리턴 | ||
| CONCAT | 인자로 전달받은 두 개의 문자/문자열을 합쳐서 리턴 | ||
| REPLACE | 전달받은 문자열 중에 지정한 문자를 인자로 전달받은 문자로 변환하여 리턴 |
LENGTH
-> 주어진 컬럼 값/문자열의 길이 (문자 개수)를 반환하는 함수
| 작성법 | 리턴값 타입 | 파라미터 (인자값) |
|---|---|---|
| LENGTH(COLUMN or STRING) | NUMBER | CHARACTER 타입의 컬럼 또는 임의의 문자열 |
LENGTHB
-> 주어진 컬럼 값/문자열의 길이(BYTE)를 반환하는 함수
| 작성법 | 리턴값 타입 | 파라미터 |
|---|---|---|
| LENGTHB(COLUMN or STRING) | NUMBER | CHARACTER 타입의 컬럼 또는 임의의 문자열 |
INSTR
-> 찾는 문자(열)이 지정한 위치부터 지정한 횟수만큼 나타난 시작 위치를 반환
| 작성법 | 리턴값 타입 |
|---|---|
| INSTR(STRING,STR,[POSITION,[OCCURRENCE]] | NUMBER |
| 파라미터 | 설명 |
|---|---|
| STRING | 문자타입 컬럼 또는 문자열 |
| STR | 찾으려는 문자(열) |
| POSITION | 찾을 위치 시작 값(기본값 1) POSITION > 0 STRING의 시작부터 끝 방향으로 찾기 POSITION < 0 STRING의 끝부터 시작 방향으로 찾기 |
| OCCURRENCE | 검색된 STR의 순번(기본값 1), 음수 사용 불가 |
※ 시작위치의 INDEX 값은 0이 아닌 1부터 시작
LPAD / RPAD
-> 주어진 컬럼 문자열에 임의의 문자열을 왼쪽/오른쪽에 덧붙여 길이 N의 문자열을
반환하는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| LPAD(STRING,N,[STR])/RPAD(STRING,N,[STR]) | CHARACTER |
| 파라미터 | 설명 |
|---|---|
| STRING | 문자 타입 컬럼 또는 문자열 |
| N | 반환할 문자(열)의 길이(바이트) 원래 STRING 길이보다 작다면 N만큼 잘라서 표시 |
| STR | 덧붙이려는 문자(열), 생략 시 공백 문자 |
LTRIM / RTRIM
-> 주어진 컬럼이나 문자열의 왼쪽 혹은 오른쪽에서 지정한 STR에 포함된 모든 문자를
제거한 나머지를 반환
| 작성법 | 리턴값 타입 |
|---|---|
| LTRIM(STRING,STR)/RTRIM(STRING,STR) | CHARACTER |
| 파라미터 | 설명 |
|---|---|
| STRING | 문자 타입 컬럼 또는 문자열 |
| STR | 제거하려는 문자(열), 생략하면 공백문자 |
TRIM
-> 주어진 컬럼이나 문자열의 앞/뒤/양쪽에 있는 지정한 문자를 제거하여 나머지를 반환
| 작성법 | 리턴값 타입 |
|---|---|
| TRIM(STRING) | CHARACTER |
| TRIM(CHAR FROM STRING) | CHARACTER |
| TRIM(LEADING or TRAILING or BOTH [CHAR] FROM STRING) | CHARACTER |
| 파라미터 | 설명 |
|---|---|
| STRING | 문자 타입 컬럼 또는 문자열 |
| CHAR | 제거하려는 문자, 생략하면 공백문자 ※ TRIM은 문자 1글자만 가능 |
| LEADING | TRIM할 CHAR의 위치를 지정 앞(LEADING), 뒤(TRAILING), 양쪽(BOTH) 지정 가능 (기본값은 양쪽) |
SUBSTR
-> 컬럼이나 문자열에서 지정한 위치부터 지정한 개수의 문자열을 잘라내어 리턴하는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| SUBSTR(STRING,POSITION,[LENGTH]) | CHARACTER |
| 파라미터 | 설명 |
|---|---|
| STRING | 문자 타입 컬럼 또는 문자열 |
