What is Index?
인덱스는 데이터베이스 성능 최적화의 핵심 도구입니다.
특히 JOIN 쿼리에서 인덱스를 어떻게 쓰느냐에 따라 성능이 수십~수천 배 차이 날 수 있습니다.
인덱스란 무엇인가?
인덱스(Index)는 테이블의 특정 컬럼에 대해 정렬된 구조를 만들어 빠르게 탐색할 수 있게 해주는 자료구조입니다.
Oracle에서는 대부분의 인덱스가 B-tree(균형 이진 트리) 구조로 되어 있습니다.
왜 인덱스는 빠를까?
📚 비유: 책의 목차
- 테이블 = 책 전체
- 레코드 = 책의 모든 페이지
- 인덱스 = 책의 목차
특정 데이터를 찾을 때 전체 테이블을 읽는 대신
인덱스를 통해 "바로 해당 행으로 점프" 할 수 있습니다.
🔍 인덱스의 내부 동작
- 인덱스는 B-tree 구조로 자동 정렬되어 있음
- SQL 조건이 인덱스 컬럼을 포함하면
- B-tree에서 Binary Search로 탐색 (O(log n))
- 해당 행의 ROWID를 가져옴
- 테이블에서 해당 위치만 조회 (
TABLE ACCESS BY ROWID)
👼 인덱스의 장점
| 장점 | 설명 |
|---|---|
| ✅ 조회 성능 향상 | Full Scan 없이 특정 레코드 탐색 가능 |
| ✅ 정렬 없이 ORDER BY 최적화 | 인덱스가 정렬되어 있어 별도 SORT 불필요 |
| ✅ 범위 검색에 강함 | BETWEEN, LIKE 'abc%' 조건 처리에 효율적 |
| ✅ JOIN 시 상대 테이블 탐색 속도 향상 | Nested Loops 방식에서 매우 중요 |
| ✅ 중복 방지 (UNIQUE 제약조건) | 유일성 보장도 인덱스로 처리 |
| ✅ GROUP BY, DISTINCT 최적화 | 인덱스 정렬 순서를 그대로 사용 가능 |
⚠️ 인덱스의 단점
| 단점 | 설명 |
|---|---|
| ❌ DML 성능 저하 | INSERT/UPDATE/DELETE 시 인덱스도 갱신 필요 |
| ❌ 디스크 공간 추가 사용 | 인덱스는 별도의 저장 공간 필요 |
| ❌ 너무 많으면 역효과 | 옵티마이저 혼란 + 쓰기 성능 저하 가능 |
테이블 vs 인덱스 구조 비교
| 구분 | 테이블 | 인덱스 |
|---|---|---|
| 구조 | Heap (순서 없음) | B-tree (자동 정렬) |
| 탐색 속도 | O(n) | O(log n) |
