0. Abstract
데이터센터에서 DRAM은 계륵과도 같은 존재이다. 속도가 빠르지만 가격이 비싸 데이터센터 설립에 필요한 비용 중 많은 부분을 차지하기 때문이다.
대안으로 compressed memory, NVMe SSD, NMV 기반 device들이 존재하여 가격은 낮으면서 용량은 큰 메모리를 제공하지만, DRAM보다는 느리기 때문에 colder memory를 저장하는 용도로 쓰인다. 이때 colder memory를 싼 memory에 저장하는 것을 offloading이라 하고 이것들을 저장하는 memory를 offload dev-
ice라고 한다.
이러한 offloading은 app에게 투명하게 서비스되어야 하는데, 가장 큰 어려움은 데이터센터에는 다양한 workload들이 존재하며 offload device들 간에도 상당한 성능 차이가 존재하기 때문에 kernel에서 이러한 요소들을 고려하는 것이 쉽지 않다는 것이다.
TMO는 이러한 문제점을 최소화하고 다양한 데이터센터 환경에서도 투명한 memory offloading 서비스를 제공해준다.
TMO는 offload device의 성능 특성과 app의 메모리 접근에 대한 민감성을 기준으로 다양한 offload device들에 얼만큼의 memory를 offload할지를 조절한다.
또한 TMO는 ananymous memory와 file cache 모두를 타겟팅한다.
1. Introduction
(나중에)
2. Memory Offloading Opportunities and Challenges in Datacenters
2.1 Memory and SSD Cost Trends
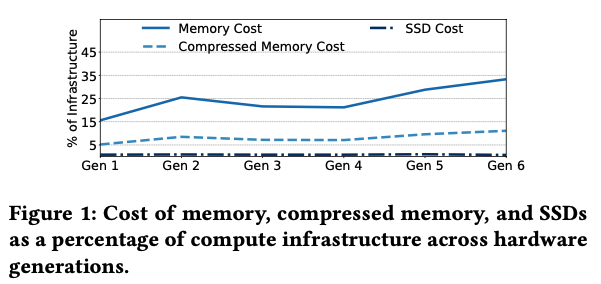
위 그림은 DRAM, compressed memory, SSD 각각이 데이터센터의 서버 비용에서 차지하는 비율을 나타낸 것이다.
DRAM의 겨우 비용의 33%를 차지하며 파워 또한 38%에 달한다고 한다.
compressed memory의 경우 비용을 상당히 줄일 수 있지만, 논문에서는 충분치 않기 때문에 NVMe SSD를 사용하여 비용을 더욱 줄여야 한다고 주장한다.
2.2 Cold Memory as Offloading Opportunity
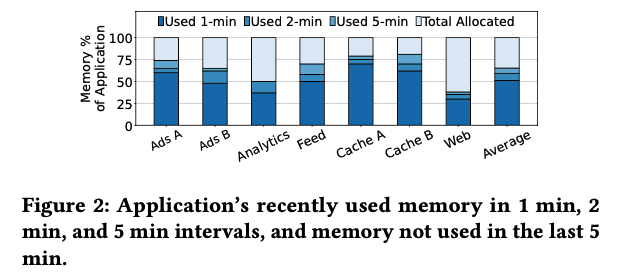
위 그림과 같이 workload 별로 memory coldness의 비율이 굉장히 다른 것을 확인할 수 있다. 때문에 offloading system은 다양한 workload들에 대해서 offloading을 효과적으로 진행할 수 있어야 한다.
2.3 Memory Tax
app의 기능에 영향을 미치는 memory로서 Datacenter Tax와 Microservice Tax가 존재한다.
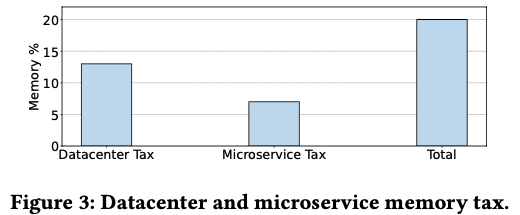
위 그림과 같이 이들 memory가 차지하는 비율이 20%나 되기 때문에 초기 TMO 사용에서는 이들 메모리를 offloading 하는 것에 집중했다고 한다.
