Linear Neural Networks
Linear Regression

- 어떻게 Model의 와 를 찾을것인가? -> 역전파
- 기본적으로 loss 함수가 주어져있을 때 loss를 줄이는 것이 목표
- 나의 parameter가 어느 방향으로 움직였을 때 loss function이 줄어드는 지를 찾고 해당 방향으로 parameter를 이동시킨다.
- loss function을 각각의 parameter로 미분하게되는 방향을 역수방향으로(그 방향의 음수 방향으로) update를 하게 되면 loss가 최소화되는 지점에 이르게 된다.
- 위 그림에서 parameter는 w와 b
| weight | bias |
|---|---|
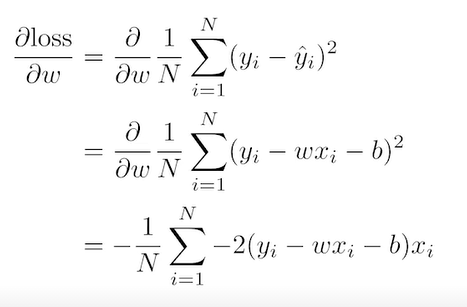 | 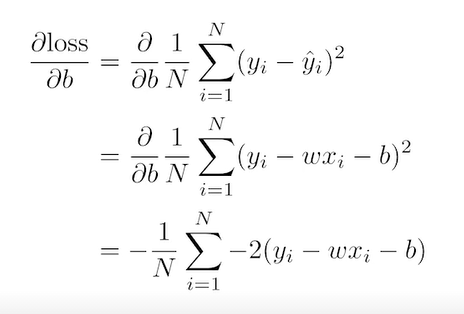 |
-
loss function을 w로 편미분한 값에 적절한 값을 곱하여 현재 w 값에서 빼준다
-
b도 마찬가지로 편미분 한뒤 적절한 값을 곱하여 현재 b 값에서 빼준다. (η : 에타)

-
위와 같이 w와 b를 계속해서 업데이트 하는것이 gradient descent이다.
- 만약 reward function 처럼 parameter를 계속 키워야한다면 ascent가 될 것
-
이때 적절한 step size(에타)를 설정하는 것이 가장 중요하다
차원이 변하는 경우

- 행렬을 사용하여 변환(Affine Transform)
- 여기서 행렬이란? -> 두개의 벡터 차원사이의 변환
Beyond Linear Neural Networks
딥러닝이란?
- 위와 같은 Linear Neural Networks를 shallow하지 않고 deep 하게 쌓는 것
- 아래의 경우는 결국 하나의 Neural Network를 사용 한 것

Nonlinear transform
- 네트워크가 표현할 수 있는 표현력을 최대한 극대화 하기 위해선 단순히 선형 결합을 여러번 반복해선 안된다
- Activation function(sigmoid, ReLU 등..)을 활용한 Nonlinear transform을 거쳐 Linear와 Nonlinear를 같이 사용해줘야 함

Activation functions

- tmi) 대학 수업에서 교수님이 일단 모르겠으면 ReLU로 돌리라고 하셨던 기억이 나요
Multi-Layer perceptron
loss functions
- loss function은 실제값과 예측값의 차이(loss, cost)를 수치화해주는 함수이다.
- 오차가 클수록 loss fuction의 값이 크고, 오차가 작을수록 값이 작아진다.
- loss function의 값을 최소화 하는 W, b를 찾아가는것이 학습 목표이다.
1. MSE

- 연속형 변수를 예측할 때 사용
2. Cross-Entropy

- 낮은 확률로 예측해서 맞추거나, 높은 확률로 예측해서 틀리는 경우 loss가 더 크다.
- 이진분류 : binary_crossentropy / 다중분류 : categorical_crossentropy
- y : 실제값(0혹은1) / y^ : 예측값(확률)
3. MLE (최대가능도추정 Maximum Likelihood Estimation)