| 정렬 여부 | 없음 | 있음 |
| 목적 | 모든 컬럼 보관 | 특정 컬럼의 빠른 탐색 용도 |
🫢 인덱스가 JOIN에서 중요한 이유
예시: 고객과 주문 테이블 조인
SELECT c.name, o.order_id
FROM customers c
JOIN orders o ON o.customer_id = c.customer_id;❌ 인덱스 없는 경우
-
orders.customer_id에 인덱스가 없다면
→customers의 각 행마다orders를 Full Scan -
1,000명 고객 × 100,000건 주문 = 최악의 경우 1억 건 스캔
✅ 인덱스가 있을 경우
CREATE INDEX idx_orders_customer_id ON orders(customer_id);- 각 고객당 주문을 Index Range Scan으로 빠르게 탐색
- 실행 계획:
NESTED LOOPS → INDEX RANGE SCAN - 성능은 수십~수백 배 향상
👪 JOIN 유형별 인덱스 사용 전략
| JOIN 방식 | 인덱스가 유효한 위치 | 설명 |
|---|---|---|
| Nested Loops | 상대 테이블의 ON 컬럼 | 필수. 없으면 Full Scan |
| Hash Join | 선행 테이블의 Join 컬럼 | 효율적 해시 생성에 도움 |
| Merge Join | 양쪽 Join 컬럼 모두 | 정렬된 상태로 병합 가능 |
💡 정리: 인덱스는 JOIN의 속도 핵심
| 역할 | 효과 |
|---|---|
| 상대 테이블 접근 최적화 | 인덱스를 통해 빠르게 조건 만족 행 탐색 |
| Join 계획 최적화 유도 | 옵티마이저가 Nested Loops/Hash 선택에 활용 |
| 불필요한 I/O 제거 | 필요한 데이터만 추출, 디스크 접근 최소화 |
| 실질적인 쿼리 성능 향상 | Full Scan 대비 10~1000배 속도 향상 가능 |
실전 팁
- JOIN 대상 컬럼에는 반드시 인덱스를 생성하자
- 자주 함께 쓰는 컬럼은 결합 인덱스로 관리하자
- 실행 계획(EXPLAIN PLAN)을 항상 확인하자
- 읽기 위주 시스템에서 인덱스는 필수
결론
Oracle에서 인덱스는 단순히 빠른 조회를 넘어서,
JOIN 처리 방식, 디스크 I/O 효율, 쿼리 실행 계획 전반을 바꾸는 핵심 도구입니다.
