제로베이스 데이터 스쿨(Data Science & Analytics)
1.데이터 취업 스쿨 스터디 노트 - OT

6월부터 시작하는 제로베이스 데이터 스쿨 28기가 시작됐다.입과 계기이전에 PM/PO 업무를 하면서 서비스를 계획하고 관리하는 업무보다 데이터를 처리하고 보는 업무가 나와 더 맞다고 느꼈다. 부트캠프를 통해 포트폴리오를 만들고 직무 전환을 하기위해 신청했다.각오, 다짐
2.데이터 취업 스쿨 스터디 노트 -(1) 파이썬 변수선언/데이터타입
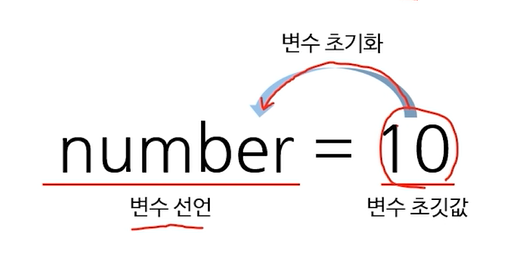
\*pycham에서 ctrl+c & ctrl+v -> ctrl+d로 쉽게 대체할 수 있다.변수: 데이터가 저장된 메모리 공간변수명: 변수의 이름(주소)\*변수는 데이터를 재사용하기 위해서 사용한다.변수 두개 이상 사용시 '콤마'를 사용한다.숫자는 사용가능하지만 첫번째에
3.데이터 취업 스쿨 스터디 노트 -(3) 반복문 for, while

for문을 주로 사용함for문에도 pass 사용 가능.실행문이 정해지지 않았다면 pass 사용하면 됨.range(시작,끝,단계)단계가 1씩 증가하는 경우 생략 가능함.ex) range(2,11)단계가 1일때 시작이 0인 경우 생략 가능함.ex) range(10)
4.데이터 취업 스쿨 스터디 노트 -(2) format, 연산자, 조건문

데이터 입력 input() ex) userInputData=input('데이터 입력해라!') input으로 받은 데이터는 전부 str(문자형) 정수형으로 받고 싶으면 int(input())의 형태를 사용 ex) 데이터 출력 print()함수는 기본적으로 자동 자동
5.데이터 취업 스쿨 스터디 노트 -(4) datetime, isdigit

: datetime: len()특정문자열의 위치를 찾음: find()첫번째 위치는 '0'이다.cf) input() 함수 사용시 사용자한테 입력받은 것은 전부 문자이다. 그래서 int 같은것으로 변환을 해줘야함.ex) int(input())
6.데이터 취업 스쿨 스터디 노트 -(5) 문제풀이 + QUIZ 메모
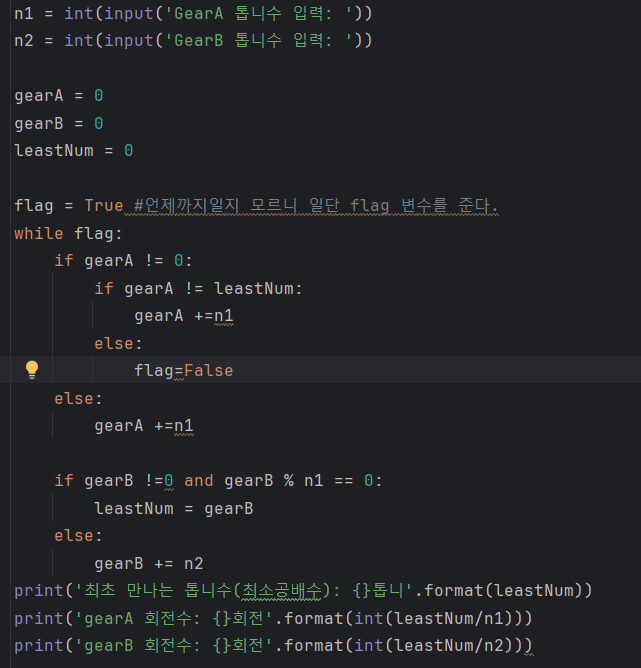
몫을 구하는 모듈ex) operator.floordiv(5,2) -> 2나머지를 구하는 모듈ex) operator.mod(5,2) -> 1
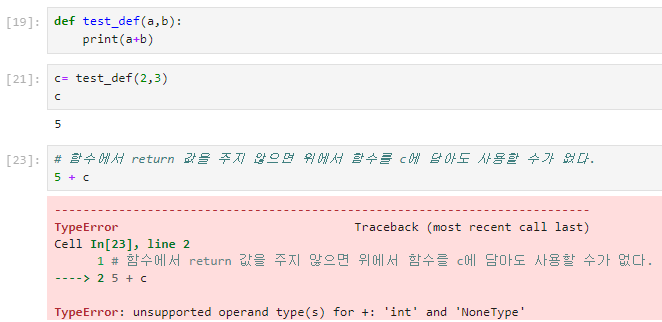
7.데이터 취업 스쿨 스터디 노트 -(6) 함수, return, 모듈

