*공부 및 복습 용도의 글입니다. 부족하거나 틀린 부분이 있다면 댓글로 알려주신다면 감사드리겠습니다.
VGGNet
VGGNet은 옥스포드 대학 소속의 Karen Simonyan, Andrew Zisserman이 만든 CNN 모델이다. 2014년 ILSVRC에서 준우승을 차지하였고, 비교적 단순한 구조로 당해 우승작인 GoogLeNet보다도 인기를 끌었다. 논문 Very Deep Convolutional Networks for Large-Scale Image Recognition을 살펴보자.
Architecture
Pre-processing
- 전처리를 위해, 입력으로 들어가는 RGB 이미지 각각에 평균 RGB값을 빼서 normalize한다.
Configurations
- 논문에서는 VGGNet을 층의 개수를 늘려가며 여러 가지로 실험해보았다.
원 논문에 나온 VGGNet의 구조 A~E
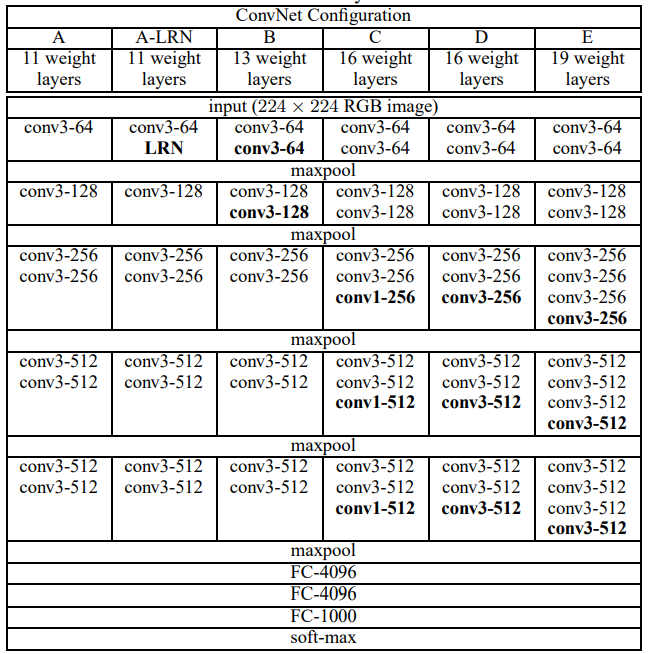
- 표에 나와있듯 아래의 FC layer들과 soft-max층은 전부 공통이고, 나머지 층들은 A~E 각자 설정된 개수의 convolution layer를 가지고 있다.
- 가령 D는 conv층과 FC층 총 16개를 가지고 있어, VGG16이라 불린다. E도 마찬가지로 VGG19로 불린다.
- VGG16과 VGG19는 다른 구조(A~C)에 비해 성능이 좋아 VGGNET이라 하면 보통 이 둘, 그 중에서도 VGG16을 말한다. 둘의 성능은 거의 비슷하지만 VGG16이 더 가볍고 파라미터가 적기 때문이다.
- A~E 각각의 구조는 학습을 따로 시킨 게 아니라 앞선 구조의 파라미터 값 일부를 다음 구조로 옮겨, 새로 더해진 층을 추가적으로 학습시키는 방식으로 진행되었다. 예를 들어 처음에 A를 학습시킨 후 위의 4개 층은 B에 옮기고, 추가된 conv3-64와 conv3-128을 학습시키는 것이다.
- A와 A-LRN을 비교한 결과, LRN(Local Response Normalization)은 성능을 늘려주지 못할 뿐더러 메모리와 훈련 시간을 증가시켰다. 그래서 B부터는 LRN을 사용하지 않았다.
- 모든 filter는 3x3, stride=1으로 고정이다. C에서만 추가적으로 1x1 filter가 쓰였다. Padding은 3x3에 대해 1픽셀, 즉 크기의 변화가 없도록 들어갔다.
- Max-pooling은 2x2, stride=2로 이루어졌다.
- AlexNet과 마찬가지로 ReLU nonlinearity를 사용했다.
3x3 filter
- 3x3 필터를 두 번 적용하면 5x5를 한 번 적용한 결과와 같고, 세 번 적용하면 7x7을 한 번 적용한 것과 같다(특성맵의 크기 측면에서).
