
카프카는 분산된 데이터 파이프라인을 표준화하고 통합하길 원했고, 처리량에 중점을 두고 설계되었습니다. 이에 따라서 카프카는 높은 처리량과 빠른 메시지 전송, 운영 효율화 등을 위해 분산 시스템, 페이지 캐시, 배치 전송 처리 등의 기능이 구현되었습니다.
카프카 디자인의 특징
이제 카프카는 어떻게 성능을 높였는지 카프카 디자인의 특징을 알아 보겠습니다.
1. 분산 시스템
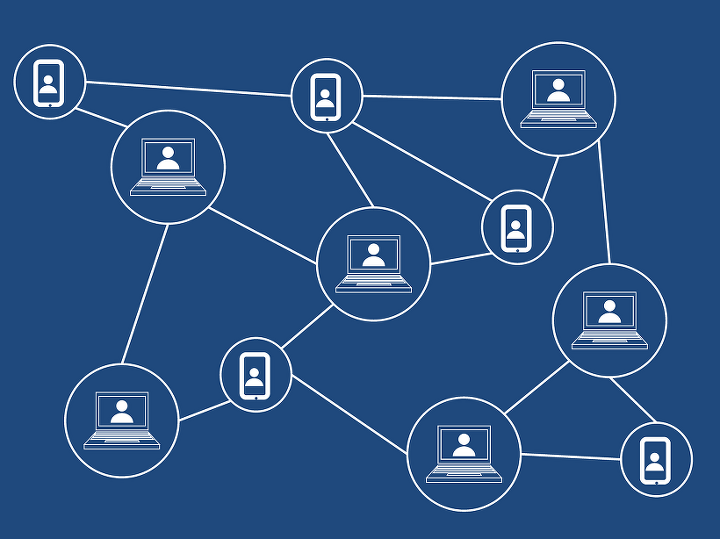
분산 시스템은 같은 역할을 하는 여러 대의 서버로 이뤄진 서버 그룹을 분산 시스템이라고 합니다.
이런 분산 시스템의 장점은 단일 시스템보다 높은 성능을 얻을 수 있다는 점과 하나의 서버 또는 노드 등이 장애가 발생하면 다른 서버 또는 노드가 대신 처리할 수 있으며 시스템 확장이 용이하다는 점입니다. 하지만 불필요하게 서버만 계속 추가하면 불필요한 비용이 증가하는 단점도 있습니다. 무조건 서버를 늘려 부하를 분산하기보다는 장애 상황과 서버의 리소스 사용량 등을 고려해 적절한 수로 유지하는 것이 좋습니다.
카프카도 분산 시스템이기 대문에 유동적으로 서버를 늘릴 수 있습니다.
2. 페이지 캐시

일단 OS와 페이지 캐시가 어떤 관련이 있는지부터 알아야 합니다.
OS는 물리적 메모리에 애플리케이션이 사용하는 부분을 할당하고 남은 잔여 메모리 일부를 페이지 캐시로 유지해 OS의 전체적인 성능을 향상하게 됩니다. 이렇게 잔여 메모리를 사용해 디스크에 읽고 쓰기를 하지 않고 페이지 캐시를 통해 읽고 쓰는 방식을 이용하면 처리 속도가 매우 빠르기 때문에 성능을 향상할 수 있습니다. 카프카는 이러한 특징을 이용하고자 OS의 페이지 캐시를 이용하도록 디자인되었습니다.
또한 페이지 캐시를 사용한다는 점 때문에 카프카를 구성할 때는 디스크 중에서 가격이 저렴한 디스크를 사용해도 무방합니다. 이는 카프카 공식 문서에도 나오는 내용입니다.
3. 배치 전송 처리
서버와 클라이언트 사이 내부적으로 데이터를 주고받는 과정에서는 I/O가 발생하기 마련입니다. 작은 I/O가 빈번하게 일어나게 되면 속도를 저하시키는 원인이 됩니다. 따라서 카프카는 이런 작은 I/O들을 묶어서 처리할 수 있도록 배치 작업으로 처리합니다. 예를 들어보겠습니다. 서버와 클라이언트 사이에 데이터를 주고받을 때 1초 정도의 딜레이가 있다고 가정하며 4개의 데이터를 한 개씩 보낼 경우 4초의 딜레이가 발생됩니다. 하지만 이를 배치 처리하여 4개를 한 번에 보내는 경우 1초의 딜레이만 발생할 것입니다. 이 처럼 배치 작업은 속도 향상에 매우 큰 도움을 줍니다.
마무리
이번 포스팅을 통해서 카프카는 성능을 높이기 위해서 디자인 설계를 어떤 방식을 통해서 했는지 알아보았습니다. 분산 시스템으로 리소스 부담을 줄여 성능을 높이는 방식과 페이지 캐시라는 읽고 쓰는 것이 빠른 방식을 이용했습니다. 또한 데이터를 전송하는데 하나씩 보내는 방식이 아닌 배치 전송 처리함으로써 네트워크의 오버헤드를 최소화해 전송 속도를 높여 성능을 향상했습니다.
REFERENCE
해당 글의 모든 레퍼런스는 "카프카, 데이터 플랫폼의 최강자" (고승범, 공용준 지음) 을 알립니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
