아파치 스파크는 통합 컴퓨팅 엔진이며 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합입니다. 스파크는 가장 활발하게 개발되고 있는 병렬 처리 오픈소스 엔진이며 빅데이터에 관심 있는 여러 개발자와 데이터 사이언티스트에게 표준 도구가 되어가고 있습니다. 스파크는 널리 쓰이는 파이썬, 자바, 스칼라, R를 지원하며 SQL뿐만 아니라 스트리밍, 머신러닝에 이르기까지 넓은 범위의 라이브러리를 제공합니다. 스파크는 단일 노트북 환경부터 수천 대의 서버로 구성된 클러스터까지 다양한 환경에서 실행할 수 있습니다. 이런 특성을 활용해 빅데이터 처리를 쉽게 시작할 수 있고 엄청난 규모의 클러스터로 확장해나갈 수 있습니다.
1. 아파치 스파크의 핵심요소
1.1 통합
스파크는 빅데이터 애플리케이션 개발에 필요한 통합 플랫폼을 제공하자는 핵심 목표를 가지고 있습니다. 통합이라는 단어는 스파크의 핵심 목표와 일치합니다. 스파크는 간단한 데이터 읽기에서부터 SQL 처리, 머신러닝 그리고 스트림 처리에 이르기까지 다양한 데이터 분석 작업을 같은 연산 엔진과 일관성 있는 API로 수행할 수 있도록 설계되어 있습니다. 스파크의 이러한 개발 사상은 현실 세계의 데이터 분석이 다양한 처리 유형과 라이브러리를 결합해 수행된다는 통찰에서 비롯되었습니다.
스파크의 통합 특성을 이용하면 기존의 데이터 분석 작업을 더 쉽고 효율적으로 수행할 수 있습니다. 먼저 스파크에서는 일관성 있는 조합형 API를 제공하므로 작은 코드 조각이나 기존 라이브러리를 사용해 애플리케이션을 만들 수 있습니다. 조합형 API만으로 문제를 해결할 수 없을 때는 직접 스파크 기반의 라이브러를 만들 수도 있습니다. 스파크의 API는 사용자 애플리케이션에서 다른 라이브러리의 기능을 조합해 더 나은 성능을 발휘할 수 있도록 설계되었습니다. 예를 들어 SQL 쿼리로 데이터를 읽고 ML 라이브러리로 머신러닝 모델을 평가해야 할 경우 스파크 엔진은 이 두 단계를 하나로 병합하고 데이터를 한 번만 조회할 수 있게 해 줍니다.
스파크는 소프트웨어 영역의 여러 통합 플랫폼과 유사한 사용 방식을 제공합니다. 기존 통합 프레임워크를 사용하는 데이터 사이언티스트는 데이터 모델링에 파이썬이나 R에서 제공하는 다양한 통합 라이브러리를, 웹 개발자는 Node.js나 Django 같은 통합 프레임워크가 제공하는 기능을 활용합니다. 스파크가 발표되기 전에는 통합 엔진을 제공하는 병렬 데이터 처리용 오픈소스가 없었습니다. 따라서 사용자는 다양한 API와 시스템을 직접 조합해서 애플리케이션을 작성해야 했습니다. 스파크는 통합 엔진을 제공하면서 빠르게 빅데이터 분석 업무의 표준이 되었습니다. 시간이 지나면서 스파크는 더 많은 처리 유형을 지원하기 위해 자체 API를 확장해나가고 있으며 스파크 프로젝트 개발자들은 통합 엔진을 더욱 정교하게 다듬고 있습니다.
