
MORE COMPLEX SQL RETRIEVAL QUERIES
More Complex SQL Retrieval Queries
- Nested queries (중첩 질의) -> 외부 질의 + 내부 질의
- Joined tables (Natural Join)
- Outer joins in the FROM clause
- Views (Derived Tables), Assertions (oracle 지원 X), Triggers
- Aggregate functions (집계 함수) -> Grouping이 필요
- Grouping
Comparisons Involving NULL and Three-Valued Logic
- SQL는 Three-valued logic을 사용
- NULL을 처리하기 위해 사용
TRUE,FALSEandUNKNOWN(NULL)- 은 계산할 수 없다.
- ISNULL로 판단
- Logical connectives (truth table)

if문은 two-valued logic
TRUEorFALSE
- SQL은 attribute value가 NULL인지
ISNULL로 판단
- Super_ssn의 값이
NULL인 tuple을 listing - Super_ssn의 값이
TRUE이면(존재하는 경우) 전체 값은FALSE - NULL이 아닌지를 확인하려는 경우,
Super_ssn IS NOT NULL
- Super_ssn의 값이
Nested Queries
views를 사용하여 query 단순화 가능
- outer query는 WHERE 절 내에 완전한 select-from-where block을 가진 subquery 또는 inner query를 가진다.

- WHERE Pnumber IN ... -> IN 뒤의 결과 집합과의 evaluate
Set/Mutliset Comparison Operator: IN
v IN V: values의 set(or multiset)인V와 valuev를 비교V안에v가 존재하는 경우,TRUE
 ( ... )를 사용하여 multi attribute에 대한 비교도 가능하다.
( ... )를 사용하여 multi attribute에 대한 비교도 가능하다.
Other Comparison Operator: ALL
- single value
v에 대한 비교 연산자 ALL: 는 nested query로부터 얻은 "모든" value와의 비교
Aliases
- 잠재적인 error와 모호성을 예방하기 위해 생성
- Ex) Retrieve the name of each employee who
1) Has a dependent with the same first name, and
2) Is the same gender as that of the employee.

- outer query tuple이 inner query에 적용됨
- correlated nested query (상호 연관된 중첩 질의)
- outer query의 각 tuple과 한 번씩 비교
- outer query tuple과 inner query tuple이 서로 연관 => "join"
- Ex) Retrieve the name of each employee who
Join과 Correlated nested query
- '=', 'IN' 을 사용하는 nested queries는 join condition을 사용하는 single query로 변환이 가능하다. (상호 변환)
- Ex)

The (NOT) EXISTS Functions in SQL for Correlating Queries
(NOT) EXISTS function
- correlated nested query의 result가 'not empty'인지 'empty'인지 check
- Boolean function
EXISTS: 결과 생성이 가능하면TRUE, 그렇지 않으면FALSENOT EXISTS: 결과 생성이 가능하면FALSE, 그렇지 않으면TRUE

Use of NOT EXISTS
- 모든 universal quantifier effect를 위해, SQL에서 이중 부정을 사용
(A하지 않은 튜플들은 존재하지 않는다. = A한 튜플들만 존재한다.) - “Retrieve the name of employees working on “ALL” projects controlled by Dno = 5.”

WHERE 절- 첫 번째 SELECT 문 -> 5번 부서가 관리하는 전체 PROJECT의 Pnumber를 return
{1,2,3} - 두 번째 SELECT 문 -> EMPLOYEE가 참여하는 PROJECT의 Pno를 return
{1,2} - {1,2,3} {1,2} = {3}
- NOT EXISTS (3) =>
FALSE - 어떠한 tuple도 선택되지 않는다.
- 첫 번째 SELECT 문 -> 5번 부서가 관리하는 전체 PROJECT의 Pnumber를 return
- 위의 query는 two-level nesting을 이용한 더 복잡한 방법으로 재작성될 수 있다.

Explicit Sets and Renaming in SQL
- values의 explicit set은 WHERE 절에서 사용될 수 있다.

WHERE Pno IN (1,2,3); == WHERE (Pno = 1) or (Pno = 2) or (Pno = 3);
Attribute renaming
: AS 키워드로 attribute name을 변경할 수 있다.

Joined Tables in SQL and Inner Joins
Joined Tables (-join)
- Concepts: 사용자는 query의 FROM 절에서 join operation을 사용하여 얻은 table을 사용할 수 있다.

