데이터분석 내일배움캠프 TIL
1.[사전캠프 TIL]#1 - 1일차(생각 정리)

데이터 분석 내일배움캠프 사전캠프를 시작했다.이미 이전에 데이터 분석 및 사이언스 부트캠프를 수강했는데 또 수강하는 이유와 생각을 정리해보려고 한다.내일배움캠프 수강 이유물론 취업이 쉽지 않은게 가장 큰 원인이다.지난 부트캠프 결과물을 보완하고 여러군데 지원해보면서 D
2.[사전캠프 TIL]#2 SQL 데이터 계산/가공/조건문

데이터 계산 및 가공sum, avg, count, min, max, replace, substring, concat\+, -, \*, /substring or substr붙일 수 있는 문자의 종류컬럼한글영어숫자기타 특수문자실습실습 이메일 도메인별 고객 수와 평균 연령
3.[사전캠프 TIL]#3 SQL subquery, join, coalesce, pivot table

subquery, join, coalesce: 쿼리 안에 select~from 으로 구성된 또다른 쿼리를 사용하는 것.서브쿼리가 필요한 경우여러번의 연산을 수행해야 할 때조건문에 연산 결과를 사용해야 할 때조건에 Query 결과를 사용하고 싶을 때→ 별도의 계산된 컬럼
4.[사전캠프 TIL]#4 SQL Window Function (RANK, SUM), 날짜 포맷(date, date_format), python 기초#1

Window Function (RANK, SUM), 날짜 포맷(date, date_format)Window Function 의 기본 구조argument : 함수에 따라 작성하거나 생략특정 기준으로 순위를 매기는 함수누적합을 구할때 주로 사용함.yyyy-mm-dd 형식의
5.[사전캠프 TIL]#5 set, map, lambda, filter, if/for문 한줄 표현, 클래스

파이썬 기본기: set, f-string, if/for문 한줄 표현, map, lambda, filter, 매개변수, 클래스중복을 제거하고 집합을 구현함. ex) a= 1,2,2,3일때 set(a)ex) print(f'{name}은 {score}점입니다')ex) for
6.[사전캠프 TIL]#6 통계의 종류와 모집단과 표본, 신뢰구간

