
INTRODUCTION
Basic Definitions
What is "data" ?
- Known facts that can be recorded and have an implicit meaning.
What is "database" ?
- A(n) (organized) collection of related data.
Database Management System(DBMS) ?
- A "software package/system" to enable users to create and maintain a DB
Database System ?
- DB + DBMS (+ DB applications)

Types of Databases and Database Applications
Tranditional & More Recent Applications가 존재
Recent Developments: NoSQL DB (1/2)
NoSQL
- is a term used for a broad group of data management technologies varying in features and functionality
- SQL DB는 Concrete한 개념이지만, NoSQL은 그렇지 않다.
features
- High performance writes and massive scalability
- Data를 쓰는 데 있어 정의된 Schema를 요구하지 않는다.
- Primarily eventually-consistent by default.
- 현대 programming 언어의 넓은 영역 지원 (python, Scala, Go, ...)
- 주로 분산 컴퓨팅에 대해 fault tolerance 지원
Recent Developments: NoSQL DB (2/2)
- ex) MongoDB -> uses the document data model

DATABASE SYSTEM ENVIRONMENT
A "Simplified" Database System Environment

- Query: 일반적으로 어떤 데이터가 검색되도록 함
- Transaction: 일부 데이터가 database에 atomically 하게(더 이상 쪼개질 수 없는) 읽히거나 쓰이도록 함
2) Applications는 인증되지 않은 사용자가 데이터에 접근하는 것을 허용하지 않는다:
- Data Protection을 제공
3) Applications는 DB에 대한 사용자의 요구사항에 대응해야 한다:
- password policy change, authorization change
Typical DBMS Functionality
1) 특정 database를 정의하는데, 그것의 data types, structures 그리고 constraints의 관점에서 정의한다.
2) "Secondary" storage medium인 HDD, SSD와 같은 저장소에 초기 database contents를 구성하거나 로드한다.
3) database를 조작한다:
- Retreival: Querying, generating reports
- Modification: Insertions, deletions and updates to its content
- Access: Web applications를 통해 database에 대한 접근 권한을 가진다.