Dno = Dnumber에서, attribute name이 같은 경우, aliasing이 필요
FROM (EMPLOYEE JOIN DEPARTMENT ON Dno = Dnumber) t와 같이 Joined table에 aliasing이 가능 (aliasing한 경우, SELECT 절에서 t. Fname, t.Lname 과 같이 사용 가능) - single joined table을 포함하는데, 이러한 join은 inner join이라고도 하고, 이는 tuple matching에만 사용된다.
Different Types of JOINed Tables in SQL
different types of join
NATURAL JOIN
- 가장 대표적인 inner join
- (left table) (right table), join condition은 명시되지 않는다.
- 두 table에서 같은 attribute name을 갖는 것에 대해 implicit
EQUIJOINcondition을 생성하는 것과 동일

CREATE TABLE DEPT AS: query의 결과를 table화하겠다는 의미
Dnumber as Dno: Natural join을 위한 renaming
INNER JOIN (vs. OUTER JOIN)
- joined table에서의 default type
- 다른 relation에 matching tuple이 존재하는 경우에만 tuple이 result에 포함된다.
- non-matching tuples을 확인하고 싶은 경우는 ?
LEFT (RIGHT) OUTER JOIN
- left(right) table에 있는 모든 tuples는 무조건 result에 포함된다.
- matching tuple이 없는 경우, right(left) table의 attributes의 values에
NULL값을 삽입 - Ex)

EMPLOYEE E와EMPLOYEE S의 LEFT OUTER JOIN이므로, EMPLOYEE E의 tuples 중 join에 참여하지 않는 tuples도 result에 보여진다.
FULL OUTER JOIN
- LEFT & RIGHT OUTER JOIN의 result 결합

Multiway JOIN in the FROM clause
"multiway" join은 JOIN specificaitons를 nesting함으로써 기술할 수 있다.
- Ex)

왼쪽부터 JOIN 수행하고 그 결과에 다시 JOIN 수행
Aggregate Functions in SQL
- multiple tuples로부터 요약한 정보(통계값, 요약 정보)들을 single tuple에 group 단위로 가져오고 싶을 때 사용
- Built-in aggregate functions:
- : NULL이 포함된 tuple은 count하지 않는다.
- : Round() 함수가 없으면 반올림해주지 않는다.
- 일반적으로
GROUP BY절로 grouping을 수행- summarizing 전에 tuples의 subgroups 생성
- Group내에 구분을 두기 위해서 (조건을 적용하기 위해서)
HAVING절 사용 - Aggregate functions는
SELECT절이나HAVING절에 사용될 수 있다.
Aggregations Applied for Entire Tuples



COUNT는 NULL 값에 대한 counting을 하지 않기에 마지막 예시에서의 결과값이 다르게 나온다.
Grouping: The GROUP BY Clause
- tuples의 하위 집합으로의 Partition relation
- grouping attributes를 기반으로, 같은 값을 가진 것을 선택
- 각 group에 독립적으로 function 적용
GROUP BY Clause
- grouping attributes를 명시
- grouping attributes는 무조건 SELECT 절에 명시되어야 한다.
- Ex) Dno 값이 같은 tuple들로 grouping 수행 ( Dno가 select 절에 포함되어야 함)


- JOIN의 result에도 적용할 수 있다.
GROUP BY사용 시, attributes의 기술 순서 중요ORDER BY의 default는 오름차순


Grouping: The GROUP BY Clause with HAVING Clause
HAVING clause
-
전체 group을 select하거나 reject하는 조건을 제공
-
HAVING절의 위치는GROUP BY뒤 (+ORDER BY는 제일 마지막) -
Ex)

 HAVING 절에 의해 선택되지 않은 groups
HAVING 절에 의해 선택되지 않은 groups 최종 result
최종 result -
Ex) “For each department with >= 2 employees, retrieve the department number and the number of its employee who’re earning > $40,000.