통계, 데이터 분석 방법, 모집단과 표본, 신뢰구간, 표본 오차데이터를 요약하고 설명하는 통계 방법평균: 데이터의 대표값중앙값: 데이터를 크기 순서대로 정렬했을 때 중앙에 위치한 값분산: 데이터 값들이 평균으로부터 얼마나 떨어져 있는지를 나타내는 척도. 데이터의 흩어짐
7.[사전캠프 TIL]#7 통계학
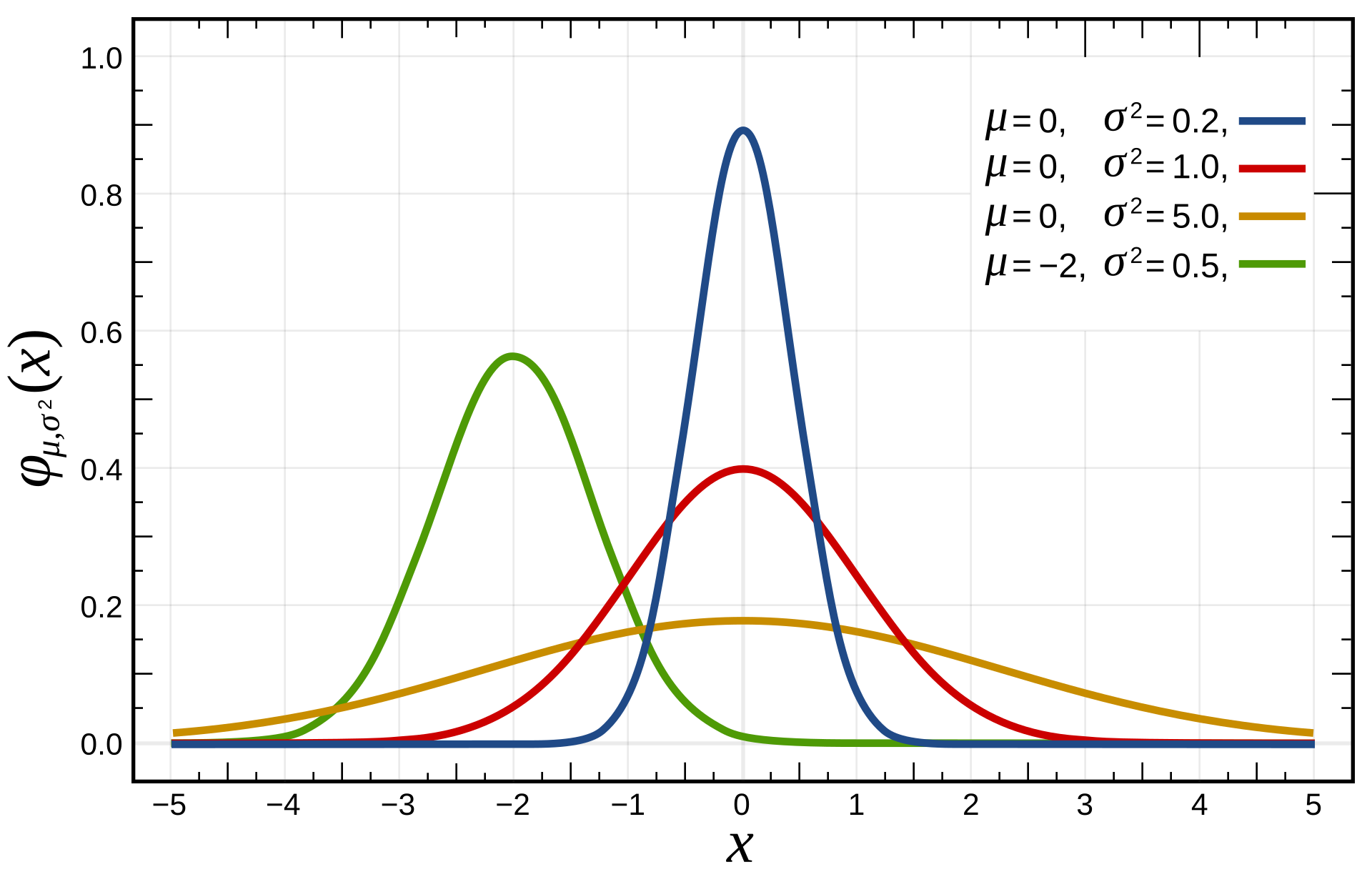
분포종류, 검정정규분포평균을 중심으로 좌우 대칭데이터가 충분히 많다면 정규 분포를 따름표준 편차는 분포의 퍼짐 정도By Inductiveload - 자작 (원문: self-made, Mathematica, Inkscape), 퍼블릭 도메인, https://co
8.[사전캠프 TIL]#8 통계학(2)
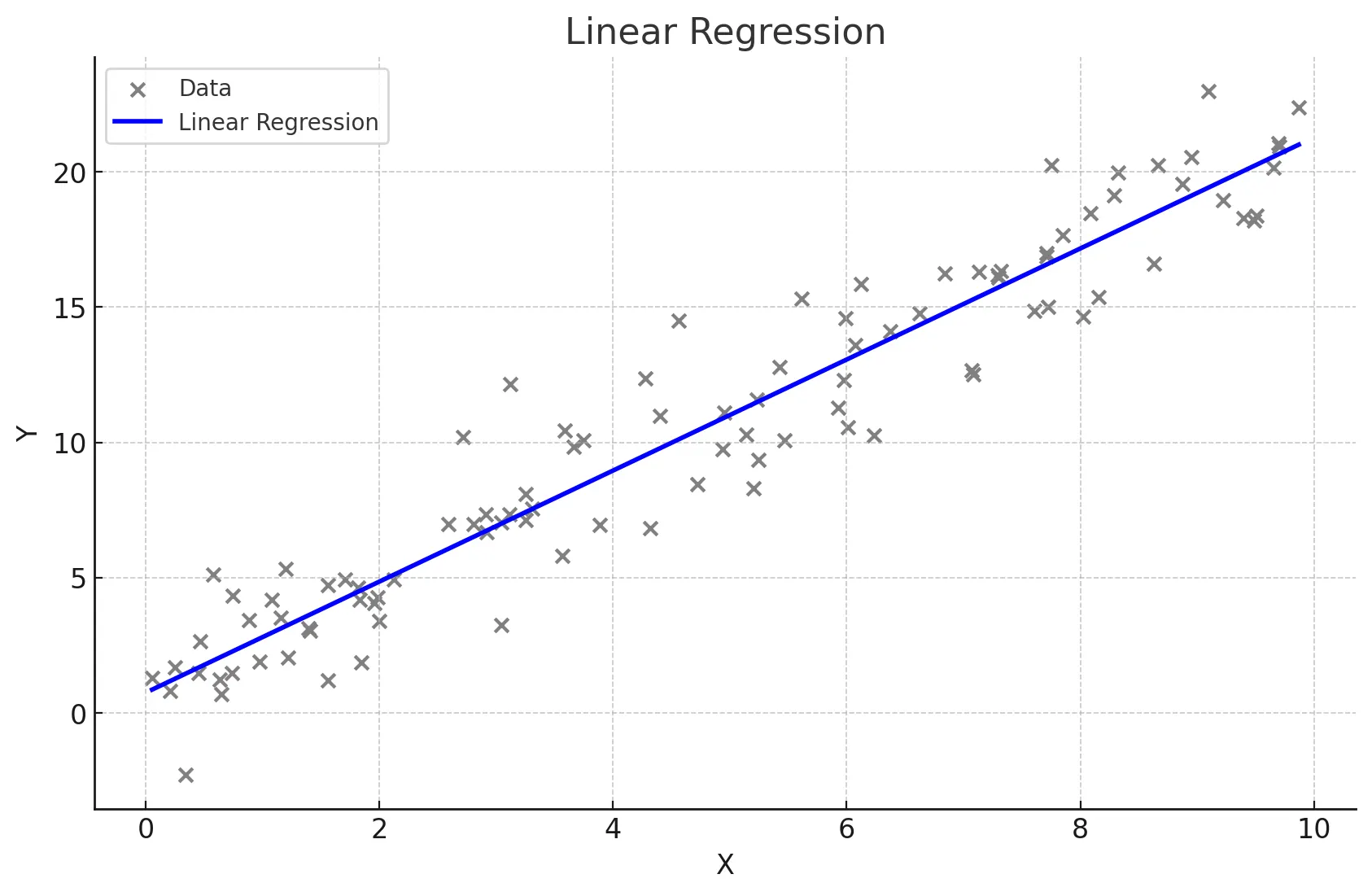
단순 선형 회귀, 한개의 변수에 의한 결과 예측(= 1차 함수)하나의 독립 변수(X)와 하나의 종속 변수(Y) 간의 관계를 직선으로 모델링하는 방법3\. 배운점
9.[사전캠프 TIL]#9 간단 퀴즈

