Collector
Collector는 스트림에서 최종연산에 해당하는 .collect() 함수의 파라미터에 해당하는 인터페이스이다. 내가 가장 자주 사용하는 .collect(Collectors.toList())도 Collector의 한 부분이다.
Collectors 구성
스트림 데이터를 어떻게 그룹화 하냐에 따라 여러 방식이 나뉩니다.
- 요약
- counting
- maxBy, minBy
- summingInt, summingLong, summingDouble)
- averagingInt, averagingLong, averagingDoubl
- summarizingInt, summarizingLong, summarizingDouble
- joining
- toList, toSet, toCollection
- 다수준 그룹화
- groupingBy, collectingAndThen
- 분할
- partitioningBy
요약
스트림의 항목을 컬렉션으로 재구성할 수 있으며, 일반적으로 컬렉터로 스트림의 모든 항목을 하나의 결과로 합칠 수 있다.
- counting()
private static long howManyDishes() {
return menu.stream().collect(Collectors.counting());
// return menu.stream().count(); 더 쉽게 표현하는 방법
}컬렉터로 메뉴에서 요리의 수를 반환한다.
- maxBy(), minBy()
private static Dish findMostCaloricDishUsingComparator() {
Comparator<Dish> dishCaloriesComparator = Comparator.comparingInt(Dish::getCalories);
BinaryOperator<Dish> moreCaloricOf = BinaryOperator.maxBy(dishCaloriesComparator);
return menu.stream().collect(reducing(moreCaloricOf)).get();
}maxBy(Comparator comparator) 는 파라미터로 비교/정렬을 위한 기준을 제공하는 Comparator를 받고, Comparator를 기준으로 최댓값을 갖는 객체로 요약해서 리턴합니다.
마찬가지로 minBy(Comparator comparator) 는 Comparator를 기준으로 최솟값을 갖는 객체로 요약해서 리턴합니다.
- summingInt()
private static int calculateTotalCalories() {
return menu.stream().collect(Collectors.summingInt(Dish::getCalories));
}summingInt가 collect 메서드로 전달되면 요약 작업을 수행하며 리스트의 총 칼로리를 계산한다.
- averagingInt()
private static Double calculateAverageCalories() {
return menu.stream().collect(Collectors.averagingInt(Dish::getCalories));
}숫자 집합의 평균을 계산한다. (averagingLong, averagingDouble)
- summarizingInt()
private static IntSummaryStatistics calculateMenuStatistics() {
return menu.stream().collect(summarizingInt(Dish::getCalories));
}
// 결과 : Menu statistics: IntSummaryStatistics{count=9, sum=4300, min=120, average=477.777778, max=800}요소 수, 요리의 칼로리 합계, 평균, 최댓값, 최솟값 등을 계산해준다. (summarizingLong, summarizingDouble)
- joining()
private static String getShortMenu() {
return menu.stream().map(Dish::getName).collect(joining());
}
// 결과 : porkbeefchickenfrench friesriceseason fruitpizzaprawnssalmon모든 요리명을 연결해주는 함수이다. getName을 받아와 모든 이름들은 연결해준다. 내부적으로는 StringBuilder를 이용하여 문자를 하나로 만든다. 뒤에 collect(joining(", ")) 와 같이 구분자도 넣어줄 수 있다.
하지만 지금까지 구현한 모든 예제는 collect(reducing())을 이용해서도 구현할 수 있지만 코드의 가독성과 편의성도 좋아지기 때문에 컬렉터를 사용하는 것이 좋을 수 있다.
Stream의 많은 방법으로 구현할 수 있다. 어떤 방법을 이용해야할까?
스트림을 통해 다양한 방법으로 구현할 수 있다. sum을 구하는 로직이라도 reduce를 이용할 수 있고 IntStream을 이용할 수 있으며 Collectors.summingInt를 이용할 수 있다. 문제를 해결할 수 있는 다양한 해결 방법을 확인하고 가장 일반적으로 문제에 특화된 해결책을 고르는 것이 가장 바람직한 선택 방법이다.