4) 모든 data이 유효성과 일관성은 유지하면서, 동시 사용자와 application programs의 집합 단위로 Processing가 sharing을 수행한다.
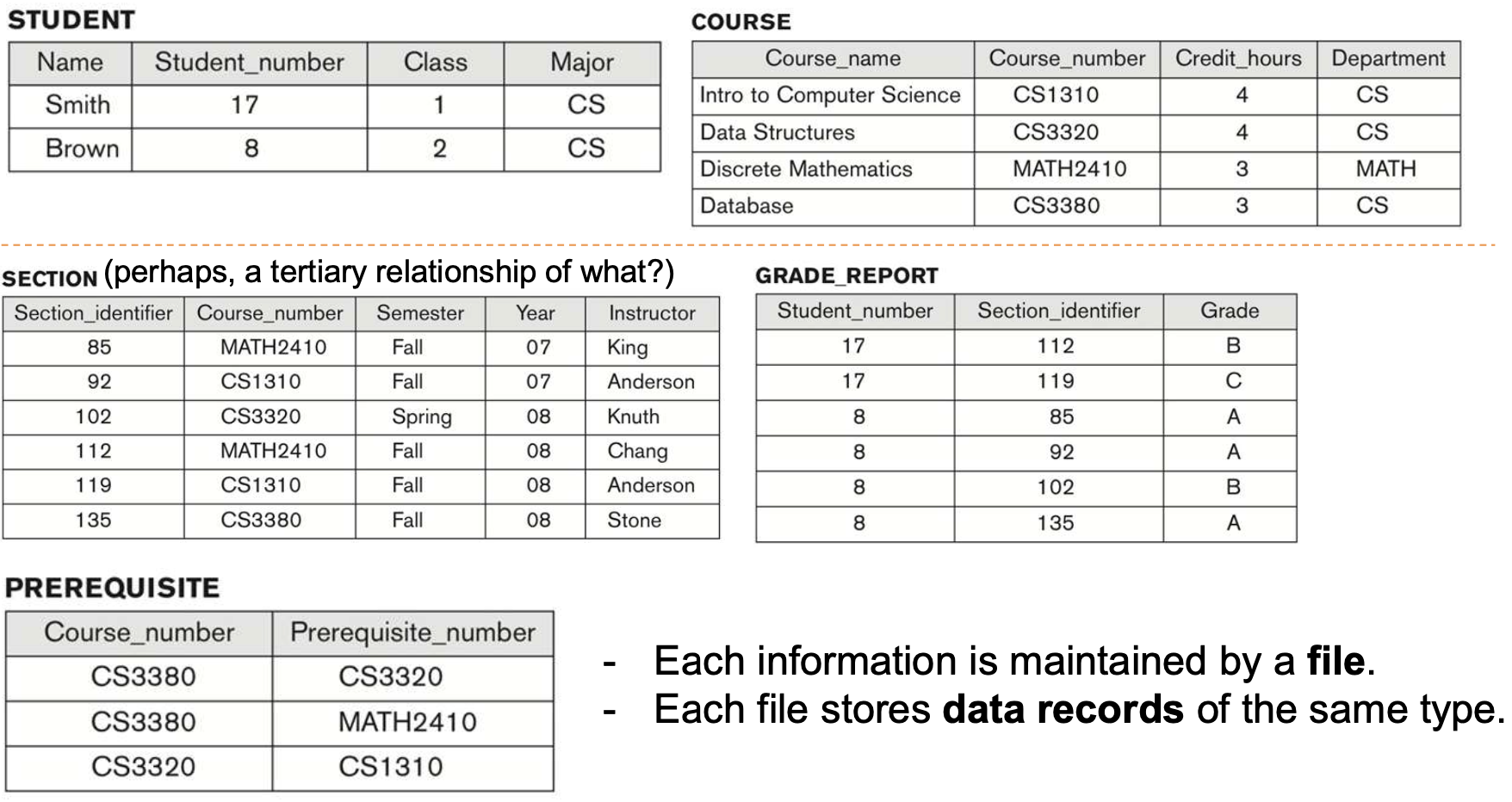
Example of a Database (With a Conceptual Data Model)
- Mini-world for the example: university environment
- Some mini-world entities(개체/엔티티):
- STUDENTs
- COURSEs
- SECTIONs(of COURSEs) (분반)
- (academic) DEPARTMENTs
- INSTRUCTORs
- ...
- Some mini-world has relationship among entities:
- SECTIONs are of specific COURSEs
- STUDENTs take SECTIONs
- COURSEs have prerequisite COURSEs
- INSTRUCTORs teach SECTIONs
- DEPARTMENTs offers COURSEs
- STUDENTs major in DEPARTMENTs
- ...
- 위의 "entities"와 "relationships"는 일반적으로 conceptual data model에서 표현된다.
Database Design Phases
- Stage 1: Requirement specification and analysis
- Stage 2: Conceptual design (for easily being transformed into a database implementation)
- Stage 3: Logical design (for a data model implemented in a DBMS)
- Stage 4: Physical design (for storing and accessing the database)
MAIN CHARACTERISTICS OF THE DATABASE APPROACH
Main Characteristics of the DB Approach (1/5)
(1) Self-describing nature of a DB system:
- DB system은 DB 자체뿐만 아니라 DB structure, types, and constraints의 complete definition(or description)를 포함한다.
- Catalog: stores the description, called metadata, of a particular DB
- some newest systems (a few NoSQL ones: MongoDB, Cassandra, Redis) don't need metadata.
- data definition을 그 구조안에 바로 저장하는 방식으로 self-describing을 구현 (e.g. 'key': 'value')

Main Characteristics of the DB Approach (2/5)
(2-1) Insulation between programs and data:
- Called program-data independence
- DBMS 접근 프로그램 없이도 data structures와 storage organization을 변경할 수 있다.
- file-processing systems에서는 프로그램에 의해 접근되는 파일의 구조가 변경되면 프로그램을 변경해야 한다.
