
DATA MODELS, SCHEMAS, AND INSTANCES
Data Models (데이터 모델)
Data Model
- 데이터 추상화를 이루기 위해 필요한 의미들을 제공한다.
- DB의 structure (구조), 이러한 구조들을 조작하는 operations (연산) 그리고 DB가 따라야 하는 constraints (제약 조건)을 표현한다.
- Structure는
data types, relationships, constraints를 표시한다. - Operation은 DB의 구조를 retrieve(검색)하거나 update(갱신)하기 위해 사용된다.
- insert, delete, update와 같은 basic operation과, 사용자가 직접 정의하여 사용하는 user-defined operation이 있다.
Data Model Structure and Constraints:
- Constructs는 DB 구조를 정의하기 위해 사용된다.
- Constructs는 일반적으로
- groups of elements 뿐 아니라 elements(그리고 그들의 데이터 타입)까지도 포함한다. (elements => attribute, column)
- 또한 그러한 groups 간의 relationships(entity가 필요)도 포함한다.
- Constraints는 "valid" data에 대한 몇몇 제한사항들을 명시한다.
- 이러한 constraints는 항상 지켜져야 하는데, 그렇지 않으면 그 data는 해당 data model을 따른다고 할 수 없다. 즉, data의 유효성을 위해 constraints는 항상 지켜져야 하고, constraints가 존재해야 data의 유효성 검증이 이뤄진다.
Categories of Data Models
Conceptual (high-level, semantic) data models:
- 중요한 개념 정의에 사용한다.
- 많은 사용자가 data를 인지하는 방식에 가깝게 entity, attribute, relationship과 같은 Concepts를 제공한다.
- entity-based(e.g., the ER model) or object-based data models로 불린다.
Physical (low-level, internal) data models:
- 어떻게 data가 computer storage media (e.g. typically HDD or RAM/SSD)에 저장될 지에 대한 설명을 명시하는 Concepts를 제공한다.
- e.g., files, record formats(e.g., row-oriented/column-oriented), and access paths(e.g., primary/non-/clustering indexes)
Implementation (representational, logical) data models:
- High level과 Low level 사이에서 완충한 data model이다.
- relational data models와 같은 상업적 DBMS 구현에서 많이 사용된다.
Self-Describing data models:
- 스스로를 식별하는 data model이다.
- data에 대한 description과 data values가 결합된 형태이다.
- 예시로는 아래의 XML, JSON과 같은 형태가 있다.
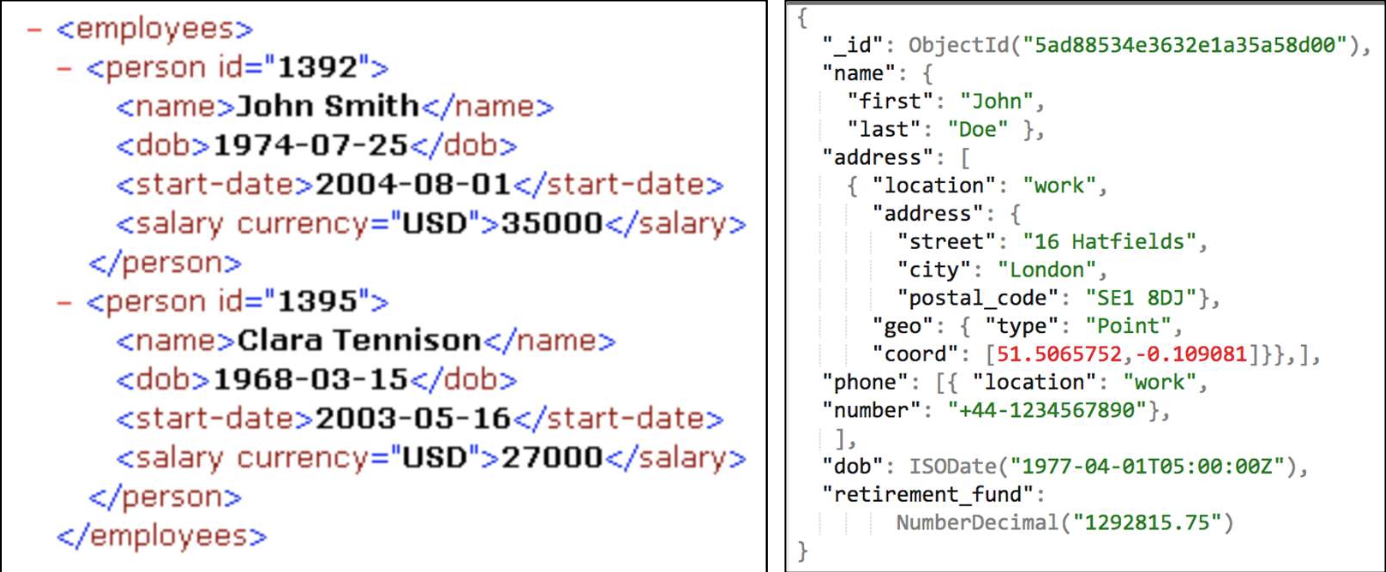
Recall the UNIVERSITY Database
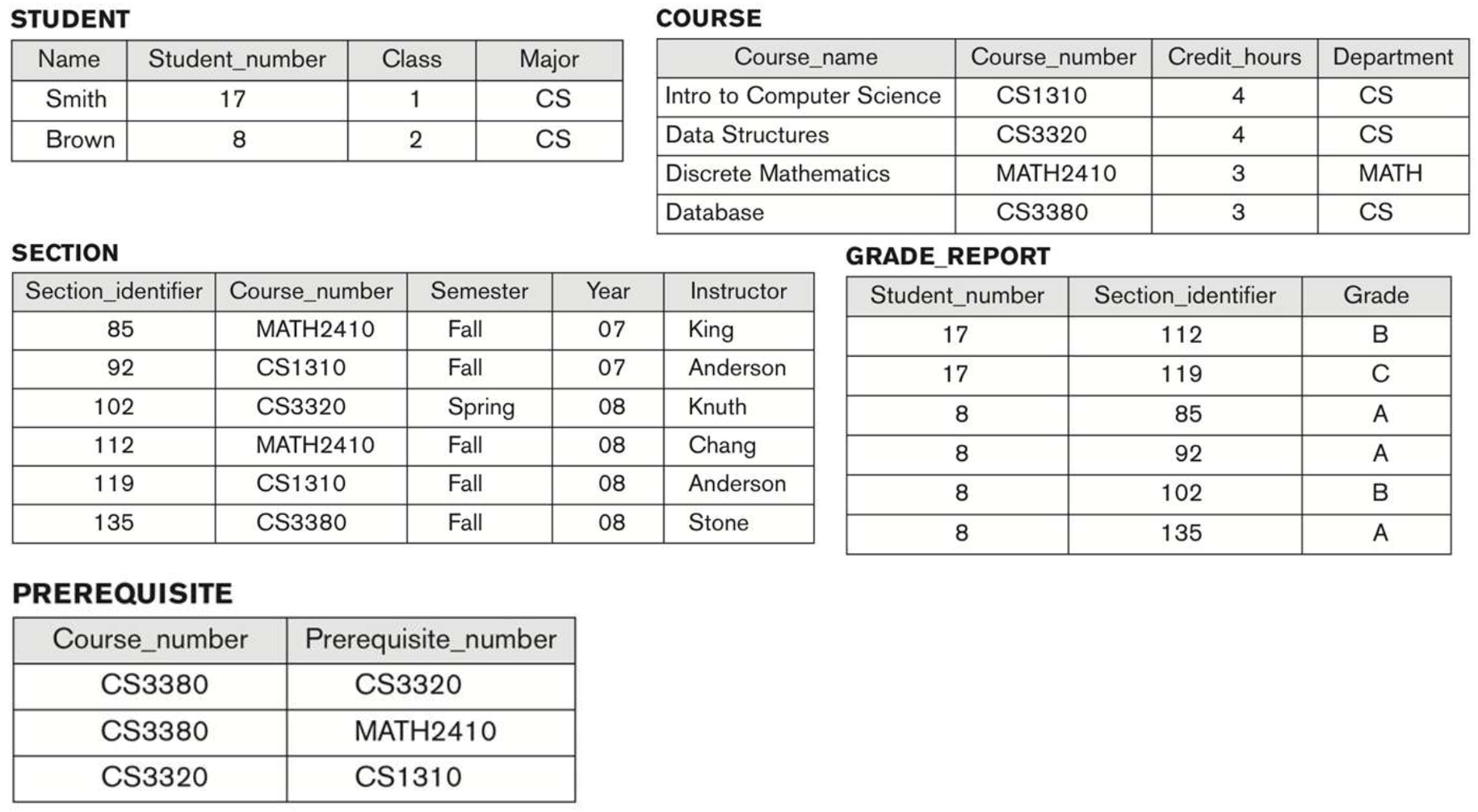
The "Database Schema" of UNIVERSITY
- Database Schema는 구조만 설명하고 관계에 대한 표현은 포함되지 않는다.