| POSITION | 문자열을 잘라낼 위치 양수이면 시작 방향에서 지정한 수 만큼의 위치를 의미 음수이면 끝 방향에서 지정한 수 만큼의 위치를 의미 |
| LENGTH | 반환할 문자의 개수를 의미 (생략시 문자열의 끝까지를 의미, 음수이면 NULL을 리턴) |
LOWER / UPPER / INITCAP
-> 컬럼의 문자 혹은 문자열을 소문자/대문자/단어별 첫글자만 대문자로 변환하여 리턴하는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| LOWER(STRING) / UPPER(STRING) / INITCAP(STRING) | CHARACTER |
LOWER : 소문자
UPPER : 대문자
INITCAP : 각 단어 별 첫 글자만
| 파라미터 | 설명 |
|---|---|
| STRING | 문자 타입 컬럼 또는 문자열 |
CONCAT
-> 컬럼의 문자 혹은 문자열을 두 개 전달 받아 하나로 합친 후 리턴하는 함수
-> || 와 동일
| 작성법 | 리턴값 타입 |
|---|---|
| CONCAT(STRING,STRING) | CHARACTER |
| 파라미터 | 설명 |
|---|---|
| STRING | 문자 타입 컬럼 또는 문자열 |
REPLACE
-> 컬럼의 문자 혹은 문자열을 두 개(변경할,변경될)의 문자열 값을 전달 받아 변경 후 리턴
| 작성법 | 리턴값 타입 |
|---|---|
| REPLACE(STRING,STR1,STR2) | CHARACTER |
| 파라미터 | 설명 |
|---|---|
| STRING | 문자 타입 컬럼 또는 문자열 |
| STR1 | 변경대상이 되는 문자 혹은 문자열 |
| STR2 | 변경할 문자 혹은 문자열 |
숫자 처리 함수
| 구분 | 입력값 타입 | 리턴값 타입 | 설명 |
|---|---|---|---|
| ABS | 절대값을 구하여 리턴 | ||
| MOD | 입력받은 수를 나눈 나머지 값을 반환 | ||
| ROUND | NUMBER | NUMBER | 특정 자릿수에서 반올림 |
| FLOOR | 소수점 아래를 잘라내고 리턴(버림) | ||
| TRUNC | 특정 자릿수에서 잘라내고 리턴(버림) | ||
| CEIL | 지정한 자릿수에서 올림하여 리턴 |
ABS
-> 인자로 전달받은 숫자의 절대값을 구하는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| ABS(NUMBER) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| NUMBER | 숫자 혹은 숫자 데이터 컬럼 |
MOD
-> 인자로 전달받은 숫자를 나누어 나머지를 구하는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| MOD(NUMBER,DIVISION) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| NUMBER | 숫자 혹은 숫자 데이터 컬럼 |
| DIVISION | 나눌 수(값) 혹은 나눌 숫자 데이터 컬럼 |
ROUND
-> 인자로 전달 받은 숫자 혹은 컬럼에서 지정한 위치 이후 값을 반올림하여 리턴
| 작성법 | 리턴값 타입 |
|---|---|
| ROUND(NUMBER) | NUMBER |
| ROUND(NUMBER,POSITION) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| NUMBER | 숫자 혹은 숫자 데이터 컬럼 |
| POSITION | 반올림 할 위치 자리 |
FLOOR
-> 인자로 전달받은 숫자 혹은 컬럼의 소수점 자리 수를 버리는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| FLOOR(NUMBER) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| NUMBER | 숫자 혹은 숫자 데이터 컬럼 |
TRUNC
-> 인자로 전달받은 숫자 혹은 컬럼의 지정한 위치 이후 소수점 자리 수를