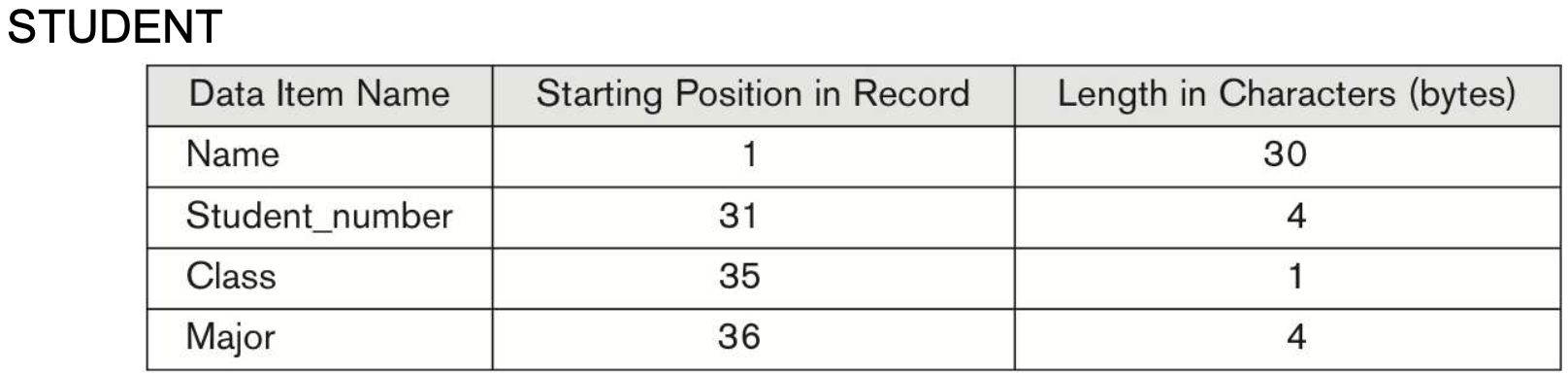
- 만약 STUDENT record에 Birth_Date이라는 attribute를 삽입하려고 한다면 어떻게 될까 ?
- Birth_Date 40 4 정도가 들어갈려나
Main Characteristics of the DB Approach (3/5)
(2-2) Data abstraction:
- program-data와 program-operation(on objects) independence를 허용해주는 특성
- data model의 비공식적인 정의: data 추상화의 유형
- storage details를 숨기고 conceptual view of the DB를 users에게 보여주기 위해 사용
- data가 어떻게 저장되고 접근되는지는 알 필요가 없음 => Declarative property
- Application programs는 data storage 세부 정보보다는 data model 구성을 참조한다.
Main Characteristics of the DB Approach (4/5)
(3) Support of multiple views of the data:
- 각 유저는 DBMS의 서로 다른 view를 볼 것이다.
- 그렇다면 각 유저는 해당 유저가 관심있는 data만을 볼 것이다.
- Ex 1) 어떤 사용자는 각 학생들의 성적표를 확인하고 인쇄하는 것에만 관심이 있다.
- Ex 2) 또 다른 사용자는 학생이 등록한 각 강의에 대해서 해당 학생이 모든 선수과목을 수강하였는지 여부에 대해서만 관심이 있다.
Main Characteristics of the DB Approach (5/5)
(4) Sharing of data and multiuser transaction processing:
- concurrent users의 집합이 DB로부터 데이터를 검색하고 DB를 갱신하는 것을 가능하게 한다. E.g. U1(read) - U2(write) - U3(read) - U4(update) ...
- DBMS의 동시성 제어는 각 transaction이 정상적인 경우에는 정확하게 실행되고, 이상이 있는 경우에는 중단되도록 보장한다.
- Transaction: DB 접근을 포함하는 일련의 statements로 구성되어 실행중인 프로그램이나 프로세스
- ACID (Atomicity, Consistency, Isolation, Durability) 특성을 만족해야 한다.
- Transaction: DB 접근을 포함하는 일련의 statements로 구성되어 실행중인 프로그램이나 프로세스
- Recovery subsystem은 완료된 각 transaction이 DB에 영구적으로 기록되는 것을 보장한다.
- OLTP (OnLine Transaction Processing)은 DB application이 주요 파트이다.
- 매 초단위로 수 백개의 동시적인 transactions가 실행되도록 한다.
