
이전 포스팅을 통해서 카프카의 동작 방식과 원리를 알아보았습니다. 기존 Pub/Sub 모델과도 다른 메시징 시스템을 구성하고 있는데 자세히 살펴보도록 하겠습니다.
💎 기존 메시징 시스템과 차별화된 카프카

카프카는 기존의 메시징 시스템과는 차별화되는 특징이 있습니다.
크게 5개 정도로 정리 할 수 있습니다.
- 프로듀서와 컨슈머의 분리
- 멀티 프로듀서, 멀티 컨슈머
- 디시크에 메시지 저장
- 확장성
- 높은 성능
이제 크게 5개 정도로 정리된 차별화된 특징을 자세히 알아 보겠습니다.
1. 프로듀서와 컨슈머의 분리 💎
기존의 메시징 시스템들은 Pub/Sub 모델이 아닌 데이터를 전송하는 노드와 데이터를 사용하는 노드를 직접 연결하는 방식을 이용했습니다. 이 경우 데이터를 사용하는 노드에서 문제가 생기는 경우 데이터 전송하는 노드에서 대기를 하던가, 지연이 된다던가 이런 문제가 생기게 됩니다. 또한 여기서 데이터를 사용해야하는 노드가 추가로 생기게 된다면 이것을 연결해주는 방식은 매우 복잡하며, 추가적인 작업도 매우 늘어납니다. 아래는 직접 연결하는 방식입니다.
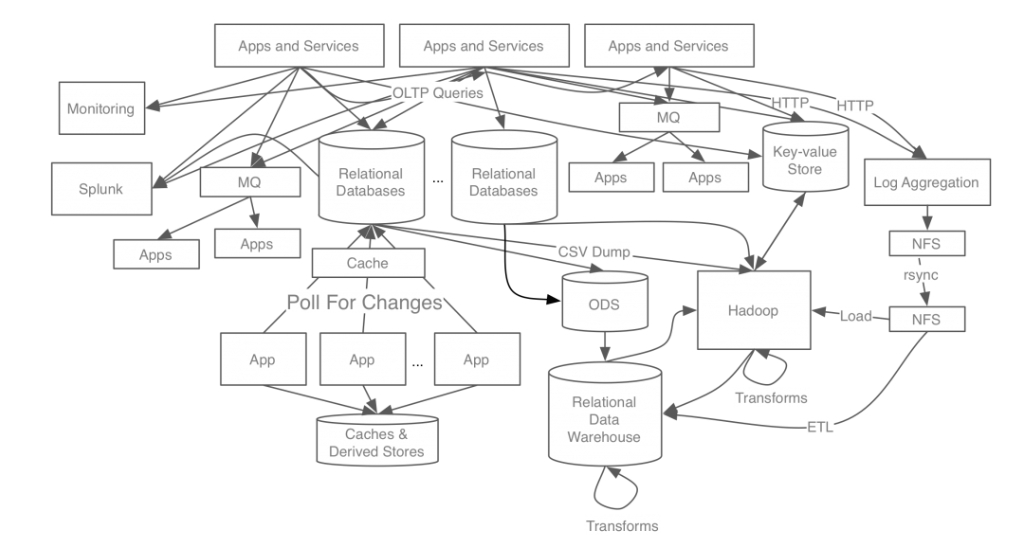
그래서 카프카는 Pub/Sub 모델을 기본으로 메시징 시스템을 데이터를 전송하고 받는 중간에 있어서 이를 관리해줍니다. 이를 단적으로 보여주는 사진은 아래와 같습니다. 한눈에 보기에도 구조가 매우 단순해졌으며, 각각 서비스 서버들은 카프카로 메시지를 보내는 역할만 하면 되고, 서비스 서버들은 카프카에 저장되어 있는 메시지를 가져오면 됩니다. 이렇게 프로듀서와 컨슈머로 완벽하게 분리되면서, 한쪽 시스템에서 문제가 발생하더라도 연쇄 작용이 발생할 확률은 낮아지게 됩니다. 또한 여기서 추가적인 서비스가 있더라도 카프카에 연결해서 데이터를 보내던 가져오던 하는 방식으로 추가하는데 있어서 부담을 매우 줄일 수 있습니다.