버리는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| TRUNC(NUMBER,POSITION) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| NUMBER | 숫자 혹은 숫자 데이터 컬럼 |
| POSITION | 버림 할 위치 자리 |
CEIL
-> 인자로 전달받은 숫자 혹은 컬럼을 올림 계산하여 나온 값을 리턴 하는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| CEIL(NUMBER) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| NUMBER | 숫자 혹은 숫자 데이터 컬럼 |
날짜 처리 함수
| 구분 | 입력값 타입 | 리턴값 타입 | 설명 |
|---|---|---|---|
| SYSDATE | DATE | 시스템에 저장된 현재 날짜를 반환 | |
| MONTHS_BETWEEN | DATE | NUMBER | 두 날짜를 전달받아 몇 개월 차이인지 계산하여 반환 |
| ADD_MONTHS | 특정 날짜에 개월 수를 더한다. | ||
| NEXT_DAY | 특정 날짜에서 최초로 다가오는 인자로 받은 요일의 날짜를 반환 | ||
| LAST_DAY | 해당 달의 마지막 날짜를 반환 | ||
| EXTRACT | 년, 월, 일 정보를 추출하여 반환 |
SYSDATE
-> 시스템에 저장되어 있는 현재 날짜를 반환하는 함수
SELECT SYSDATE FROM DUAL; -> 현재 시간을 반환하여 출력※ 그외 현재 시각 알려주는 명령어
CURRENT_DATE, LOCALTIMESTAMP, CURRENT_TIMESTAMP
SELECT CURRENT_DATE FROM DUAL;
SELECT LOCALTIMESTAMP FROM DUAL;
SELECT CURRENT_TIMESTAMP FROM DUAL;MONTHS_BETWEEN
-> 인자로 날짜 두 개를 전달받아, 개월 수의 차이를 숫자 데이터형으로 리턴하는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| MONTHS_BETWEEN(DATE1,DATE2) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| DATE1 | 기준이 되는 날짜를 입력 |
| DATE2 | 개월 수를 구하려는 날짜를 입력 |
ADD_MONTHS
-> 인자로 전달받은 날짜에 인자로 전달받은 숫자만큼 개월 수를 더하여 특정 날짜를 리턴하는 함수
| 작성법 | 리턴값 타입 |
|---|---|
| ADD_MONTHS(DATE,NUMBER) | DATE |
| 파라미터 | 설명 |
|---|---|
| DATE | 기준이 되는 날짜를 입력 |
| NUMBER | 더하려는 개월 수를 입력 |
NEXT_DAY
-> 인자로 전달받은 날짜에 인자로 전달받은 요일 중 가장 가까운 다음 요일을 출력
| 작성법 | 리턴값 타입 |
|---|---|
| NEXT_DAY(DATE,STRING [OR NUMBER]) | DATE |
| 파라미터 | 설명 |
|---|---|
| DATE | 기준이 되는 날짜를 입력 |
| STRING[OR NUMBER] | 구하려는 요일을 입력 (숫자의 경우 1=일요일,....7=토요일) |
LAST_DAY
-> 인자로 전달받은 날짜가 속한 달의 마지막 날짜를 구하여 리턴
| 작성법 | 리턴값 타입 |
|---|---|
| LAST_DAY(DATE) | DATE |
| 파라미터 | 설명 |
|---|---|
| DATE | 기준이 되는 날짜를 입력 |
EXTRACT
-> 년,월,일 정보를 추출하여 리턴
| 작성법 | 리턴값 타입 |
|---|---|
| EXTRACT(YEAR FROM DATE) | DATE |
| EXTRACT(MONTH FROM DATE) | DATE |
| EXTRACT(DAY FROM DATE) | DATE |
| 파라미터 | 설명 |
|---|---|
| DATE | 기준이 되는 날짜를 입력 |
형 변환 함수
