선형검색
선형으로 나열되어 있는 데이터를 순차적으로 스캔하면서 원하는 값을 찾는다.
- 반복문 돌리면서 찾는것과 같음
보초법
마지막 인덱스에 찾으려는 값을 추가해서 찾는 과정을 간략화 한다.

(실습 문제가 쉬워보이지만 헷갈리는 부분이 있어 좋은 문제라고 생각함.)
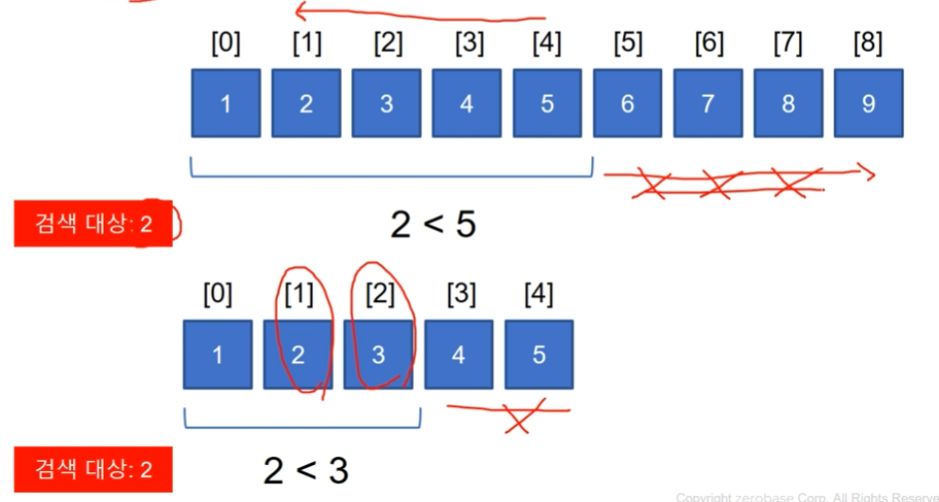
이진검색
- 정렬되어 있는 자료구조에서 중앙값과의 크고 작음을 이용해서 데이터를 검색한다.
- 이진검색은 정렬이 되어있는 상태에서 진행한다.
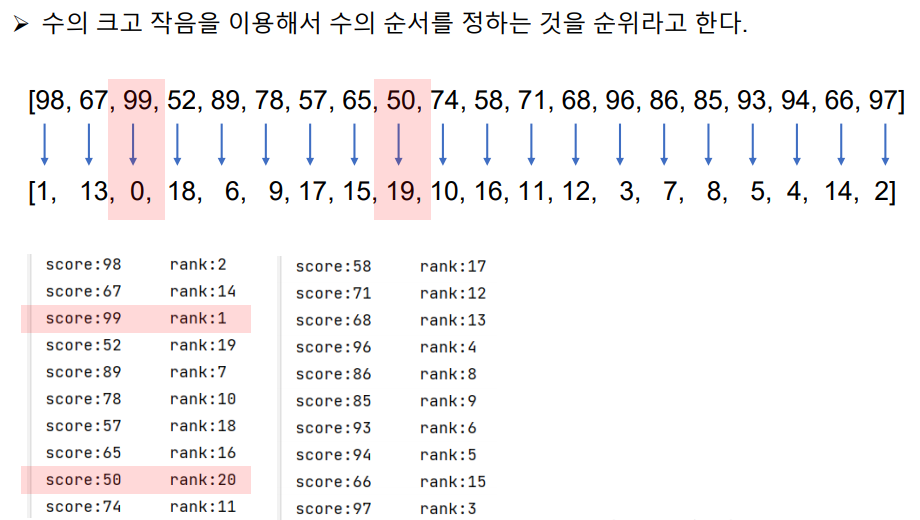
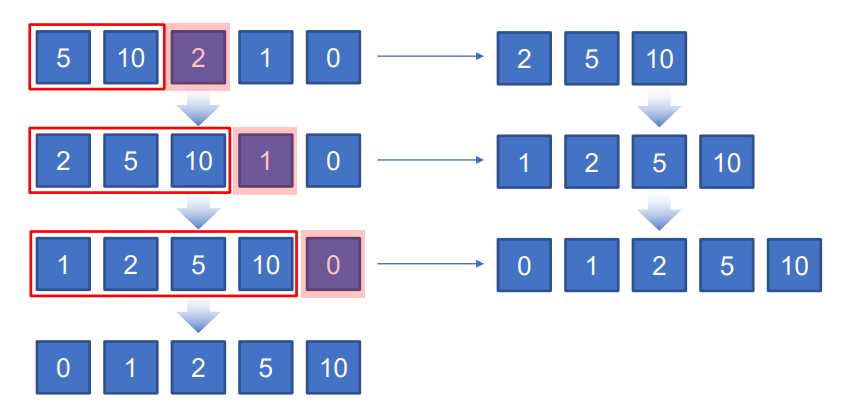
순위
각 값들을 하나씩 비교해서 지면 인덱스 값을 1 올려줌. 그러면 최종적으로 전부 진 값은 인덱스가 가장 마지막 인덱스 값을 갖게되고 모두 이긴 값은 인덱스 값이 0인 상태로 존재함.