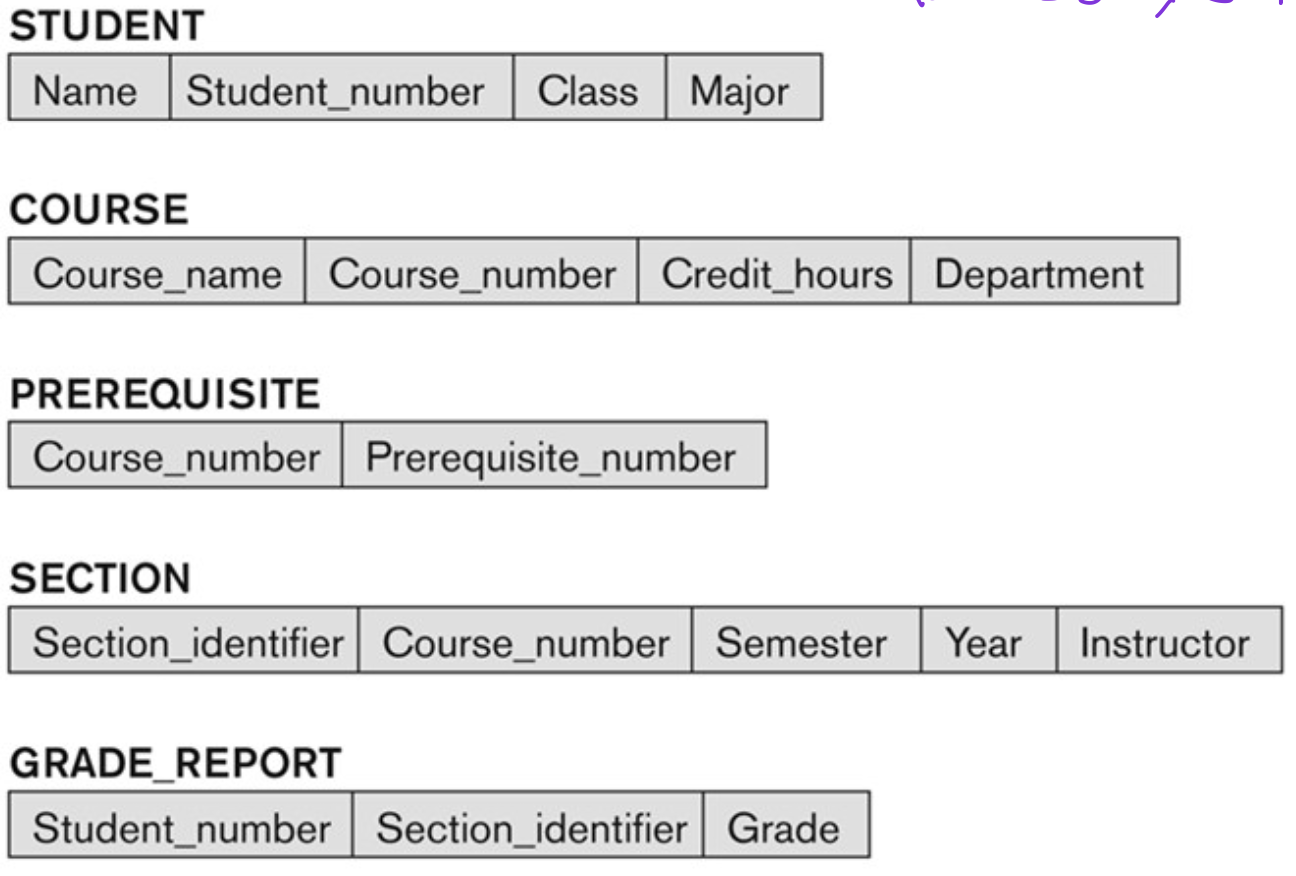
Schemas vs. Instances
Database Schema (intension or meta-data):
- 시간이 지남에 따라 잘 바뀌지 않는다.