1.2 컴퓨팅 엔진
스파크는 통합이라는 관점을 중시하면서 기능의 범위를 컴퓨팅 엔진으로 제한해왔습니다. 그 결과 스파크는 저장소 시스템의 데이터를 연산하는 역할만 수행할 뿐 영구 저장소 역할은 수행하지 않았습니다. 그 대신 클라우드 기반의 Azure Storage, Amazon S3, Apache Hadoop(분산 파일 시스템), Apache Cassandra(키-벨류 저장소), Apache Kafka(메시지 전달 시스템)등의 저장소를 지원합니다. 스파크는 내부에 데이터를 오랜 시간 저장하지 않으며 특정 저장소 시스템을 선호하지도 않습니다. 연구 결과 대부분의 데이터는 여러 자종소 시스템에 혼재되어 저장되고 있기 때문입니다. 데이터 이동은 높은 비용을 유발합니다. 따라서 스파크는 데이터 저장 위치에 상관없이 처리에 집중하도록 만들어졌습니다. 또한 사용자 API는 서로 다른 저장소 시스템을 매우 유사하게 볼 수 있도록 만들어졌습니다. 따라서 애플리케이션은 데이터가 저장된 위치를 신경 쓰지 않아도 됩니다.
스파크는 연산 기능에 초점을 맞추면서 아파치 하둡과 같은 기존 빅데이터 플랫폼과 차별화하고 있습니다. 하둡은 범용 서버 클러스터 환경에서 저비용 저장 장치를 사용하도록 설계된 하둡 파일 시스템과 컴퓨팅 시스템(MapReduce)을 가지고 있으며 두 시스템은 매우 밀접하게 연관되어 있습니다. 하둡과 같은 구조에서는 둘 중 하나의 시스템만 단독으로 사용하기 어렵습니다. 특히 다른 저장소의 데이터에 접근하는 애플리케이션을 개발하기 어렵습니다. 스파크는 하둡 저장소와 잘 호환됩니다. 그리고 연산 노드와 저장소를 별도로 구매할 수 있는 공개형 클라우드 환경이나 스트리밍 애플리케이션이 필요한 환경 등 하둡 아키택처를 사용할 수 없는 환경에서도 많이 사용됩니다.
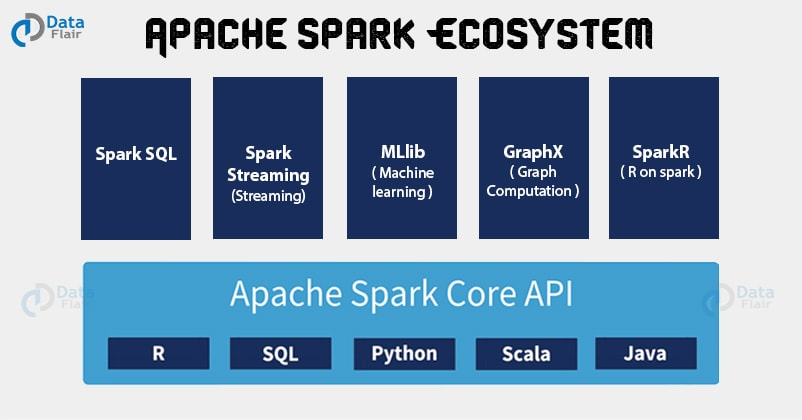
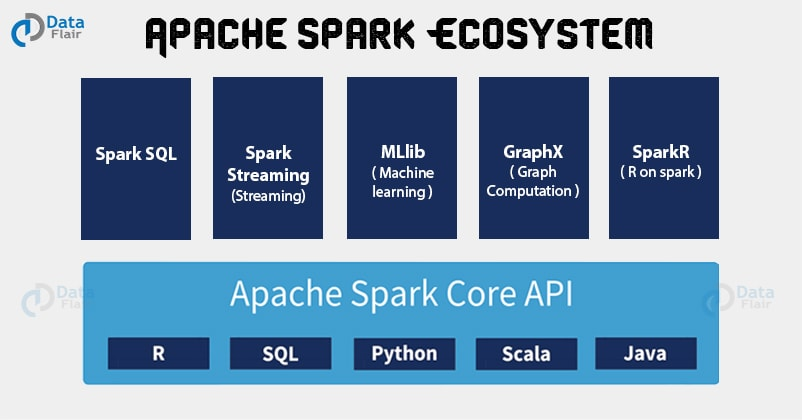
1.3 라이브러리
궁극의 스파크 컴포넌트는 데이터 분석 작업에 필요한 통합 API를 제공하는 통합 엔진 기반의 자체 라이브러리입니다. 스파크는 엔진에서 제공하는 표준 라이브러리와 오픈소스 커뮤니티에서 서드파티 패키지 형태로 제공하는 다양한 외부 라이브러리를 지원합니다. 사실 스파크의 표준 라이브러리는 여러 오픈소스 프로젝트의 집합체입니다. 스파크 코어 엔진 자체는 최초 공개 후 큰 변화가 없었지만 라이브러리의 경우 더 많은 기능을 제공하기 위해 꾸준히 변해왔습니다. 스파크 SQL과 구조화된 데이터를 제공하는 스파크 SQL, 머신러닝을 지원하는 MLlib, 스트림 처리 기능을 제공하는 스파크 스트리밍과 새롭게 선보인 구조적 스트리밍(Structured Stream) 그리고 그래프 분석 엔진인 GraphX 라이브러리를 제공합니다. 