1. 학습 키워드
인덱스 활용, iloc, loc, 데이터 병합, 데이터 집계, 데이터 정렬
2. 학습 내용
저장하기
Unnamed 인덱스 없애기: index = False
df.to_csv('./newfile.csv', index = False)
불러오기
Unnamed 인덱스 없애기: index_col=0
df.read_csv('./newfile.csv', index_col = 0)
인덱스 활용하기
-
loc[]: 특정 인덱스의 행에 접근
row = df.loc['idx2'] -
sort_index(): 인덱스를 기준으로 데이터프레임 정렬
sorted_df = df.sort_index() -
set_index(): 특정 컬럼을 인덱스로 설정
df.set_index('컬럼명') -
.index: 인덱스 확인하기
#리스트 형태를 활용해서 인덱스를 새로 입력할 수 있음.
data.index = ['1번' , '2번' , '3번']- reset_index(): 현재 인덱스를 0부터 시작하는 정수로 변경
reset_index(): 기존 인덱스를 index라는 컬럼을로 만들고 새로운 인덱스 생성
reset_index(drop=True): 기존인덱스는 없애고 0부터 시작하는 새로운 인덱스 생성
컬럼
-
컬럼명 바꾸기: rename()
df.rename(columns = {'컬럼명': '바꿀명'}) -
컬럼 생성
df['스포츠'] = '축구' → 전부 '축구'로 채워진 컬럼 생성 -
컬럼 삭제
del df['컬럼명']
데이터 확인
- .head(): 기본 5개 출력
- .info(): 데이터프레임 정보 확인
- .describe(): 기초 통계 정보
- 결측치 확인:
.info()로 확인,df[df['B'].isna()]형태로 확인 - 데이터 타입:
df['A'].dtype,df.dtypes - 데이터 타입 변경:
df['A'].astype(str)
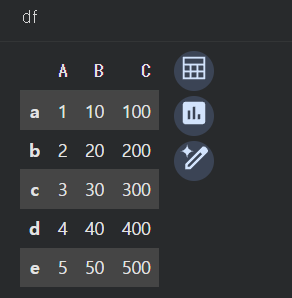
데이터 선택
iloc
df.iloc[0]
df.iloc[0:4]
df.iloc[0:7:2]
df.iloc[0::2] # 처음부터 끝까지 간격을 2로 해서 추출
df.iloc[0:2, 0:2] # 행, 열
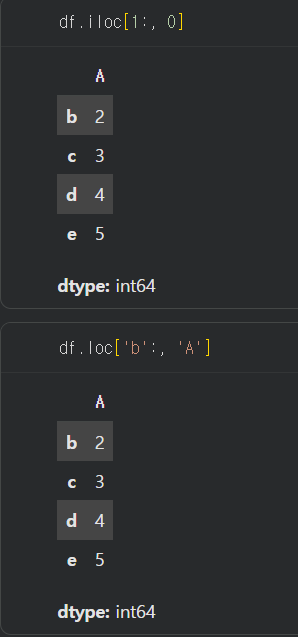
와 같은 형태로 사용함.loc
컬럼 명으로 선택을 함.
iloc는 슬라이싱할 때 1:3 이면 3은 포함되지 않지만 loc는 'a':'e'일때 e를 포함함.
불리언 인덱싱
단일 조건
df[df['age'] >= 30]여러 조건
# 'age' 열에서 30세 이상이면서 'gender' 열이 'Male'인 행 필터링 # or의 경우 | 사용 df[(df['age'] >= 30) & (df['gender'] == 'Male')]조건에 따른 특정 컬럼
# 'age' 열에서 30세 이상인 경우의 'name' 열만 선택 df.loc[df['age'] >= 30, 'name']
isin()을 활용한 필터링# 'gender' 열에서 'Male' 또는 'Female'인 행 필터링 df[df['gender'].isin(['Male', 'Female'])]
데이터 병합
concat
- pd.concat([df1, df2, df3]) : 기본값 axis=0 으로 위아래로 합침
- pd.concat([df1, df2, df3], axis=1) : 좌우로 병합
- ignore_index: 기본값은 False. True로 하면 index가 0부터 새롭게 생김.