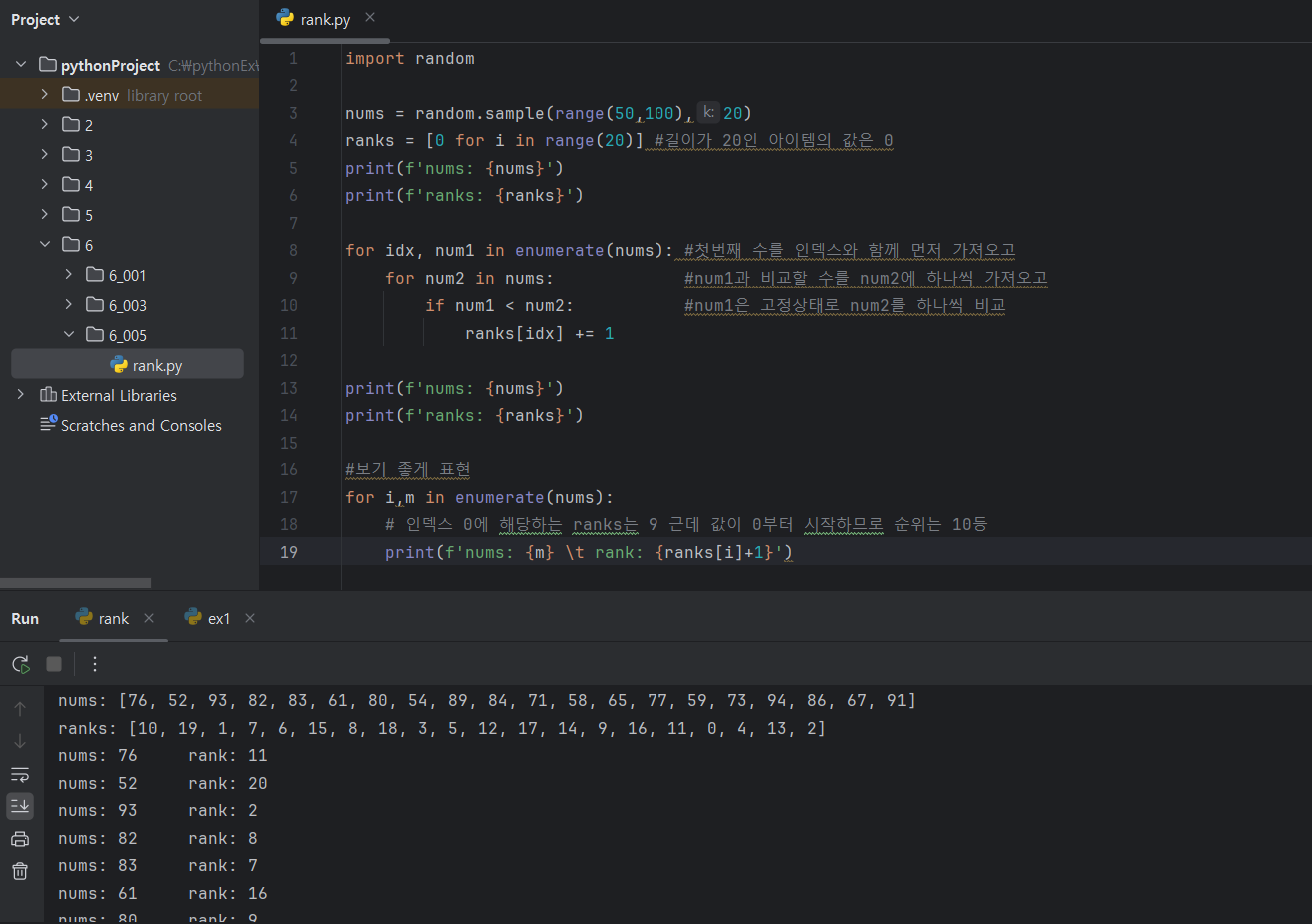
range() 헷갈려서...