- the Description of a database: stored in the DBMS catalog
- 가끔, 특정한 경우에만 schema evolution이 발생할 수 있다.
- database structure의 descriptions, data types, and the constraints가 포함된다.
- Schema construct: schema의 컴포넌트 또는 schema의 object. (e.g., STUDENT or COURSE)
Database State (or extension)
- 특정 시점에 database에 저장되어 있는 the actual data
- database에 있는 모든 data의 collection을 포함한다.
- database instance(occurrence or snapshot)이라고도 불린다.
- instance는 개별적인 database components에도 사용된다.
Database Schema vs. Database State
Database State:
- 한 시점의 database의 content
Initial Database State:
- DBMS로 처음으로 로드되었을 때의 database state (or "populated with initial data")
Valid State:
- databasem이 structure와 constraints를 만족(Schema를 따르고 있는)하는 state
- DBMS는 모든 database의 state가 'valid' 하도록 해야 한다.

THREE-SCHEMA ARCHITECTURE AND DATA INDEPENDENCE
Three-Schema Architecture
- database approach(Chap1)의 4가지 특성 중 첫 3가지 특성을 지원하기 위해 제안되었다.
C1) Use of a catalog to store schema to make it self-describing
C2) Program-data or program-operation independence
C3) Support of multiple user views - database system organization 설명 시 유용
- user applications를 physical database로부터 분리하기 위한 목표를 가진다.
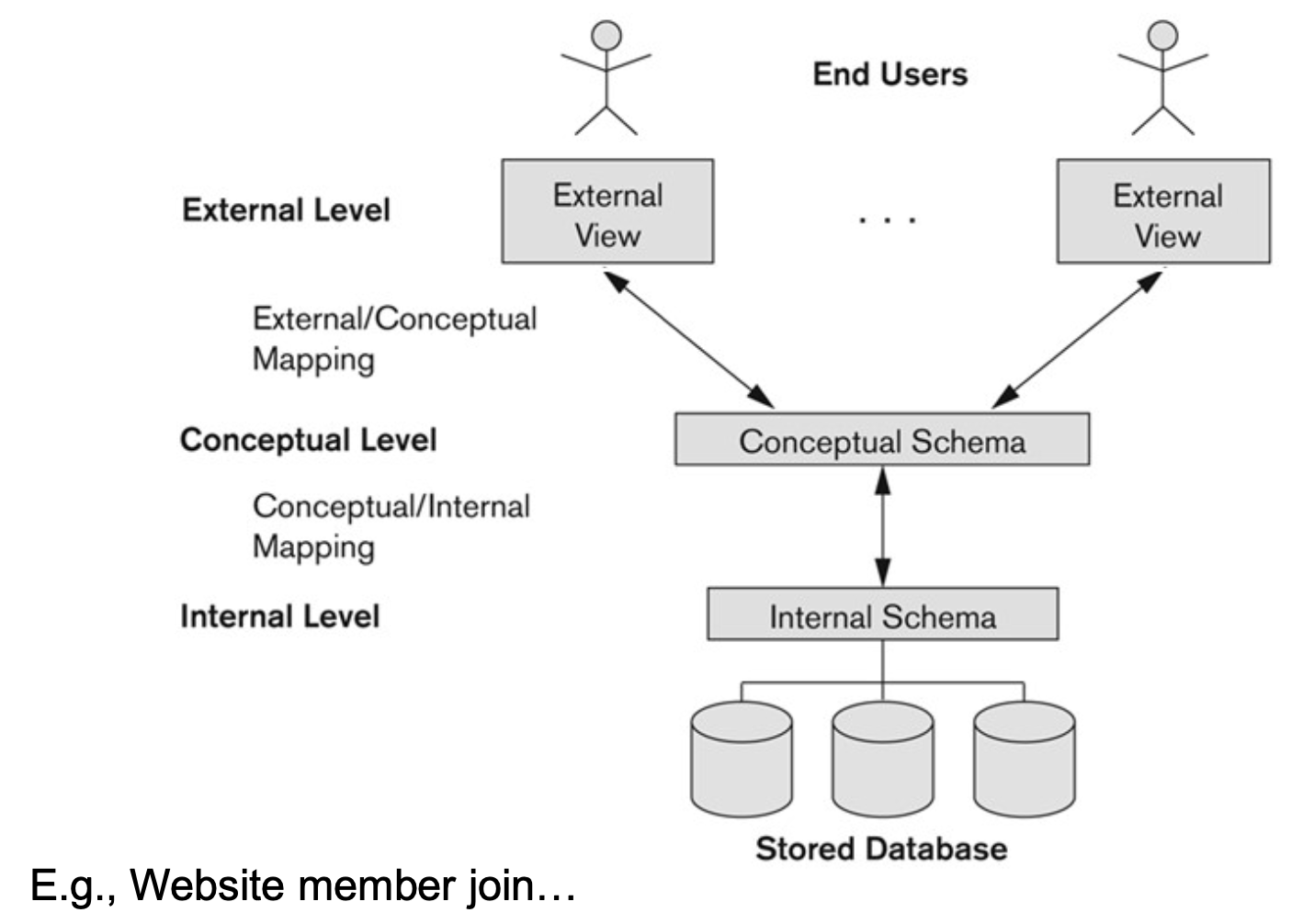
- level 간의 Mapping 정보 관리로 다른 level의 변화에 영향을 받지 않도록 한다.