메뉴 표시음료 선택(목록에 없는 경우 종료)지불 금액 입력(부족한 경우 부족하다는 메시지)잔액 확인컴퓨터가 랜덤으로 영어단어를 선택합니다.a. 영어단어의 자리수를 알려줍니다.ex) PICTURE = 7자리사용자는 A 부터 Z 까지의 알파벳 중에서 하나를 선택합니다.a.
10.데이터 분석 TIL - 데이터 리터러시(AARRR, 리텐션, LTV, Funnel)

데이터 리터러시데이터를 읽고 이해하고 분석하는 능력데이터 수집과 원천 이해데이터 활용법 이해데이터를 통한 핵심 지표 이해데이터 리터러시는 올바른 질문을 던질 수 있도록 만들어줌.심슨의 역설전체에 대한 결론이 언제나 개별 집단에 동일하게 적용되는 것은 아니다.데이터 분석
11.데이터 분석 TIL - 데이터 관련 직무 조사

데이터 분석가"설명 + 실행 제안"데이터 사이언티스트"예측 + 자동화/최적화 제안"과거/현재 데이터를 통해 비즈니스 문제를 데이터 기반으로 해석하고 제안함으로써 의사결정을 지원하는 역할핵심 질문"무엇이 일어났는가?", "왜 일어났는가?"하는 일현황 분석: 매출, 이탈
12.데이터 분석 TIL - 변수와 데이터 타입
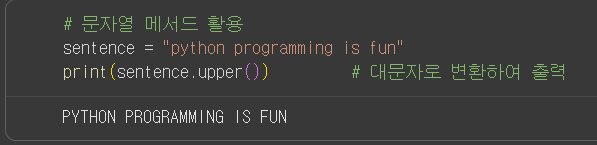
변수와 데이터 타입Numeric Type: integers(정수), float(실수), complex(복소수)DictionarySequence Type: list, tuple, stringsSetSequence Type: 순서대로 나열된 자료형. 문자형도 몇번째 글자인
13.데이터 분석 TIL - 데이터 분석 용어 정리

1. 학습 키워드 2. 학습 내용 데이터 분석가 주요 업무 데이터 분석가: 서비스의 현 상태를 파악하고 비즈니스 개선에 도움이 되는 인사이트 도출 데이터 추출: SQL, Python 등을 주로 활용 데이터 가공: 이상치 처리, 정합성 검증, (머신러닝/딥러닝 모델
14.데이터 분석 TIL - 리스트, 튜플, 딕셔너리

리스트, 튜플, 딕셔너리append(): 리스트에 항목을 추가합니다.extend(): 리스트에 다른 리스트의 모든 항목을 추가합니다.insert(): 리스트의 특정 위치에 항목을 삽입합니다.remove(): 리스트에서 특정 값을 삭제합니다.pop(): 리스트에서 특정
15.데이터 분석 TIL - 조건문, 반복문, while + MySQL cast

MySQL: cast파이썬: 조건문, 반복문, whilecast (값 as 타입변환) 형식으로 사용함타입변환 종류BINARY: 값을 binary로 변환CHAR: 값을 문자열로 변환DATE: 값을 yyyy-mm-dd의 date로 변환DATETIME: 값을 yyy-mm-
16.데이터 분석 TIL - 파일 불러오기/저장하기, 패키지 종류, 포맷팅

파일 불러오기, 파일 저장하기, 패키지 종류(csv, excel)과 json을 저장하는 방식이 다르다.exceljson pandas: 데이터를 효과적으로 조작하고 분석할 수 있도록 도와줌numpy: 다차원 배열과 행렬 연산을 지원함matplotlib: 데이터 시각화를
17.데이터 분석 TIL - 리스트 컴프리헨션, lambda, glob, os