파이썬의 함수는 수학의 함수와 동일하다.
8.데이터 취업 스쿨 스터디 노트 -(7) 객체지향, 클래스, 복사, 상속, 오버라이딩, 예외처리
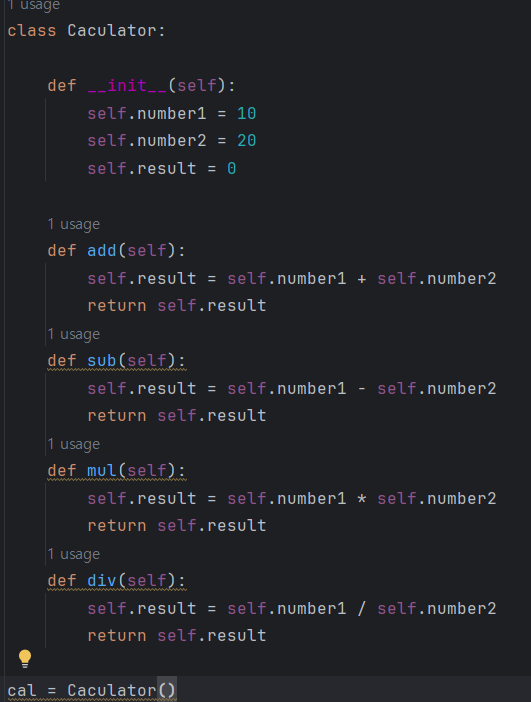
객체지향 프로그래밍 객체를 이용한 프로그램으로 객체는 속성과 기능으로 구성된다. 객체의 의미를 프로그래밍으로 가져와서 프로그램으로 만듬. > 계산기 > 자동차 객체 만들기(생성) 클래스는 객체를 만들기 위한 하나의 틀이다. 클래스는 한개이지만 객체는 내가 원하는
9.데이터 취업 스쿨 스터디 노트 -(8) 파일 읽기,쓰기
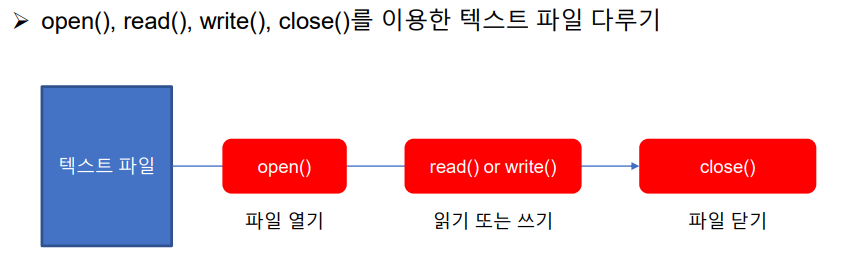
DS\_파이썬42번. 클래스에서 객체가 생성될 때 생성자를 호출하더라도 \_\_int\_\_() 은 자동호출이 되지 않는다. -> False
10.데이터 취업 스쿨 스터디 노트 -(9) 연습문제
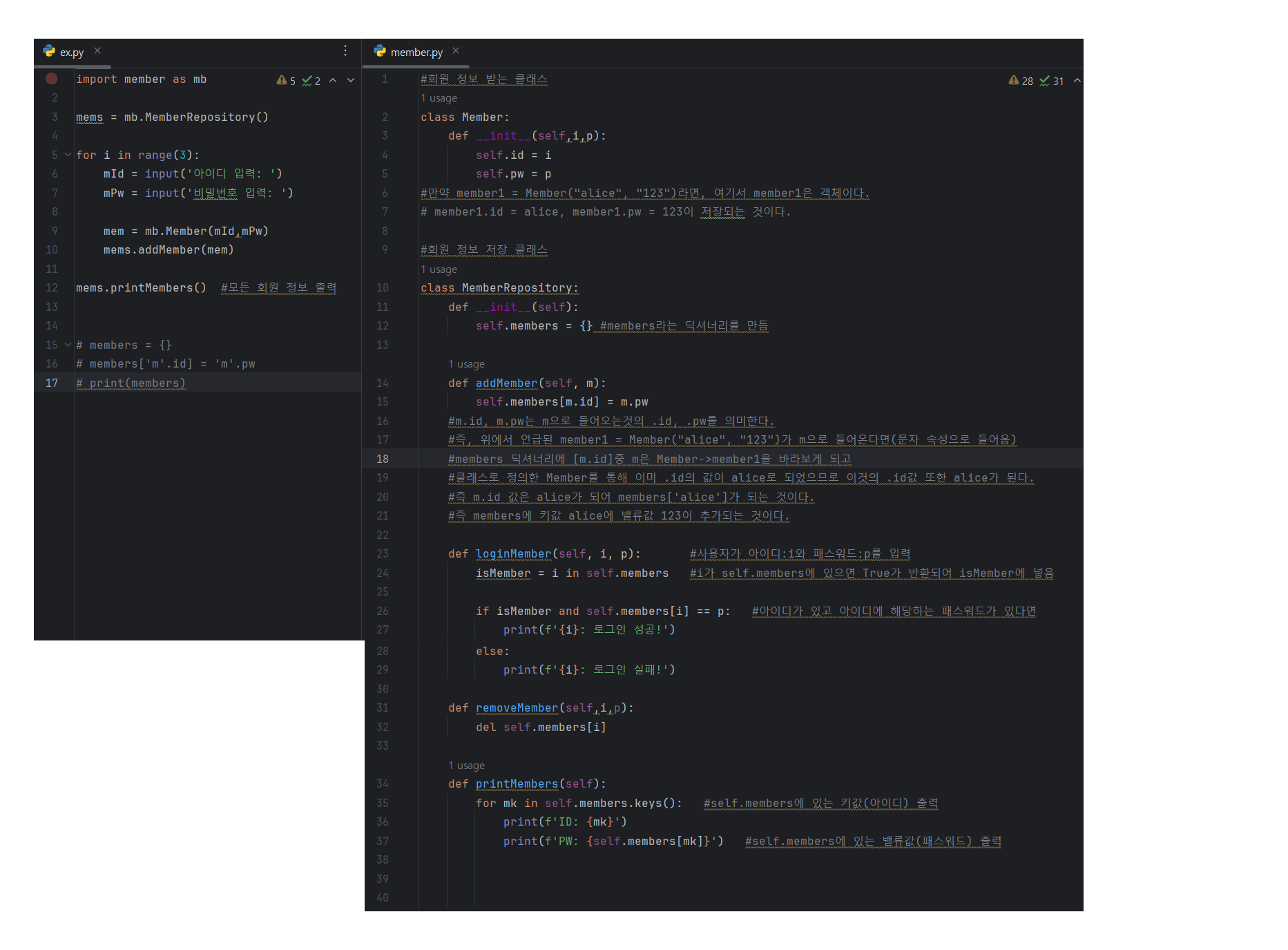