기존 라이브러리 외에 다양한 저장소 시스템을 위한 Cnnector부터 머신 러닝을 위한 알고리즘까지 수백 개의 외부 오픈소스 라이브러리도 존재합니다. 외부 라이브러리 목록은 https://spark-packages.org/ 에서 확인할 수 있습니다.

2. 스파크의 등장 배경
데이터 분석에 새로운 처리 엔진과 프로그래밍 모델이 필요한 근본적인 이유는 컴퓨터 애플리케이션과 하드웨어의 바탕을 이루는경제적 요인 변화 때문입니다. 역사적으로 컴퓨터는 프로세서의 성능 향상에 힘입어 빠르게 성장했습니다. 그 결과 애플리케이션은 코드를 수정하지 않아도 자연스럽게 빨라졌습니다. 대규모 애플리케이션은 이런 경향에 맞춰 만들어졌으며 대부분의 시스템은 단일 프로세서에서만 실행되도록 설계되었습니다. 하지만 안타깝게도 하드웨어 성능 향상은 여러 이유로 멈춰졌습니다. 이런 현상은 애플리케이션의 성능 향상을 위해 병렬 처리가 필요하며 스파크와 같은 새로운 프로그래밍 모델의 세상이 유망해질 것임을 암시했습니다.
이런 병렬처리로 인해서 데이더 저장과 수집 기술은 눈에 띄게 느려지지 않았습니다. 데이터를 저장하는데 드는 비용은 14개월마다 절반으로 줄어들고 있고 데이터 수집하는 비용은 계속해서 저렴해지고 정밀도는 개선되고 있습니다. 결과적으로 데이터 수집 비용은 극히 저렴해졌지만, 데이터는 클러스터에서 처리해야 할 만큼 거대해졌습니다. 게다가 지난 50년간 개발된 소프트웨어는 더는 자동으로 성능이 향상되지 않았고 데이터 처리 애플리케이션에 적용한 전통적인 프로그래밍 모델도 더는 힘을 발휘하지 못했습니다. 따라서 새로운 프로그래밍 모델이 필요해졌으며 이런 문제를 해결하기 위해 아파치 스파크가 탄생했습니다.

3. 스파크의 역사
아파치 스파크는 UC버클리 대학교에서 2009년 스파크 연구 프로젝트로 시작되었습니다. 다음해에 UC 버클리 대학교 AMPLab 소식인 마테이 자라이아, 모샤라프 카우두리, 마이클 플랭클린, 스콧 쉔커, 이온 스토이카가 발표한 논문 "Spark: Cluster Computing with Working Sets"를 통해 처음 세상에 알려졌습니다. 당시 하둡 맵리듀스는 수천 개의 노드로 구성된 클러스터에서 병렬로 데이터를 처리하는 최초의 오픈소스 시스템이자 클러스터 환경용 병렬 프로그래밍 엔진의 대표주자였습니다. AMPLap은 새로운 프로그래밍 모델의 장단점을 이해하기 위해 맵리듀스 사용자들과 함께 일했습니다. 그리고 여러 가지 사용 사례에서 발견한 문제점들을 정리해 더 범용적인 컴퓨팅 플랫폼을 설계했습니다.