pd.concat([df1, df4], ignore_index = True)
merge: sql의 join과 동일함.
merged_df = pd.merge(left_df, right_df, on='key', how='inner')
on: 병합 기준이 되는 열
how: inner, outer(합집합), left, right
데이터 집계
groupby
집계할 수 없는 컬럼들이 있다면 집계할 수 있는 컬럼만 슬라이싱 해서 진행.
import pandas as pd # 샘플 데이터프레임 생성 data = { 'Category': ['A', 'B', 'A', 'B', 'A', 'B'], 'Value': [1, 2, 3, 4, 5, 6] } df = pd.DataFrame(data) # 'Category' 열을 기준으로 그룹화하여 'Value'의 연산 수행 grouped = df.groupby('Category').mean() grouped_sum = df.groupby('Category').sum() grouped_count = df.groupby('Category').count() grouped_max = df.groupby('Category').max() grouped_min = df.groupby('Category').min() grouped_first = df.groupby('Category').first() # 첫번째 등장하는 애들만 표현하겠다.
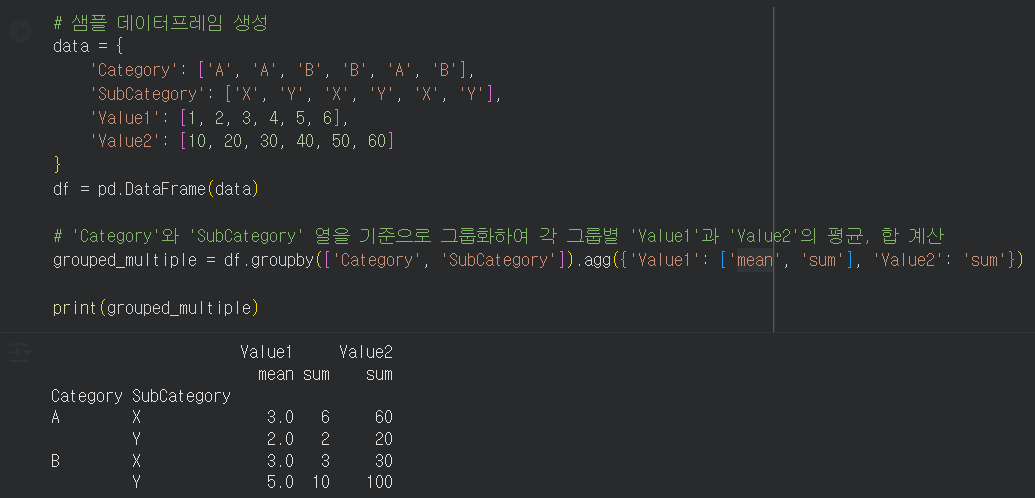
agg() 사용으로 여러 열에 대한 집계함수 적용.
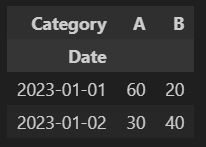
pivot_table
# 피벗 테이블 생성: 날짜를 행 인덱스로, 카테고리를 열 인덱스로, 값은 'Value'의 합으로 집계 pivot = df.pivot_table(index='Date', columns='Category', values='Value', aggfunc='sum')
데이터 정렬
df.sort_values('Score') # 'Score' 열을 기준으로 오름차순 정렬 df.sort_values('Score',ascending=False) # 'Score' 열을 기준으로 내림차순 정렬 df.sort_values(by=['Score', 'Age'], ascending=[True, False]) # Score 기준으로 오름차순 한 뒤에 Age 기준으로 내림 차순 정렬 df.sort_index() # 인덱스를 기준으로 오름차순 정렬
3. 배운점
- 이전에 알고 있던 것들을 복습해 보면서 loc와 iloc의 차이에 대해서 명확히 알 수 있었다.
- concat, merge의 차이도 명확하게 인지할 수 있었다. 그리고 groupby 사용할 때 마다 사용법을 헷갈리는 경우가 있는데 집계할 수 없는 열이 있으면 에러가 난다는 것을 인지 할 것.