n=0, n=-1까지 계속 내려가지 않고 n=1에서 실행이 종료되는 이유는 n=1일때 if문이 실행되 return 1이 반환된다.중요한 점은 'return'문을 만나면 함수는 해당값을 반환하고 즉시 종료된다는 것이다. 그렇기에 n=1 미만으로는 더이상 실행되지 않는다.
11.데이터 취업 스쿨 스터디 노트 -(10) 기초수학
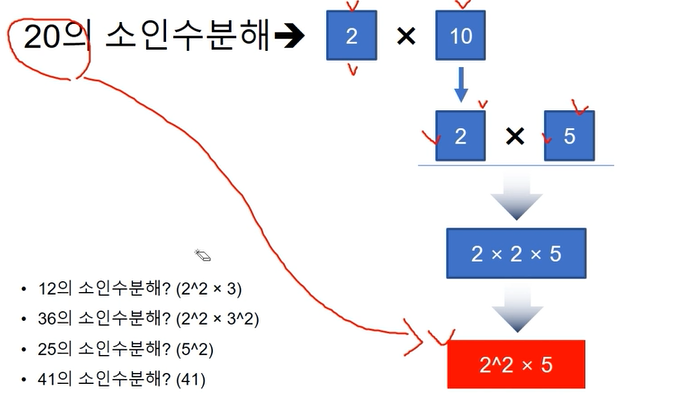
어떤 수를 나누어 떨어지게 하는 수나누어 떨어지는 수가 1과 본인 자신인 수. 단 1은 제외.약수중에서 소수인 숫자.10의 소인수는 2,51보다 큰 정수를 소인수의 곱으로 나타낸 것.소인수 구하는 코드
12.데이터 취업 스쿨 스터디 노트 -(11) 기초수학 문제풀이
1 외에 공약수가 없는 경우100부터 1000사이의 2개의 난수에 대해서 공약수와 최대공약수를 출력하고, 서로소인지 출력하는 프로그램 만들기
13.데이터 취업 스쿨 스터디 노트 -(12) 자료구조, 리스트