리스트 컴프리헨션, lambda, glob, os리스트를 간결하게 생성하는 방법중의 하나조건문, 반복문을 사용해 리스트를 생성코드의 가독성을 높여줌ex)add = lambda x, y: x+ yprint(add(3, 5))square = lambda x: x\*\*2p
18.데이터 분석 TIL - split, join, 클래스, 불리언 인덱싱, 데코레이션
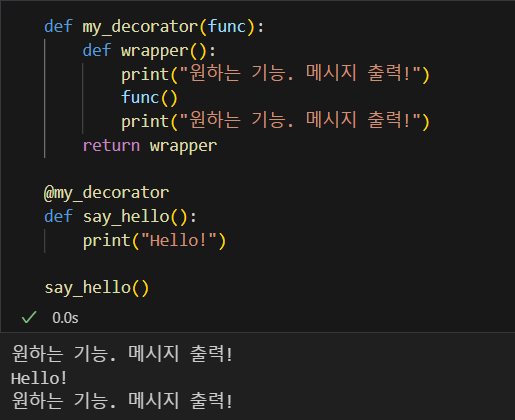
split, join, 클래스, 불리언 인덱싱, 데코레이션.split(): 문자열 공백을 기준으로 나누고 리스트로 반환.split('/'): / 를 기준으로 나누로 리스트로 반환.rsplit('/', 1): 오른쪽에서 1번째 / 를 기준으로 나눔..join(리스트):
19.데이터 분석 TIL - 데이터 전처리와 시각화, pandas란?
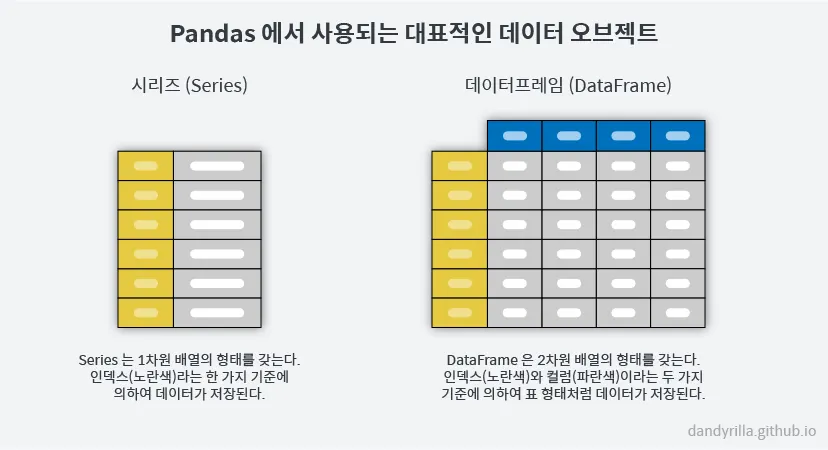
데이터 전처리, 시각화 기본, pandas란?시각화를 왜 하는가?설득하기 위해서 데이터를 시각화함데이터 전처리와 시각화는 왜 해야할까?데이터 전달의 목적성과 효과성을 위해서 (중요!)전처리를 하기 전에 어떻게 분석할 것인지 미리 설계해야 전처리 과정에서의 시행착오를 줄
20.데이터 분석 TIL - 인덱스 활용과 데이터 병합, 집계, 병렬
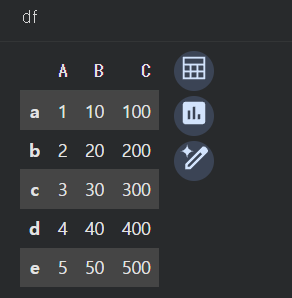
인덱스 활용, iloc, loc, 데이터 병합, 데이터 집계, 데이터 정렬Unnamed 인덱스 없애기: index = Falsedf.to_csv('./newfile.csv', index = False)Unnamed 인덱스 없애기: index_col=0df.read_cs
21.데이터 분석 TIL - sql윈도우함수, 파이썬 기초메모, 데이터시각화
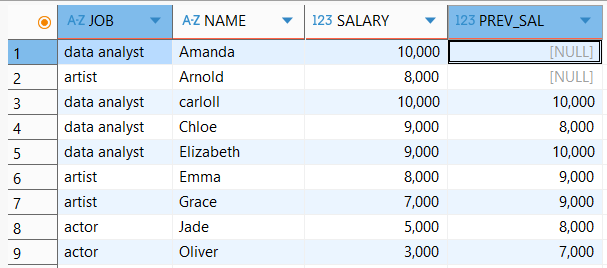
sql - 윈도우 함수파이썬 이론 메모데이터 시각화행과 행간의 관계를 정의하기 위해 사용함.일반적으로 단일 쿼리만 사용시 집계 함수를 사용한 다음에는 집계를 하지 않는 컬럼은 못가져온다. 그러나 윈도우 함수는 이를 가능하게함.ex) 국가별 연봉이 가장 높은 사람의 '성
22.데이터 분석 TIL - SQL 주요 함수 정리, 파이썬 별 피라미드 응용

