아파치 스파크
1.아파치 스파크(Apache Spark)란
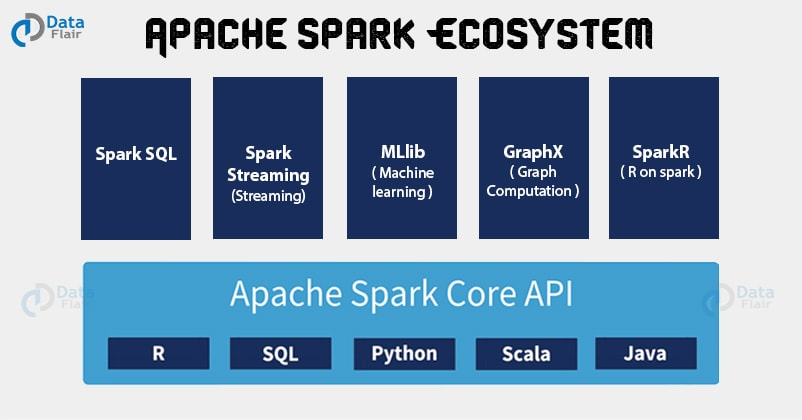
아파치 스파크는 통합 컴퓨팅 엔진이며 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합입니다. 스파크는 가장 활발하게 개발되고 있는 병렬 처리 오픈소스 엔진이며 빅데이터에 관심 있는 여러 개발자와 데이터 사이언티스트에게 표준 도구가 되어가고 있습니다. 스파크
2021년 11월 9일
2.아파치 스파크(Apache Spark)의 기본 배경지식
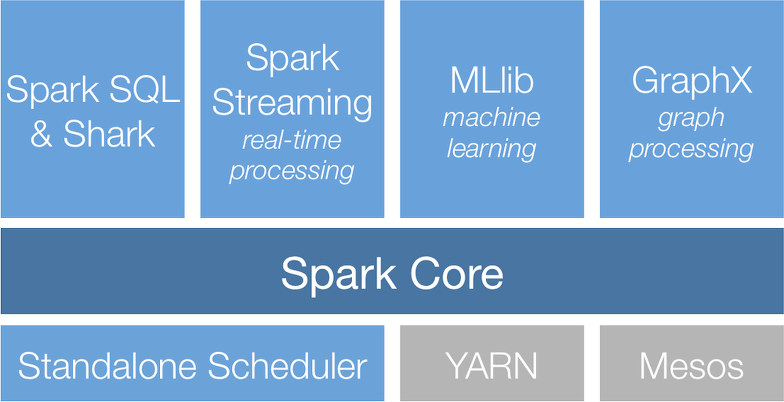
이번에는 아파치 스파크의 DataFrame, SQL을 사용해 클러스터, 스파크 애플리케이션 그리고 구조적 API를 살펴봅시다. 보통 컴퓨터로는 대규모 정보를 연산할 만한 자원이나 성능을 가지지 못합니다. 연산을 할 수 있다고 해도 완료하는 데 너무 많은 시간이 걸릴 수
2021년 11월 9일
3. 아파치 스파크(Apache Spark)의 기능 둘러보기

스파크의 라이브러리는 그래프 분석, 머신러닝 그리고 스트리밍 등 다양한 작업을 지원하며, 컴퓨팅 및 스토리지 시스템과의 통합을 돕는 역할을 합니다. 이번 포스팅을 통해 아직 다루지 않은 API와 주요 라이브러리 그리고 스파크가 제공하는 다양한 기능을 소개합니다.spar
2021년 12월 31일
4.[Apache Spark] 아파치 스파크의 메모리 관리에 대해서
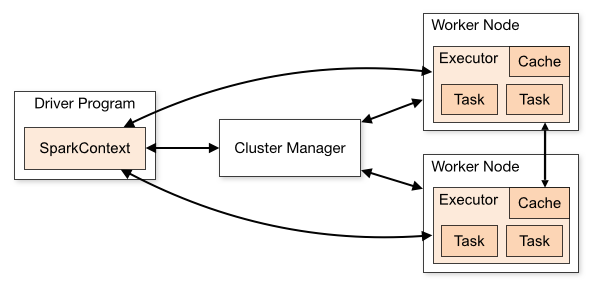
Spark를 사용하다보면 메모리 관련해서 문제가 발생되는 경우가 많습니다. 최근 연구하는데 있어서 Apach Spark의 Structured Streaming(https://spark.apache.org/docs/latest/structured-streamin
2022년 1월 24일