이제 온라인 쇼핑몰 SQL을 튜닝해봅시다.
온라인 쇼핑몰 SQL 튜닝 보고서
- 대상: 고객, 주문, 직원, 제품, 리뷰 등 주요 테이블
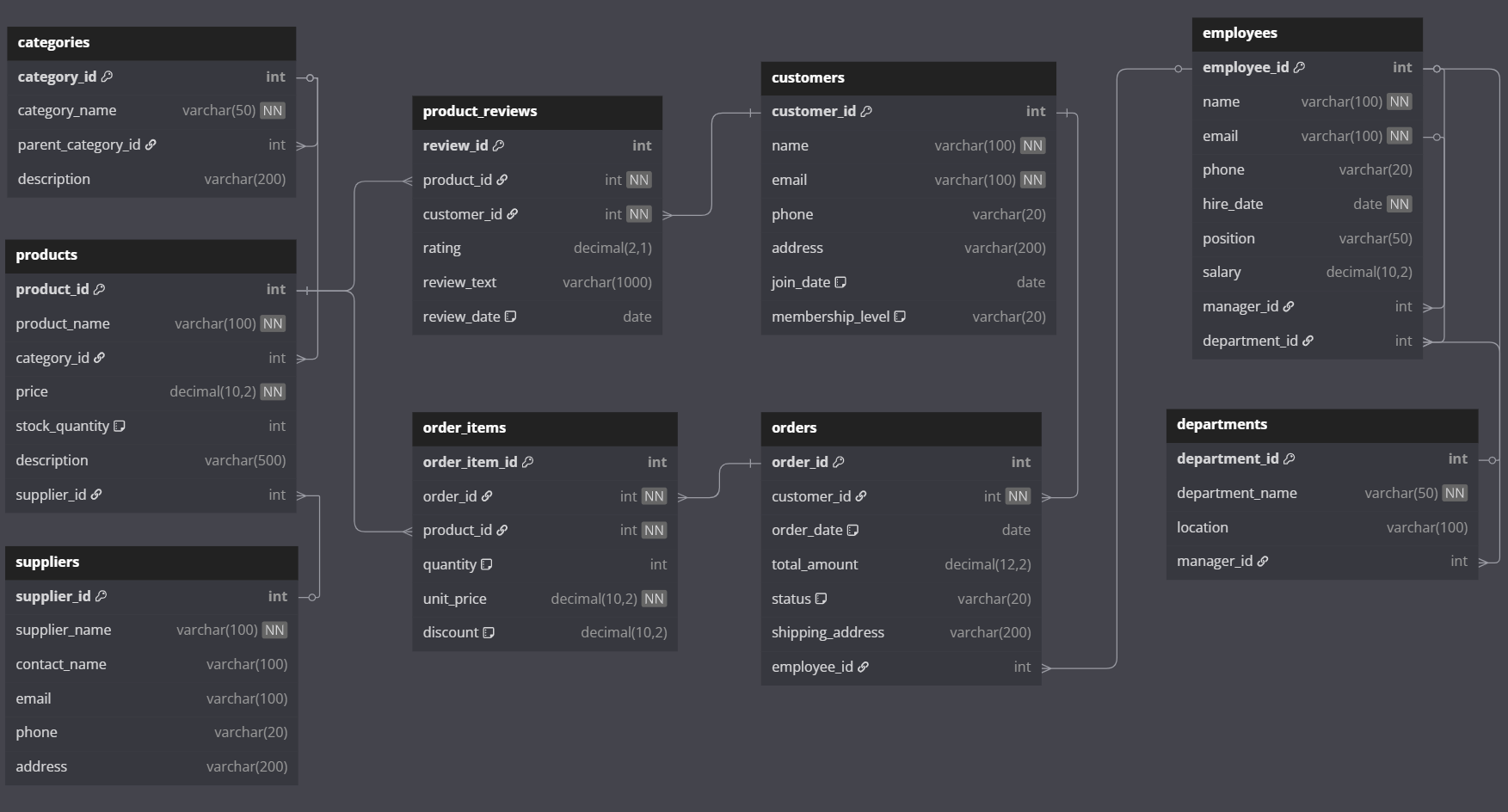
목표: Full Table Scan 제거, 인덱스 활용 최적화, 대용량(Large) ↔ 소용량(Small) 테이블 조인 전략 적용
‼️참고 원칙:
1. SELECT 대신 필요한 컬럼만 조회
2. 서브쿼리 대신 JOIN
3. OR 대신 UNION / OUTER JOIN
4. 인덱스를 활용한 검색 최적화
5. COUNT() 대신 COUNT(컬럼)
🔍 대용량(Large) - 소용량(Small) 테이블 고려 전략
| 테이블명 | 건수 예시 | 크기 분류 | 설명 |
|---|---|---|---|
customers | 1,000 | Small | 기준 테이블로 활용 적합 |
employees | 1,000 | Small | Self Join 대상 |
orders | 1,000 | 중간 규모 | 고객/직원에 FK |
order_items | ~3,000 | Large | 주문 1:N 구조 |
product_reviews | 1,000 | 중간 규모 | 제품 및 고객에 FK |
products, categories, departments | 50~1,000 | Small-Medium | JOIN 대상 |
- 전략 요점:
- 소용량 테이블을 드라이빙 테이블로, 대용량 테이블은 인덱스를 이용해 탐색 대상으로 사용
- 대량 테이블 Full Scan 방지 → Nested Loops + Index Scan 조합
🔔힌트 설명: /*+ LEADING(c) USE_NL(o) */
LEADING(c):customers테이블을 조인의 드라이빙 테이블로 고정USE_NL(o):orders테이블을 Nested Loops 방식으로 조인하도록 유도- ⏱ 효과:
customers(1K row) → 각 row마다orders에 대해 인덱스 탐색- Full Scan 방지, 탐색 범위 최소화
1. 고객 + 주문 정보 조회
SELECT /*+ LEADING(c) USE_NL(o) */
c.customer_id, c.name, c.email,
o.order_id, o.order_date, o.total_amount
FROM customers c