SQL 주요 함수 정리, 파이썬 별 피라미드 응용🔥CONCAT: 문자열 병합🔥SUBSTRING: 문자열을 자를 때 사용🔥SUBSTRING_INDEX: 특정 구분 기호를 기준으로 문자열을 추출할 때REVERSE: 문자열을 뒤집는 함수LEFT, RIGHT: 문자열을
23.데이터 분석 TIL - 자꾸 잊어버리는 파이썬 기초 메모 glob, *args, **kwargs
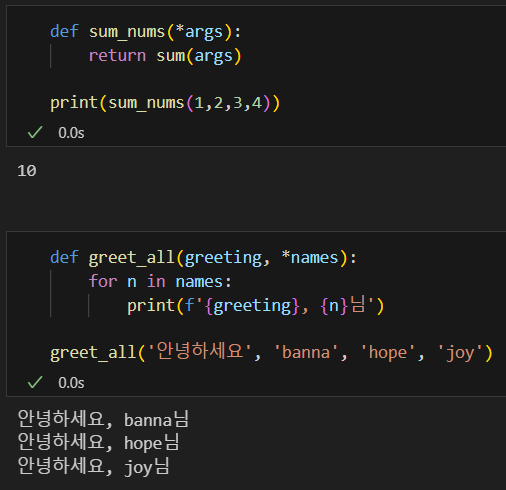
자꾸 잊어버리는 파이썬 기초: glob, \*args, \*\*kwargs전역 변수를 함수 내부에서 변경하고 싶을 때개수가 정해지지 않은 인자를 받을 때ex) 2개를 더하든 10개를 더하든 입력받은 인자를 모두 더하고 싶을때\*args는 인자를 하나의 튜플 형태로 받음
24.데이터 분석 TIL - sql join 방식의 습관 차이가 협업에 도움이 될까?
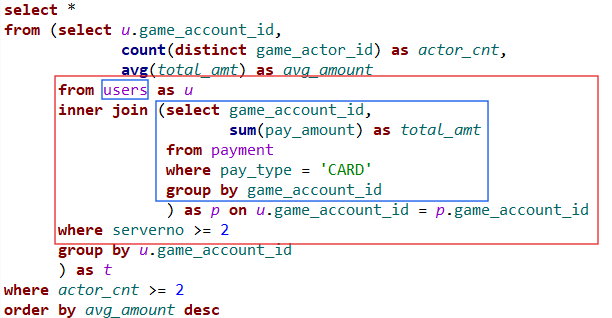
1. 학습 키워드 sql join 방식의 습관 차이 2. 학습 내용 sql join 방식의 사소한 습관 차이 > 오늘은 sql에 대한 복습과 사소한 습관 차이를 기록하려고 한다. 나는 그동안 특별한 경우가 아니면 join을 먼저 한 후에 조건에 맞는 필터를 걸어주는
25.데이터 분석 TIL - 파이썬 기본의 익숙함과 응용의 중요성
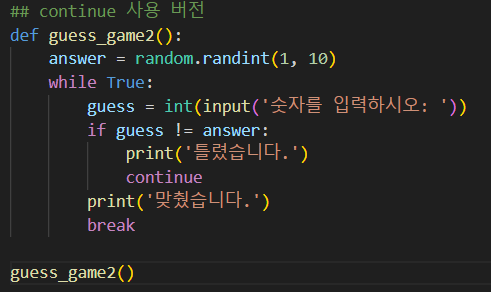
함수 정의 실습 메모바로 생각 안났던 \*args, join초급 수준의 기능이나 함수도 자주 사용하지 않거나 응용하는 습관을 안 들이면 머리가 굳어버린다.: break와 continue를 사용해 동일한 기능을 하는 함수를 다르게 표현해보려고 한다.사용자로 부터 숫자를
26.데이터 분석 TIL - 컴프리헨션과 예외처리
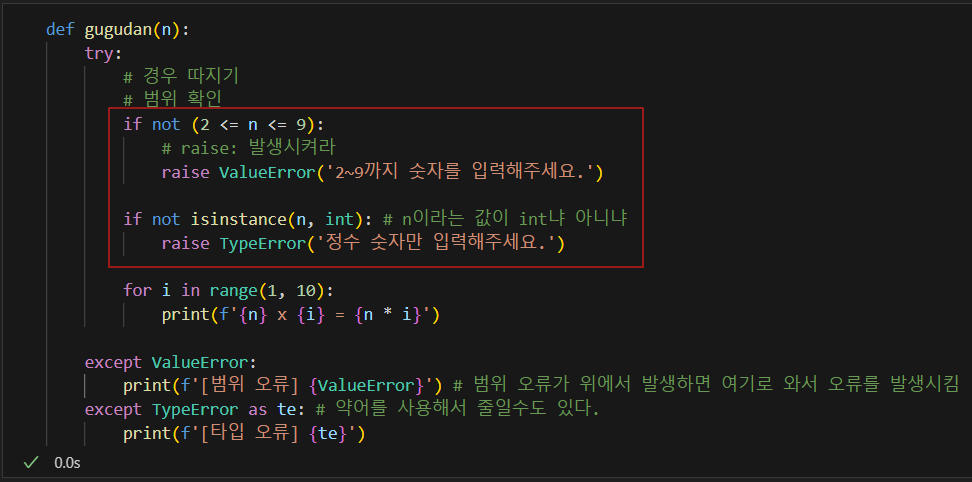
컴프리헨션예외 처리(raise 사용)반복문을 한줄로 줄이는 문법(for문을 짧고 간단하게 쓰는 방법)파이써닉(파이썬 활용시 깔끔하고 읽기 좋은 코드로 작성)을 위해 사용정석적인 for 문 사용보다 코드 실행 속도가 더 빠름무조건 좋은 것이 아니라 컴프리헨션 사용으로
27.데이터 분석 TIL - 표준 라이브러리와 파일 입출력(읽기/쓰기)
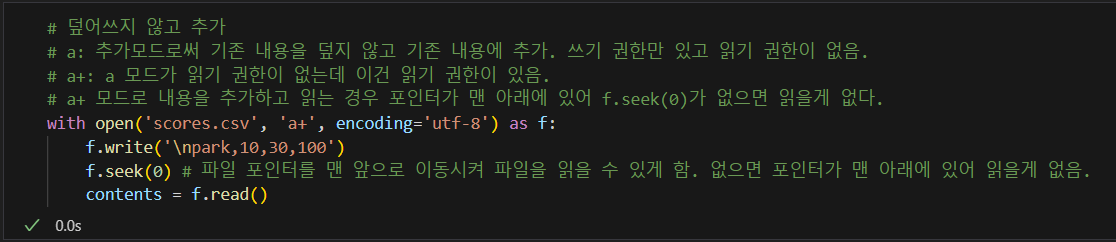
표준 라이브러리 활용파일 입출력date.today(): 오늘 날짜time(14, 30, 0): 시간으로 표현 ex) 14:30:00datetime.now():현재 시간🔥timedelta(days=7, hours=3): 7일 + 3시간 시간차. 데이터 분석에 자주 사용
28.데이터 분석 TIL - 입문자를 위한 데이터 분석 미니 사이클 실습
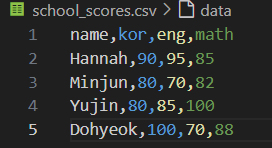
데이터 분석 미니 사이클 실습데이터 불러오기전처리데이터 분석(평균, 합격)예외 처리출력 데이터 분석 과정에서 수행되는 업무의 사이클을 간단한 데이터와 함수 구현을 통해서 진행해본 내용을 작성하고자 한다.students에는 {'name': 'Hannah', 'kor':
29.데이터 분석 TIL - 라이브러리와 EDA(%%time, isna, iloc, groupby 등)

