Kafka Connect란?
카프카 오픈소스에 포함된 툴 중 하나로 데이터 파이프라인 생성 시 반복 작업을 줄이고 효율적인 전송을 이루기 위한 애플리케이션이다, 즉 프로듀서, 컨슈머가 반복된 작업을 할 경우 매번 개발하고 배포, 운영해야 하기 때문에 비효율적일 수 있는 부분을 커넥트를 통해 특정한 형태의 템플릿으로 만들어놓은 커넥터를 실행함으로써 반복 작업을 줄일 수 있다.
- 소스 커넥터(source connector) → 프로듀서 역활을 한다.
- 싱크 커넥터(sink connector) → 컨슈머 역할을 한다.
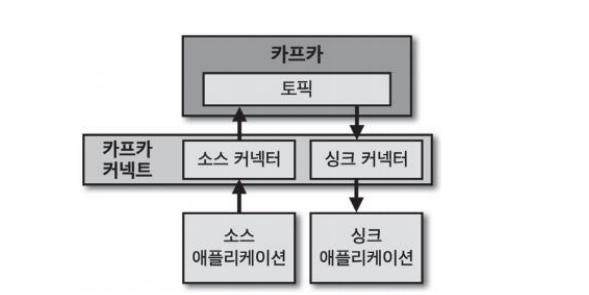
즉, Kafka Connect는 더 간편하게 효율적으로 데이터파이프라인을 구축하는 방법이며, MicroService에서 직접 DB에 대한 커넥션과 처리작업을 하지 않고 관련 작업은 kafka에 일임하는 역할을 한다. 그렇기 때문에 비용, 시간이 단축될 수 있다.
-
데이터 중심 파이프라인
- 커넥트를 이용해 카프카로부터 데이터를 보내거나, 카프카로부터 데이터를 가져올 수 있다.
-
유연성과 확장성
- 커넥트는 테스트 및 일회성 작업을 위한 단독 모드 (standalone mode) 로 실행할 수 있고, 대규모 운영 환경을 위한 분산 모드 (distributed mode(클러스터형))로 실행할 수 있다.
-
재사용성과 기능 확장
- 커넥트는 이미 만들어진 기존 커넥트들을 활용할 수도 있고, 운영 환경에서의 요구사항에 맞춰 빠르게 확장이 가능하다.
-
장애 및 복구
- 카프카 커넥트를 분산 모드로 실행하면, 워커 노드(worker node)의 장애 상황에도 유연하게 대응 가능하므로 고가용성이 보장된다.
커넥트의 종류
-
단일 모드 커넥트
- 단일 애플리케이션으로 실행
- 1개 프로세스만 실행되는 특징 (단일 프로세스이기에 단일 장애점이 될 수 있다.)
- 주로 개발환경이나 중요도가 낮은 파이프라인을 운영할 때 사용
-
분산 모드 커넥트
- 2대 이상의 서버에서 클러스터 형태로 운영(단일 대비 안전하게 유지 가능)
- 데이터 처리량의 변화에도 유연하게 대응 가능 (스케일 아웃 가능)
Kafka Connector
커넥터는 데이터를 어디서(soruce) 복사하는지와, 어디에다(sink) 붙여넣어야 하는지를 정의한다.
- 카프카 커넥트와 카프카 커넥터의 정의
kafka connect : 프레임워크
kafka connector : connec 안에 들어가는 플러그인의 한 종류
- 두 가지 종류의 kafka connector
Source Connector - Source System의 데이터를 카프카 토픽으로 Publish 하는 커넥터. 즉, Producer의 역할을 하는 커넥터
Sink Connector - 카프카 토픽의 데이터를 Subscribe해서 Target System에 반영하는 커넥터. 즉, Consumer의 역할을 하는 커넥터
소스 커넥터
소스 애플리케이션 또는 소스 파일로부터 데이터를 가져와 토픽으로 넣는 역할을 한다. 많은 오픈 소스 커넥터가 존재하지만 라이선스 문제나 로직을 커스텀해서 구현해야 할 경우 SourceConnector, SourceTask 클래스를 사용하여 직접 만들 수 있다.
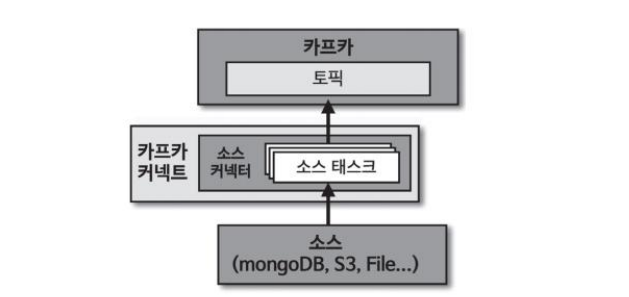
- SourceConnector : Task를 실행하기 전 커넥터 설정파일을 초기화하고 어떤 태스크 클래스를 사용할 것인지 정의하며 실질적인 데이터 처리 로직이 들어가지 않는다.
- SourceTask : 소스 애플리케이션 또는 소스 파일로부터 데이터를 가져와서 토픽으로 데이터를 보내는 역할
gradle에 dependency 추가
// https://mvnrepository.com/artifact/org.apache.kafka/connect-api
implementation group: 'org.apache.kafka', name: 'connect-api', version: '2.5.0'싱크 커넥터
토픽의 데이터를 타깃 애플리케이션 또는 타깃 파일로 저장하는 역할을 한다. 커넥트 라이브러리에서 제공하는 SinkConnector와 SinkTask 클래스를 사용하면 직접 싱크 커넥터를 구현할 수 있다.
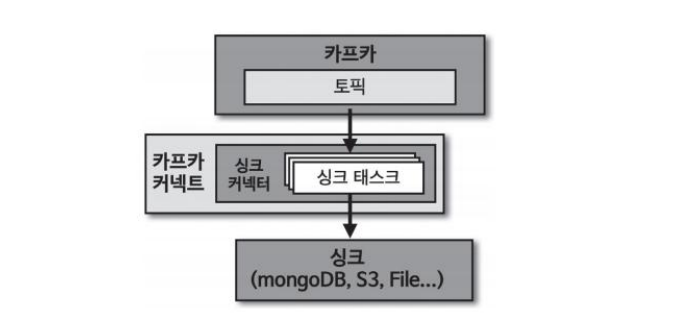
- SinkConnector : Task를 실행하기 전에 사용자로부터 입력받은 설정값을 초기화하고 어떤 태스크 클래스를 사용할 것인지 정의하며 실질적인 데이터 처리 로직이 들어가지 않는다.
SinkTask : 실제로 데이터를 처리하는 로직이 있는 곳이며 컨슈머 역할을 하고 데이터를 저장하는 코드를 가지게 된다.
참고 자료
Kafka Connect 란?