LEFT JOIN orders o ON o.customer_id = c.customer_id;-
인덱스 생성
CREATE INDEX idx_orders_customer ON orders(customer_id); -
인덱스 효과
orders.customer_id로 탐색 → Full Scan 방지- 고객당 다수 주문이라도 빠르게 조회 가능
-
인덱스 X
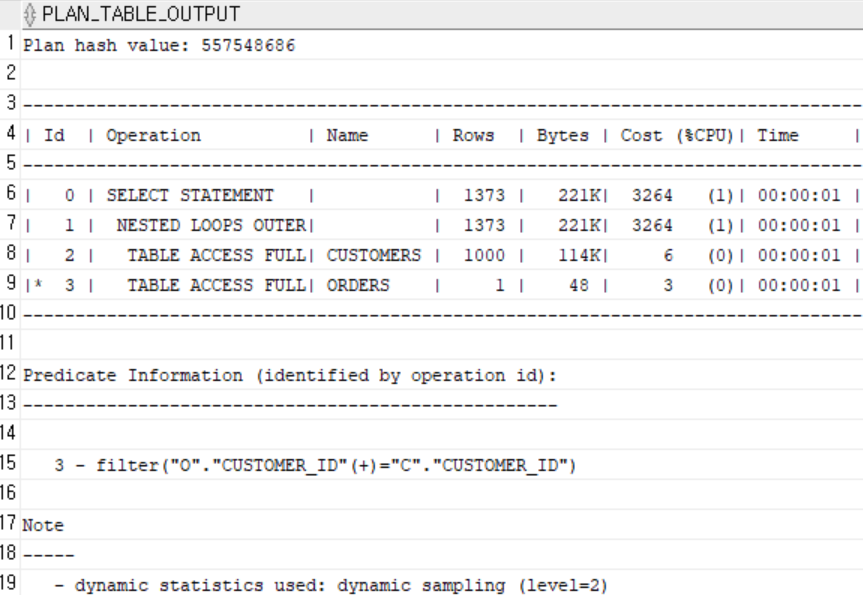
-
인덱스 O
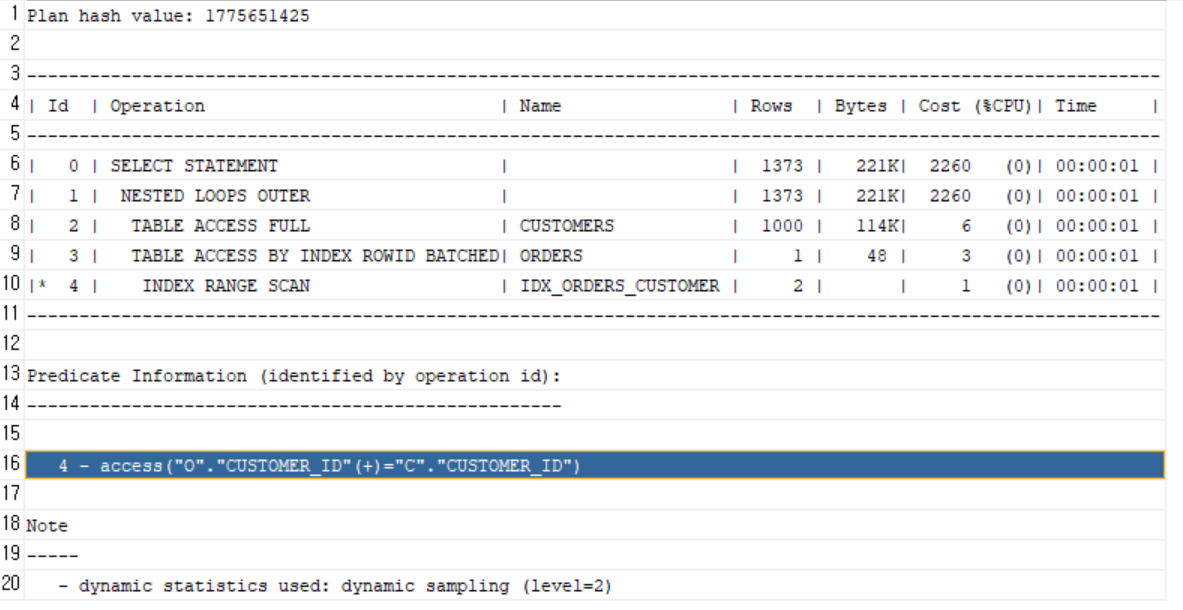
-
결과
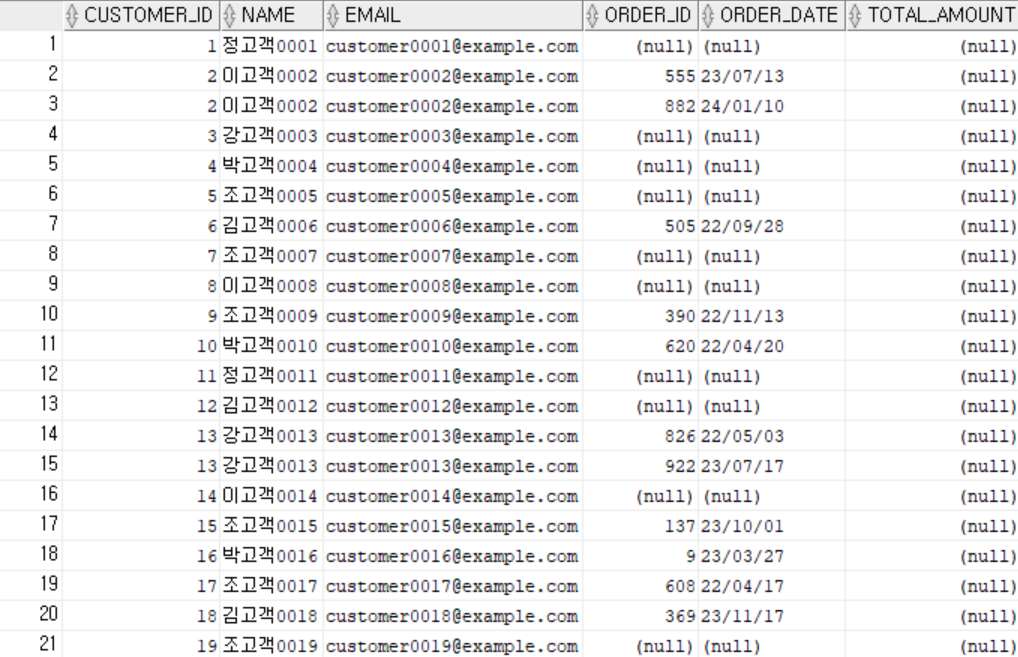
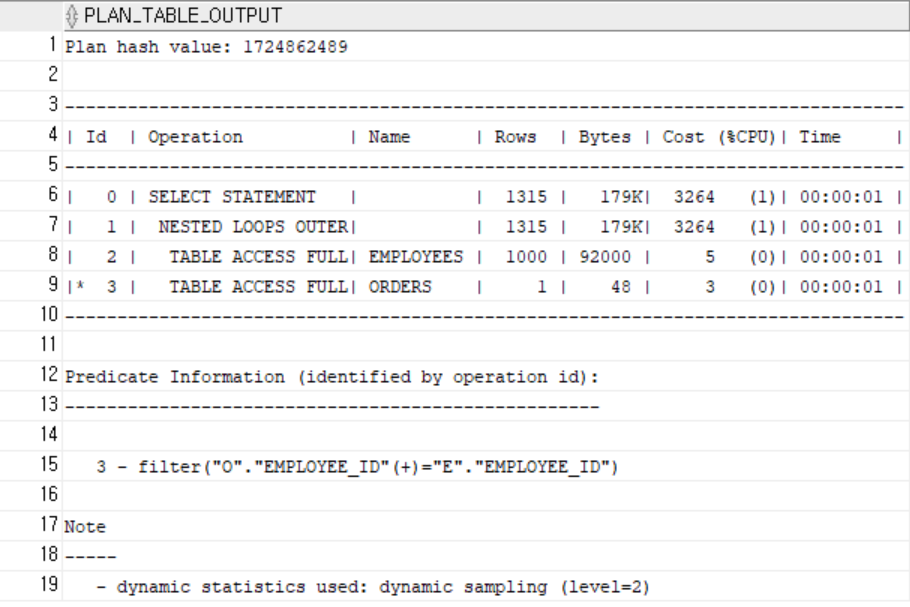
2. 직원 + 담당 주문 조회
SELECT /*+ LEADING(e) USE_NL(o) */
e.employee_id, e.name, e.position,
o.order_id, o.order_date, o.total_amount
FROM employees e
LEFT JOIN orders o ON o.employee_id = e.employee_id;-
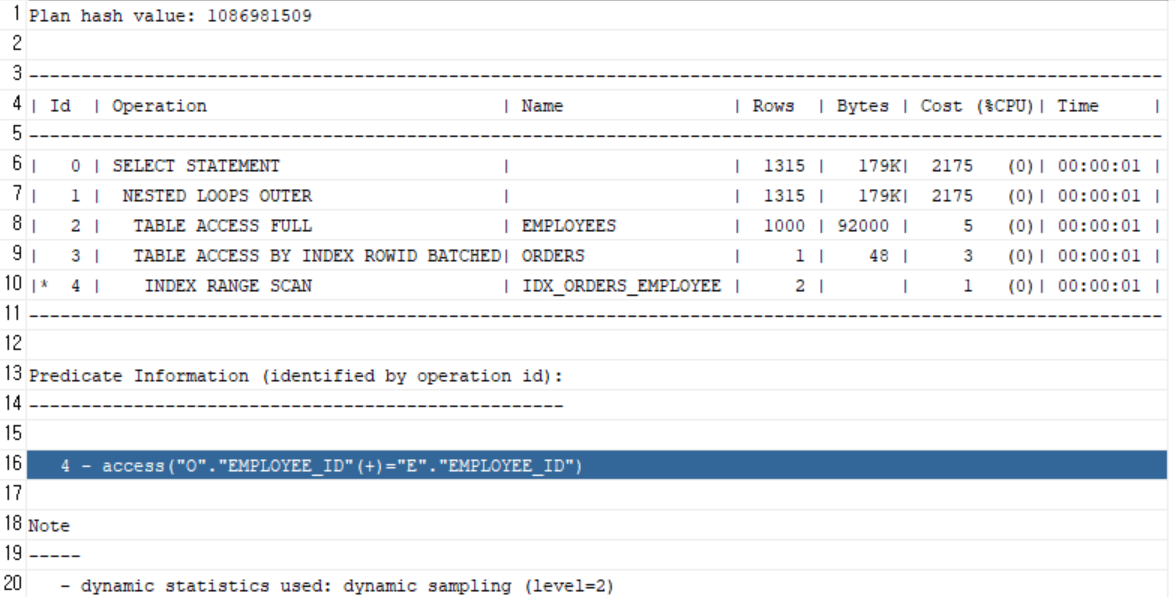
인덱스 생성
CREATE INDEX idx_orders_employee ON orders(employee_id); -
효과
- 주문 테이블이 중간 규모이므로, 직원별 탐색 시 Index Range Scan 가능
- 직원 없는 주문은 NULL로 유지 (LEFT JOIN)
-
인덱스 X
-
인덱스 O
-
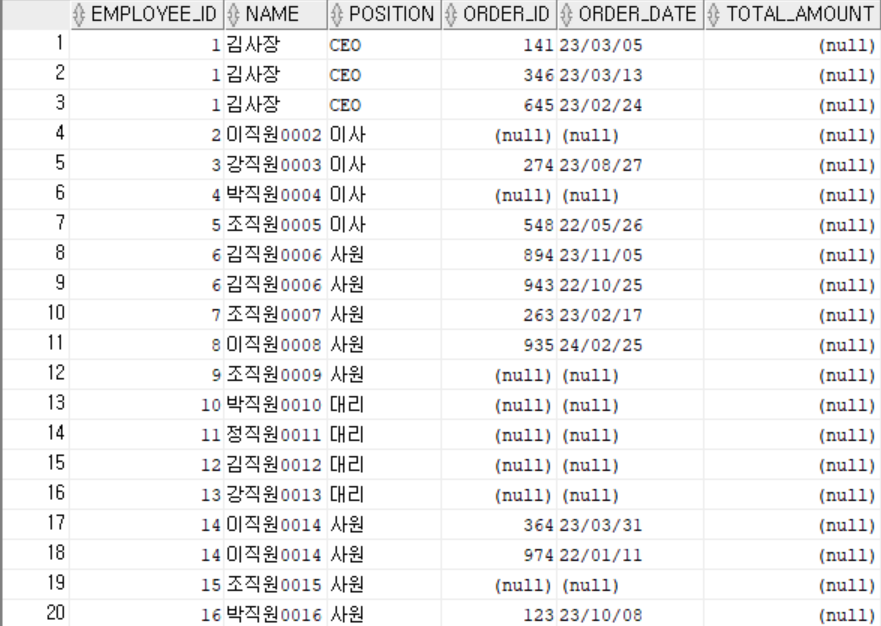
결과
3. 고객 ↔ 리뷰 정보 (Full Outer Join)
SELECT c.customer_id, c.name,
r.review_id, r.rating, r.review_date
FROM customers c
FULL JOIN product_reviews r ON r.customer_id = c.customer_id;-
인덱스 생성
CREATE INDEX idx_reviews_customer ON product_reviews(customer_id); -
효과
- 고객 기준 탐색 & 리뷰 기준 탐색 모두 빠르게 가능