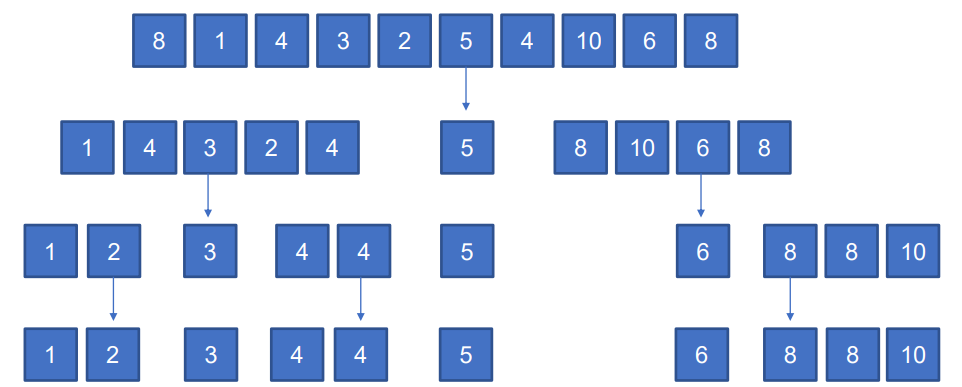
버블정렬

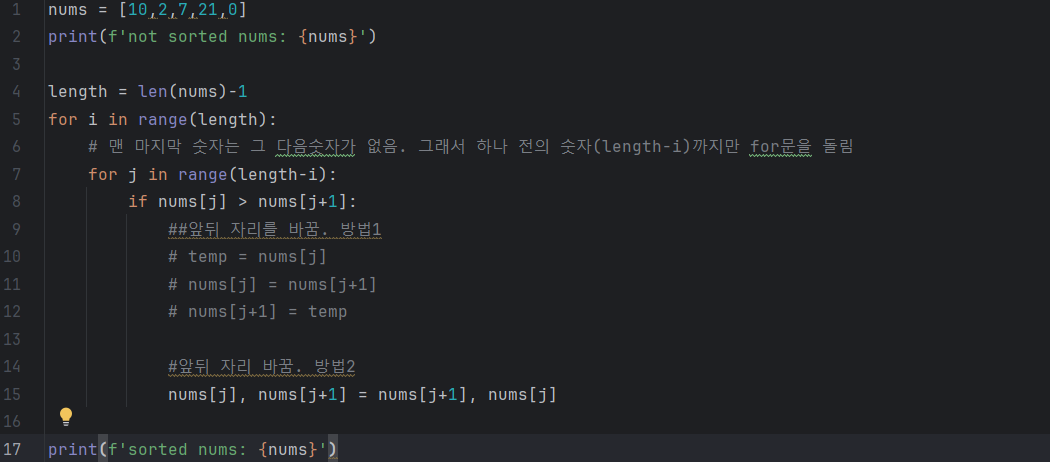
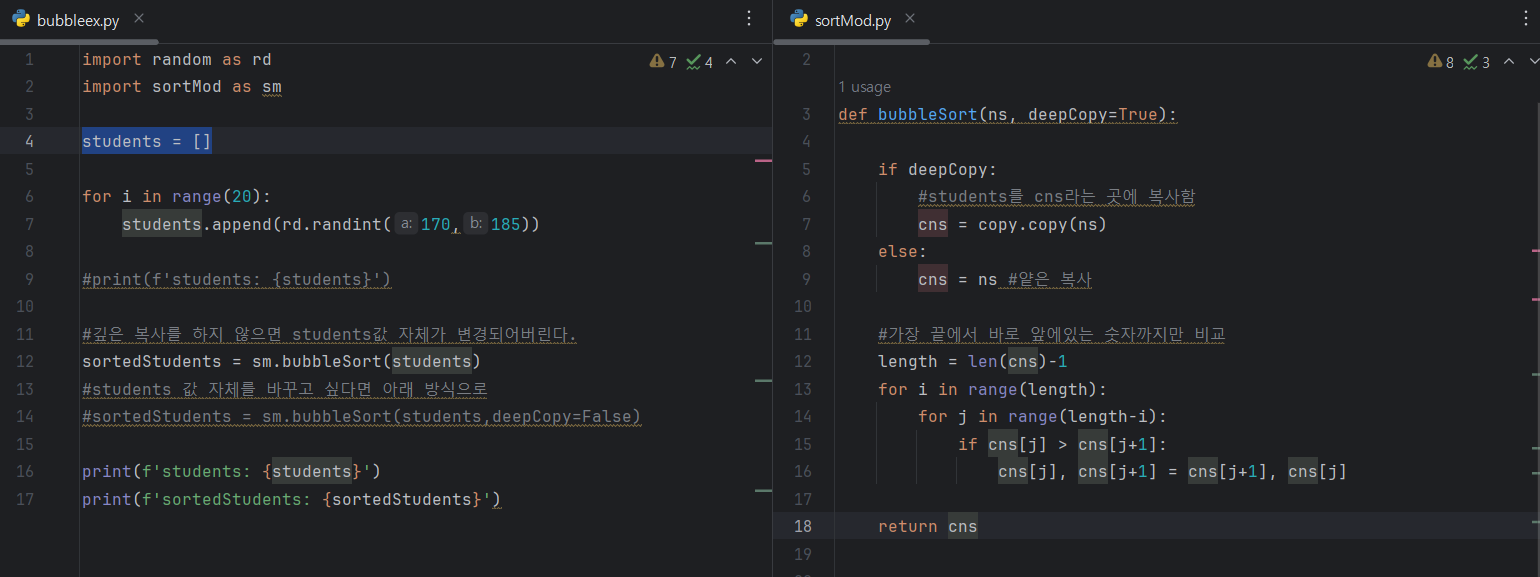