참고 이미지 (출처: https://bskyvision.com/504)
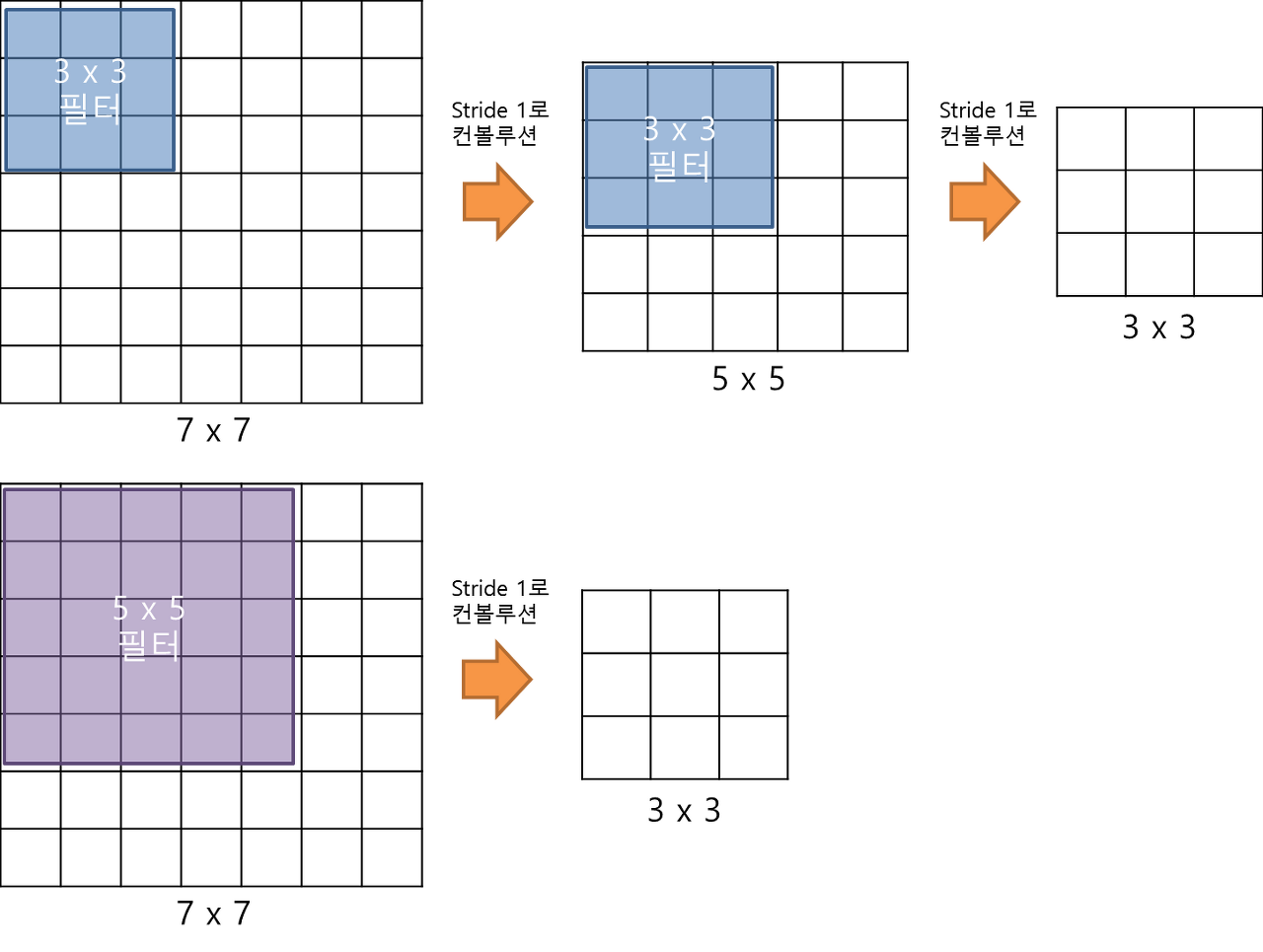
- 그럼에도 불구하고 5x5, 7x7을 쓰지 않은 이유는 두 가지다.
- 첫 번째 이유는 여러 층을 쓸수록 비선형층(여기서는 ReLU)도 늘어나므로, decision function이 더 discriminative 해지는 것이다(Discriminative는 차별적이라는 뜻. 분류를 더 정교하게 할 수 있다는 말 같다).
- 두 번째는 3x3을 썼을 때 가중치의 개수가 더 적어 훈련이 빠르다는 것이다.
- 가령 3x3을 세 층 쌓는다면 3x3x3=27개의 가중치를 가진다. 반면 7x7은 한 층뿐이지만 7x7x1=49개의 가중치를 가지게 된다.
- 한 편 C에서 쓰인 1x1 필터는 그저 선형변환일 뿐이지만, 그 뒤에 추가되는 ReLU층으로 인한 비선형성을 관찰하기 위한 것이다.
