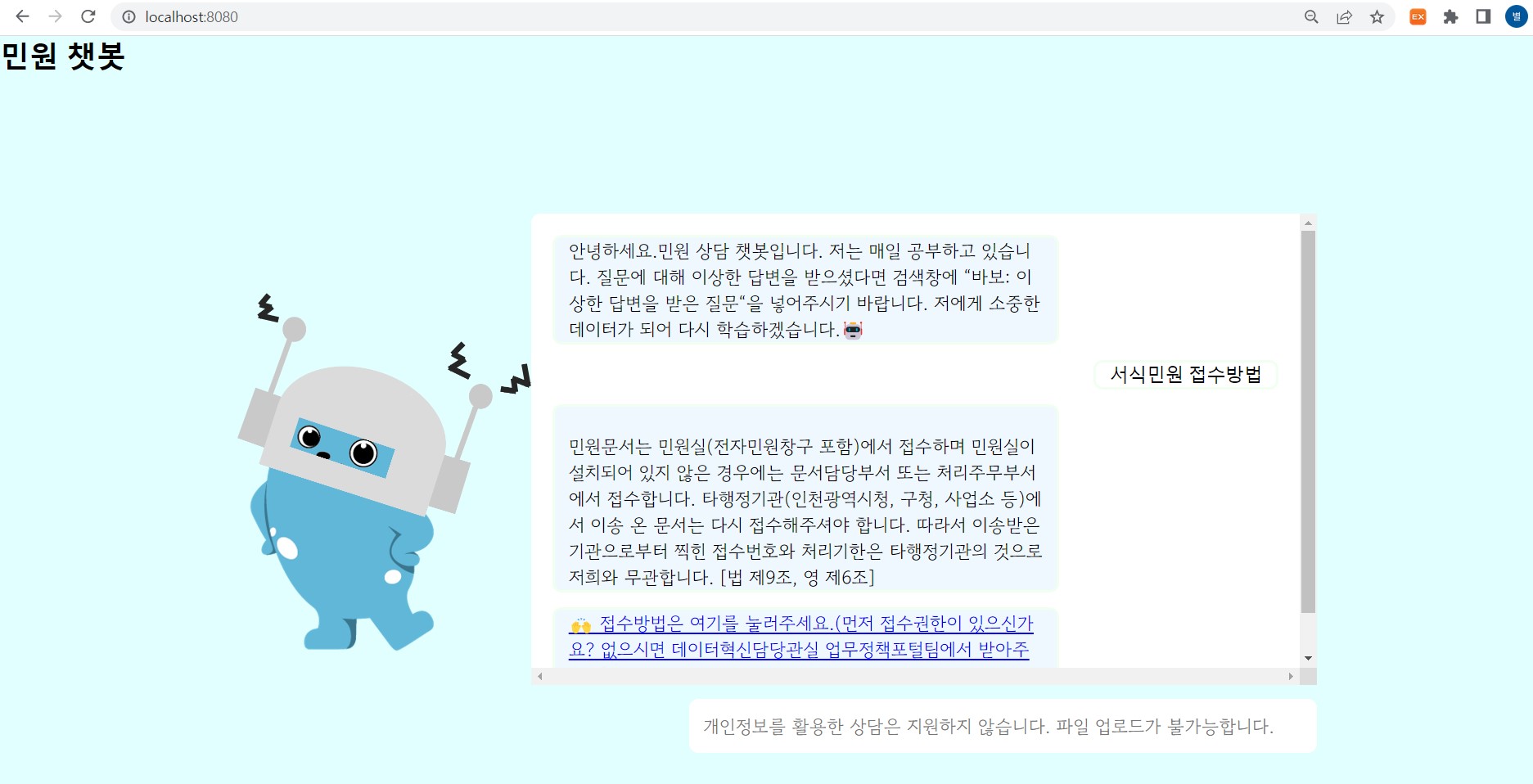
위는 프로젝트를 localhost에서 구현한 모습입니다.
전체적인 모양새는 아래와 같습니다.
프론트와 백엔드를 구별했으면 각 Controller와 클래스의 역할은 이렇다.
원하는 기능
- 서식민원 접수하는 방법, 취아원 등의 양식을 요구하면 바로 다운받을 수 있도록 파일이 업로드된 답변을 줘야 한다.
- 그 외로 민원처리법에 관해 자주 묻는 질문들에 대해서 바로바로 답변해줘야 한다.
접근
-
단어 사전 구축하기
-
의도 파악 데이터 만들기
-> 어떤 모델을 사용할 것인가? 논문 읽어보기
-> 몇개의 클래스로 만들것인가? 너무 적으면 모호하다
-> 내가 직접 만들어야 한다.