연구 결과로 두가지 사실이 명확해졌습니다. 첫 번째는 클러스터 컴퓨팅이 엄청난 잠재력을 가지고 있다는 것입니다. 맵리듀스 경험이 있는 조직은 자체 데이터를 활용해 기존과는 다른 애플리케이션을 만들어냈습니다. 하지만 이런 경험이 없는 조직은 누군가가 성공하고 난 후에야 활용할 수 있었습니다. 두 번째는 맵리듀스 엔진을 사용하는 대규모 애플리케이션의 난이도와 효율성 문제였습니다. 예를 들어 전통적인 머신러닝 알고리즘은 데이터를 10~20회가량 처리합니다. 하지만 이를 맵리듀스로 처리하려면 단계별로 맵리듀스 잡을 개발하고 클러스터에서 각각 실행해야 하므로 매번 데이터를 처음부터 읽어야 했습니다.
스파크 팀은 이런 문제를 해결하기 위해 먼저 여러 단계로 이루어진 애플리케이션을 간결하게 개발할 수 있는 함수형 프로그래밍 기반의 API를 설계했습니다. 그리고 연산 단계 사이에서 메모리에 저장된 데이터를 효율적으로 공유할 수 있는 새로운 엔진 기반의 API를 구현했습니다. 이어서 스파크 팀은 UC버클리 대학교와 외부 사용자를 대상으로 시스템에 대한 실험을 시작했습니다.
스파크의 첫번째 버전은 배치 애플리케이션만 지원했습니다. 하지만 얼마 지나지 않아 대화형 데이터 분석이나 비정형 쿼리 같은 강력한 기능을 제공하기 시작했습니다. 스칼라 인터프리터를 단순히 스파크에 접목하는 방식으로 수백 개의 노드에서 쿼리를 실행할 수 있는 매우 유용한 대화형 시스템을 제공할 수 있었습니다. 이 아이디어를 기반으로 분석가나 데이터 사이언티스트들이 스파크에서 대화형 SQL을 실행할 수 있는 엔진인 Shark를 빠르게 개발했습니다.
스파크 팀은 최초 공개 후 새로운 라이브러리가 스파크의 가장 강력한 부가 기능이 될 수 있다는 확신을 하게 되었습니다. 따라서 현재도 표준 라이브러리 형태의 구현 방식을 유지하고 있습니다. 이후 AMPLab의 여러 그룹이 MLlib, 스파크 스트리밍 그리고 GraphX를 만들기 시작했습니다. 이들이 만들어낸 API의 뛰어난 호환성 덕분에 처음으로 같은 엔진을 이용해 여러 처리 유형을 결합한 빅데이터 애플리케이션을 개발할 수 있었습니다.
4. 스파크의 현재와 미래
수년 전에 공개된 스파크는 꾸준한 인기를 얻고 있으며 활용 사례가 늘어나고 있습니다. 그리고 스파크 생태계의 여러 신규 프로젝트는 스파크의 영역을 꾸준히 넓혀나가고 있습니다. 2016년에는 고수준 스트리밍 엔진인 Structured Stream을 소개했습니다. 이 기술은 우버나 넷플릭스 같은 기술 회사뿐만 아니라 NASA, CREN 같은 연구소에서 거대한 규모의 데이터셋을 처리하기 위해 사용합니다.
스파크가 여전히 빠르게 성장하고 있다는 점을 고려하면 빅데이터 분석을 수행하는 기업의 핵심 기술이 도리 것이라 예상할 수 있습니다. 빅데이터 문제를 해결하려는 데이터 사이언티스트나 엔지니어는 스파크를 가까이해야 할 것입니다.
REFERENCE
해당 포스팅의 레퍼런스는 "스파크 완벽 가이드" 저자 빌 체임버스, 마테이 자하리아 입니다.
https://coupa.ng/cadQGH