1. 학습 키워드 라이브러리와 EDA 2. 학습 내용 EDA 탐색적 데이터 분석 이상치 결측치 시각화 주요 라이브러리 pandas: 데이터프레임을 만들 때 사용 numpy: 리스트를 확장한 다차원 배열을 제공하며 통계 분석을 지원함. matplotlib, seabo
30.데이터 분석 TIL - 파이썬 데이터 결합(merge, concat, pivot table, rrule, strftime)
파이썬 데이터 결합mergeconcatpivot tablerruleSQL의 join과 유사. 공통 컬럼을 기준으로 테이블 병합.주요옵션(파라미터)on: 조건 컬럼(한개 or 여러개)how: 어떤 조인 방식을 사용할 것인지(inner, outer, left, right)
31.데이터 분석 TIL - 이상치와 결측치 처리
이상치, 결측치이상치: 명확한 기준은 없지만 일반적인 데이터들과 달리 매우 크거나 작은 값결측치: 데이터 수집 과정에서 측정되지 않거나 누락된 데이터결측치 처리에는 두가지 방법이 있다.제거 or 대체. 그렇다면 제거하는 것이 좋을까? 대체하는 것이 좋을까?결측치를 갖고
32.데이터 분석 TIL - 시각화 실습 메모
1. 학습 키워드 2. 학습 내용 오늘 내용은 코드 공부나 기술의 내용보다 시각화 실습을 진행 하면서 간단히 메모해두고 싶은 내용을 정리하고자 한다. seaborn 그래프의 종류 distplot: 분포 그래프 countplot: 범주형 변수의 발생 횟수를 세어주는
33.데이터 분석 TIL - 기초 프로젝트 주제 선정

기초 프로젝트 주제선정발표날짜를 제외하면 약 1주일 이라는 짧은 기간 동안 프로젝트를 진행한다. 총 7가지의 주제 중에서 한가지를 선택하기 위해 팀원 각자가 주제에 대해 생각해보고 의견을 모았다.5명의 팀원이 개인당 2~3개의 주제를 선택해왔는데 거의 모든 주제의 득표
34.데이터 분석 TIL - 프로젝트 데이터 전처리 규칙 통일화 회고

데이터 전처리 규칙 통일화EDA를 진행함에 앞서 데이터 전처리가 정말 중요하다팀원 각자가 우선 데이터를 바탕으로 EDA를 진행하기로 했다. 하지만 이 과정에서 들었던 생각이 EDA를 진행하는 데이터의 통일성이 없으면 똑같은 분석을 하더라도 다른 결과가 나올 것이라고 생
35.데이터 분석 TIL - EDA 분석 상황 공유

각자 데이터 분석 진행 상황 공유부동산 실거래 데이터를 기반으로 전반적인 경향과 특수성을 찾기 위해 여러가지 관점에서 EDA를 진행하고 있다. 회사처럼 분명한 문제 상황이 이미 발생한 상황이라면 거기에 초점을 맞추면 되지만 우리가 분석하고자 하는 데이터가 어떤 문제와
36.데이터 분석 TIL - 논의는 매번 어렵다