Three levels of data abstraction
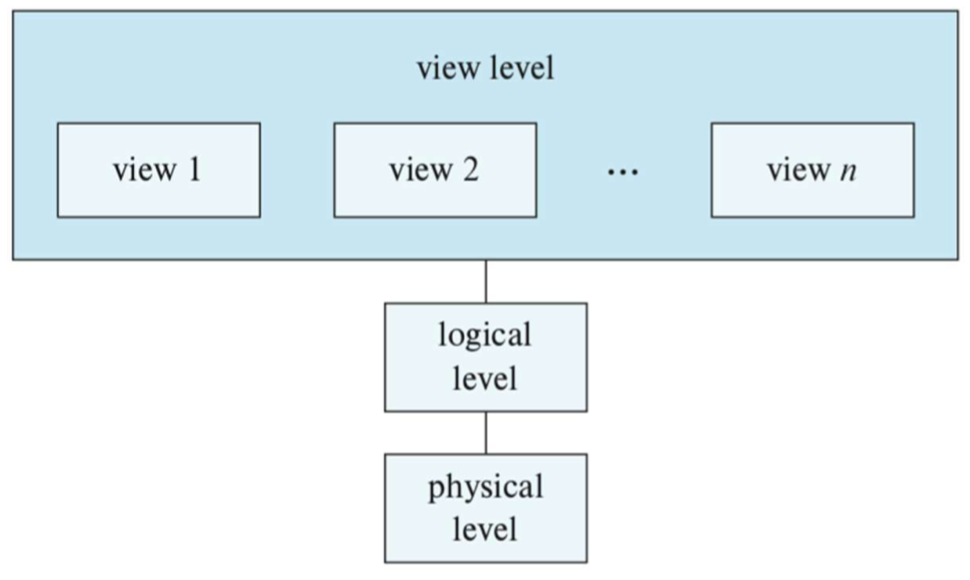
Defines DBMS schemas at three levels:
-
Internal (physical) schema (at the internal level)
- 물리적인 storage 구조와 access paths에 대한 설명
- 일반적으로 physical data model에서 사용됨
- 물리적인 storage 구조와 access paths에 대한 설명
-
Conceptual (logical) schema (at the conceptual level)
- 사용자 community를 위한 전체 database 구조와 constraints을 설명
- 물리적인 storage 구조에 대한 디테일은 숨기고, database constructs 설명에 초점
- conceptual or an implementation data model에서 사용
- 사용자 community를 위한 전체 database 구조와 constraints을 설명
-
External (view level) schema (at the external level)
- 다양한 user views에 대한 설명
- 일반적으로 conceptual schema와 같은 data model을 사용
- 각 external schema는 사용자 그룹이 관심있어 하는 database의 부분에 대해서만 보여주고, 나머지 부분은 숨긴다.
- 다양한 user views에 대한 설명
-
"requests"와 "data"를 변환하기 위해서는 schema levels 사이에서의 Mappings가 필요하다.
- three schemas는 data에 대한 description일 뿐이다.
- 실제 data는 physical level에만 저장되어 있다.