깊은 복사를 사용한 정렬
삽입정렬(이해하기 어려움)
와우~ 뭔가 어렵지 않은듯 하면서 어려움.
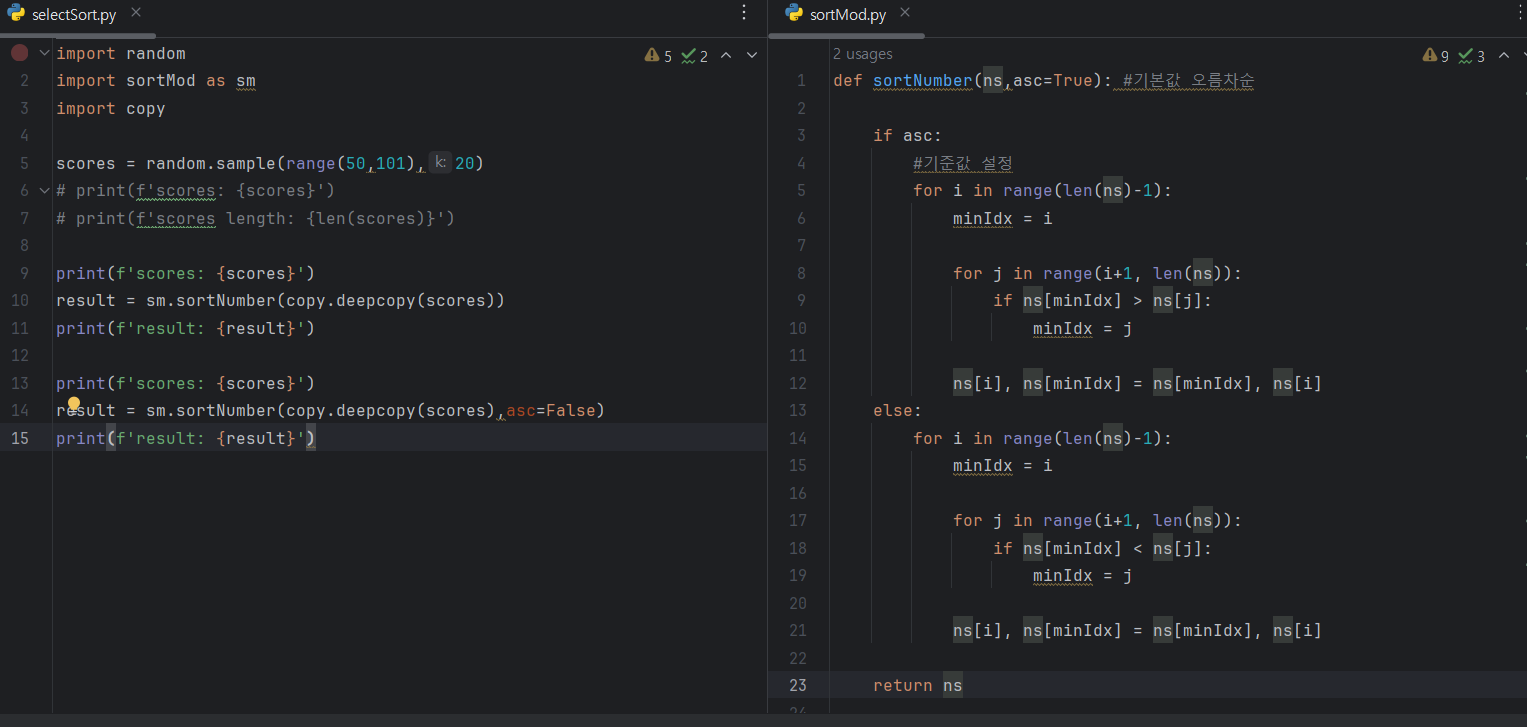
정렬되어 있는 자료 배열과 비교해서, 정렬 위치를 찾는다.