-> 의도 intent, 질문 query -
개체명 파악 데이터 만들기
-> 어떤 모델을 사용할 것인가? 논문 읽어보기
->공개된 개체명 말뭉치 데이터를 정제해서 사용하기
-> 사용할 수 없다. 내가 직접 만들어야 한다.
-> 일단 내가 만든 질문들 관련해서 개체명을 뽑아야 한다.
공개된 개체명 데이터를 살펴보니 내가 만들고자 하는 주제와 많이 다르기 때문에 직접 만들어야 한다.
-> 질문에서 핵심으로 등장하는 단어들을 개체명으로 인식하도록 만들어야 겠다.
아래는 저 교재에 있던 예제이다. 이것도 작가가 직접 만든 것이다.; 가락지빵 주문 하고싶어요 $<가락지빵:FOOD> 주문 하고싶어요 1 가락지빵 NNG B_FOOD 2 주문 NNP O 3 하 VV O 4 고 EC O 5 싶 VX O 6 어요 EC O ; 가락지빵 먹고싶어요 $<가락지빵:FOOD> 먹고싶어요 1 가락지빵 NNG B_FOOD 2 먹 VV O 3 고 EC O 4 싶 VX O 5 어요 EC O -
앞서 말한 두개의 모델이 아닌 다른 모델로 데이터 학습 시키기. 교재와는 다른 방식으로 진행한다.
-> 일단 spaCy라는 라이브러리를 통해서 개체명을 custom할 수 있지만 한국어는 지원하지 않는다. 어떤 사람이 한국어 기반의 spaCy를 만들려고 했으나 실패했다는 글을 보았다. 일단 아쉽게도 데이터를 직접 만들어야 할 거 같다. 먼저 문장을 품사 단위로 나눈 후에 거기에 개체명을 넣기로 한다.
-> 알아보니 Bert라고 해서 미리 학습된 모델을 내 입맛에 맞게 바꿀 수 있는 것이 있다는데... koBert라고 한국어에 맞게 학습된 모델이 있었다! 개체명 인식도 가능하다는데 일단 더 알아봐야할 거 같다.
접근 2
다시 다른 접근법으로 시작
1. chatbot 학습모델 bert 이용
-> 결론 책에서 배운 의도파악하고 개체명 인식으로 두개의 모델을 이용하지 않고
이미 학습된 모델을 가져오는 Bert를 사용할 것이며 찾아보니 다국어 모델이 있어 한국어 대해서도 반응하는 것이 있었다.
-> 참고로 읽어오는 엑셀 파일의 형태

- bert는 python 파일을 통해서 진행되는데 python파일을 읽어올 java 코드를 구현해야한다.
중간에 고생했던 것은 나는 이 java 코드를 main()함수에서 구현하지 않으며 또한 메소드 자체를 호출하기를 원했기 때문에 processBuilder로 읽어오는데 한계가 있어 중간에 java코드로 구현했다
-> 이는 다시 python 문법을 보니 내가 기초가 부족했던것
if name == main의 의미는 cmd창에서 python파일을 명을 호출할 때 저 아래있는 함수를 호출하겠다는 의미였다..
저 아래 있는 함수가 cmd창의 메인 함수가 되는 것이다!.
-
데이터 구축
평상시 회사에서 사람들이 많이 물어보는 법적인 해석과 양식, 방법들에 대한 파일들을 업로할<a>태그를 함께 넣어줌 -
중요한 것은
<a>태그를 innerHtml로 해서 넣을 것이기 때문에 중간 bert모델의 output데이터(String인 묹열)을 태그로 감싸진 String과 아닌 real text를 분리하는 작업이 필요하다. -
무엇보다 중요한 것은 프론트에서 비동기적으로 데이터를 붙이는 ajax를 사용할 것이며 Controller끼리 데이터를 주고받기 때문에 ajax끼리 순서가 필요하다. 따라서 promis then으로 구현하려 했으나 다음 ajax로 넘어가고 응답이 너무 안왔기 때문에 지저분하지만 success에 넣어서 구현
-
AWS ec2의 서버를 구현하려 했으나 뭔가 이상한 삽질의 시작 그래서 네이버 클라우드에 스프링부트 jar파일을 배포하려고 한다. 일단 부족한 부분은 sudo코드에 대한 이해가 너무 부족하고 공개키에 대한 부분, 포트포워딩, 공유 IP 등 네트워크적 기초 지식이 많이 부족함을 느꼈다. 우분투, 리눅스 등 OS에 대한 이해 등 운영체제와 구조 그냥 기초지식이 부족함
- 마지막으로 일단 데이터를 확보해야 한다. 사람들이 많이 질문하는 내용들과 그에 대한 답변에 해당하는 400쌍의 데이터를 넣어놓았지만 아직도 이상한 답변을 내놓기 때문에 사용자에게 이상한 답변이 오면 "바보: 이상한 답변이 온 질문" 이라는 응답 데이터를 부탁하며 그 데이터는 DB에 쌓아서 다시 학습할 수 있도록 DB와 연동하는 sql문 작업이 필요하다.
