기업 탄소 배출 데이터 기반 환경 영향도 분석 보고서
데이터 원본: emission 테이블 (단일 테이블 구성)
분석 환경: Oracle 23c Free · Python (pandas, scikit-learn)
1. 분석 개요
본 분석은 단일 테이블 emission을 활용하여 아래와 같은 단계로 탄소 배출과 기업 특성 간의 관계를 분석한다:
- DBMS: SQL 기반 조건 검색 및 집계로 기초 데이터 이해
- Data Warehouse (DW): 가상의 시계열·산업 분석 구조 설계 (논리적 확장 모델)
- Data Mining: Python 기반 K-Means 클러스터링으로 기업 유형 분류 및 인사이트 도출
2. DBMS 분석 (Oracle SQL 기반 단일 테이블 활용)
2.1 테이블 구조
CREATE TABLE emission (
group_name VARCHAR2(50),
emission_tco2 NUMBER,
domestic_share NUMBER(5,2),
asset_total NUMBER,
listed_cos NUMBER,
reporters NUMBER,
top_emitter VARCHAR2(100)
);2.2 SQL 분석 예시
-- 탄소 배출량 상위 5개 그룹
SELECT group_name, emission_tco2
FROM emission
ORDER BY emission_tco2 DESC
FETCH FIRST 5 ROWS ONLY;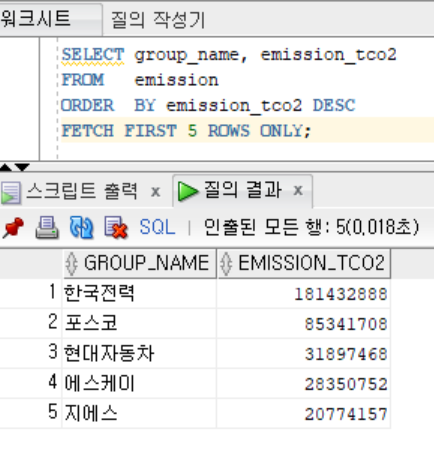
-- 자산 대비 배출량 비율이 높은 기업
SELECT group_name,
ROUND(emission_tco2 / asset_total, 4) AS tco2_per_asset
FROM emission
ORDER BY tco2_per_asset DESC;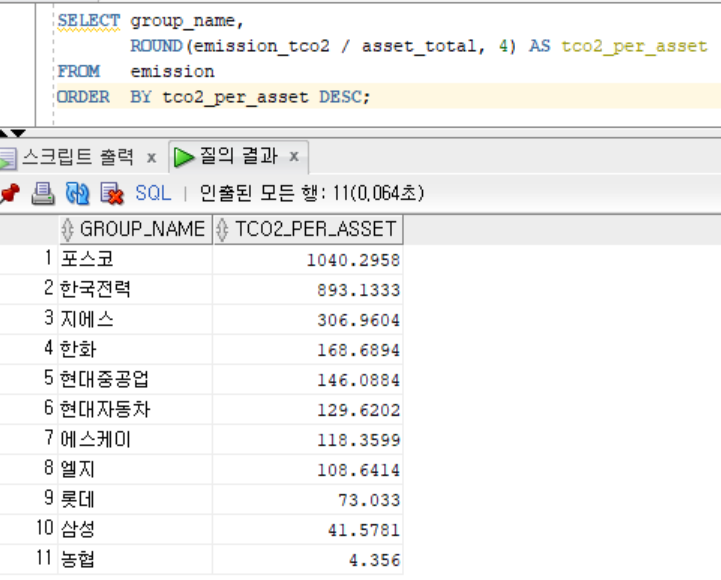
-- 명세서 제출 기업 수 비율
SELECT group_name,
ROUND(reporters / listed_cos * 100, 1) AS reporting_ratio
FROM emission
ORDER BY reporting_ratio DESC;
2.3 인사이트
- 한국전력, 포스코는 압도적으로 높은 배출량을 기록
- 농협은 자산에 비해 배출량이 매우 적은 저탄소 그룹
- 에스케이(SK)는 명세서 제출사 비율이 매우 높아 투명한 ESG 구조로 보임
3. Data Warehouse 설계 (논리적 구조 확장)
※ 실제로는 emission 단일 테이블이지만, DW 설계를 위한 논리적 모델로 아래처럼 확장 가능
3.1 논리적 구조 예시
| 테이블 | 설명 |
|---|---|
emission | 사실 테이블, 연도/기업/배출량/자산 등 포함 |
dim_time (가정) | 분석 연도, 분기 정보 |
dim_sector (가정) | 기업 업종 분류 (에너지, 철강 등) |
해당 실습에선 실제 차원 테이블 없이
emission만으로 분석 수행
3.2 분석 아이디어 예시
- 연도별 기업 배출 변화 시각화 (향후 배출량 트렌드 예측 기반 마련 가능)
- 산업군별 평균 배출량, 자산 대비 효율성 비교
- 기업 그룹 내 명세서 제출 비율 추이 분석
4. Data Mining (Python 기반 KMeans 클러스터링)
4.1 Python 코드
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
# 데이터 로드
df = pd.read_csv("emission.csv")
# 분석 대상 컬럼 선택 및 정규화
features = df[['EMISSION_TCO2', 'ASSET_TOTAL', 'LISTED_COS', 'REPORTERS']]
X = StandardScaler().fit_transform(features)
# K-Means 클러스터링
kmeans = KMeans(n_clusters=3, random_state=42, n_init='auto')
df['cluster'] = kmeans.fit_predict(X)
# 클러스터별 통계 요약
cluster_summary = df.groupby('cluster').agg({
'EMISSION_TCO2': 'mean',
'ASSET_TOTAL': 'mean',
'LISTED_COS': 'mean'
}).round(0)
print(cluster_summary)4.2 해석 예시
| 클러스터 | 특징 |
|---|---|
| 0 | 초고배출, 대규모 자산 보유 기업 (예: 한국전력, 포스코) |
| 1 | 중간 규모 배출과 자산 보유 (예: 한화, 롯데) |
| 2 | 배출량이 적고 자산 대비 효율적인 구조 (예: 농협) |
결과를 기반으로 각 군집에 맞는 ESG 전략 제안 가능 (고배출 그룹에 감축 KPI 설정 등)
5. 결론 및 정책적 시사점
| 분석 단계 | 주요 결과 | 의사결정 활용 예 |
|---|---|---|
| DBMS | 자산/배출 비율, 제출사 비율 등 단일 기업 기준 비교 | 환경위험도 스코어링, 공시 우수기업 선별 |
| DW (논리적) | 시계열·산업군별 확장 가능 | 산업별 규제 정책 차등 적용 기반 마련 |
| Data Mining | 기업별 탄소 특성 군집화 | 고배출/저배출 맞춤 전략 수립 및 ESG 평가 근거 제공 |
📌 종합 시사점
- 단일 테이블(
emission)로도 충분히 탄소·재무 관련 핵심 인사이트 도출 가능 - 향후 실제 시계열 및 산업군 데이터가 추가되면, 분석 정밀도 및 정책 연결성 더욱 강화 가능

💻