선택정렬
- 기준값(맨 앞의 값)을 제외하고 최소값을 찾는다
- 최소값과 맨앞의 숫자(기준값)와 바꾼다
- 맨앞을 제외한 나머지 숫자를 가지고 똑같은 방식을 진행한다.
- 두번째 숫자까지 진행됐으면 나머지 숫자로 동일한 방식 진행.
- 반복

자리바꾸는 간단한 방법 중 하나
ns[i], ns[minIdx] = ns[minIdx], ns[i]
깊은 복사를 사용한 또다른 방법
최댓값
- 파이썬에서 기본으로 제공하는 max() 함수도 있지만 직접 알고리즘을 만들어 보자.
- 초기 최대값을 숫자 리스트 인덱스 0인 값으로 설정 후 리스트의 다른 숫자가 설정한 최대값보다 큰 경우 해당 숫자로 최대값 변경
최솟값
- 초기 최대값을 숫자 리스트 인덱스 0인 값으로 설정 후 리스트의 다른 숫자가 설정한 최대값보다 작은 경우 해당 숫자로 최대값 변경
cf) 특정 문자를 아스키코드로 변환하는 함수 ord(문자)
최빈값
데이터에서 빈도수가 가장 많은 데이터
- 0부터 배열에 있는 숫자 까지의 개수만큼 아이템이 0인 indexes라는 배열을 만든다.(5까지 있으면 0이 6개인 배열을 만듬)
- 원래 배열의 숫자 값을 인덱스라고 생각하고 indexes 배열에 해당 인덱스에 해당하는 자리에다가 1씩 더한다.(원래 배열의 값이 3이면 indexes[3]에 +1)
- 그 뒤에 최대값 알고리즘으로 indexes에서 가장 큰 값을 찾은뒤 해당 값의 인덱스를 역으로 구한다.
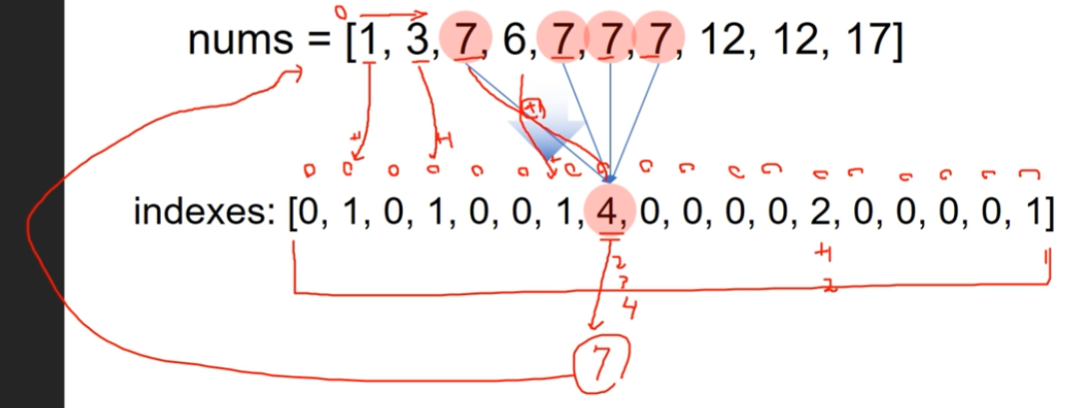
요약
최빈값을 구하고자 하는 배열의 값을 인덱스로 생각하고 해당 값을 인덱스로 하는 새로운 배열을 만든다. 그리고 그 빈도수 만큼 더한다.