Training
- Optimizer는 Gradient descent with momentum으로, momentum=0.9, batch_size=256, l2=0.0005로 설정했다.
- Learning rate는 초기값 0.01에 validation accuracy가 늘지 않을 때마다 10으로 나눴다. 총 74 epoch를 돌며 learning rate는 3번 나뉘었다.
- 이는 alexnet과 비교해 더 빠른 훈련 속도이다. 그 이유는 더 깊은 깊이와 더 작은 filter로 (암묵적)정규화가 더 잘 되고, 미리 레이어들을 초기화했기 때문이다.
- 깊은 신경망의 잘못된 가중치 초기화는 훈련을 멈출 수도 있다. 이러한 문제를 방지하기 위해, vgg팀은 우선 비교적 얕은 A구조를 랜덤하게 초기화시켰다. 초기 가중치값은 mean=0, stdev=0.1인 정규분포로, bias는 전부 0으로 설정했다.
- Glorot, Bengio의 초기화 방법을 사용하면 이런 방식을 쓰지 않아도 된다고 한다.
아마도...? - Alexnet과 유사하게, 224x224 RGB 이미지에 crop과 flip을 적용해 훈련 데이터셋을 늘렸다.
Results
- VGG팀은 2014년도 ILSVRC에 참여해 top-1, top-5 오차율 각각 23.7%, 7.3%를 기록하며 2등을 했다.
- 이는 제출한 모델이 구조 C,D,E의 softmax층을 평균내어 사용했기 때문이고, 이후 D,E층만을 평균내어 사용하자 6.8%까지 줄일 수 있었다.
코드 구현
import numpy as np
import pandas as pd
import tensorflow as tf# define model parameters
NUM_EPOCHS = 1000
NUM_CLASSES = 10
IMAGE_SIZE = 224
BATCH_SIZE = 16#데이터 전처리(resize, one hot encoding) 파트
#twinjui님의 코드를 사용했다
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from tensorflow.keras.datasets import cifar10
def zero_one_scaler(image):
return image/255.0
def get_preprocessed_ohe(images, labels, pre_func=None):
# preprocessing 함수가 입력되면 이를 이용하여 image array를 scaling 적용.
if pre_func is not None:
images = pre_func(images)
# OHE 적용
oh_labels = to_categorical(labels)
return images, oh_labels
# 학습/검증/테스트 데이터 세트에 전처리 및 OHE 적용한 뒤 반환
def get_train_valid_test_set(train_images, train_labels, test_images, test_labels, valid_size=0.15, random_state=2021):
# 학습 및 테스트 데이터 세트를 0 ~ 1사이값 float32로 변경 및 OHE 적용.
train_images, train_oh_labels = get_preprocessed_ohe(train_images, train_labels)
test_images, test_oh_labels = get_preprocessed_ohe(test_images, test_labels)
# 학습 데이터를 검증 데이터 세트로 다시 분리
tr_images, val_images, tr_oh_labels, val_oh_labels = train_test_split(train_images, train_oh_labels, test_size=valid_size, random_state=random_state)
return (tr_images, tr_oh_labels), (val_images, val_oh_labels), (test_images, test_oh_labels )
# CIFAR10 데이터 재 로딩 및 Scaling/OHE 전처리 적용하여 학습/검증/데이터 세트 생성.
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
print(train_images.shape, train_labels.shape, test_images.shape, test_labels.shape)
(train_images, train_labels), (val_images, val_labels), (test_images, test_labels) = \
get_train_valid_test_set(train_images, train_labels, test_images, test_labels, valid_size=0.2, random_state=2021)
print(train_images.shape, train_labels.shape, val_images.shape, val_labels.shape, test_images.shape, test_labels.shape)from tensorflow.keras.utils import Sequence
import cv2
import sklearn
# 입력 인자 images_array labels는 모두 numpy array로 들어옴.
# 인자로 입력되는 images_array는 전체 32x32 image array임.
class CIFAR_Dataset(Sequence):
def __init__(self, images_array, labels, batch_size=BATCH_SIZE, augmentor=None, shuffle=False, pre_func=None):
'''
파라미터 설명
images_array: 원본 32x32 만큼의 image 배열값.