그룹화
데이터베이스에서도 많이 볼 수 있는 연산 중에 하나로 그룹화하는 연산이다.
이번에는 최종 연산자 collect 의 Collector 인터페이스를 구현하여 그룹화하는 다양한 방법에 대해 알아보자!
private static Map<Dish.Type, List<Dish>> groupDishesByType() {
return menu.stream().collect(groupingBy(Dish::getType));
}
// 결과 : {FISH=[prawns, salmon], MEAT=[pork, beef, chicken], OTHER=[french fries, rice, season fruit, pizza]}type이 일치하는 모든 요리를 추출하는 함수를 groupingBy 메서드로 전달했다. (분류 함수)
하지만 groupingBy는 복잡한 기준에는 사용할 수 없는데 이럴 경우 람다 표현식으로 로직을 직접 구현해야한다. 또한 groupingBy의 큰 장점은 그룹화된 요소 조작이 가능하다는 것이다.
private static Map<Dish.Type, List<Dish>> groupCaloricDishesByType() {
// 방법 1 : {OTHER=[french fries, pizza], MEAT=[pork, beef]}
return menu.stream().filter(dish -> dish.getCalories() > 500)
.collect(groupingBy(Dish::getType));
// 방법 2 : {MEAT=[pork, beef], OTHER=[french fries, pizza], FISH=[]}
return menu.stream().collect(
groupingBy(Dish::getType,
filtering(dish -> dish.getCalories() > 500, toList())));
}둘의 차이점은 filter에 포함되지 않는 결과를 포함하냐 마냐에 차이에 있다.
다수준의 그룹화도 가능한데 다수준의 그룹화란 그룹화내부에 또 그룹화를 하는 것을 말한다.
private static Map<Dish.Type, Map<CaloricLevel, List<Dish>>> groupDishedByTypeAndCaloricLevel() {
return menu.stream().collect(
groupingBy(Dish::getType,
groupingBy((Dish dish) -> {
if (dish.getCalories() <= 400) {
return CaloricLevel.DIET;
}
else if (dish.getCalories() <= 700) {
return CaloricLevel.NORMAL;
}
else {
return CaloricLevel.FAT;
}
})
)
);
}
// 결과 : {FISH={DIET=[prawns], NORMAL=[salmon]}, MEAT={FAT=[pork], DIET=[chicken], NORMAL=[beef]}, OTHER={DIET=[rice, season fruit], NORMAL=[french fries, pizza]}}분할
분할 함수라 불리는 프레디케이트를 분류 함수로 사용하는 특수한 그룹화 기능이며 맵의 키 형식은 Boolean이다.
private static Map<Boolean, List<Dish>> partitionByVegeterian() {
return menu.stream().collect(partitioningBy(Dish::isVegetarian));
}
// 결과 : {false=[pork, beef, chicken, prawns, salmon],
// true=[french fries, rice, season fruit, pizza]}true와 false만 존재하므로 결과는 무조건 2가지 분류로 나눠지게 된다.
private static Map<Boolean, Map<Dish.Type, List<Dish>>> vegetarianDishesByType() {
return menu.stream().collect(partitioningBy(Dish::isVegetarian, groupingBy(Dish::getType)));
}
// 결과 : {false={FISH=[prawns, salmon], MEAT=[pork, beef, chicken]},
// true={OTHER=[french fries, rice, season fruit, pizza]}}위와 같은 형식으로 partitioningBy안에 groupingBy 정의함으로써 두 수준의 맵으로 반환 받을 수도 있다.
Collector 인터페이스
리듀싱 연산을 어떻게 구현할지 제공하는 메서드 집함으로 구성되어 있다.