그 뒤 새로운 배열의 최대값을 찾고 이 최대값의 인덱스를 역으로 구하면 원래 배열의 값이 되고 이 최대값은 빈도수가 된다.
근사값
특정 값(참값)에 가장 가까운 값을 근사값이라고 한다.

평균
여러 수나 양의 중간값을 갖는 수
평소 평균 구하듯이 하면 된다.
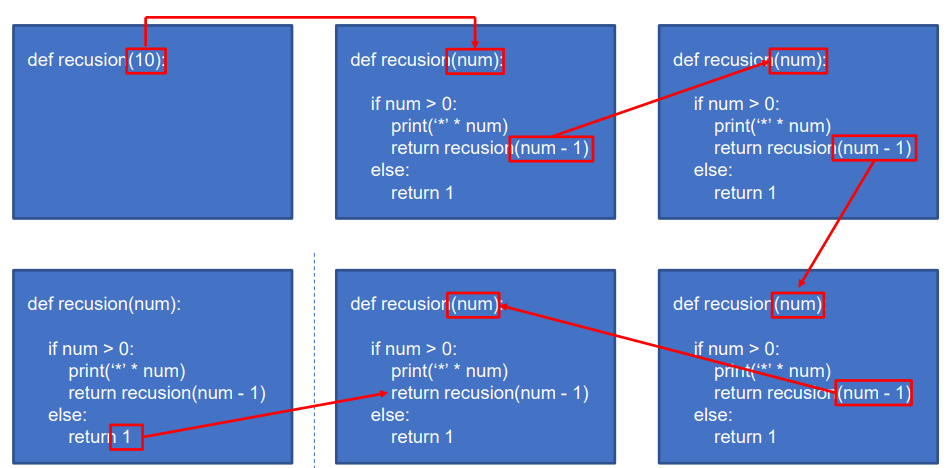
재귀 알고리즘
나 자신을 다시 호출하는 것을 재귀라고 한다.
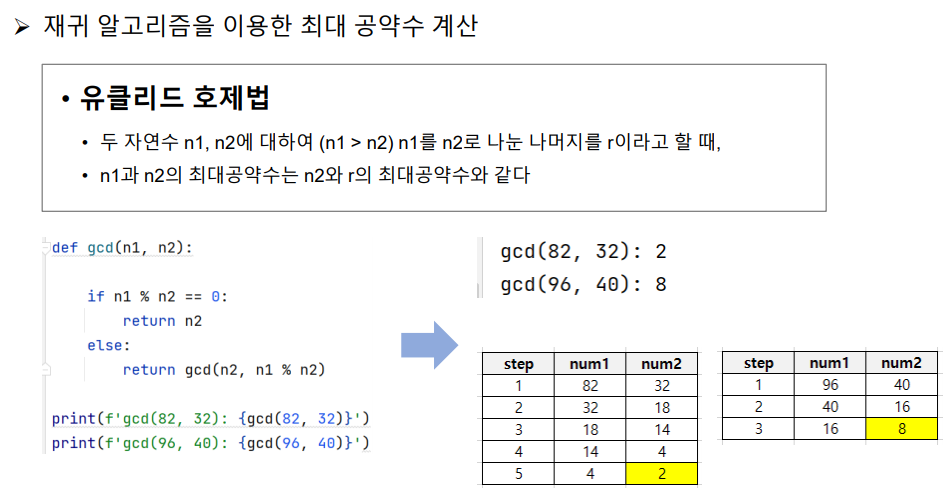
재귀함수의 대표적인 것인 팩토리얼이다.