2.4 Anonymous and File-Backed Memory
memory는 크게 anonymous memory와 file-backed memory로 구분이 된다. anonymous memory는 app에 의해 할당이 되고 file 혹은 device에 의해서 저장이 되지는 않는다. file-backed memory는 나중에 kernel의 page cache에 저장이 된다.

위 그림과 같이 각 workload들 별로 두 memory의 비율이 큰 차이를 보이는 것을 확인할 수 있다.
2.5 Hardware Heterogeneity of Offload Backend
논문에서 offload backend에 대한 정의를 내렷는데, offloaded memory를 저장하고 있는 slow-memory tier이다. 논문 지필 당시 NVMe SSD와 compressed memory에 대해서만 고려했다.
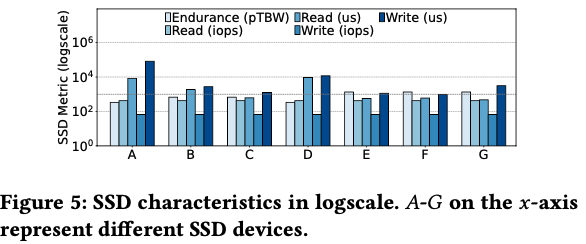
위 그림과 같이 offload backend는 한 가지 종류의 device로만 구성되지 않기 때문에 offloading을 진행할 때 성능이 낮은 backend에 대해서는 offloading을 소극적으로 진행해야하고 높은 backend에 대해서는 적극적으로 진행해야 한다.
ZSWAP
zswap은 TMO 이전에 offloading을 시도한 사례이다. 자세한 내용이 궁금하면 아래 링크에서 논문을 확인하는 것도 좋을 것 같다.
zswap은 compressed memory를 offload backend로 사용하는데, memory를 압축하고 해제하는데 사용되는 CPU의 연산 overhead가 swapping으로 인해 발생하는 IO overhead보다 작을 때 해당 기법이 TMO와 비교해 더 유리해진다.
zswap의 문제점은 아래와 같다.
1) supports only compressed memory pool
NVMe SSD와 같은 더 싼 device를 사용하지 못하고, machine learning 모델과 같은 특정 memory page는 압축이 힘들다.
2) page-promotion rate metric
offload할 memory의 양을 정할 때 page-promotion rate metric을 사용하면 app의 메모리 접근으로 인한 지연을 제대로 반영하지 못하며, 각 offloading device들의 성능 특성을 고려하지 못하게 된다.
3. TMO Design
TMO의 목적은 비용 효율적이면서 느린 다양한 offload backend들에 메모리를 투명하게 offloading하는 것이다.
궁극적으로 TMO는 아래 두 가지 질문에 답한다.
1) how much memory to offload?
2) what memory to offload?
TMO는 page-promotion rate metric을 사용하는 zswap과 다르게 PSI를 이용하여 얼만큼의 memory를 offload할 수 있는지를 판단한다. PSI란 Pressure Stall Information의 약자로 특정 process가 memory 부족에 의해서 멈추는 시간 비율을 의미한다. PSI가 높으면 해당 process의 memory가 부족하다는 뜻이기 때문에 offloading을 줄여야 하고, 낮으면 offloading을 늘려도 괜찮다.
TMO는 userspace의 Senpai를 이용하여 kernel이 memory reclaim을 하도록 만든다. 이때 kernel이 어떤 memory를 offload할지를 결정하게 된다.
이때 논문에서는 기존 kernel이 file cache에 치중해서 memory offloading을 시행한다는 사실을 알아냈다. anonymous memory와 file-backed memory가 균등하게 offloading 되도록 기존 kernel을 수정했다고 한다.