- Collector 인터페이스의 내부

T : 매개변수 리덕션 연산에 사용되는 입력 요소의 타입을 나타낸다. 즉, 어떤 종류의 요소를 입력을 받을 것인지 나타냄
A : 리덕션 연산 중에 누적되는 값의 타입을 나타낸다. 누적값은 중간 과정에 발생하며 종종 내부적인 구현 세부사항은 숨겨진다.
R : 리덕션 연산의 결과물의 타입을 나타낸다. 즉, 최종 결과물이 어떤 타입인지 나타냄
- supplier 메서드
Supplier<A> supplier();
//활용
public Supplier<List<T>> supplier() {
return ArrayList::new; // 생성자 참조
}supplier는 수집 과정에서 빈 누적자 인스턴스를 만드는 파라미터가 없는 함수다.
간단히 말해 reducing 연산을 진행하며 누적할 저장소 공간(A)을 생성한다고 생각하면 될 것 같다. ToListCollector에서는 ArrayList형 인스턴스를 만들어 반환한다.
- accumulator 메서드
BiConsumer<A, T> accumulator();
// 활용
@Override
public BiConsumer<List<T>, T> accumulator() {
return List::add;
}accumulator 메서드는 리듀싱 연산을 수행하는 함수를 반환한다.
요소를 탐색하면서 적용하는 함수의 의해 누적자 내부상태가 바뀌므로 함수의 반환 타입은 void이다. ToListCollector에서는 supplier에서 받은 저장소 공간 List(A)에 데이터(T)를 누적하는 로직이 들어가야 한다.
- finisher 메서드
Function<A, R> finisher();
//활용
@Override
public Function<List<T>, List<T>> finisher() {
return Function.identity();
}finisher 메서드는 스트림 탐색을 끝내고 누적자 객체를 최종 결과로 변환하면서 누적 과정을 끝낼 때 호출할 함수를 반환해야 한다. ToListCollector에서는 스트림 탐색을 진행하며 누적한 데이터(A)와 최종 결과(R)가 같은 형태이므로 변환 과정이 필요하지 않다. Function의 identity 메서드는 데이터를 그대로 반환한다.
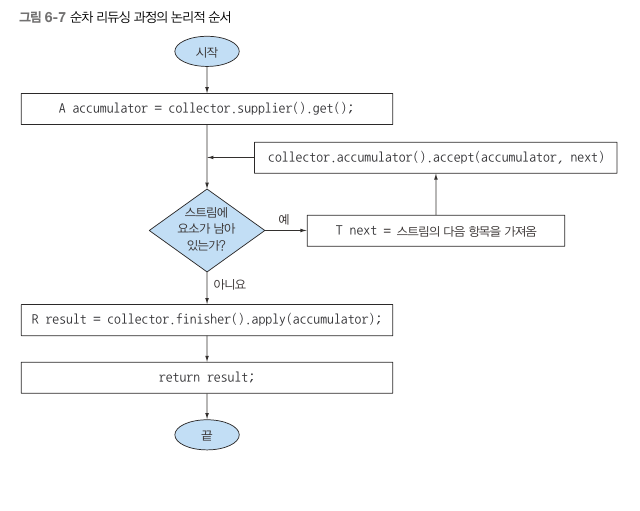
- combiner 메서드
BinaryOperator<A> combiner();
// 활용
@Override
public BinaryOperator<List<T>> combiner() {
return (list1, list2) -> {
list1.addAll(list2);
return list1;
};
}combiner 메서드는 스트림의 서로 다른 서브파트를 병렬로 처리할 때 누적자가 이 결과를 어떻게 처리할지 정의한다. ToListCollector에서는 List와 List를 병합하는 코드를 작성하면 된다. combiner 메서드까지 이용하면 스트림의 리듀싱을 병렬로 수행할 수 있다. 스트림의 리듀싱을 병렬로 수행할 때 포크/조인 프레임워크와 Spliterator를 사용한다.