여러 개의 데이터가 묶여있는 자료형을 컨테이너 자료형이라고 하고, 이러한 컨테이너 자료형의 데이터 구조를 자료구조라고 한다.ex)이름A, 이름B, 이름C, 이름D -> 묶어서 관리 = 컨테이너 자료형Dictionary는 key와 value로 이루어짐Set의 특징은 중복
14.데이터 취업 스쿨 스터디 노트 -(13) 튜플, 딕셔너리

리스트와 비슷하지만 아이템 변경이 불가하다.'( )'를 이용해서 선언하고 데이터 구분은 ','를 이용한다.숫자, 문자(열), 논리형 등 모든 기본 데이터를 같이 저장할 수 있다.튜플에 또다른 컨테이너 자료형 데이터를 저장할 수도 있다.
15.데이터 취업 스쿨 스터디 노트 -(14) 연습문제
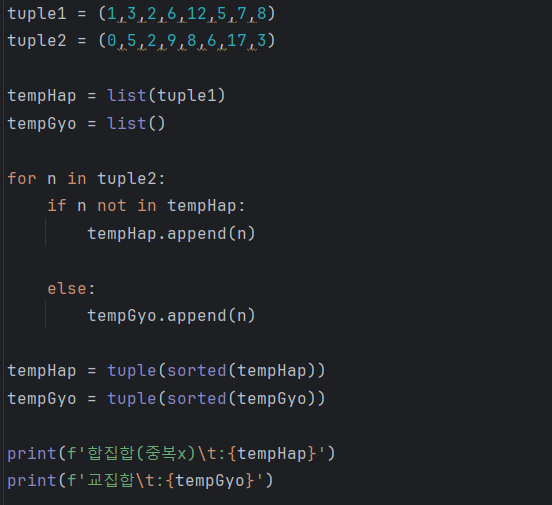
연습문제 인사이트 (4_040) 1부터 100사이의 난수 10개 생성 >
16.데이터 취업 스쿨 스터디 노트 -(15)알고리즘