기준 지표 정하기회사 생활 뿐만 아니라 팀 프로젝트를 함에 있어서도 언제나 항상 의견을 하나로 모으는 것이 정말 어렵다.어떠한 방법으로 팀의 협업을 이끌었는가?어떠한 방법으로 의견을 하나로 모았는가?매번 느끼는거지만 정답이 없다. 면접을 준비하는 상황에서는 마치 정답이
37.데이터 분석 TIL - 이게 분석 프로젝트가 맞는 것인가?
매물 추천 실행분석했던 결과?를 바탕으로 매물추천하는 방향성에 대해서 논의를 했다. 어렵게 저녁 9시가 지나고 나서 갑자기 생각이 들었다.이렇게 하는게 맞나?어느 순간 우리의 결과는 필터링만 하면 끝나는 프로젝트가 됐다.사실 그 이전에 어떤 인사이트가 있는지 혹은 타겟
38.데이터 분석 TIL - 기초 프로젝트 마무리 단계
프로젝트 마무리프로젝트 마무리 단계에서 방향성 설정이라는 말이 참 아쉬운 말이다. 튜터님이 우리가 정한 주제나 방향에 대해 이상하지 않고 그대로 분석을 진행하면 된다고 하셨지만 표현하기 어려운 여러 부분들이 있다.나는 프로젝트의 방향이 완전히 잘 못 됐다고 뒤늦게 생각
39.데이터 분석 TIL - 기초 프로젝트 회고

프로젝트가 마무리 됐습니다. 개인적으로는 너무나 아쉬운 프로젝트가 됐네요. 특히나 너무나 잘한 다른 팀들을 보면 부럽기도 하고 아쉬움도 남고 후회도 남는 프로젝트였습니다.나의 부족함이 뭘까? 어떻게 했어야 할까? 앞으로는 어떻게 해야 할까? 참 많은 생각과 고민이 남았
40.데이터 분석 TIL - 기초프로젝트 보완 계획 정리