3.1 TMO Architecture
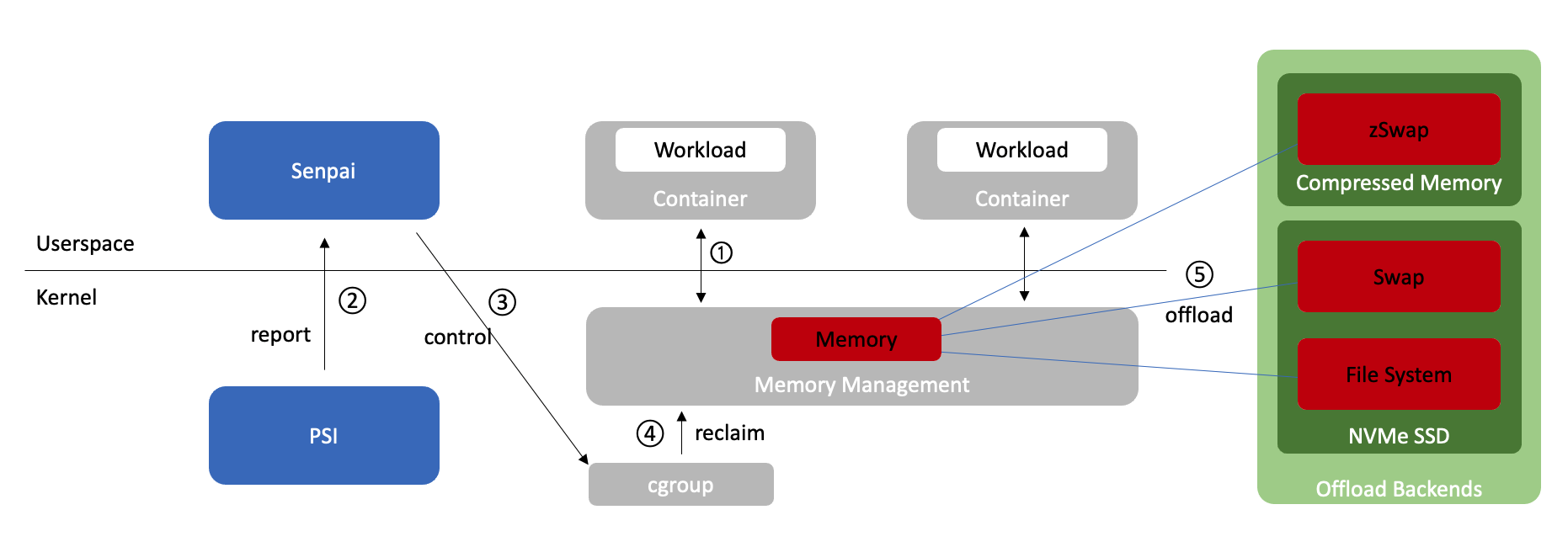
1) 가장 먼저 userspace에 존재하는 workload들은 kernel에 존재하는 memory management 유닛과 상호작용한다. workload 입장에서 즉각적으로 데이터를 주고받을 수 있는 memory(DRAM에 존재)에 read&write을 수행해주는 블록이라고 생각하면 된다.
2) userspace에 존재하는 Senpai는 주기적으로 PSI의 값을 확인하여 app의 성능 저하가 있는지 확인한다. PSI와 Senpai에 대한 자세한 내용은 각각 3.2와 3.3에서 확인할 예정이다.
3) Senpai는 PSI의 정보를 이용해 offloading을 할지 말지, 한다면 얼마나 적극적으로 할지 결정해 kernel에 존재하는 cgroup control file에 적절한 내용을 작성한다.
4) kernel에 존재하는 memory management 유닛은 cgroup에 적힌 내용을 확인한다.
5) 해당 내용을 토대로 memory management는 offloading을 수행한다.
3.2 Defining Resource Pressure
하나의 테스크에 무한한 memory resource가 있다면 멈추지 않고 CPU에서 계속 수행될 수 있다. 하지만 memory가 제한이 된다면 시행이 되다가 필요로 하는 데이터가 memory에 없을 시 멈추게 된다(stall). 그리고 필요로 하는 데이터가 로드 되면 다시 수행된다.
논문에서는 특정 테스크의 전체 수행 시간 대비 이렇게 memory resouce 부족으로 인해서 프로세스가 멈추는 시간의 비율을 PSI라고 정의한다.