선형으로 나열되어 있는 데이터를 순차적으로 스캔하면서 원하는 값을 찾는다.마지막 인덱스에 찾으려는 값을 추가해서 찾는 과정을 간략화 한다.(실습 문제가 쉬워보이지만 헷갈리는 부분이 있어 좋은 문제라고 생각함.)정렬되어 있는 자료구조에서 중앙값과의 크고 작음을 이용해서
17.데이터 취업 스쿨 스터디 노트 -(16)알고리즘 연습문제
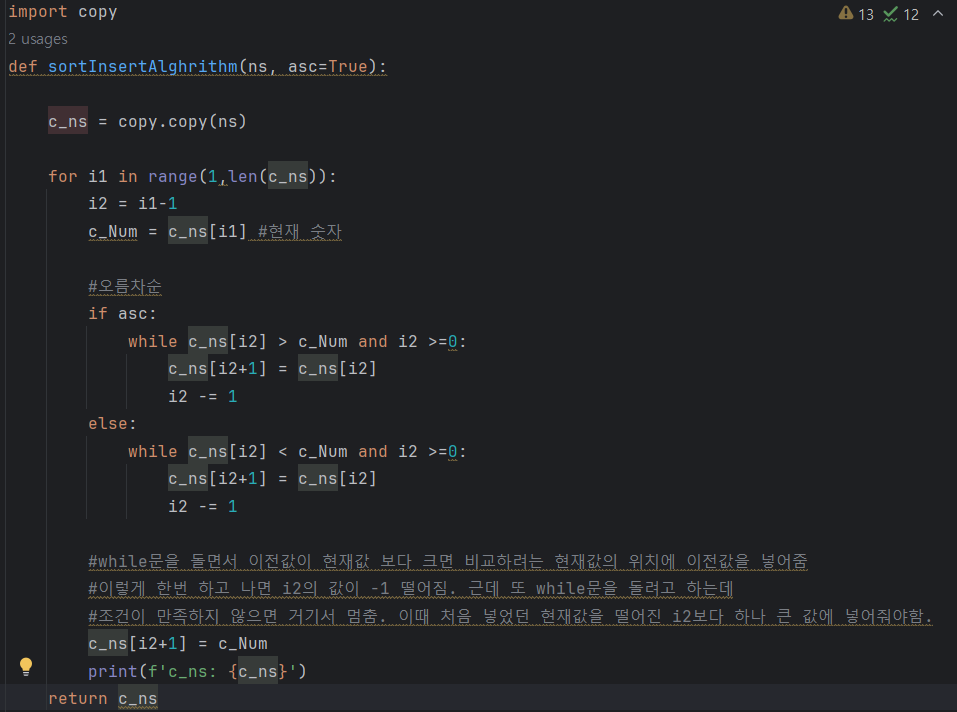
(6_032) 이진검색함수 코드(왜 마지막 숫자가 일치하는 경우를 따로 작성하는지, 존재하지 않는 숫자를 검색하려고 할때 어떻게 무한 루프 방지하는지)실행 코드
18.데이터 취업 스쿨 스터디 노트 -(17) pandas

파이썬에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈단일 프로세스에서는 최대 효율코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨import pandas as pd로 사용함.cf) from MODULE import functionMODULE에 포함된 funct
19.데이터 취업 스쿨 스터디 노트 -(18) matplotlib, numpy

plt.figure(figsize=(10,6))plt.plot(x,y)plt.shownp.arange(a,b,s): a부터 b까지 s의 간격np.sin(value)1\. 격자무늬 추가2\. 그래프 제목 추가3\. x축, y축 제목 추가4\. 주황색, 파란색 선 데이터
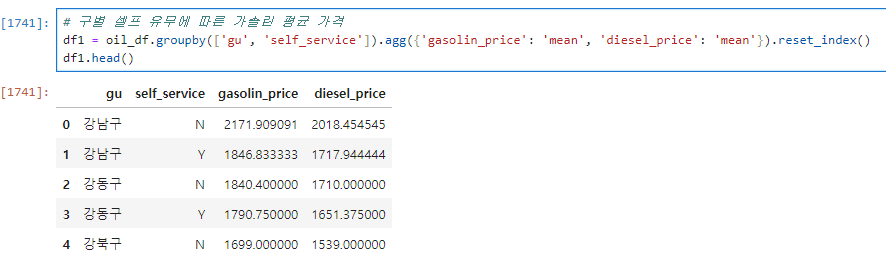
20.데이터 취업 스쿨 스터디 노트 -(19) 강남3구 범죄현황 Googlemaps, seaborn, Folium
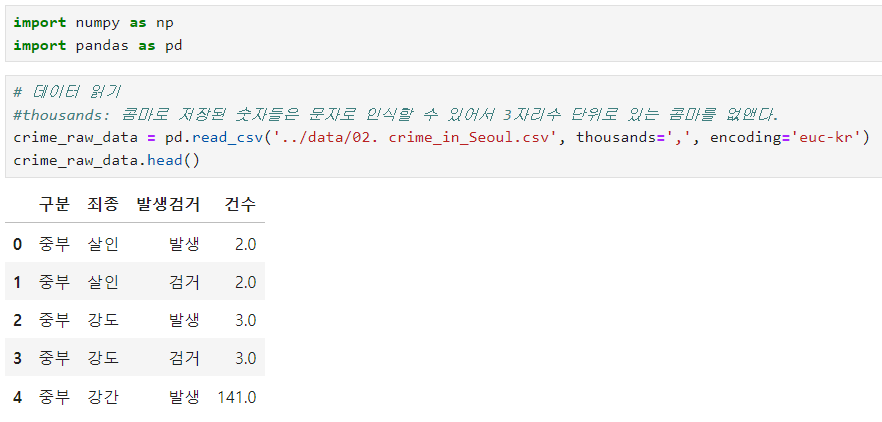
데이터의 용량도 처음에 비해 엄청 줄어듬
21.데이터 취업 스쿨 스터디 노트 -(20) 웹 데이터 분석(Beautiful Soup, 정규식)
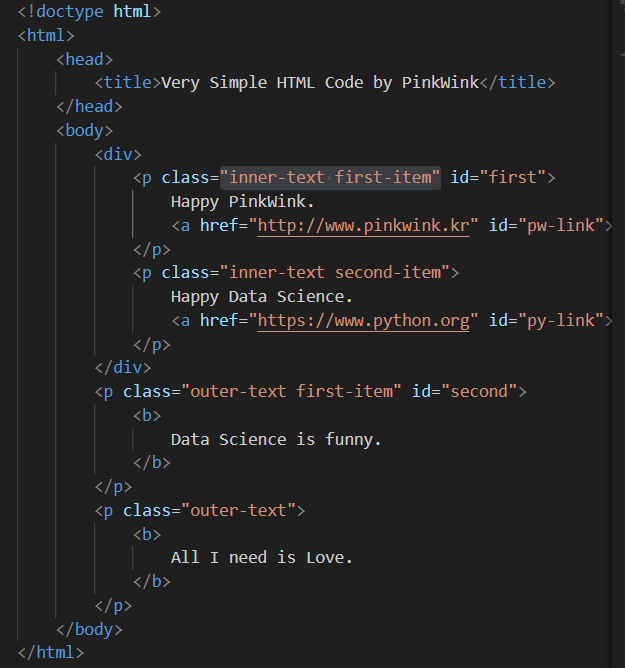
conda install -c anaconda beautifulsoup4 또는pip install beautifulsouplinks = soup.find_all('a')links0.get('href'), links1
22.데이터 취업 스쿨 스터디 노트 -(21) Selenium
윈도우, mac(intel)conda install seleniumpip install seleniummac(m1)pip install seleniumchromedriver 다운로드(크롬 우측상단 점3개 -> 도움말 -> Chrome 정보 -> 맨 앞숫자 버전확인 ->
23.데이터 취업 스쿨 스터디 노트 -(22) forecast(시계열 분석)
시간의 흐름에 대해 특정 패턴과 같은 정보를 가지고 있는 경우를 시계열 데이터라고 함.일반적으로 머신러닝에서는 '시간'을 특성으로 잡지 않아서 머신러닝에서는 시계열 데이터를 다루지는 않음.페이스북에서 만든 시계열 분석 라이브러리fbprophet -> prophet으로
24.데이터 취업 스쿨 스터디 노트 -(23) 네이버 api 사용