기초 프로젝트 보완 방향 고민오늘은 캠프에서 밍글데이를 진행했다.오전에 다음 학습과 프로젝트를 위해 학습한 내용에 대한 테스트를 진행한 뒤에 오후에는 기초 프로젝트가 끝난 기념으로 분위기 전환도 하면서 학습 이외의 퀴즈도 풀고 사연에 대한 공유도 하면서 휴식하는 분위기
41.데이터 분석 TIL - 데이터프레임 핸들링(melt, stack, unstack)
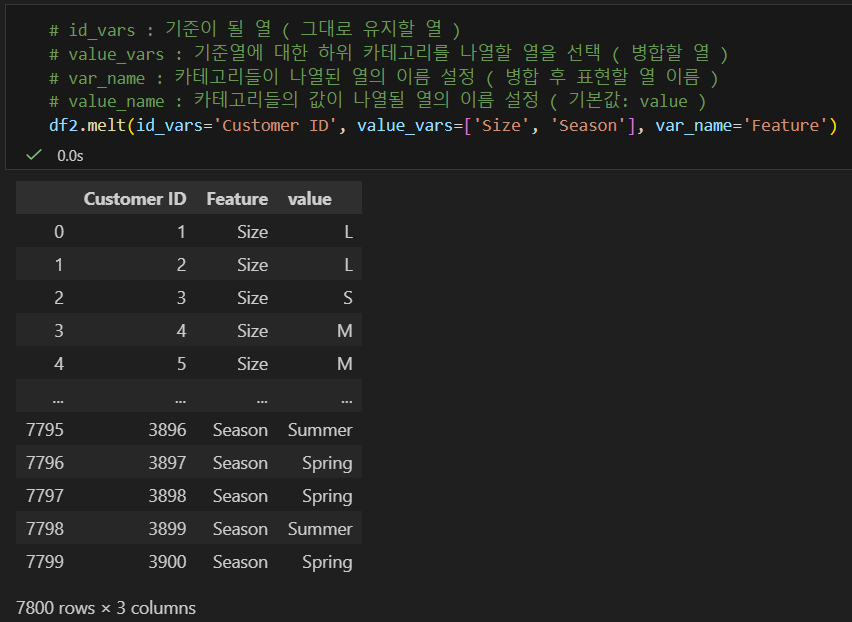
데이터프레임 핸들링transpose, pivot table, melt, stack, unstackwide format: 측정값을 모두 한 행에 표시. 열 이름으로 그 측정값의 의미를 나타냄long format: 긴 형식. 하나의 관찰값이 하나의 행에 위치행렬 전환데이터
42.데이터 분석 TIL - 머신러닝, 통계 세션 메모
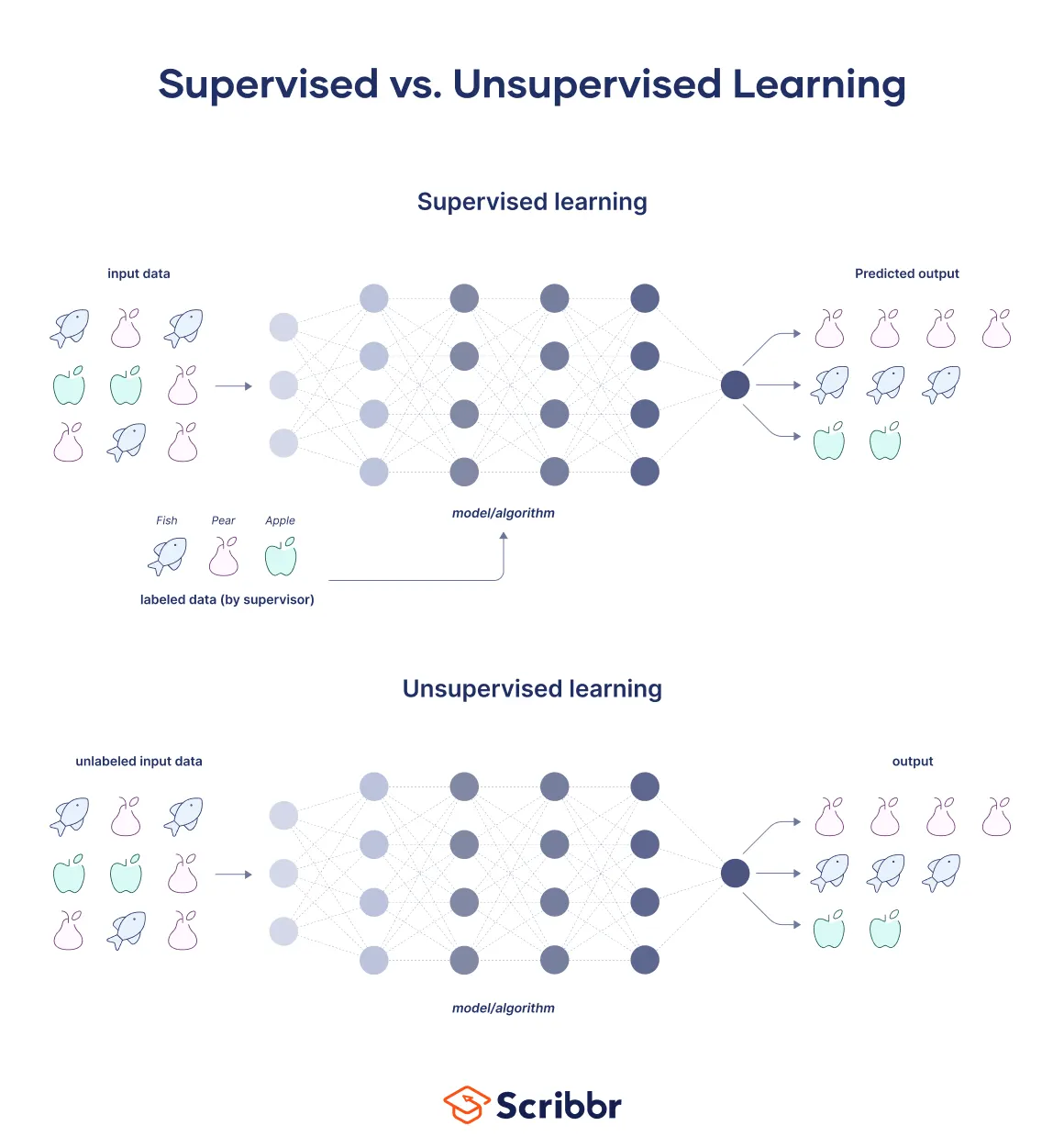
1. 학습 키워드 머신러닝 2. 학습 내용 머신러닝 머신러닝 AI를 실현하기 위한 방법중 하나. 데이터로 부터 특징이나 규칙을 찾아내서 학습하는 것 ex) 스팸 메일에 특정 단어나 형태가 자주 등장하는 공통점(패턴)이 있을 수 있는데 이를 자동으로 스팸으로 분류 딥
43.데이터 분석 TIL - 머신러닝을 위한 데이터 전처리, 시계열을 다루기 위한 함수(shift, rolling, expanding), 통계 세션 p-value
1. 학습 키워드 머신 러닝을 위한 전처리 파이썬 윈도우 함수 2. 학습 내용 데이터 전처리 > 데이터 전처리 원시(raw) 데이터에서 불필요하거나 손실(노이즈)이 있는 부분을 처리하고, 분석 목적에 맞는 형태로 만드는 과정 필요성 모델 정확도 및 신뢰도 향상 이상
44.데이터 분석 TIL - 가설검정(t-검정, z검정, 카이제곱)과 연속형/범주형 변수의 상관관계
가설 검정의 종류상황에 따라 다르게 사용하는 검정 방법연속형 변수와 범주형 변수의 상관관계 구하는 함수가설을 검정하는 방법은 여러가지가 있다. 연속형 데이터를 비교할 때, 범주형 데이터를 비교할 때 사용하는 검정의 방법이 다르며 비교하고자 하는 집단의 수에 따라서도 다