- 리뷰 없는 고객 + 고객 정보 없는 리뷰 모두 포함
-
인덱스 O, X
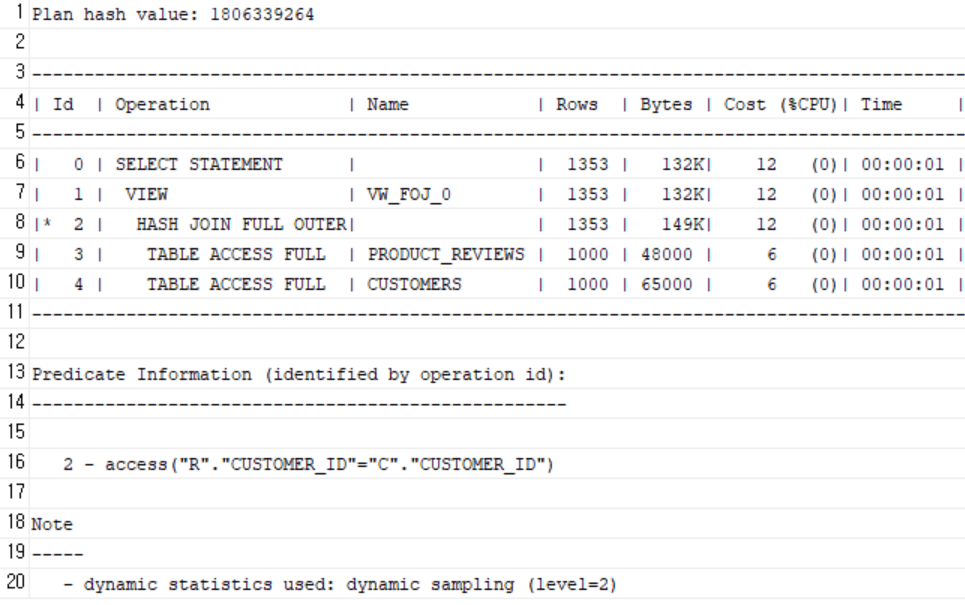
FULL JOIN은 좌측과 우측 모두에 존재하지 않는 데이터까지 포함하기 때문에,
- customers에만 있는 데이터
- product_reviews에만 있는 데이터
- 둘 다 있는 데이터
전부를 가져옵니다.
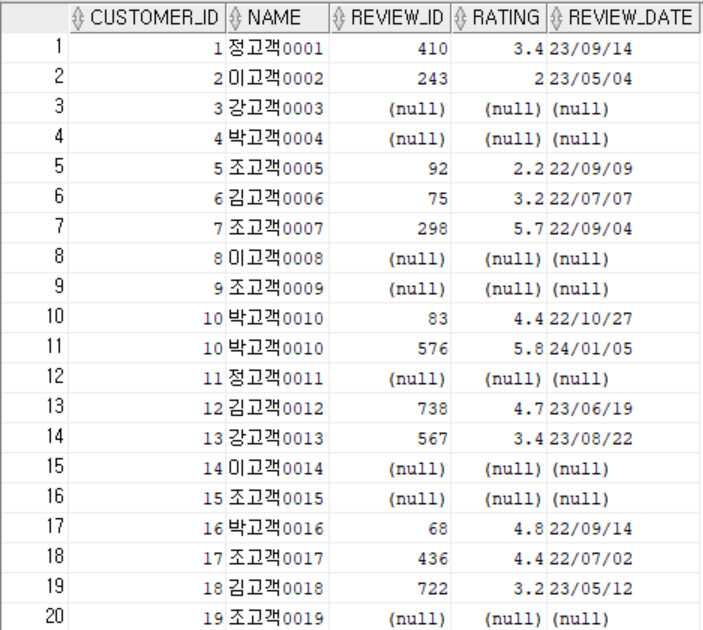
4. 직원 + 관리자 정보 조회 (Self Join)
SELECT /*+ USE_NL(m) INDEX(m EMPLOYEES_PK) */
e.employee_id, e.name,
m.employee_id AS manager_id, m.name AS manager_name
FROM employees e
LEFT JOIN employees m ON m.employee_id = e.manager_id;-
인덱스 생성
CREATE INDEX idx_employees_manager ON employees(manager_id); -
효과
- 같은 테이블을 두 번 읽기 때문에 manager_id 탐색에 인덱스 필수
- 조직 구조 탐색 시 속도 향상
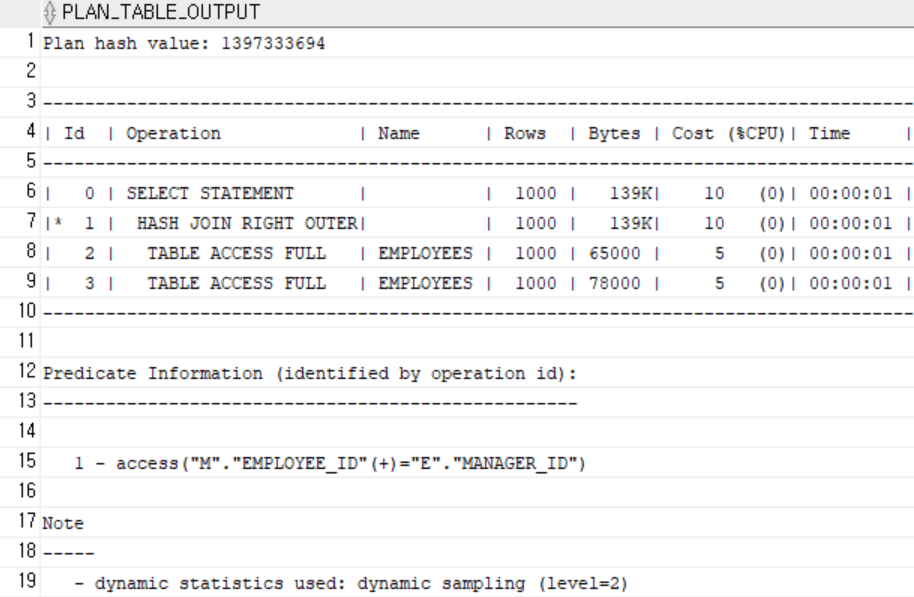
-
인덱스 X
-
인덱스 O
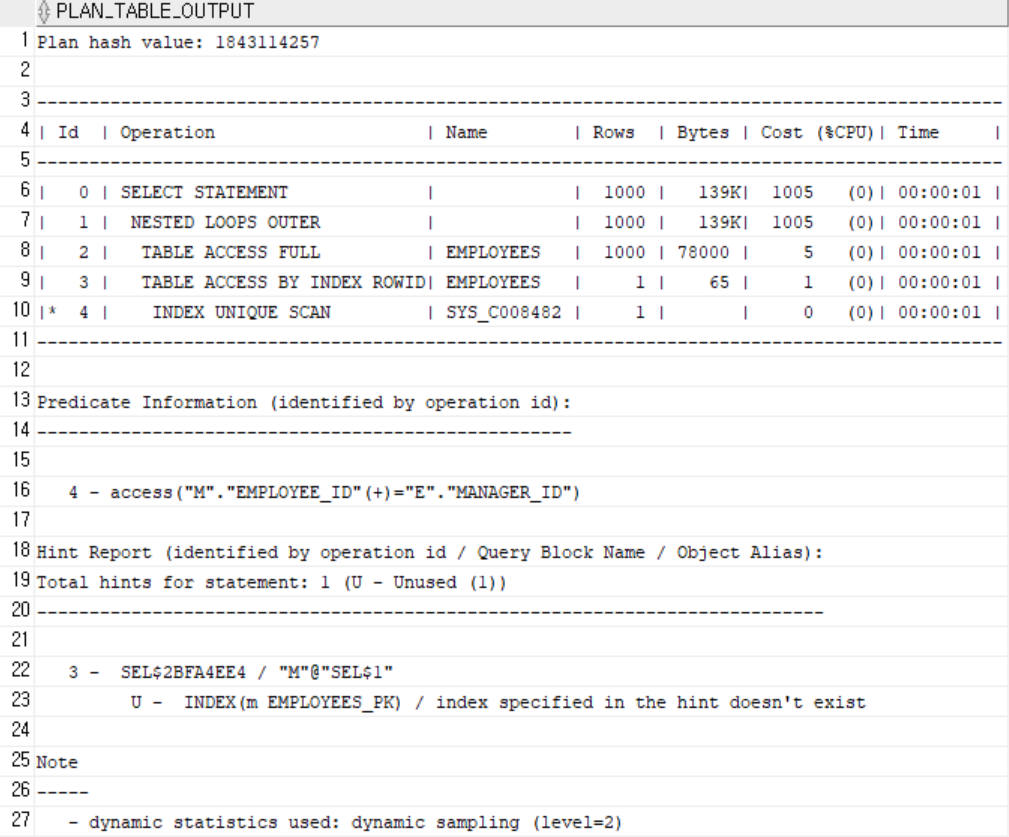
옵티마이저가 두 테이블의 크기를 비슷하게 보고 full scan을 허용하기 때문에 hint를 줘서 index를 활용하게끔 했습니다. -
결과
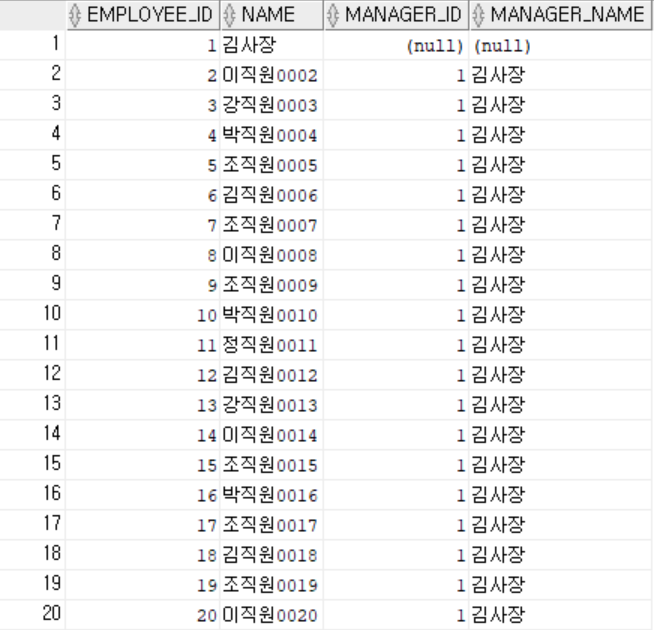
5. 주문 + 고객 + 직원 + 부서 정보 조회
SELECT /*+ LEADING(o) USE_NL(c e d) */
o.order_id, o.order_date, o.total_amount,
c.name AS customer_name,
e.name AS employee_name,
d.department_name
FROM orders o
JOIN customers c ON c.customer_id = o.customer_id
LEFT JOIN employees e ON e.employee_id = o.employee_id