ADVANTAGES OF USING THE DB APPROACH
Advantages of Using the DB Approach
Controlling redundancy (중복 제어)
- data storage와 개발/보수 작업 절약 가능
- 이상적으로, 각 논리적 data item(e.g., a student's name or birth date)을 DB의 한 곳에만 저장하도록 DB를 설계해야 한다. 이를 Data normalization(데이터 정규화)라고 한다.
Restricting unauthorized access (비인가 접근 제한)
- E.g., Confidential financial data, type of operation (read and/or update)
- DBMS는 security와 authorization subsystem을 제공해야 한다.
- DBA staff만이 해당 시스템을 이용하여 privileged commands와 facilities를 통해 계정 생성 및 계정 제한을 지정할 수 있다.
Providing persistent storage for program objects (영속 저장)
- Object-oriented(OO) DBMSes는 program object(written in C++ or Java)를 영구화할 수 있다.
- C.f.
Class ObjectOutputStreamin Java - Impedence mismatch problem: (traditional) DBMS가 제공하는 data 구조가 해당 프로그래밍 언어의 data 구조와 호환되지 않는다는 것을 의미한다. 하지만 이는 OODBMS(객체지향 데이터베이스)로 해결된다. (대부분의 이러한 Impedence mismatch problem은 관계형 데이터베이스에서 발생한다 ?)
- C.f.
Providing storage structures (e.g., indexes) for efficient query processing (효율적 질의 처리를 위한 저장 구조 제공)
- 주어진 query에 대응되는 목표 records에 대한 disk search의 속도를 향상시키기 위함이다.
- DBMS는 효율적인 search를 위해 indexes (보조 파일에 저장됨)를 활용한다.
- tree-based or hash-based는 disk block에 최적화되어있다.
- 또한 DB는 스스로의 buffering/caching을 사용할 수 있다.
- ?) 왜 OS의 버퍼링이나 캐싱은 사용하지 않는가 ?
- 1k buffer pages로 1M disk blocksize를 scanning 하는 경우 Sequential Flooding 발생 !
- ?) 왜 OS의 버퍼링이나 캐싱은 사용하지 않는가 ?
Besides, a lot of benefits:
- 효율적인 프로세싱을 위한 query 최적화
- 백업과 recovery 서비스 지원
- 다양한 클래스의 사용자에 대한 multiple interface 지원
- data 간의 복잡한 relationship 표현
- DB의 일관성과 무결성을 위해 무결성 제약 조건 적용
- 참조 무결성 제약조건, 고유 제약 조건
- Triggers: table의 갱신으로 인해 동작되는 규칙의 한 형태로서, 다른 tables에 대한 추가적인 operations를 발생시킨다.
- +) 특정 테이블에 INSERT, DELETE, UPDATE 같은 DML 문이 수행되었을 때, DB에서 자동으로 동작하도록 작성된 프로그램입니다. 사용자가 직접 호출하는 것이 아니라, DB에서 자동적으로 호출하는 것이 가장 큰 특징이다. 참조
WHEN NOT TO USE A DBMS
When Not to Use a DBMS (1/2)
The overhead costs of using a DBMS:
- SW, HW and traing에 있어 비싼 초기 개발 비용
- data를 정의하고 처리하기 위해 DBMS가 제공하는 generality
- security, concurrency control, recovery and integrity funcitons 제공의 Overhead
When a DBMS may be unnecessary:
- DB와 Application이 간단하거나, 잘 정의되어서, 변경이 없을 것으로 예상되는 경우
- data에 대한 Multiple user의 접근이 없는 경우
When running a DBMS may not be possible:
- 제한된 storage 용량을 가진 임베디드 시스템의 경우, 범용 DBMS를 사용할 수 없다. 이런 경우에는 SQLite를 사용할 수 있다.
When Not to Use a DBMS (2/2)
When no general-purpose DBMS may be necessary:
(1) DBMS의 overhead로 인해 몇몇 application program의 엄격한 real-time 요구사항이 충족되지 않을 수 있다.
(2) modeling limitations으로 인해 DB system이 data의 복잡성을 처리할 수 없는 경우
- E.g. in complex genome and protein databases
(3) DBMS가 지원하지 않는 special operations를 필요로 하는 경우 (e.g., GIS and location-based services): resulting in a spatial DBMS using R-tree indexes

배우고 정리하고 공유하기