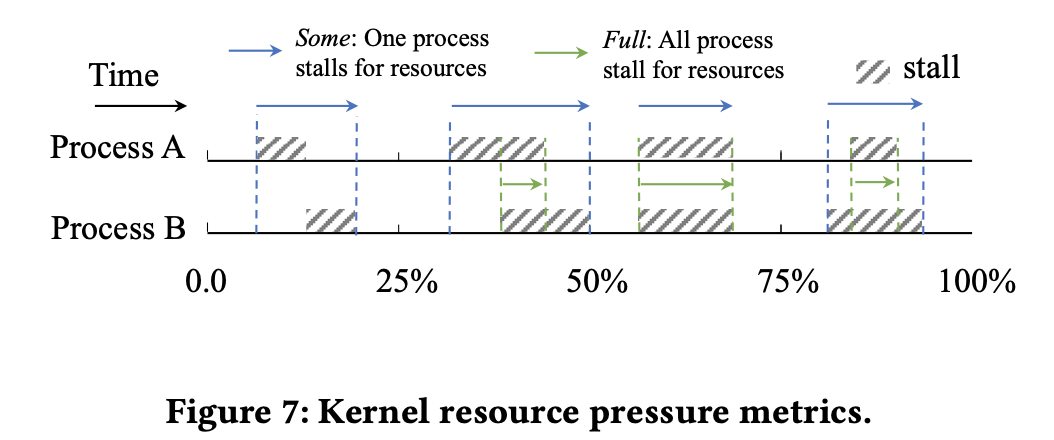
위 그림처럼 프로세스가 두 개 이상 존재할 때 stall을 두 가지로 구분할 수 있다. 적어도 하나의 프로세스가 멈추는 시간의 총 합 비율을 some metric, 모든 프로세스가 멈추는 시간의 총 합 비율을 full metric이라고 정의한다.
TMO에서는 some metric을 이용하여 memory offloading으로 인한 성능 영향을 측정한다.
3.3 Determining Memory Requirements of Containers
다시 복습하자면, TMO는 아래 두 가지 질문에 답한다고 했다.
1) how much memory to offload?
2) what memory to offload?
여기서 첫 번째 질문인 얼마 만큼의 memory를 offload 할지를 결정할 때 3.2에서 정의한 PSI를 이용한다. PSI가 클수록 해당 process는 memory resource 부족으로 인해서 stall이 많다는 것이고, 이런 경우에는 offloading을 안 하거나 적게 해야할 것이다. 반대로 PSI가 작을수록 memory가 충분하다는 의미이므로 offloading을 더욱 적극적으로 수행해도 괜찮을 것이다.
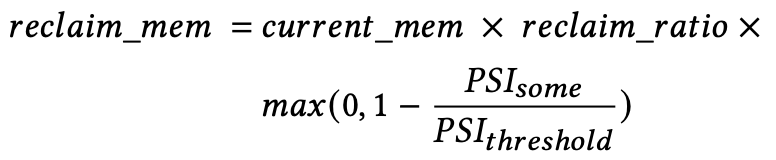
위 식은 reclaim의 양, 즉 offloading을 할 양을 결정하는 식이다. 여기서 reclaim_ratio와 PSI_threshold는 미리 정해지는 값이다.
max 안의 식을 보면 PSI_some > PSI_threshold이면 해당 process가 memory 부족 현상을 겪고 있는 것이니 reclaim을 하지 않고, PSI_some < PSI_threshold이면 reclaim을 진행한다. PSI_some의 값이 작을수록 더욱 많은 reclaim을 수행한다.
Senpai는 또한 workload의 cgroup의 memory limit을 지속적으로 조절한다. 하지만, workload의 memory growth가 빠를 경우 Senpai가 limit을 조절할 때까지 memory growth가 막힐 수 있다.
이런 문제를 해결하기 위해 stateless memory.reclaim cgroup file을 만든다.
3.4 Kernel Optimizations for Memory Offloading
Senpai가 cold memory page들을 reclaim 할 때는 kernel에 존재하는 알고리즘을 활용한다. 그러나 역사적으로 kernel은 swap을 이용하는 것에 굉장히 보수적이기 때문에 reclaim이 file cache memory에 편향된다.
이는 HDD를 사용하던 시기 swap을 이용하면 상당한 overhead가 생겼으며, 일반적으로 working set이 필요로 하는 memory의 크기가 사용 가능한 memory보다 큰 경우가 별로 없었기 때문이다.
reclaim이 file cache memory에 편향되는 문제를 해결하기 위해서 TMO는 refault 값을 이용한다.
file cache가 memory로부터 방출되면 cgroup별로 존재하는 counter가 작동되고, 현재 counter 값은 shadow entry에 저장이 된다고 한다. file cache가 다시 필요해지면(fault가 발생) kernel은 이 counter 값을 비교하여 reuse distance를 확인할 수 있다. reuse distance가 resident memory의 크기보다 작으면 해당 fault를 refault로 간주한다.