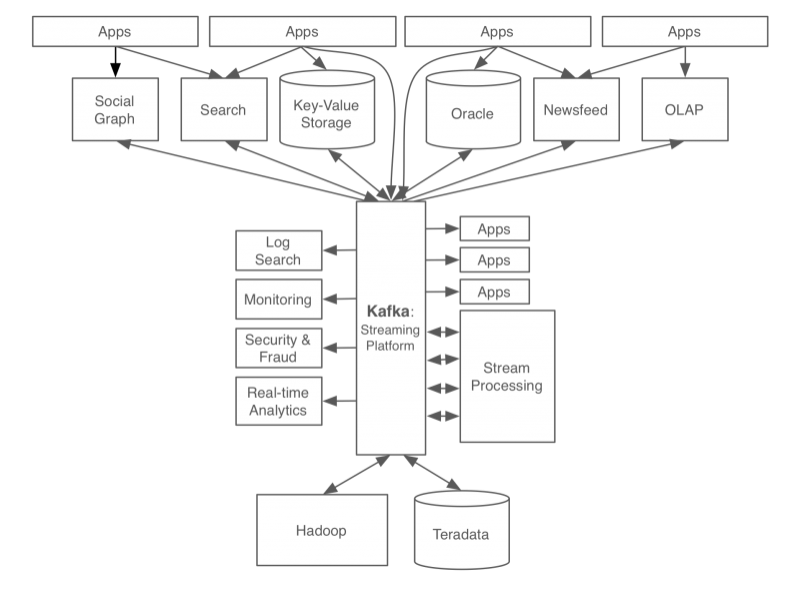
2. 멀티 프로듀서, 멀티 컨슈머 💎
이전 특징에서 말씀드린 메시지라는 데이터를 카프카에 보내고, 가져오는 프로듀서와 컨슈머를 분리함으로써 확장에 용이한 시스템으로 설명드렸습니다. 여기서 중앙에 있는 카프카의 메시징 시스템에서는 토픽(Topic)이라는게 존재합니다. 토픽에 여러 프로듀서 또는 컨슈머들이 접근 가능한 구조로 되어 있습니다. 만약 하나의 토픽에 하나의 프로듀서와 컨슈머만 접근 가능하도록 했으면, 이는 직접 연결 하는 방식과 크게 다를리가 없습니다. 그래서 카프카는 토픽이라는 곳에 프로듀서가 보내고 컨슈머들은 토픽을 Subscrible 하는 방식으로 여러개를 연결 해서 가져 올 수 있도록합니다. 이렇게 하면 이제 카프카는 중앙 집중형 구조로 구성 할 수 있게 됩니다.
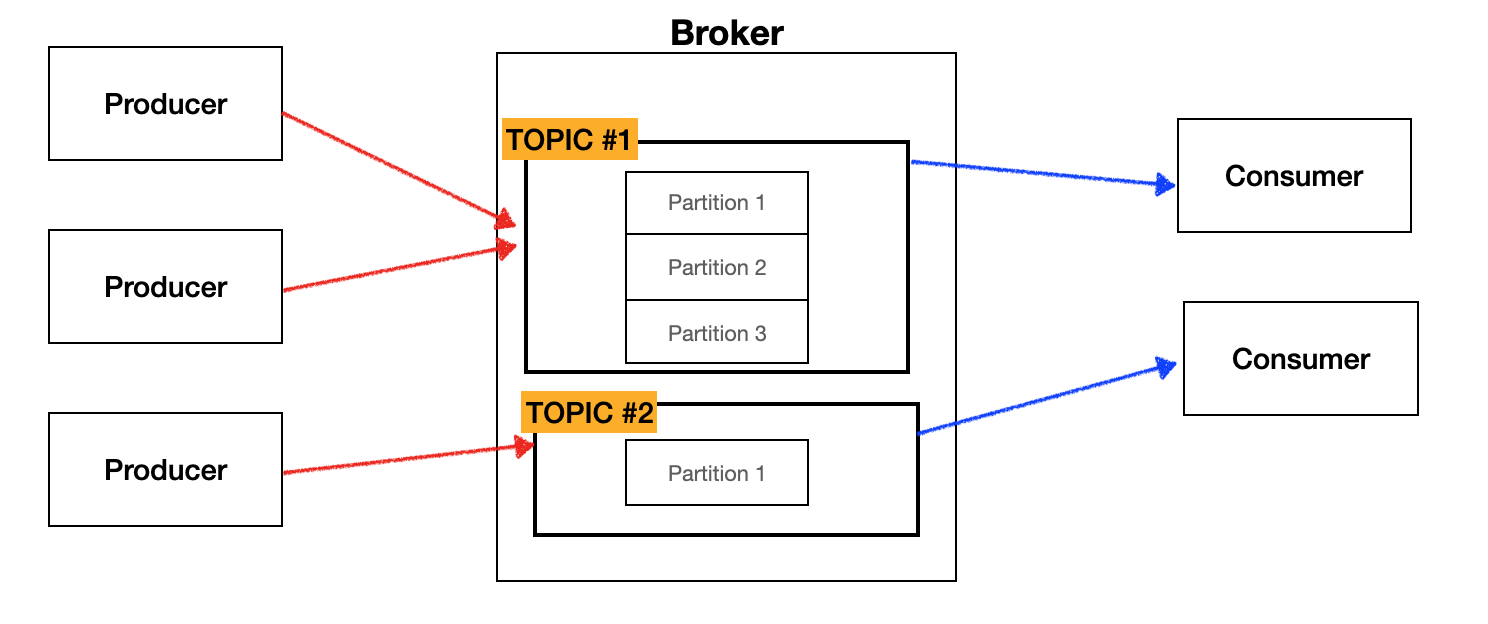
3. 디스크에 메시지 저장 💎

기존의 메시징 시스템과 가장 다른 특징 중 하나는 바로 디스크에 메시지를 저장하고 유지하는 것입니다. 일반적인 메시지 시스템들은 컨슈머가 메시지를 읽어가면 큐에서 바로 메시지를 삭제합니다. 하지만 카프카는 컨슈머가 메시지를 읽어가더라도 정해져 있는 보관 주기 동안 디스크에 메시지를 저장합니다. 이렇게 되면 컨슈머의 처리가 늦어지더라도 카프카의 디스크에 안전하게 보관되어 있기 때문에, 컨슈머는 메시지 손실 없이 메시지를 가져갈 수 있어 메시지 손실 없이 작업이 가능합니다.
4. 확장성 💎

카프카는 앞서 설명드린것 처럼 카프카는 확장이 매우 용이하게 설계되어 있습니다. 하나의 카프카 클러스터는 3대의 브로커로 시작해 수십대의 브로커로 확장 가능합니다. 이처럼 확장 작업은 카프카 서비스의 중단 없이 온라인 상태에서 작업이 가능합니다.