- 각 group은 그에 해당하는 고유의 external schema를 참조한다. 즉, 한 group은 다른 group의 external schema를 알 수 없다.
- external schema로부터 요청된 real data objects에 접근권한을 갖기 위해 DBMS는 아래의 과정을 거친다.
- (i) external schema에서 주어진 request를 수행하고,
- (ii) conceptual schema에 대한 request를 수행하고,
- (iii) internal schema에 대한 request를 수행한다.
이를 통해 stored database를 처리한다.
- internal level로부터 추출된 data는 external level에서의 original request와 대응되기 위해 "reformat" 된다.
- three schemas는 data에 대한 description일 뿐이다.
즉 (i)~(iii)의 과정을 거쳐 internal level에 존재하는 실제 데이터를 얻어오고, 이를 정제하여 external level로 보낸다.
Data Independence (데이터 독립)
- database system에서 어떤 한 level에서의 schema의 변경이 다른 상위 level의 schema의 변경을 요구하지 않는 능력
- 다른 level에 영향을 주지 않기 위해 필요
Logical data independence:
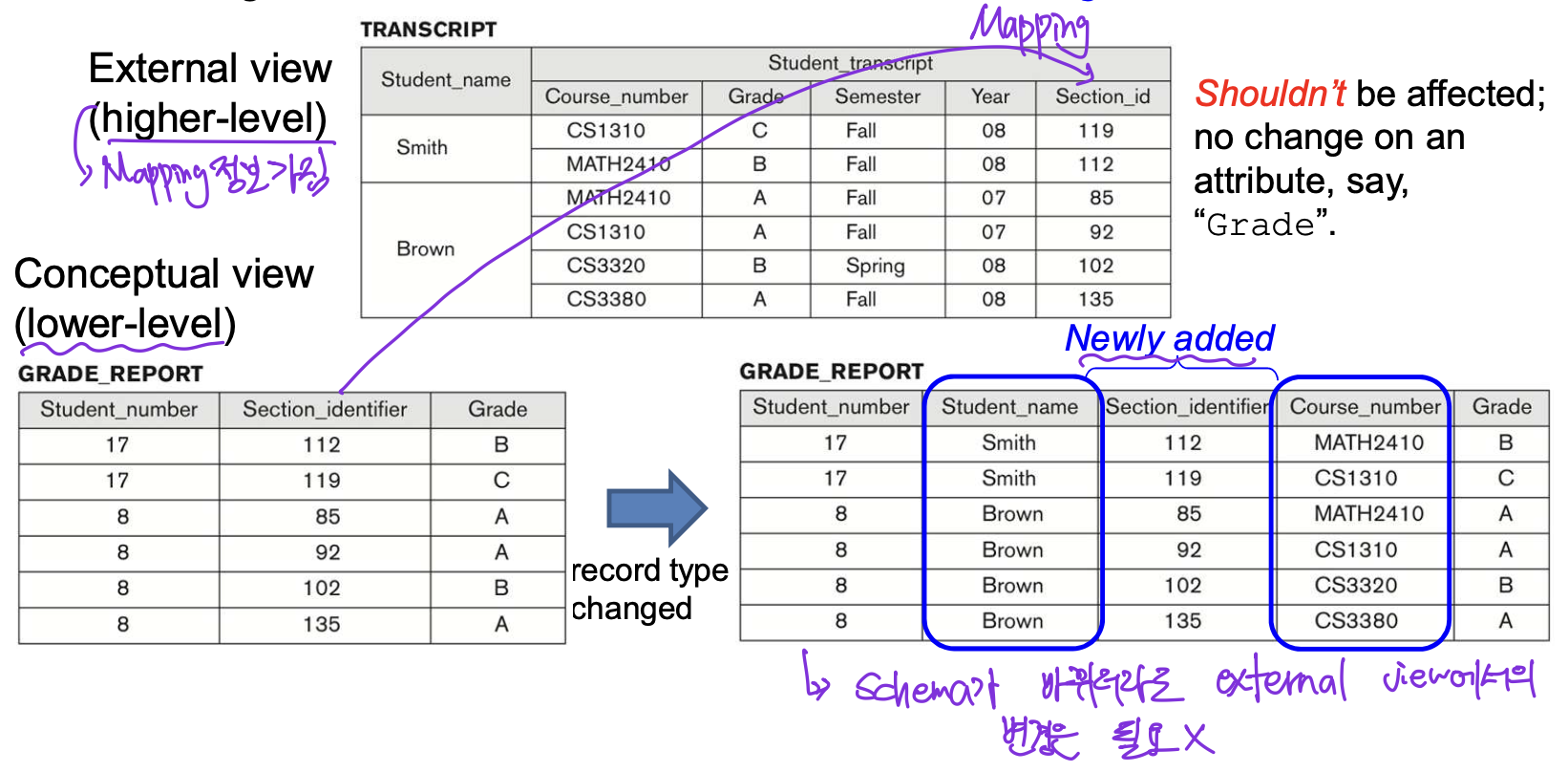
- external schemas와 associated application programs의 변경 없이 conceptual (or, logical) schema를 변경할 수 있는 능력
Physical data independence:
- conceptual (or, logical) schema의 변경 없이 internal (or, physical) schema를 변경할 수 있는 능력
- internal schema는 특정 파일의 구조가 재구성될 때, 변경될 수도 있다; database의 성능 향상을 위해 새로운 인덱스가 생성된다. (기본 index + 보조 index)
- DBMS는 data independence를 지원하기 위해 lower level의 schema가 변경되면, 상위 level가 해당 level 사이의 "mappings"만 변경하도록 한다. 즉, 상위 level의 schema는 변경될 필요가 없다.
DATABASE LANGUAGES AND INTERFACES
DBMS Language: DDL
Data Definition Language (DDL)
- DB의 conceptual/internal schema 정의와 두 schema 간의 mapping 정의 시 사용하는 language