labels: 해당 image의 label들
batch_size: __getitem__(self, index) 호출 시 마다 가져올 데이터 batch 건수
augmentor: albumentations 객체
shuffle: 학습 데이터의 경우 epoch 종료시마다 데이터를 섞을지 여부
'''
# 객체 생성 인자로 들어온 값을 객체 내부 변수로 할당.
# 인자로 입력되는 images_array는 전체 32x32 image array임.
self.images_array = images_array
self.labels = labels
self.batch_size = batch_size
self.augmentor = augmentor
self.pre_func = pre_func
# train data의 경우
self.shuffle = shuffle
if self.shuffle:
# 객체 생성시에 한번 데이터를 섞음.
#self.on_epoch_end()
pass
# Sequence를 상속받은 Dataset은 batch_size 단위로 입력된 데이터를 처리함.
# __len__()은 전체 데이터 건수가 주어졌을 때 batch_size단위로 몇번 데이터를 반환하는지 나타남
def __len__(self):
# batch_size단위로 데이터를 몇번 가져와야하는지 계산하기 위해 전체 데이터 건수를 batch_size로 나누되, 정수로 정확히 나눠지지 않을 경우 1회를 더한다.
return int(np.ceil(len(self.labels) / self.batch_size))
# batch_size 단위로 image_array, label_array 데이터를 가져와서 변환한 뒤 다시 반환함
# 인자로 몇번째 batch 인지를 나타내는 index를 입력하면 해당 순서에 해당하는 batch_size 만큼의 데이타를 가공하여 반환
# batch_size 갯수만큼 변환된 image_array와 label_array 반환.
def __getitem__(self, index):
# index는 몇번째 batch인지를 나타냄.
# batch_size만큼 순차적으로 데이터를 가져오려면 array에서 index*self.batch_size:(index+1)*self.batch_size 만큼의 연속 데이터를 가져오면 됨
# 32x32 image array를 self.batch_size만큼 가져옴.
images_fetch = self.images_array[index*self.batch_size:(index+1)*self.batch_size]
if self.labels is not None:
label_batch = self.labels[index*self.batch_size:(index+1)*self.batch_size]
# 만일 객체 생성 인자로 albumentation으로 만든 augmentor가 주어진다면 아래와 같이 augmentor를 이용하여 image 변환
# albumentations은 개별 image만 변환할 수 있으므로 batch_size만큼 할당된 image_name_batch를 한 건씩 iteration하면서 변환 수행.
# 변환된 image 배열값을 담을 image_batch 선언. image_batch 배열은 float32 로 설정.
image_batch = np.zeros((images_fetch.shape[0], IMAGE_SIZE, IMAGE_SIZE, 3), dtype='float32')
# batch_size에 담긴 건수만큼 iteration 하면서 opencv image load -> image augmentation 변환(augmentor가 not None일 경우)-> image_batch에 담음.
for image_index in range(images_fetch.shape[0]):
#image = cv2.cvtColor(cv2.imread(image_name_batch[image_index]), cv2.COLOR_BGR2RGB)
# 원본 image를 IMAGE_SIZE x IMAGE_SIZE 크기로 변환
image = cv2.resize(images_fetch[image_index], (IMAGE_SIZE, IMAGE_SIZE))
# 만약 augmentor가 주어졌다면 이를 적용.
if self.augmentor is not None:
image = self.augmentor(image=image)['image']
# 만약 scaling 함수가 입력되었다면 이를 적용하여 scaling 수행.
if self.pre_func is not None:
image = self.pre_func(image)
