Gradient Descent
Local minimal?
- loss function을 최소화 시킬 수 있는 parameter가 여러개 존재 할 수 있다.
- 이때 국소적으로 봤을 때 좋은 local minimal을 찾을 수 있고 그것이 목적이 된다.
- 추가적인 내용은 1주차에 작성한 Gradient Descent 확인
Important Concepts in Optimization
Generalization
-
많은 경우에 Generalization(일반화) 성능을 높이는 것이 목표
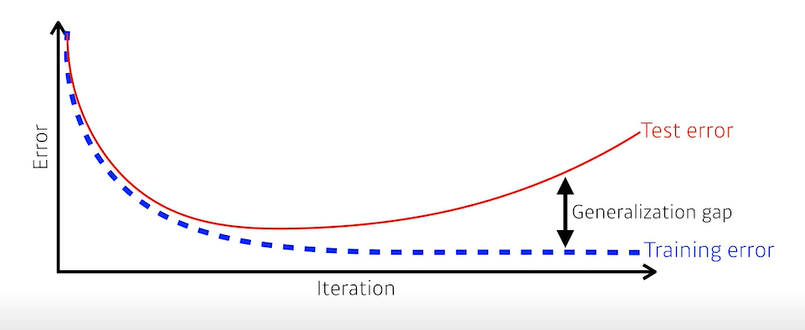
- 일반적으로 학습을 진행하게 되면 학습 Iteration에 따라 Training error가 줄어들게 된다.
- 그러나 Training error가 0이 된다고 해서 최적값에 도달한다는 보장은 없다.
- 왜? -> 학습을 사용하지 않은 데이터에 대해서는 성능이 떨어지기 때문
-
generalization performance가 좋다 -> generalization gap이 작다
하지만 generalization performance가 좋다 하더라도 항상 테스트 데이터의 성능이 좋다고 할 수 는 없다. 왜냐하면 학습 데이터에 대한 성능 자체가 좋지 않을 경우 테스트 데이터와의 성능 차이가 줄어들면 오히려 안좋은 성능을 가진 것이기 때문
Underfitting vs. Overfitting
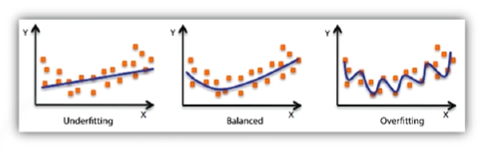
Underfitting
- 학습데이터에 과도하게 학습되어 테스트 데이터에 대한 오차가 커지는 상태
overfitting
- 학습량이 너무 적어 학습데이터도 잘 못맞추는 상태
Cross-validation
- 학습의 기본적인 목표는 train data로 학습된 모델이 학습에 사용되지 않은 test data에 대해 좋은 성능을 내는 것
- test data 없이 학습을 시키려면 train data를 validation data와 나눠 서로 학습시켜야 한다.
- 그렇다면 train data와 validation data의 적절한 비율은 얼마일까?
-> 이것을 해결하는것이 바로 Cross-validation
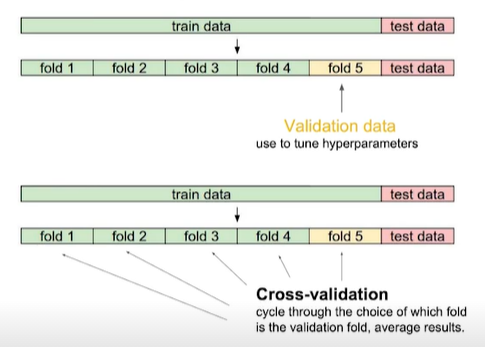
- 학습데이터를 K개로 나눠서 K-1개로 학습을 진행한 뒤 나머지 1개로 test를 하는 방식
- 위 그림으로 예를들면 1~4번 데이터로 학습한 뒤 5번데이터로 test
- 다음은 1,2,3,5번 데이터로 학습한 뒤 4번 데이터로 학습 ...
언제 사용되나요?