5. 높은 성능 💎

카프카는 Pub/Sub 모델에서 단점으로 언급되어지는 중간에 카프카라는 메시징 시스템에 보내고 컨슈머들이 받는다는 구조적 단점으로 속도가 느리다는 점과, 직접 연결해서 전달하는 과정이 아니다보니 컨슈머가 제대로 데이터를 전달 받았는지 확인하는 방법이 어렵다는 점입니다. 그래서 카프카는 내부적으로 분산처리, 배치 처리 등 다양한 기법을 사용하여 대규모, 고성능을 유지하는 메시징 시스템이 가능하도록 합니다.
카프카의 용어 정리
- 카프카 (Kafka) : 애플리케이션 이름입니다. 클러스터 구성이 가능하며, 카프카 클러스터라고 부릅니다.
- 브로커 (Broker) : 카프커 애플리케이션이 설치되어 있는 서버 또는 노드를 말합니다.
- 토픽 (Topic) : 프로듀서와 컨슈머들이 카프카로 보낸 메시지를 구분하기 위한 네임으로 사용합니다.
- 파티션 (Partition) : 병렬처리가 가능하도록 토픽을 나눌 수 있고, 많은 양의 메시지 처리를 위한 파티션의 수를 늘려 줄 수 있습니다.
- 프로듀서 (Producer) : 메시지를 생산하여 브로커의 토픽 이름으로 보내는 서버 또는 애플리케이션 등을 말합니다.
- 컨슈머 (Consumer) : 브로커의 토픽 이름으로 저장된 메시지를 가져가는 서버 또는 애플리케이션 등을 말합니다.
REFERENCE
해당 글의 모든 레퍼런스는 "카프카, 데이터 플랫폼의 최강자" (고승범, 공용준 지음) 을 알립니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