# image_batch에 순차적으로 변환된 image를 담음.
image_batch[image_index] = image
return image_batch, label_batch
# epoch가 한번 수행이 완료 될 때마다 모델의 fit()에서 호출됨.
def on_epoch_end(self):
if(self.shuffle):
#print('epoch end')
# 원본 image배열과 label를 쌍을 맞춰서 섞어준다. scikt learn의 utils.shuffle에서 해당 기능 제공
self.images_array, self.labels = sklearn.utils.shuffle(self.images_array, self.labels)
else:
pass
def zero_one_scaler(image):
return image/255.0
train_ds = CIFAR_Dataset(train_images, train_labels, batch_size=BATCH_SIZE, augmentor=None, shuffle=True, pre_func=zero_one_scaler)
val_ds = CIFAR_Dataset(val_images, val_labels, batch_size=BATCH_SIZE, augmentor=None, shuffle=False, pre_func=zero_one_scaler)from tensorflow.keras.layers import *
class VGG(tf.keras.Model):
def __init__(self, num_classes=NUM_CLASSES):
super().__init__()
self.regularizer = tf.keras.regularizers.l2(l2=0.0005)
self.net = tf.keras.Sequential([
Conv2D(
filters=64,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
Conv2D(
filters=64,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
MaxPool2D(pool_size=2, strides=2),
Conv2D(
filters=128,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
Conv2D(
filters=128,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
MaxPool2D(pool_size=2, strides=2),
Conv2D(
filters=256,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
Conv2D(
filters=256,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
Conv2D(
filters=256,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
MaxPool2D(pool_size=2, strides=2),
Conv2D(
filters=512,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
Conv2D(
filters=512,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
Conv2D(
filters=512,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
MaxPool2D(pool_size=2, strides=2),
Conv2D(
filters=512,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
Conv2D(
filters=512,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
Conv2D(
filters=512,
kernel_size=3,
padding='same',
kernel_regularizer=self.regularizer
),
ReLU(),
MaxPool2D(pool_size=2, strides=2),
Reshape((-1, 512 * 7 * 7)),
Dropout(0.5),
Dense(4096),
ReLU(),
Dropout(0.5),
Dense(4096),
ReLU(),
Dense(num_classes, activation='softmax'),
])
def call(self, inputs):
return tf.reshape(self.net(inputs), (-1, 10))from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping
rlr_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.001, patience=5, mode='min', verbose=1)
ely_cb = EarlyStopping(monitor='val_loss', patience=15, mode='min', verbose=1)
tb_path = './tensorboard'
tensorboard_cb = tf.keras.callbacks.TensorBoard(log_dir=tb_path)
vgg = VGG(num_classes=NUM_CLASSES)vgg.compile(
optimizer=tf.keras.optimizers.SGD(0.001, momentum=0.9),
# optimizer=tf.keras.optimizers.Adam(0.00001),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'],
run_eagerly=True
)
vgg.fit(train_ds, verbose=1, validation_data=val_ds, epochs=NUM_EPOCHS, callbacks=[tensorboard_cb, rlr_cb, ely_cb])
test_ds = CIFAR_Dataset(test_images, test_labels, batch_size=BATCH_SIZE, augmentor=None, shuffle=False, pre_func=zero_one_scaler)
vgg.evaluate(test_ds)결과
- 더이상 validation loss가 줄지 않을 때까지 돌려 85 epoch 동안 진행했다. 약 38시간이 소요됐다.
주황색이 train accuracy, 파란색이 validation accuracy이다.
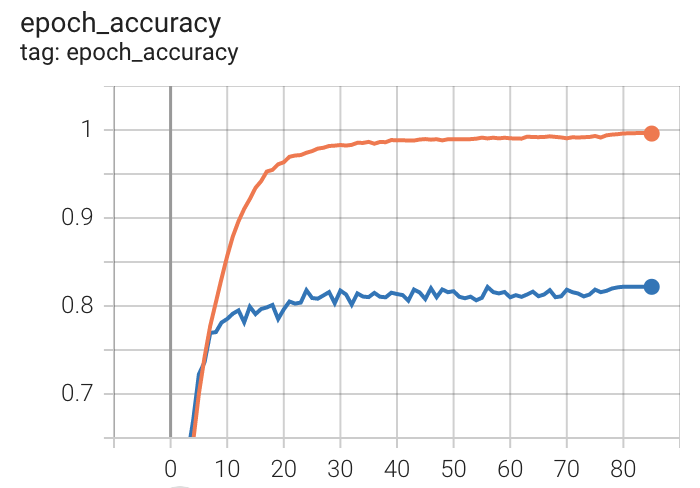
- Train loss는 0.1862, train accuracy는 0.9959, validation loss는 0.8730, validation accuracy는 0.8218이었다.
- 이후 test dataset에 대해 평가한 결과 loss는 0.8699, accuracy는 0.8162였다.
- Alexnet과 비교했을 때, 훈련 종료 시까지의 시간은 약 4배로 오래 걸렸다. 하지만 alexnet의 최대 validation accuracy였던 0.78을 넘는 데에는 약 10 epoch, 5시간밖에 걸리지 않았고, 최대 0.82의 validation accuracy를 찍으며 더 우월한 지표를 기록했다.
- Adam optimizer를 사용해보았는데, 이번에는 왜인지 성능이 더 안 나왔다. 훈련이 더 빨리 끝났고, loss는 1.4937, accuracy는 0.7650이었다.
요약 및 논의
- AlexNet보다 훨씬 더 깊은 vgg16을 돌려보았고 더 좋은 결과를 얻을 수 있었다.
- 초기화는 따로 설정하지 않았다. Tensorflow에서는 디폴트 초기화로 glorot 방식을 쓴다고 한다. 논문의 말이 맞다면 이것으로 충분하다. 기회가 되면 A 구조부터 가중치를 전이하는 방식도 시도해보고 싶다.
참고자료
https://daechu.tistory.com/10
https://stackoverflow.com/questions/43953531/do-i-need-to-subtract-rgb-mean-value-of-imagenet-when-finetune-resnet-and-incept (전처리)
https://bskyvision.com/504

머신러닝 던전