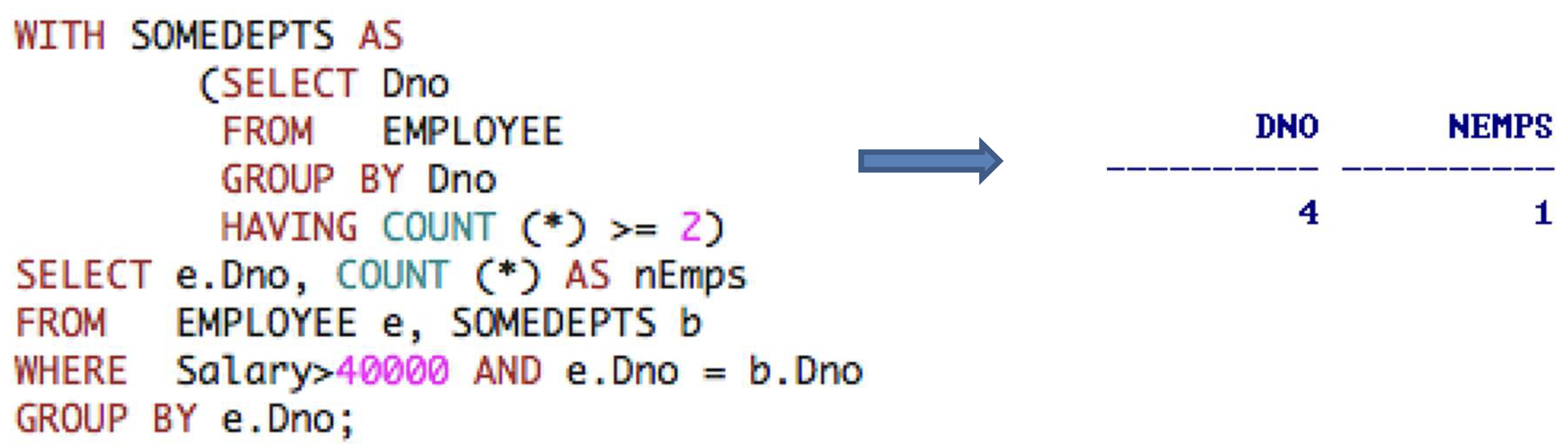
WITH Clause
- 특정 query에서 사용될 임시의 table을 사용자가 정의하는데 사용한다.
- 편의성을 위해 임시 "Views"를 만들고, query에서 즉시 사용하도록 한다. 그리고 이를 in-line view라고 한다.
- 위에서 작성한 query는
WITH절을 사용해 아래와 같이 재작성할 수 있다.
Use of CASE Clause
- 특정 조건마다 value가 다른 경우에 사용한다.
- value가 존재할 것으로 예상되는 SQL query의 어느 부분에서든 사용 가능하다.
- tuple에 대한 querying, inserting, or updating에 적용 가능하다.

Recursive Queries in SQL
동일한 table에 대해 반복적인 연산을 수행
- Ex) EMPLOYEE의 Super_ssn (FK)가 이러한 relationship을 가진다.
 SUP_EMP에 result tuples가 계속 population된다.
SUP_EMP에 result tuples가 계속 population된다.
START WITH: reculsive query를 시작할 attribute value
CONNECT BY PRIOR: 시작 tuple에서부터 해당 조건을 만족하는 tuple을 탐색
Reminder: EXPANDED Block Structure of SQL Queries

VIEWS(VIRTUAL TABLES) IN SQL
Views(Virtual Tables) in SQL
- SQL에서 view의 Concepts
- 다른 tables로부터 파생된 single table
- "필수적으로 채워지지 않는" virtual table로 간주된다.
- view는 자주 참조해야 하는 table을 지정하는 방법으로도 생각할 수 있다.
- 자주 요청되는 joins의 result를 caching할 목적으로 사용되기도 하는데, 이러한 경우는 join cost가 space보다 더욱 비용이 든다고 판단했기 때문이다.
- join cost와 space의 tradeoff
- Ex) “Retrieve the employee name and the project names that the employee works on.”
- 해당 query가 호출될 때마다 EMPLOYEE, WORKS_ON & PROJECT를 매번 join하는 비용이 크다.
- 이러한 joins에 대한 view를 정의했다면, 이후로는 single-table에 대한 retrieval로 간주된다.
Specification of Views in SQL: CREATE VIEW
- view의 name, attribute names & view definition을 정의하는 query
- 존재하는 Table의 attribute를 가져오기 때문에, data types도 기존의 table attribute의 data types와 동일

WORKS_ON1: view name
SELECT ~ FROM ~ WHERE: view definition

DEPT_INFO (Dept_name, No_of_emps, Total_sal) : 새로운 attribute name 지정
Specification of Views in SQL
- View가 한 번 정의되면, SQL queries는
FROM절에서 view relation을 사용할 수 있다. - 아래의
DROP VIEW전까지 사용 가능 - Ex) Accessing the defined view: WORKS_ON1

Advantages of defining a view
1) 특정 queries를 기술하는 데 용이
2) 보안과 권한 부여 메커니즘의 제공
- Ex) 특정 부서의 사람이 다른 부서의 정보를 볼 수 없음
3) 구현 시, 공간(join에 참여하는 table 수?)에 따른 join cost를 절감할 수 있음
DROP VIEW
- view 삭제
View Implementation
- View는 항상 up-to-date되어야 한다.
- view가 정의한 base relation의 tuples를 수정하면, 해당 수정사항이 view에도 자동적으로 반영되어야 한다.
- 그렇지 않으면, 일종의 Cache이기 때문에 이전의 tuples 정보를 사용할 수도 있다.
- view는 정의될 때가 아닌, view에 대한 query로 참조할 때 실제 결과를 저장한다.
- view가 정의한 base relation의 tuples를 수정하면, 해당 수정사항이 view에도 자동적으로 반영되어야 한다.
- DBMS는 view를 up-to-date해야하는 책임이 있다.
- view를 사용자가 최신화하는 것 X
- Q: 그럼 어떻게 DBMS가 view에게 up-to-date를 지시하는가 ?
- querying를 위한 view를 효율적으로 구현하는 것은 쉽지 않다 ...
Strategy 1) Query modification approach
- view가 참조될 때 up-to-date (compute)
- view query를 기본 table에 대한 query로 수정