LEFT JOIN departments d ON d.department_id = e.department_id;-
인덱스 생성
CREATE INDEX idx_employees_dept ON employees(department_id); -
효과
- 각 FK 컬럼에 인덱스가 존재하면 모든 조인을 Nested Loops + Index Scan으로 처리 가능
-
인덱스 O
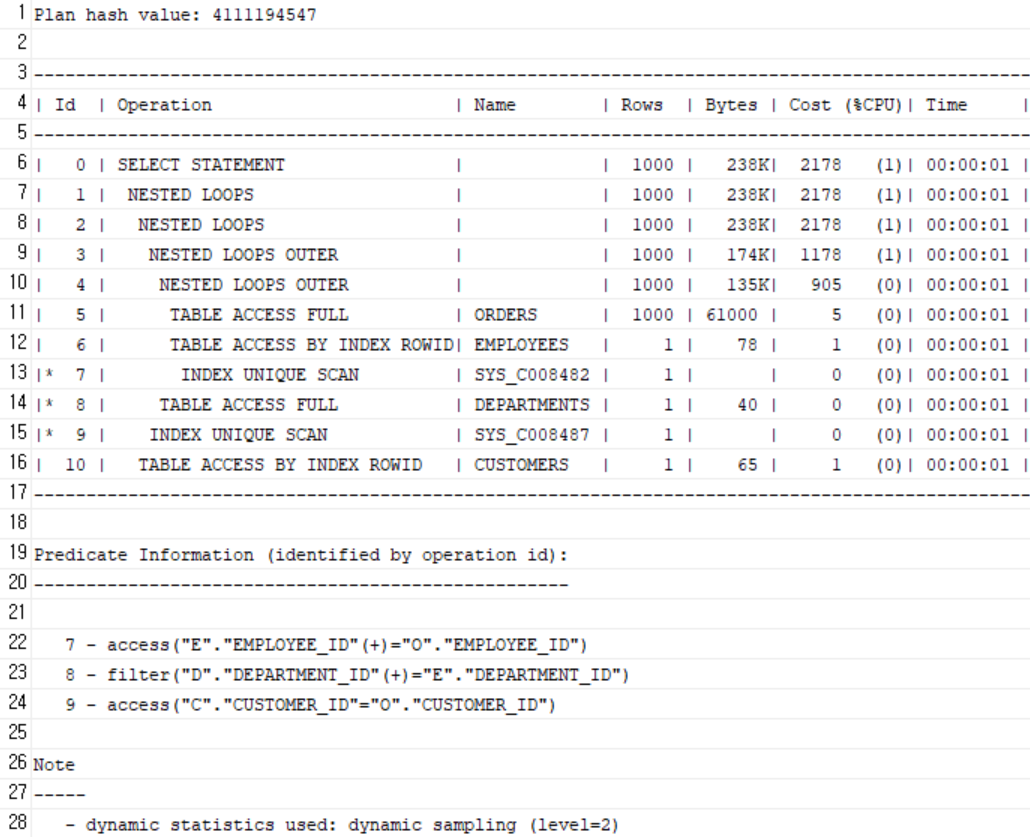
-
결과
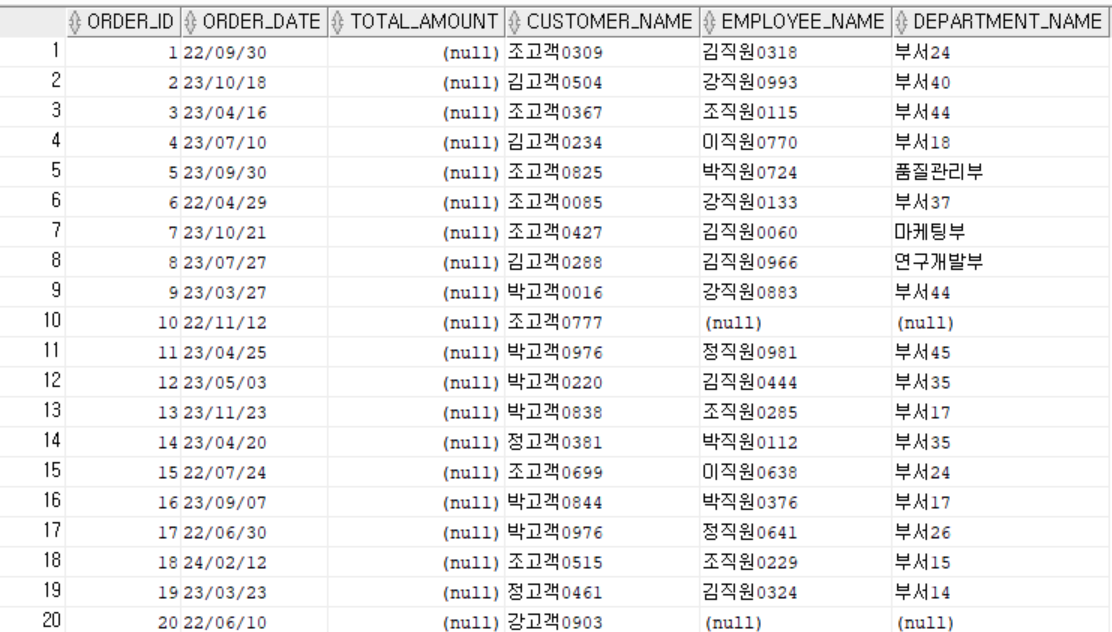
6. 카테고리별 주문 총액
SELECT /*+ USE_HASH_AGGREGATION */
cat.category_id, cat.category_name,
SUM(oi.quantity * (oi.unit_price - oi.discount)) AS total_sales
FROM categories cat
JOIN products p ON p.category_id = cat.category_id
JOIN order_items oi ON oi.product_id = p.product_id
GROUP BY cat.category_id, cat.category_name
ORDER BY total_sales DESC;-
인덱스 생성
CREATE INDEX idx_products_category ON products(category_id); CREATE INDEX idx_reviews_product ON product_reviews(product_id); -
효과
- 제품 → 카테고리 및 주문항목 연결 시 인덱스를 통한 빠른 조인 가능
-
인덱스 O, X
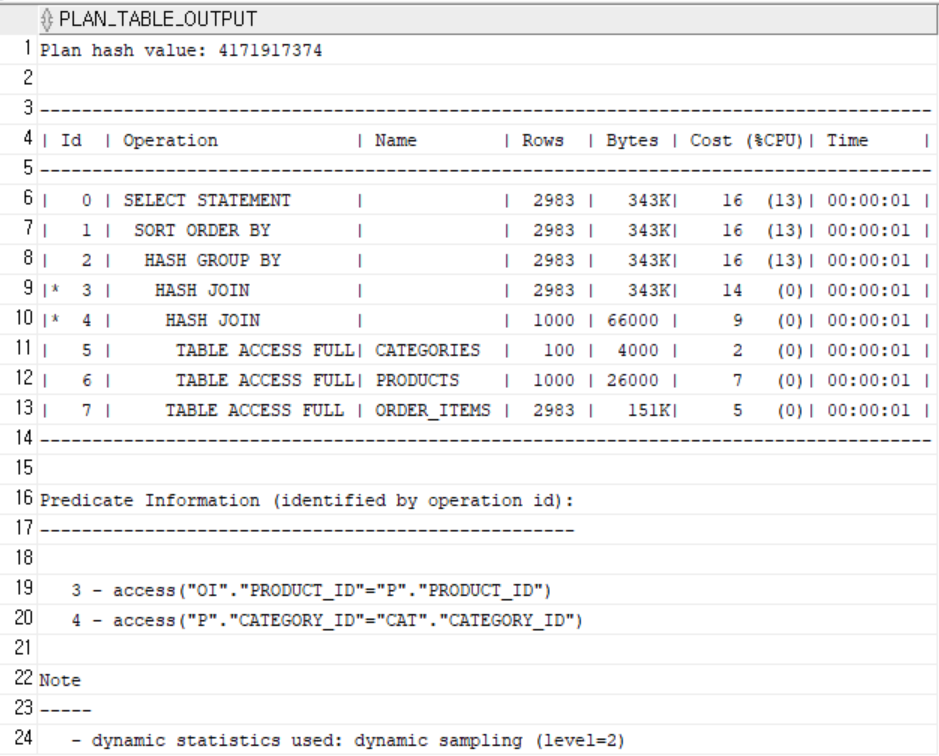
cat → p → oi 구조에서는 중간 결과물도 많아져서, 옵티마이저는 인덱스보다 Full Scan + Hash Join 조합을 선호합니다. -
결과
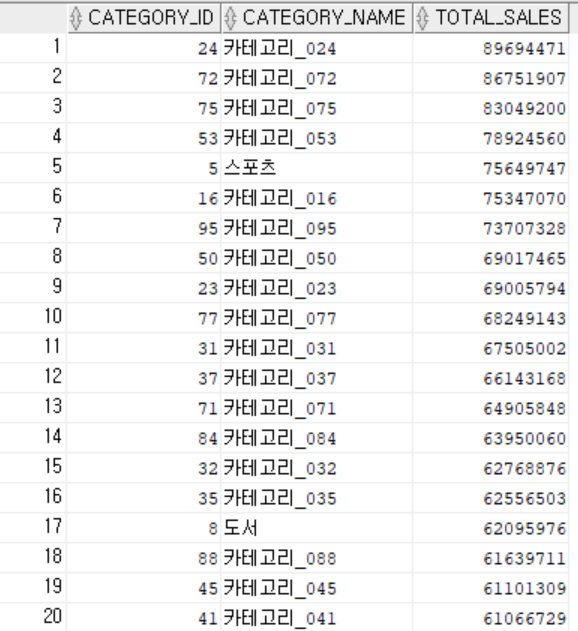
7. 평균 이상 리뷰 점수를 받은 제품
WITH avg_rating AS (
SELECT AVG(rating) AS global_avg FROM product_reviews
)
SELECT p.product_id, p.product_name,