| 구분 | 입력값 타입 | 리턴값 타입 | 설명 |
|---|---|---|---|
| TO_CHAR | DATE,NUMBER | CHARACTER | 날짜형 혹은 숫자형을 문자형으로변환 |
| TO_DATE | CHARACTER | DATE | 문자형을 날짜형으로 변환 |
| TO_NUMBER | CHARACTER | NUMBER | 문자형을 숫자형으로 변환 |
TO_CHAR
-> 날짜형 데이터를 문자형 데이터로 변환하거나, 숫자데이터를 문자형 데이터로 변환하여
리턴
| 작성법 | 리턴값 타입 |
|---|---|
| TO_CHAR(DATE,[FORMAT]) | DATE |
| TO_CHAR(NUMBER,[FORMAT]) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| DATE | 문자형으로 변환하려는 날짜형 데이터 |
| NUMBER | 문자형으로 변환하려는 숫자형 데이터 |
| FORMAT | 문자형으로 변환시 지정되는 출력 형식 |
| 날짜 -> 문자로 바꾸는 형식 | 설명 |
|---|---|
| YYYY | 년도표현(4자리) |
| YY | 년도 표현(2자리) |
| MONTH | 월 표시 |
| MM | 월을 숫자로 표현 |
| MON | 월을 알파벳으로 표현 |
| DD | 날짜 표현 |
| D | 요일을 숫자로 표현(1:일요일..) |
| DAY | 요일 표현 |
| DY | 요일을 약어로 표현 |
| HH,HH12 | 시간(12시간으로 표현) |
| HH24 | 시간(24시간으로 표현) |
| MI | 분 |
| SS | 초 |
| AM,PM | 오전,오후 표기 |
| FM | 월,일,시,분,초 앞의 0을 제거 |
숫자 -> 문자로 바꾸는 형식
| FORMAT | 예시 | 설명 |
|---|---|---|
| ,(comma) | 9,999 | 콤마 형식으로 변환 |
| .(period) | 99.99 | 소수점 형식으로 변환 |
| 0 | 09999 | 왼쪽에 0을 삽입 |
| $ | $9999 | $통화로 표시 |
| L | L9999 | Local통화로 표시(한국의 경우) |
-> 숫자 표시 단위는 충분한 크기를 주어야 한다
-> 변환될 숫자의 길이보다 포맷의 길이가 작으면 정상적으로 표시가 안된다.
-> 0과 9를 이용하여 최대 자리수를 표현 해야 한다.
TO_DATE
-> 숫자 혹은 문자형 데이터를 날짜형 데이터로 변환하여 리턴
| 작성법 | 리턴값 타입 |
|---|---|
| TO_DATE(CHARACTER,[FORMAT]) | DATE |
| TO_DATE(NUMBER,[FORMAT]) | NUMBER |
| 파라미터 | 설명 |
|---|---|
| CHARACTER | 날짜형으로 변환하려는 문자형 데이터 |
| NUMBER | 날짜형으로 변환하려는 숫자형 데이터 |
| FORMAT | 날짜형으로 변환시 입력 포맷 지정 |
※ 포맷형식은 위에 TO_CHAR에 있는것 사용
TO_NUMBER
-> 날짜 혹은 문자형 데이터를 숫자형 데이터로 변환하여 리턴
| 작성법 | 리턴값 타입 |
|---|---|
| TO_NUMBER(CHARACTER,[FORMAT]) | DATE,NUMBER |
| 파라미터 | 설명 |
|---|---|
| CHARACTER | 날짜형으로 변환하려는 문자형 데이터 |
| FORMAT | 숫자형으로 변환 시 입력 포맷 지정 |
NULL 처리 함수 - NVL
-> NULL로 되어 있는 컬럼의 값을 지정한 숫자 혹은 문자로 변경하여 리턴
| 작성법 | 리턴값 타입 |
|---|---|
| NVL(P1,P2) | NUMBER,CHARACTER |
| 파라미터 | 설명 |
|---|---|
| P1 | NULL 데이터를 처리할 컬럼명 혹은 값 |
| P2 | NULL 값을 변경(대체)하고자 하는 값 |
SELECT NVL(BONUS,0)
FROM EMPLOYEES;DECODE - 선택 함수
-> 여러 가지 경우에 선택을 할 수 있는 기능을 제공하는 함수 (일치하는 값)
DECODE(표현식,조건1,결과1,조건2,결과2,....)