뉴럴 네트워크를 학습하는데 있어서 많은 hyper parameter가 존재함
- parameter : 최적화해서 찾고 싶은 값
ex) convolution fitter의 값 - hyper parameter : 내가 정해야 하는 값
ex) learning rate, 네트워크의 크기, 사용할 loss function
이때 이런 값들에 대한 정답이 없기 때문에 일반적으로 cross-validation을 해서 최적의 hyper parameter set을 찾고 고정시킨 뒤 모든 데이터를 사용하여 학습시킨다. 단 test data는 어떠한 상황에서도 학습에 이용되어선 안된다. (조금만 생각해보면 당연하다.)
Bias and Variance

-
Variance : 내가 입력을 넣었을 때 출력이 얼마나 일관적으로 나오는가
- variance가 낮으면 출력이 일관적, 높으면 반대
-
Bias : 출력을 평균적으로 봤을때 얼마나 true target에 접근해 있는가
- Bias가 낮으면 더 가까이 접근한 것
-
위의 그림처럼 영점 맞추는 경우를 생각하면 이해하기 편하다.
Bias and Variance Tradeoff
noise가 껴있는 학습 데이터를 가지고 있을 때 noise가 껴있는 target data를 최소화 하는 것은 3가지 파트로 나뉠 수 있다. 이때 한가지 파트를 줄이면 나머지 하나는 커질 수 밖에 없다.

t : target, 이때 t는 true target에 noise가 껴있다고 가정
: neural network 출력값
- 이때 cost를 minimize한다는 것은 bias, variance, noise 3가지를 줄이는 것
- 하지만 noise는 데이터 자체에 포함된 에러로서 우리가 제어하기 힘든 영역이다.
- bias와 variance 값을 적절히 조절하여 cost를 낮춰야 함
- 둘다 동시에 낮추는 것은 매우 어렵다.
Bootstrapping
- 학습 데이터가 고정되어 있을 때 그 안에서 sub-sampling을 통해 모델을 여러개를 만들어 하나에 입력에 대해 여러 예측값을 내는 것
- 예를 들면 100개의 data가 있을때 매 케이스마다 다르게 80개씩 뽑아 사용하는 느낌
- 모든 모델에 대해 예측값이 같은 경우가 이상적이지만 당연히 그런 경우는 거의 없다.
- 따라서 각각 예측값이 얼마나 일치하는지를 보고 전체적인 모델의 uncertainty를 예측하고자 할때 사용된다.
Bagging vs. Boosting
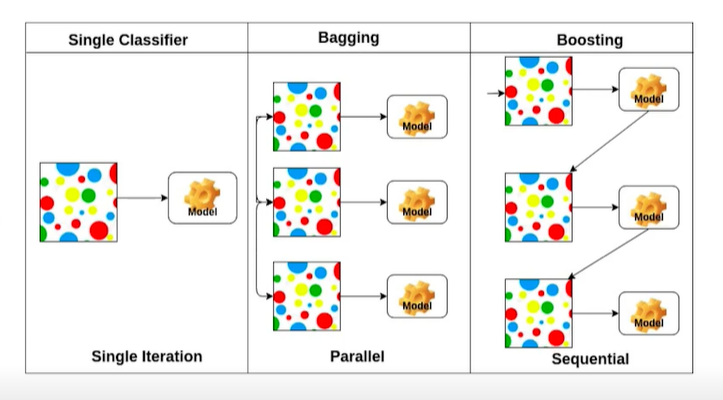
Bagging
- 모델을 Bootstarpping으로 여러개 만들어 각각의 모델을 독립적으로 사용해 결과를 내는 방식
Boosting
- Bagging과 마찬가지로 여러개의 모델을 만들어 사용하지만 각각의 모델이 독립적으로 사용되는 것이 아니라 서로 종속되어 사용되고 결과적으로 한개의 모델이 나오게 된다.
Practical gradient descent Methods
Gradient Descent Methods
- 3가지로 분류가능
Stochastic gradient descent
Mini-batch gradient descent
Batch gradient descent
1627
