카프카 미러메이커2란?
서로 다른 두 개의 카프카 클러스터 간에 토픽을 복제하는 애플리케이션이다. 미러메이커2를 사용하는 이유는 모든 토픽을 복제할 필요성이 있을 경우이다. 특히 동일한 파티션에 동일한 레코드가 들어가도록 하는 작업은 복제하기 전 클러스터에서 사용하던 파티셔너에 대한 정보가 없이는 불가능한데 이 힘든 부분을 해결할 수 있는 것이 미러메이커2 이다.
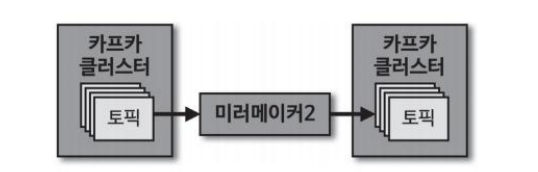
미러메이커2를 활용한 지리적 복제
- 액티브-스탠바이 클러스터 운영
서비스 애플리케이션들과 통신하는 카프카 클러스터 외에 재해 복구를 위해 임시 카프카 클러스터를 하나 더 구성하는 경우 액티브-스탠바이 클러스터로 운영할 수 있다. 이럴 경우 애플리케이션들이 직접 통신하는 카프카를 "액티브 클러스터" 라고 부르고 나머지 1개의 클러스터를 "스탠바이 클러스터" 라고 부른다.
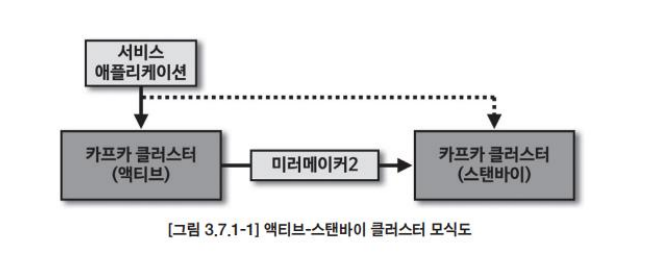
만약 액티브 클러스터가 자연 재해 또는 기술적 공격으로 중단되더라도 스탠바이 클러스터로 복제하고 잇으므로 장애 없이 계속 이어나갈 수 있다. 하지만 스탠바이 클러스터라고 무조건 복제가 되는 것은 아닌데 복제가 지연되는 현상인 "복제 랙"이 발생할 수 있으며 이는 데이터 유실로 이어지게 될 수 있다.
- 액티브-액티브 클러스터 운영
지연을 최소화하기 위해 2개 이상의 클러스터를 두고 서로 데이터를 미러링하면서 사용할 수 있는 환경을 액티브-액티브 클러스터라고 한다. 글로벌 서비스에서 자주 이용된다.
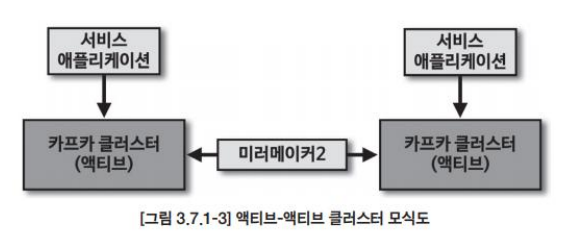
각 지역마다 클러스터를 두고 필요한 데이터만 복제하여 사용하기 때문에 관련 데이터를 조회할 때 데이터 지연을 줄일 수 있다.
- 허브 앤 스포크 클러스터 운영
소규모 카프카 클러스터를 운영하고 있을 때 각 팀의 카프카 클러스터의 데이터를 한 개의 카프카 클러스터에 모아 데이터 레이크로 사용하고 싶을 때 사용할 수 있는 방식이다.
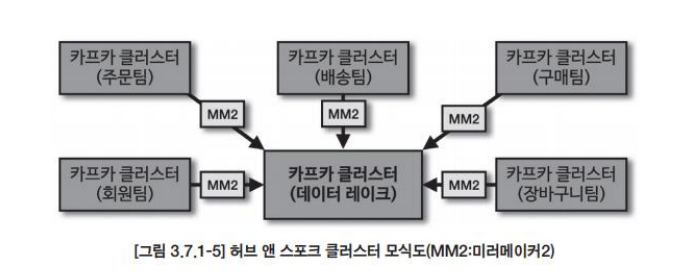
여기서 허브란 중앙에 위치한 데이터 레이크 용도의 카프카 클러스터를 뜻하며 데이터 레이크의 특성상 서비스에서 생성된 데이터를 수집, 가공, 분석하는 격리된 플랫폼이 필요하다. 미러메이커2를 사용하여 각 팀에서 사용하는 카프카 클러스터에 존재하는 데이터를 수집하고 데이터 레이크용 카프카 클러스터에서 가공, 분석하여 가치 있는 데이터를 찾아낼 수 있다.