| 파라미터 | 설명 |
|---|---|
| 표현식 | 값에 따라 선택을 다르게 할 컬럼 혹은 값 입력 |
| 조건 | 해당 값이 참인지 거짓인지 여부를 판단 |
| 결과 | 해당 조건과 일치하는 경우 결과를 리턴 |
| DEFAULT | 모든 조건이 불일치시 리턴할 값 |
CASE
-> 여러 가지 경우에 선택을 할 수 있는 기능을 제공
-> 범위 조건도 가능
작성법
CASE
WHEN 조건1 THEN 결과1
WHEN 조건2 THEN 결과2
WHEN 조건3 THEN 결과3
ELSE 결과N
END
※ ELSE는 그외
※ CASE는 끝을 의미하는 END를 붙여야 한다.
| 파라미터 | 설명 |
|---|---|
| 조건 | 해당 값이 참인지 거짓인지 여부를 판단 |
| 결과 | 해당 조건과 일치하는 경우 결과를 리턴 |
| ELSE | 모든 조건이 불일치시 리턴할 값 |
그룹 함수
-> 하나 이상의 행을 그룹으로 묶어 연산하여 총합,평균 등을 하나의 컬럼으로 리턴하는 함수
| 구분 | 설명 |
|---|---|
| SUM | 그룹의 누적 합계 리턴 |
| AVG | 그룹의 평균을 리턴 |
| COUNT | 그룹의 총 개수를 리턴 |
| MAX | 그룹의 최대값을 리턴 |
| MIN | 그룹의 최소값을 리턴 |
SUM
-> 해당 컬럼 값들의 총 합을 구하는 함수
AVG
-> 해당 컬럼 값들의 평균을 구하는 함수
COUNT
-> 테이블에서 조건을 만족하는 행의 개수를 반환하는 함수
MAX/MIN
-> 그룹의 최대값과 최소값을 구하는 함수
예제 1)
select department_id, salary
from employees
where salary>10000
and department_id =90
union
select department_id, salary
from employees
where salary>10000
and department_id = 80;
-- union으로 결과를 모아서 출력
-- 자동으로 정렬을 오름차순으로 해준다.
-- 첫번째 컬럼으로 오름차순 정렬 해줬다가 동일한 데이터 값이 있을 경우 두번째 컬럼으로 오름차순 정렬을 한다.
select department_id, salary
from employees
where salary > 10000
and department_id = 90
union all
select department_id, salary
from employees
where salary > 10000
and department_id = 80;
-- union은 중복 값을 제거하였고, union all은 중복 값을 제거하지 않고 모든 내용을 출력한다.결과 1)
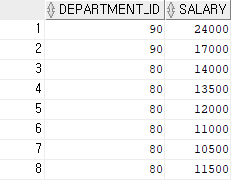
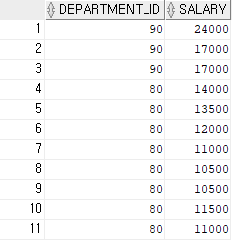
UNION은 합집합을 의미하며 SELECT 구문 2개 이상을 결합할 때 사용한다.
※ 특징
UNION : 중복 값을 제거
UNION ALL : 중복 값 포함
예제 2)
select salary
from employees
where department_id >=70
intersect
select salary
from employees
where department_id <70;
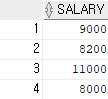
--department_id의 값이 70 이상인 부서와 70 미만인 부서의 공통 값 된 데이터를 찾는 방법
-- intersect 연산자는 공통으로 있는 데이터를 출력한다.