- 현대의 relational DBMS에서는 대부분 DBA, DB 디자이너 모두가 사용한다.
- 몇 DBMSs는 명확한 분리를 해서,
- Storage Definition Language for internal schemas: 현대 DBMS에 대해서는 이러한 언어가 없음, DBA와 DB 디자이너에게 제공되는 DBMS 명령어를 통해서 구현
- View Definition Language for user views: 미리 정의된 결과를 저장할 수 있는 SQL (Structural Query Language)에서 cover
DBMS Language: DML
Data Manipulation Language (DML)
- database 검색과 갱신 시 사용한다. 즉, database 조작 시에 사용한다.
- DML commands(called data sublanguage)는 범용적인 프로그래밍 언어(called host language)에 내장될 수 있다.
- DBMS에 접근할 수 있는 함수 라이브러리를 프로그래밍 언어로부터 제공할 수도 있다. (e.g., ODBC, JDBC)
Two types
-
High-level or non-procedural languages(e.g., SQL): declarative
- why declarative ? 검색하는 방법(how) 대신 검색할 data(what)를 명시한다.
- 독립 실행형 방식으로 사용: query language
- 프로그래밍 (host) 언어에 내장되어 있다.
= set-at-a-time or set-oriented DML - single DML 구문으로 records 집합을 검색하고(실행된 전체 결과가 return), 이를 하나하나 처리
-
Low-level or procedural languages
- 프로그래밍 언어에 항상 내장되어야 한다.
- data를 한 번에 한 record씩 검색; 여러 records에 대해서는 반복 구문과 같은 구성이 필요하다.
- called record-at-a-time DML
- 항상 row를 기반으로 하여 절차적으로 record 단위를 return하고 process
DBMS Interfaces
- 독립 실행형(Stand-alone) query language interfaces: e.g., SQL*PLUS
- Programmer interfaces for embedding DML in Programming languages(host languages)
- 사용자 친화적 interfaces
- Menu-based, forms-based, graphics-based (e.g., SQLDeveloper), etc.