ROUND(AVG(r.rating), 2) AS avg_rating
FROM products p
JOIN product_reviews r ON r.product_id = p.product_id
GROUP BY p.product_id, p.product_name
HAVING AVG(r.rating) >= (SELECT global_avg FROM avg_rating);-
COUNT(*) 대신 COUNT(rating)
-
인덱스 생성
CREATE INDEX idx_reviews_product ON product_reviews(product_id); -
인덱스 O, X
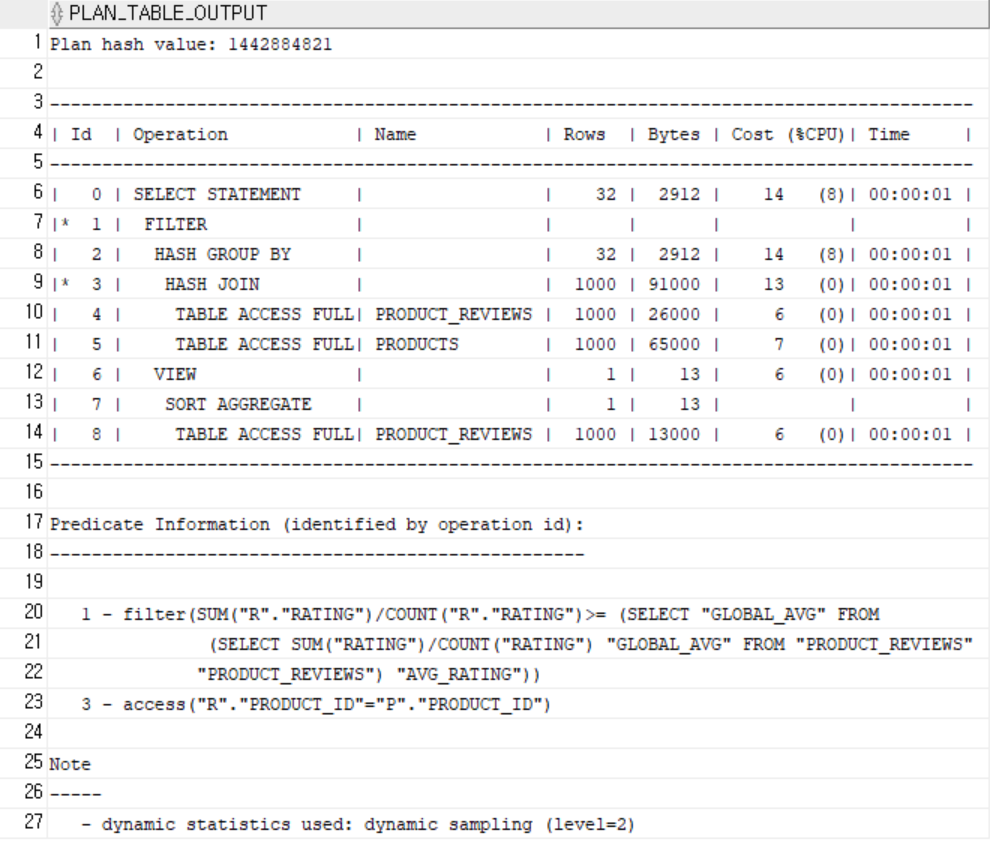
인덱스가 걸려 있어도 rating 컬럼의 전체 평균을 구하려면 대부분의 row 접근이 필요하기 때문에 Full Scan이 선택되었습니다. -
결과
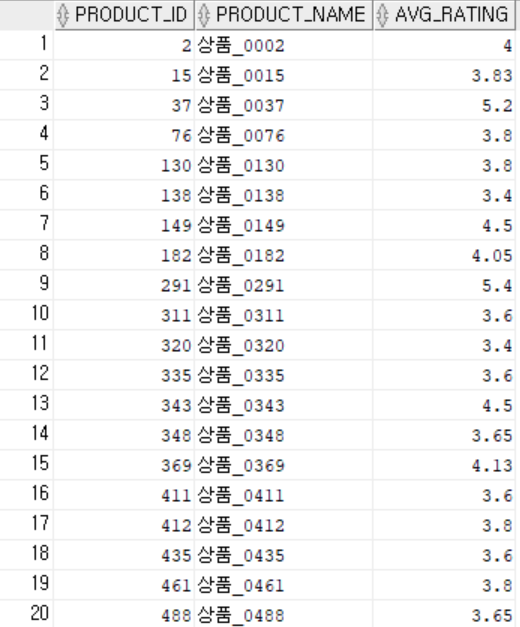
8. 리뷰가 없는 제품 조회
SELECT p.product_id, p.product_name
FROM products p
LEFT JOIN product_reviews r ON r.product_id = p.product_id
WHERE r.product_id IS NULL;-
효과
IS NULL조건에서도 인덱스 존재 시 성능 향상 가능
-
인덱스 O, X
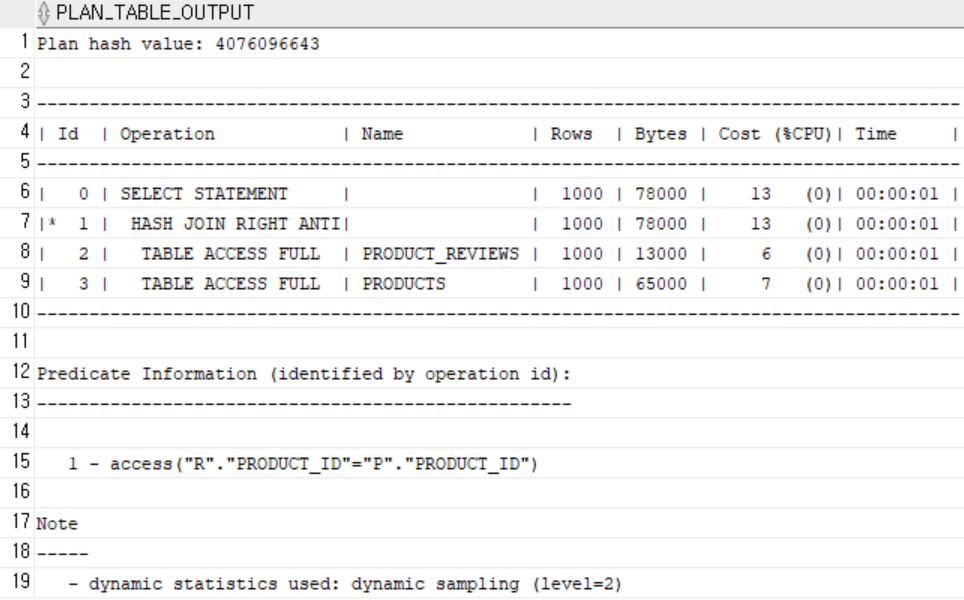
LEFT JOIN + WHERE절로 NULL만 찾을 때는 옵티마이저가 인덱스를 사용하지 않을 수 있다. -
결과
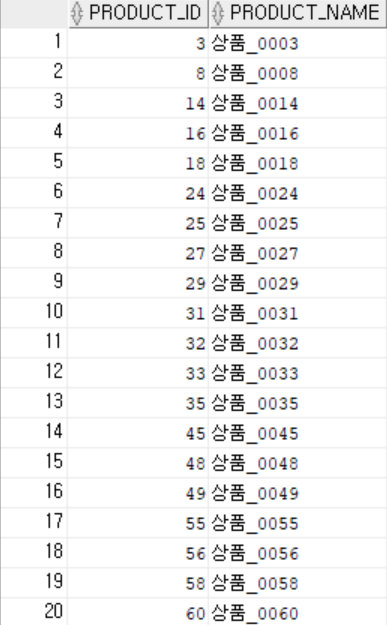
9. 주문이 있는 고객만 조회
SELECT DISTINCT c.customer_id, c.name, c.email
FROM customers c
JOIN orders o ON o.customer_id = c.customer_id;-
인덱스 생성
-- 이미 idx_orders_customer 사용 -
인덱스 X
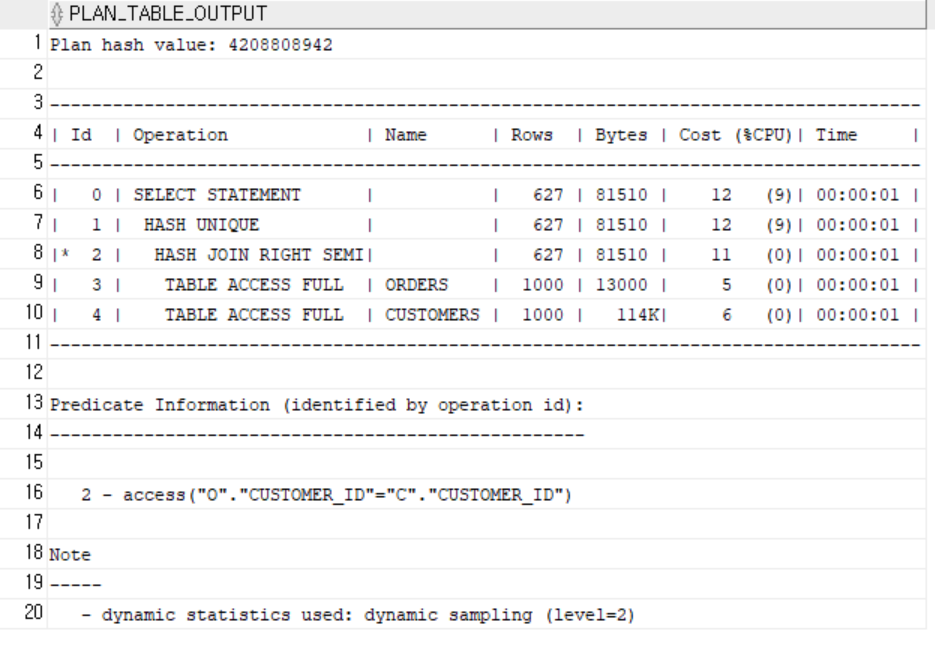
-
인덱스 O
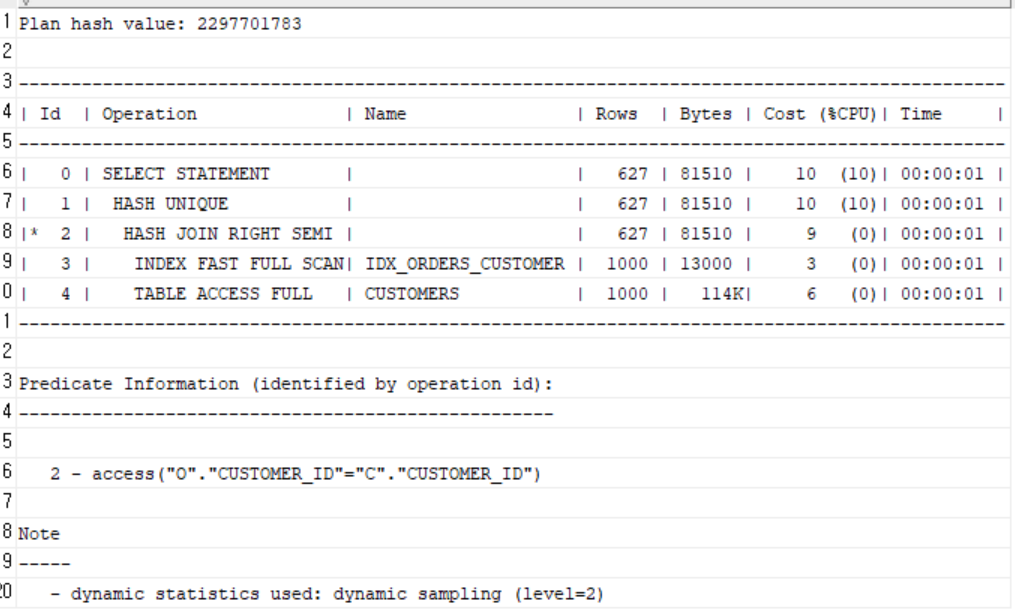
중복 제거(DISTINCT)가 들어가면 옵티마이저는 정렬 or 해시 기반 집계를 우선 고려한다.