-- 단 자주 쓰면 속도가 느려지기 때문에 주의
INTERSECT : 공통으로 있는 데이터를 출력
결과 2)
예제 3)
select salary
from employees
minus
select salary
from employees
where department_id =100;
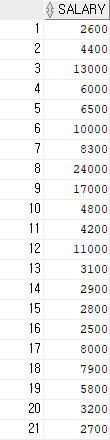
-- minus는 개수와 데이터 형태를 맞춰야 하고, 특정 결과를 제외한 결과를 출력한다MINUS : 차집합을 계산
- 기존 데이터 집합을 기준으로 공통된 부분을 제외한 데이터 출력
즉, 위 예제 코드에서 employees 테이블 결과에서 department_id가 100인 데이터를 제외한 나머지 결과를 출력함을 의미한다.
결과 3)
예제 4)
select first_name, initcap(first_name)
from employees
where department_id = 100;
-- first_name에서 initcap를 쓰면 첫 글자만 대문자로 출력하고 나머지는 소문자로 출력한다.결과 4)
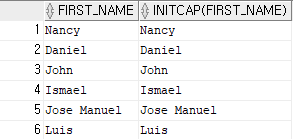
위 결과는 기본적으로 FIRST_NAME의 데이터가 첫글자는 대문자로 되어있어 동일 결과가 출력되었다.
그래서 예시로 결과를 하나 도출해본다.
select initcap('henry')
from dual;
-- dual 은 임시 테이블이다.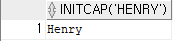
예제 5)
select first_name, lower(first_name), upper(first_name)
from employees
where department_id=100;
-- lower함수와 upper 함수는 각각 모든 문자를 소문자, 대문자로 바꾸는 함수결과 5)
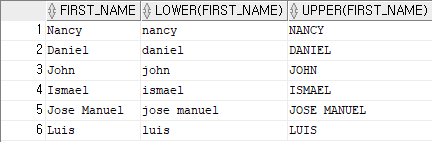
예제 6)
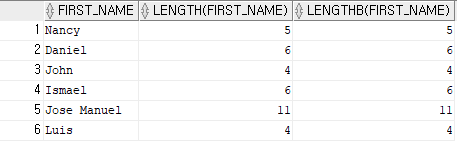
select first_name, length(first_name), lengthb(first_name)
from employees
where department_id =100;
-- 일반적으로 사용하는 데이터는 1글자당 2byte인데 문자열 길이를 계산해 줄 때 주로 사용
-- 보통 한 글자를 입력 받거나 사용자가 입력한 ID의 글자 수를 찾아야할 때 등 이럴 때 요긴하게 사용결과 6)
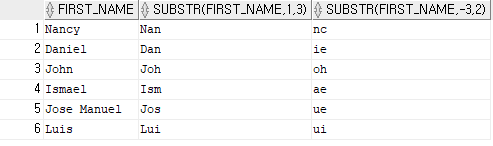
예제 7)
select first_name, substr(first_name,1,3), substr (first_name, -3,2)
from employees
where department_id =100;
-- substr = 문자열의 특정 부분을 골라내는 함수, -를 붙이지 않을 경우 왼쪽 -> 오른쪽
-- -를 붙일 경우 오른쪽 -> 왼쪽 형식으로 체크 한다. 즉 first_name, 1,3을 하면 왼쪽 1번째부터 3번째까지 출력
-- 골라낼 글자 수를 지정하지 않으면 자동으로 마지막 글자로 설정이 된다.
-- substrb를 쓸 경우에는 글자 수가 아닌 바이트 단위로 할당이 된다.결과 7)
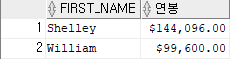
예제 8)
select first_name, to_char(salary*12,'$999,999.99') "연봉"
from employees
where department_id = 110;
-- to_char 함수는 형 변환 함수로 숫자를 문자 형으로 바꾸는 함수
-- 연봉 컬럼에 변환하여 출력결과 8)
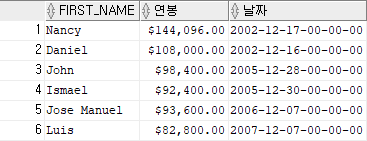
예제 9)
select first_name, to_char(salary*12,'$999,999.99')"연봉",
to_char(hire_date,'RRRR-HH-DD-HH24-MI-SS')"날짜"
from employees
where department_id =100;
-- 날짜를 문자로 변환하는 방식결과 9)
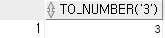
예제 10)
select to_number ('3')
from dual;
--숫자처럼 생긴 문자를 숫자로 바꿔준다.
select to_number('C')
from dual;
-- 문자를 함수로 변환하면 에러가 나타난다.