import osimport sysimport urllib.requestclient_id = "at4NZonu\_\_sHIKAokruk" client_secret = "0yA5xjQdWW" encText = urllib.parse.quote("파이썬") url = "h
25.데이터 취업 스쿨 스터디 노트 -(24) 인구 소멸 위기 지역 파악, 카르토그램
인구 소멸 위기 지역 파악인구 소멸 위기 지역의 지도 표현지도 표현에 대한 카르토그램 표현fillna(method='pad')warnings 설정header 설정컬럼 이름 변경시도 컬럼에 있는 소계 데이터 제거조건식 활용한 데이터 변경(loc)열 추가pivot_tabl
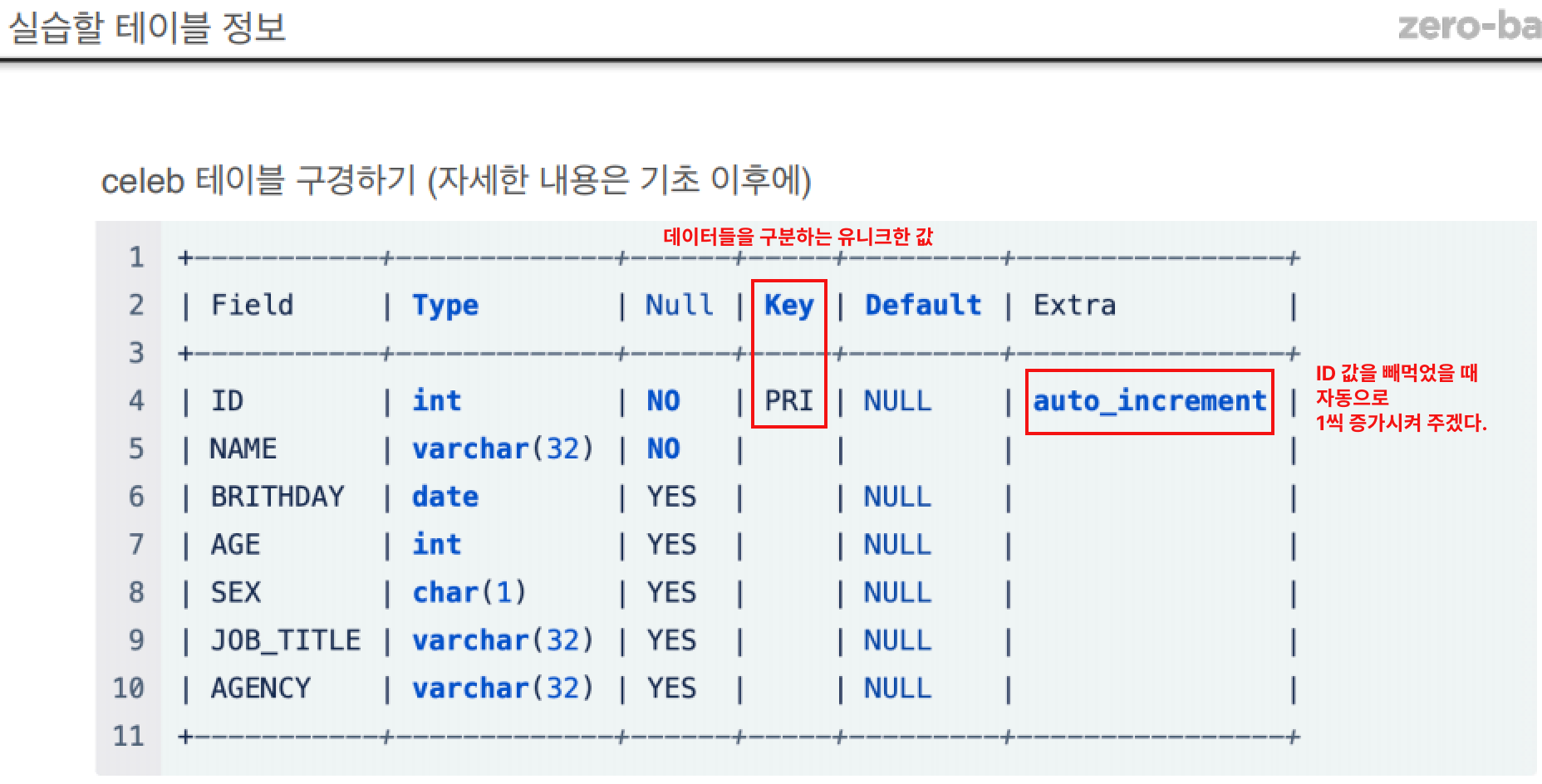
26.데이터 취업 스쿨 스터디 노트 -(25) SQL 데이터베이스, 유저, 테이블 생성/수정/삭제