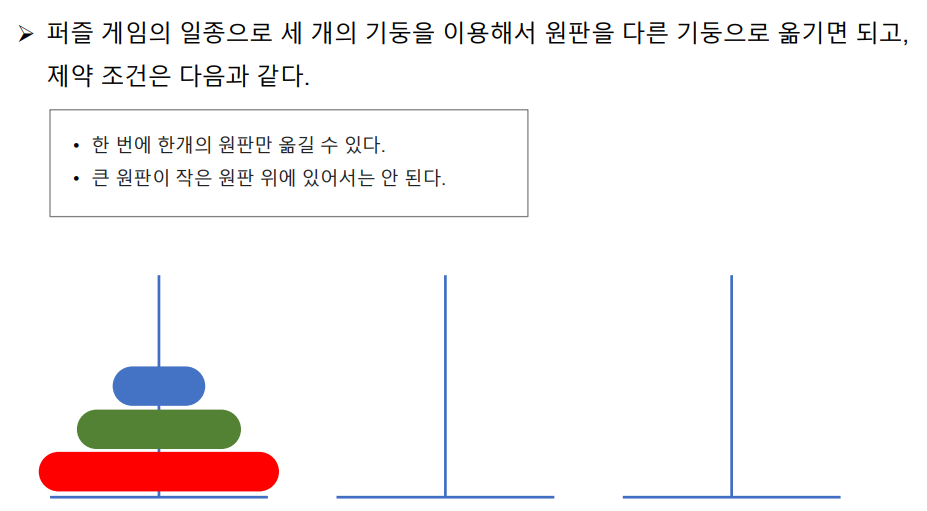
하노이의 탑
재귀함수와 같다.
알고리즘문제 단골
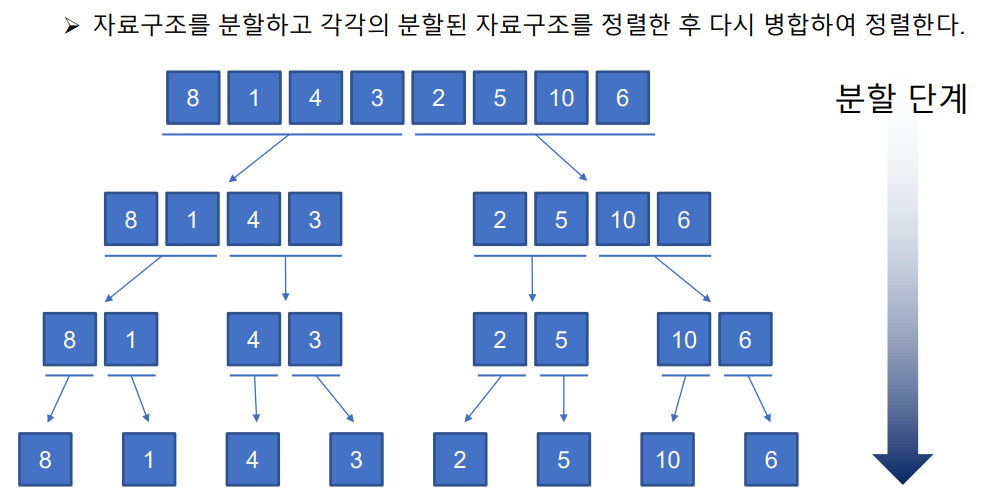
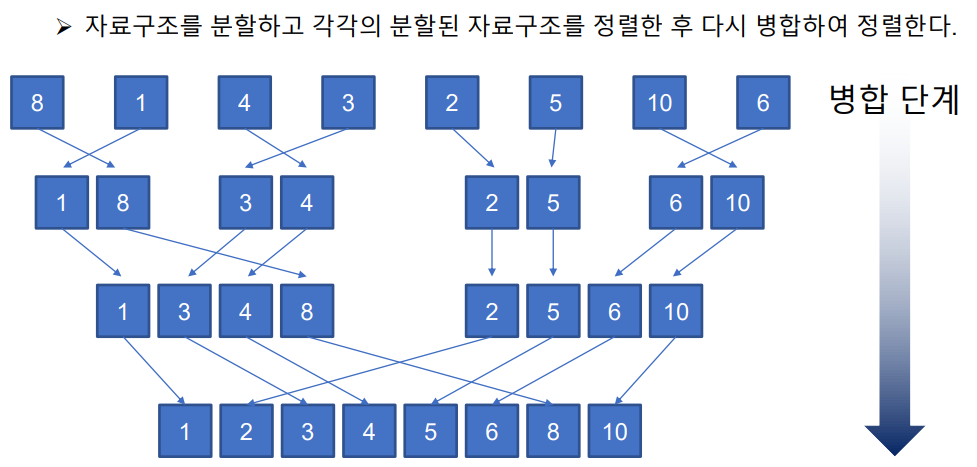
병합정렬
다시 병합할때 가장 작은숫자부터 나열한다.
퀵정렬
기준 값보다 작은 값과 큰 값으로 분리한 후 다시 합친다.
재귀함수 활용.