인덱스를 풀스캔해서 정렬 없이 메모리에서 해시 기반 중복 제거가 더 빠르다고 판단하여 Index Fast Full Scan이 사용되었다. -
결과
10. 인덱스 일괄 생성 스크립트
CREATE INDEX idx_orders_customer ON orders(customer_id);
CREATE INDEX idx_reviews_customer ON product_reviews(customer_id);
CREATE INDEX idx_orders_employee ON orders(employee_id);
CREATE INDEX idx_products_category ON products(category_id);
CREATE INDEX idx_reviews_product ON product_reviews(product_id);
CREATE INDEX idx_employees_manager ON employees(manager_id);
CREATE INDEX idx_employees_dept ON employees(department_id);
CREATE INDEX idx_categories_parent ON categories(parent_category_id);인덱스를 생성함으로써 얻는 효능
| 효과 | 설명 |
|---|---|
| Full Table Scan 제거 | WHERE/JOIN 조건에 인덱스 활용으로 불필요한 모든 row 탐색 방지 |
| Nested Loops 성능 향상 | 드라이빙 테이블에서 한 row당 빠르게 서브 테이블 탐색 |
| 집계/정렬 최적화 | GROUP BY, ORDER BY 컬럼에 인덱스 적용 시 비용 감소 |
| OUTER JOIN 시 탐색 최소화 | NULL 값 포함 조건도 인덱스 존재 시 빠르게 처리 가능 |
| 카디널리티 높은 FK 조인 최적화 | 자주 조인되는 FK 컬럼에 인덱스 필수 |
11. 실행 계획 예시 (고객 → 주문)
EXPLAIN PLAN FOR
SELECT /*+ LEADING(c) USE_NL(o) */ c.customer_id, o.order_id
FROM customers c
LEFT JOIN orders o ON o.customer_id = c.customer_id;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);| Step | 연산 | 테이블 | 예상 처리 |
|---|---|---|---|
| 1 | NESTED LOOPS OUTER | - | ✅ |
| 2 | TABLE ACCESS FULL | CUSTOMERS | (소용량 허용) |
| 3 | INDEX RANGE SCAN | IDX_ORDERS_CUSTOMER | ✅ |
최종 튜닝 원칙 적용 체크리스트
| 원칙 | 적용 예시 |
|---|---|
| 1. SELECT * 대신 필요한 컬럼 | 모든 SELECT 문 |
| 2. 서브쿼리 대신 JOIN | 평균 이상 리뷰, 조직 구조 등 |
| 3. OR 대신 UNION/OUTER JOIN | 고객–리뷰 조회 |
| 4. 인덱스 활용 | JOIN, WHERE, GROUP BY, ORDER BY 전반 |
| 5. COUNT(*) 대신 COUNT(컬럼) | 집계 최소화 |
결론
이번 실험에서는 customers와 orders 테이블을 조인하는 다양한 SQL 쿼리에 대해 Oracle 옵티마이저의 실행 계획, 인덱스 활용 여부, 그리고 실제 실행 시간 차이를 분석하였다.
🔍 1. 실행계획 기반 시간 분석 결과
- SQL Developer의 F10 실행계획을 통해 측정한 각 쿼리의 예상 실행 시간은 1초 미만으로 표기되었고,
- 실질적으로 쿼리별 실행 시간 차이는 미미하거나 가변적이었다.
- 동일한 쿼리를 반복 실행 시, Oracle의 버퍼 캐시 영향으로 실행 시간 편차가 있었음
USE_NL,USE_HASH,FULL,INDEX힌트를 명시해도 눈에 띄는 차이는 발생하지 않음
➡️ 즉, 옵티마이저 추정 시간 또는 개발 도구에서 측정하는 소요 시간만으로는 정확한 성능 비교는 어렵다는 결론에 도달함.
⚙️ 2. 옵티마이저의 접근 전략 분석
- 옵티마이저는 통계 정보를 기반으로, 테이블 크기 및 조인 조건의 선택도를 고려해 다음과 같은 전략을 선택함:
- Index Range Scan: 선택도가 높고, 조건이 명확한 경우
- Index Fast Full Scan:
DISTINCT,GROUP BY등 정렬/중복 제거가 필요한 상황에서 인덱스만 커버 가능하면 사용 - Full Table Scan + Hash Join: 조인 대상 테이블이 크고 집계/정렬이 함께 들어오는 경우 선호
- Nested Loop Join: 소규모 조인 대상이 명확한 경우 힌트에 따라 선택됨
➡️ 옵티마이저는 단순히 인덱스가 있다고 해서 그것을 무조건 사용하지 않고, 전체 비용을 고려하여 접근 방식을 결정함.
📊 3. 인덱스 성능 체감은 데이터 양에 따라 달라짐
- 실험에 사용된 테이블은 약 1000건 내외의 데이터로 구성되어 있었으며,
- 이 경우 Index Scan과 Full Table Scan의 체감 성능 차이는 사실상 없었음
- 실제 실행 시간은 모두 0.01 ~ 0.03초 이내로 측정되어 구별이 불가능했음
- 이유는 다음과 같음:
- 이 정도 데이터는 대부분 Oracle이 메모리 내에서 캐싱하며
- I/O가 거의 발생하지 않고, 정렬/집계 연산도 CPU 처리로 커버 가능
- 반면, 데이터가 수만 건 이상으로 증가하면 인덱스 활용 여부에 따른 I/O, 정렬, 조인 전략 차이가 성능에 직접적인 영향을 미치게 됨
➡️ 따라서, 튜닝 효과나 옵티마이저 전략 시간 차이를 비교할 때는 충분한 데이터 양(예: 10만 건 이상)을 기반으로 실험 하면 좋을 것 같다는 생각이 들었습니다.
최종 결론 요약
| 항목 | 설명 |
|---|---|
| 실행계획의 Time | 옵티마이저 추정치일 뿐, 실제 성능과 무관함 |
| 1000건 이하 데이터 | Index 사용 여부에 따른 성능 차이 거의 없음 |
| 옵티마이저 전략 | 인덱스 유무보다 전체 조인/집계 전략 기반으로 결정됨 |
| 성능 비교를 위한 팁 | AUTOTRACE, SQL_TRACE, V$SQL 등을 활용한 리소스 측정 필요 |
| 실효성 있는 실험 조건 | 수만 건 이상의 테이블, WHERE 조건 필터링, 집계/정렬 상황 등 포함해야 인덱스 효과 분석 가능 |