+) 아 맞다. 마지막으로 메타문자 때문에 중간 헤맸다.
위가 bert 모델로부터 읽어오는 순수한 output인데 여기서 java에서
String Link = <a href =\"서식민원처리안내.pdf\" download target="_self"> 🙌 처리방법은 여기를 보세요</a>이렇게 String으로 완변하게 저장되려면 "" 중간에 있는 ""들 즉 """"에 대하여 "a"b"c"로 분리한다고 생각해서 중간에 백슬래시를 넣어줘야 한다. 근데 저 백슬랙시가 그대로 출력되므로 중간에 백슬래시를 제거해야 하는데 저게 문자가 아니라 메타데이터여서 Link.replaceAll('\','');로 하면 오류가 생김 따라서 Link.replaceAll('\\',''); 두개로 선언해야 하나의 \를 제거
+) 서버 배포에 성공했지만 Bert모델이 너무 무겁다 보니 답장속도가 너무 느리다. Bert모델에 대한 경량화 방법에 대해 많은 논문들이 있고 그 중에서 DistilKobert나 아예 다른 모델인 KoELECTRA에 대해서 봐야할 거 같다.
또한 아직 DB 구축을 못했다. 사람들이 "바보"가 포함된 말을 해주면 DB에 저장해서 데이터를 수정하려고 했는데
지금은 이 두가지를 얼른 해결해서 제대로 된 서비스를 만들어야 한다.
접근 3
bert 모델은 너무 무겁다.
현재 나는 네이버 클라우드의 무료 서버를 이용하고 있고
[MICRO] 1vCPU, 1GB Mem, 50GB Disk [g1]의 서버 사양을 가지고 있다.
따라서 bert모델을 통해서 답변을 받기까지 20분이 소요된다.
문제는 여러 클라이언트가 서버에 요청을 한다면 이 20분보다 더 소요된다. 또한 chatbot에게 가장 원하는 것은 사람한테 물어보는 것보다 더 빠른 답변 속도를 원하는 것이다.
bert모델이 무겁기 때문에 경량화에 대한 니즈가 강하다고 한다. 그래서 조사한 것에 따르면 bert보다 가벼운 여러 모델이 있었다.
- distilbert
- MobileBERT
- ELECTRA
이 3가지 모델을 알게 되었지만 아직 어떻게 적용해야할지 그 방법을 찾지 못했다. 저 3가지 모델 중에서 distillbert와 ELECTRA의 경우 한국어 버전이 존재하기 때문에 이 두개의 모델을 좀 더 연구해 봐야할 거 같다.
그래서 마지막으로 생각한 것이 Rull-based chatbot이다.
내가 직접 rull을 만들어서 하는 chatbot 모델 중 하나인데
일단 데이터가 엄청엄청 많아야 하기 때문에 데이터를 모으는 것에 집중해야 한다.
따라서 나는 데이터를 모으는데 집중하기로 했고 chatbot에 "바보: 이상한 질문을 받은 답변"을 입력하면 DB에 쌓이도록 구현했다.
느꼈던 것들
- java 코드에서 외부 python파일을 실행하기 위해서 ProcessBuilder를 이용했다.
- 당연하지만 몰랐던 것은 이 python파일은 jar파일 내부가 아닌 서버에 있어야 한다. 왜냐하면 jar파일은 압축 파일이기 때문에 이 내부에서 어떤 경로를 가지고 있는지 서버는 알지 못하기 때문이다.
- chatbot의 모델은 bert가 아닌 rull-based 기반으로 정한다. 왜냐하면 bert모델은 너무 무겁기 때문에 내가 사용하는 무료 서버에서 사용하기에는 답변 속도가 너무 느리다. 최소 20분 뒤에 답변이 온다.
- Rull-based의 경우 데이터의 양이 많아야 하기 때문에 사용자들로부터 데이터를 모으기로 한다. "바보: 이상한 답변을 받은 질문"을 사용자가 챗봇에 입력하며 이 데이터는 DB에 쌓이고 내가 DB를 보고 올바른 데이터를 입력해주는 방식으로 진행한다.
- 마지막으로 시도했지만 실패했던 AWS의 EC2를 대신해서 네이버 클라우드를 사용하지만 나중에 AWS를 다루는 방법에 대해서 더 공부해야 겠다.
- 또한 챗봇의 말풍선을 만들기 위해서 Ajax 적용하는 방법을 배우게 되었다.
완성
http://www.minwonchatbot.site/
회사에 배포했다!