- Mobile interfaces
Programmer interfaces for embedding DML in a programming languages:
- Embedded Approach
- Procedure Call Approach
- Database Programming Language Approach
- Scripting Languages
THE DATABASE SYSTEM ENVIRONMENT
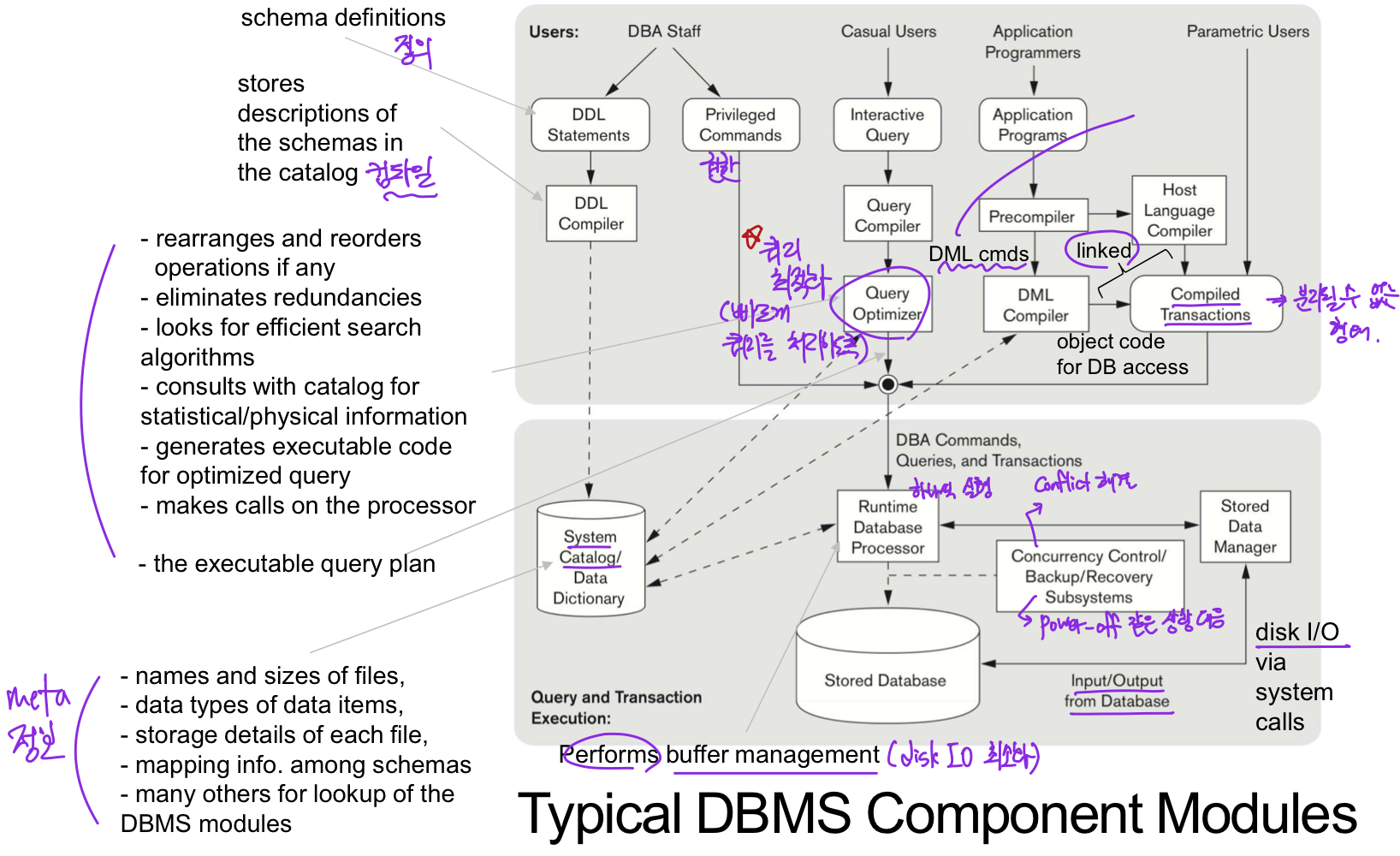
DBMS Component Modules
- Disk에 저장되는 things
- The stored database
- DBMS catalog
- Disk에 대한 접근 권한은 OS에서 관리하고, Disk read/write를 scheduling
- Disk IO에 대한 overhead가 발생할 수 있음
대부분의 DBMS는 disk read/write를 schedule하는 자기만의 buffer manager를 가짐
- OS의 kick off 정책에 반하여 자기만의 정책을 적용하여 disk-IO를 최소화하고 결과적으로 DB의 성능을 향상시킴
- DBMS의 high-level stored data manager(module)는 Disk에 저장된 DBMS information에 대한 접근을 제어
- DB의 일부이든 catalog이든 상관없이 제어 (어디에 위치해 있던지)
Typical DBMS Component Modules

배우고 정리하고 공유하기