- Characteristics 메서드
컬렉터 연산을 정의하는 Characteristics 형식의 불변 집합을 반환한다. Characteristics는 스트림을 병렬로 리듀스할 것인지 그리고 병렬로 리듀스한다면 어떤 최적화를 선택해야 할지 힌트를 제공한다.
- UNORDERED : 리듀싱 결과는 스트림 요소의 방문 순서나 누적 순서에 영향을 받지 않음
- CONCURRENT : 다중 스레드에서 accumulator 함수를 동시에 호출할 수 있으며 이 컬렉터는 스트림의 병렬 리듀싱을 수행할 수 있다.
- IDENTITY_FINISH : finisher 메서드가 반환하는 함수는 단순히 identity를 적용할 뿐이므로 이를 생략할 수 있다. 즉, 리듀싱 과정에서 최종 결과 형태로 변환하지 않고 누적자 객체를 바로 사용할 수 있다. @Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(IDENTITY_FINISH, CONCURRENT));
}ToListCollector에서는 누적자 객체와 최종 결과의 형태가 같아서 추가 변환이 필요없으므로 IDENTITY_FINISH다. 리고 병렬 처리를 실행할것이기 때문에 CONCURRENT로 설정한다.
- ToListCollector와 ToMapCollector Test
public class Order {
private String orderNumber;
private String productName;
private Integer payPrice;
private Currency currency;
public Order(String orderNumber, String productName, Integer payPrice, Currency currency) {
this.orderNumber = orderNumber;
this.productName = productName;
this.payPrice = payPrice;
this.currency = currency;
}
public String getOrderNumber() {
return orderNumber;
}
public String getProductName() {
return productName;
}
public Integer getPayPrice() {
return payPrice;
}
public Currency getCurrency() {
return currency;
}
@Override
public String toString() {
return "Order{" +
"orderNumber='" + orderNumber + '\'' +
", productName='" + productName + '\'' +
", payPrice=" + payPrice +
", currency=" + currency +
'}';
}
}
class Test{
public static void main(String[] args) {
List<Order> orders = new ArrayList<>() {{
add(new Order("00001", "아반테", 20000000, Currency.getInstance(Locale.KOREA)));
add(new Order("00002", "소나타", 30000000, Currency.getInstance(Locale.KOREA)));
add(new Order("00003", "그랜저", 40000000, Currency.getInstance(Locale.KOREA)));
add(new Order("00004", "그랜저", 30000, Currency.getInstance(Locale.US)));
}};
List<Order> usOrders = orders.stream()
.filter(order -> order.getCurrency().equals(Currency.getInstance(Locale.US)))
.collect(new ToListCollector<>());
System.out.println(usOrders);
Map<String, Order> usOrdersMap = orders.stream()
.filter(order -> order.getCurrency().equals(Currency.getInstance(Locale.US)))
.collect(new ToMapCollector<>(Order::getOrderNumber, Function.identity(), (existing, replacement) -> replacement));
System.out.println(usOrdersMap);
}
}
// List 결과 : [Order{orderNumber='00004', productName='그랜저', payPrice=30000, currency=USD}]
// Map 결과 : {00004=Order{orderNumber='00004', productName='그랜저', payPrice=30000, currency=USD}}- 컬렉터를 구현하지 않고 커스텀 수집하기
ToListCollector처럼 Override받아 직접 커스텀하지 않고 collect을 이용하여 스트림의 모든 항목을 리스트에 수집하는 방법도 있다.
ArrayList<Order> customOrder = orders.stream()
.collect(
ArrayList::new, // 발행 (supplier)
List::add, // 누적 (accumulator)
List::addAll // 집합 (combiner)
);
System.out.println(customOrder);하지만 가독성이 떨어지고 재사용성을 높이기 위하여 Collector를 커스텀하여 사용하는 것이 좋다. 또한 메서드로 Characteristics를 전달할 수 없다.
- 참고 자료