- Any problem ??
- Join과 같은 효과
- Join의 cost가 높은 경우, 비효율적이다.
Strategy 2) View materialization approach
- view query가 처음 호출되었을 때, 일시적인 view를 물리적으로 생성
- view에 대한 또다른 queries가 곧 호출될 거라는 가정 하에, 해당 view table을 유지
- base tables가 update되었을 때, 자동적으로 view table을 update하는 효율적인 전략을 필요로 한다.
- Incremental update : 새로운 tuple의 결과만 update(query의 영향을 받는 부분에 대해서만 update)
- 물리적으로 구현된 table은 query가 계속되는 한 유지된다.
- 일정 기간동안 query가 없다면, 자동적으로 table을 삭제
Multiple ways to implement materialization:
view update의 시점에 따라 구분
- Immediate update (c.f., "write-through")
- base tables가 변경되자마자 바로 view update
- Lazy update (c.f., "write-back")
- view query가 요청될 때 view update
- Periodic update
- 주기적으로 view update
View Update
INSERT/DELETE/UPDATE command로 view table을 수정하는 것은 불가능
- 여러 가지 의미로 해석될 수 있기에 reject됨, view table은 read-only!

- aggregate function 없이 single table을 기반으로 정의된 view에 대한 update는 base table에 대한 update로 변환될 수 있다.
- 아래와 같은 aggregate function이 있는 경우,
- update가 허용되는가 ? 허용되지 않을 것 같다. view table의 정의와 맞지 않기 때문 .. ?

- update가 허용되는가 ? 허용되지 않을 것 같다. view table의 정의와 맞지 않기 때문 .. ?
Views as Authorization Mechanism

- 위 query로
Dno = 5인 EMPLOYEE table의 정보만 생성하고, Dno = 5인 Employees에게만 해당 view에 대한 접근권한을 부여함으로써, EMPLOYEE table에 대한 접근을 방지할 수 있다.
SCHEMA CHANGE STATEMENTS IN SQL
Schema Evolution Commands
- tables/views, attributes, constraints, & other schema constructs를 더하거나 제거함으로써, schema를 수정하는데 사용된다.
- 하지만, 전체 database schema를 recompile하는 것이 아니라 변경된 부분에 대해서만 전체 database의 일관성을 무너뜨리지 않도록 recompile 수행
The DROP Command
-
tables, domains, or constraints와 같은 schema elements를 제거하는데 사용된다.
-
DROPoptions:CASCADE&RESTRICT -
Ex1)
DROP SCHEMA COMPANY CASCADE;- CASCADE: schema를 제거하고, 그 안의 모든 elements(tables, views, constraints, 등) 또한 제거
- RESTRICT: schema 내에 아무 element도 들어있지 않은 경우에만 제거
-
Ex2)
DROP TABLE DEPENDENT CASCADE;- CASCADE : relation(table)을 제거하고 catalog로부터 해당 relation(table)의 definition 또한 제거
- RESTRICT : 어떠한 참조도 존재하지 않는 경우에만 제거
The ALTER TABLE Command
- 포함하는 actions
- column(attribute) 추가 또는 제거
- column definition 변경
- table constraints 추가 또는 제거
- Ex)

CASCADE: 모든 제약조건과 column(Address)를 참조하는 views 제거
RESTRICT: column을 참조하는 어떠한 views/constraints가 없는 경우 제거
Default Values
 Oracle에서는 지원되지 않는 SET DEFAULT
Oracle에서는 지원되지 않는 SET DEFAULT
SPECIFYING CONSTRAINTS AS ASSERTIONS AND ACTIONS AS TRIGGERS
CREATE ASSERTION
- declarative assertions을 통해 일반적인 제약조건을 사용자가 기술할 수 있도록 한다.
- 해당 제약조건은 key, (or unique), entity, not-null, referential integrity constraints에 포함되지 않는다.
- 개별 attributes와 domains에 적용되는
CHECK절로는 기술되지 않는 경우에만 사용한다. - Oracle에서는 지원하지 않는다.

Triggers
- 특정 이벤트가 발생하거나, 특정 조건이 만족되는 경우에 취해야 할 action의 type을 기술하기 위해 사용한다.
- Ex) “If an employee exceeds a travel expense limit, notify his manager.”
- 일반적인 trigger는 3가지 components를 가진다:
- Event(s), Condition, Action (ECA)
Triggers - How to Use ?

BEFORE(사전) /AFTER(사후)NEW: 새로 들어오는 값 /OLD: 기존의 값- Oracle에서는 다른 형태로 사용됨