논문에서는 refault가 발생하는 순간부터 kernel이 file-backed와 swap-backed cold memory를 offloading하는 비율을 적절히 조절하도록 kernel을 수정했다고 한다.
Transparent Zswap Support
잠시 논문에 나와 있는 Zswap을 이용하는 것의 장점을 살펴보고 Evaluation으로 넘어가기로 하자. 먼저 zswap은 anonymous memory를 DRAM 상에 압축된 형태로 저장할 수 있도록 해준다. disk에 저장하지 않고 memory에 저장하기 때문에 IO가 수행될 필요가 없어 latency가 훨씬 작다. 하지만 이는 app의 cold anonymous memory가 압축될 수 있는 정도에 따라 제한적으로 사용할 수 있다.
zwap을 이용하면 기본적으로 latency가 줄어들기 때문에 더 많은 page들을 offload할 수 있게 된다.
4. Evaluation
아래 다섯 가지 항목에 대한 평가가 진행이 되었다.
1) How much memory can TMO save?
2) How does TMO impact memory-bound applications?
3) Are PSI metrics more effective than the promotion-rate metric?
4) How to tune TMO's configurable parameters?
5) Can TMO avoid SSD wear-out due to offloading writes?
논문에서 사용하는 offload backend는 compressed memory와 NVMe SSD라고 앞에서 설명하였다. 기본적으로 압축이 잘 돼 compressed memory에 저장하는 것이 이득인 경우에는 적극적으로 해당 backend에 offloading을 진행하는 것이 논문에서 취하는 스탠스이다. 압축이 잘 안 돼 compressed memory에 offloading 하는 것에서 이득을 볼 수 없는 workload들에 대해서는 SSD에 offloading을 진행한다.
4.1 Fleet-Wide Memory Savings
1) Application savings
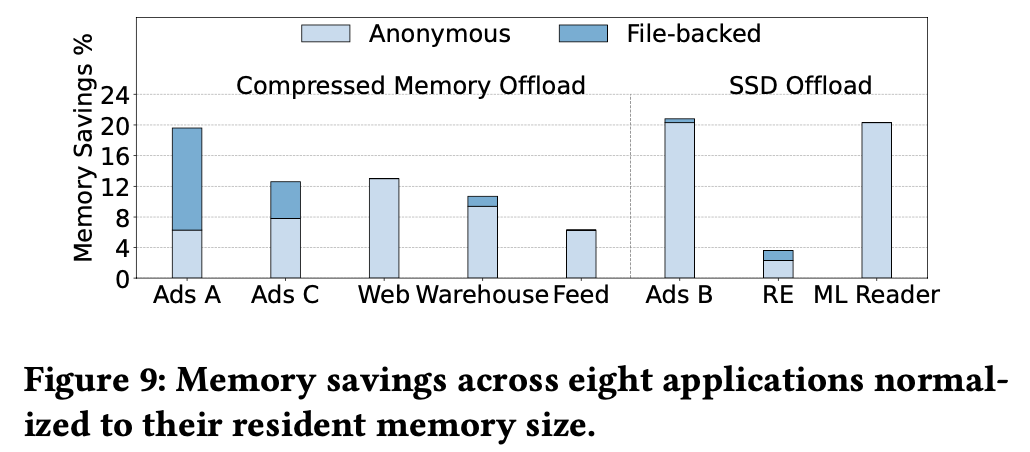
위 그림은 TMO를 사용하여 compressed memory와 SSD 각각을 offload backend로 설정했을 때 절약할 수 있는 memory의 비율을 나타낸 것이다.
4.2 Performance Impact on Memory-Bound Applications
TMO가 memory-bound app, 즉, memory가 제한된 app에 대해서 성능을 얼마나 향상시킬 수 있는지를 분석한다. Web app에 대해서 분석하는데, 이유는 meta 특성상 web의 성능을 테스트할 수 있는 도구가 많기 때문이다.
web의 현재 performance는 RPS(request per second)로 측정한다. 각 server는 memory가 부족해지면 RPS를 낮춘다.