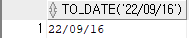
select to_date ('22/09/16')
from dual;
-- 날짜처럼 생긴 문자를 날짜로 바꿔주는 함수결과 10)
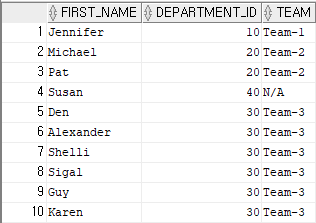
예제 11)
select first_name, department_id,
decode(department_id,'10','Team-1','20','Team-2','30','Team-3','N/A') "TEAM"
from employees
where department_id <50;
-- if문을 오라클 안으로 가져온 함수, 조건문 처리하는데 사용한다.
-- decode (A, B,'1',null) <- 단 마지막 null은 생략 가능하며 A가 B일 경우 1을 출력하고, 아닐 경우 null을 출력결과 11)
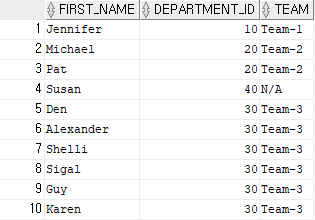
예제 12)
select first_name, department_id,
case department_id when 10 then 'Team-1'
when 20 then 'Team-2'
when 30 then 'Team-3'
else 'N/A'
end as "TEAM"
from employees
where department_id < 50;
-- end에 컬럼 명 형식으로 나타내고 비교할 때 주로 사용하는 연산자
-- when 결과 then 출력 형식으로 사용, 콤마는 존재하지 않음
-- = 조건으로 사용할 때는 case보다 decode를 더 많이 사용
-- department_id 값이 10이면 Team-1, 20이면 Team-2, 30이면 Team-3으로 출력결과 12)
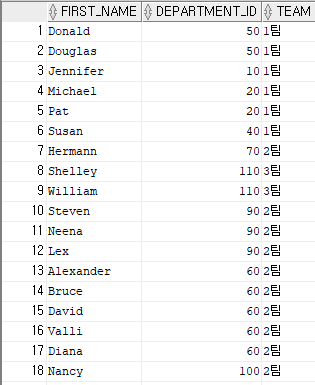
예제 13)
select first_name, department_id,
case when department_id between 10 and 50 then '1팀'
when department_id between 60 and 100 then '2팀'
when department_id between 110 and 150 then '3팀'
else 'N/A'
end "TEAM"
from employees;
-- case문의 경우 현업에서 가장 많이 사용 중이고, decode문 보다 더 넓은 범위에서 사용
-- 비교 조건이 =이 아닌 경우에 이렇게 표현결과 13)
예제 14)
select count (*), count(commission_pct)
from employees;
-- 한꺼번에 여러 데이터를 처리하는 함수
-- *를 쓰면 모든 행을 대상으로 하고, null이 아닌 데이터 건수 출력결과 14)

예제 15)
select count (*), sum(salary), avg(salary)
from employees;
-- avg는 평균값을 구하는 함수, avg함수를 쓸 때는 null 값(NVL 함수) 을 항시 포함해서 사용
-- 예를 들어 평균값을 구할 때, A, B, C 학생이 있는데, A학생 60점, B학생 결석, C학생 50점이면 110/3이 아니라 110/2가 되어야 하기 때문에 null을 사용
-- avg(nvl(salary, 0)) 형식으로 사용결과 15)