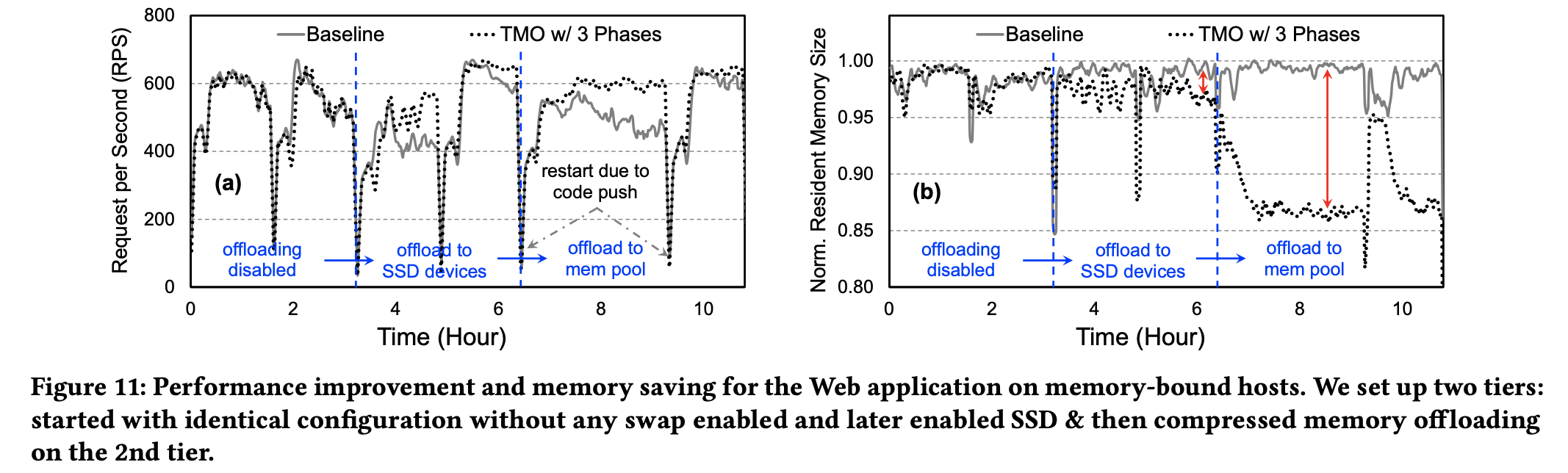
위 그림의 (a)를 보면 TMO를 사용할 때 SSD와 compressed memory offload를 사용하면 RPS가 증가하는 것을 볼 수 있다.
(b)는 SSD와 compressed memory offload 시 각각에서 resident memory size를 나타낸 것이다. 둘 모두 size가 감소하여 compressed와 SSD 각각에서 13%와 4%의 memory 절약이 이루어진다. web의 경우 compression ratio가 4x이기 때문에 SSD와 비교해 훨씬 많은 memory가 절약되는 것을 확인할 수 있다. 또한 SSD의 경우 compressed memory와 비교하여 access latency가 더 큰데, web이 latency에 취약해서 size의 극적인 절약이 이루어지지 않음을 확인할 수 있다.
4.3 Comparing PSI and Promotion Rate
기본적으로 PSI는 app의 memory 접근으로 인한 지연뿐만 아니라 offload backend에 따른 성능 차이를 잘 반영한다. 예를 들어 느린 backend를 이용하면 PSI는 증가하는 식이다.
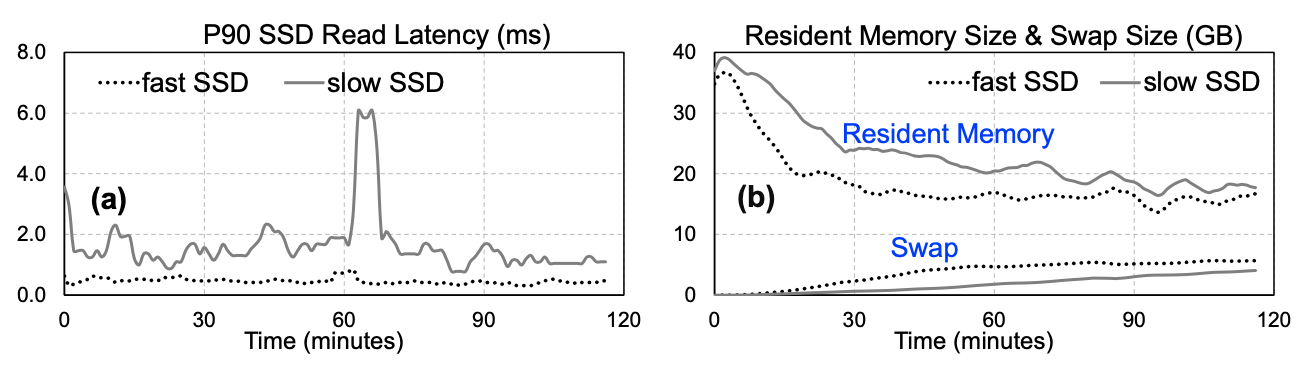
예를 들어 위 그림을 보면 fast SSD가 slow SSD보다 read latency가 더 작은데, TMO를 이용하면 fast SSD를 사용할 때 더 많은 swapping이 일어나서 resident memory가 더 줄어드는 것을 확인할 수 있다. 즉, fast SSD를 사용하면 memory를 더 많이 절약할 수 있다는 의미이다.
다르게 생각하면 fast SSD를 offload backend로 사용하는 workload가 memory pressure를 덜 받기 때문에 더 많은 offloading이 일어난다고 생각할 수 있다.
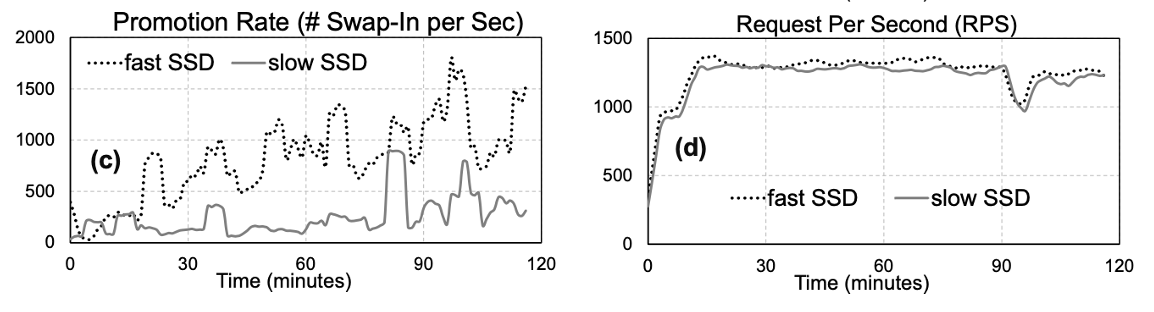
그런데, promotion rate을 memory pressure의 기준으로 사용하면, 위 그림처럼 fast SSD와 slow SSD 예시에서 fast SSD를 사용할 때 workload가 더 많은 memory pressure를 겪고 있다고 판단해버린다.
때문에 (d)에서처럼 fast SSD가 더 많은 memory request를 가져가게 된다.
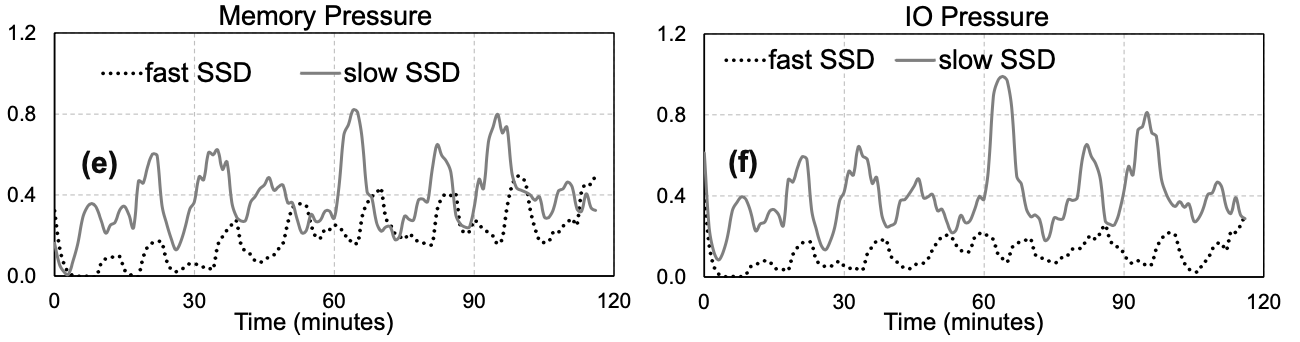
promotion rate 대신 PSI를 사용하면 위 그림처럼 offload backend의 성능에 따른 memory pressure를 알맞게 분석할 수 있다.