여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합체사용자와 데이터베이스 사이에서 사용자의 요구에 따라 정보를 생성해주고 데이터베이스를 관리해주는 소프트웨어ex) mysql서로간에 관계가 있는 데이터 테이블들을 모다운 데이터 저장공간데이터베이스
27.틈새 메모 - 과제 및 EDA 테스트(1, 2) 정규표현식, groupby
value_count: 데이터프레임 특정 조건에 해당하는 개수 세기ex) df\[df'brand' == 스타벅스].value_count()
28.데이터 취업 스쿨 스터디 노트 -(26) INSERT, SELECT, WHERE, UPDATE, DELETE

테이블의 컬럼 이름의 순서와 값의 순서가 일치하도록 작성모든 컬럼값을 추가하는 경우 컬럼명은 작성할 필요 없이 입력하는 값만 순서대로 작성하면 됨.select로 테이블 확인.desc는 해당 테이블의 컬럼값과 데이터의 형태를 보여주는 것임.select 문은 알고있기에 기
29.데이터 취업 스쿨 스터디 노트 -(27) ORDER BY, 비교연산자
30.데이터 취업 스쿨 스터디 노트 -(28) UNION, JOIN, CONCAT, ALIAS, DISTINCT, LIMIT

가져오는 컬럼의 종류는 달라도 가져오는 컬럼의 개수는 같아야 한다.하지만 그래도 컬럼의 종류도 맞추는 것이 좋다.
31.데이터 취업 스쿨 스터디 노트 -(29) aws RDS
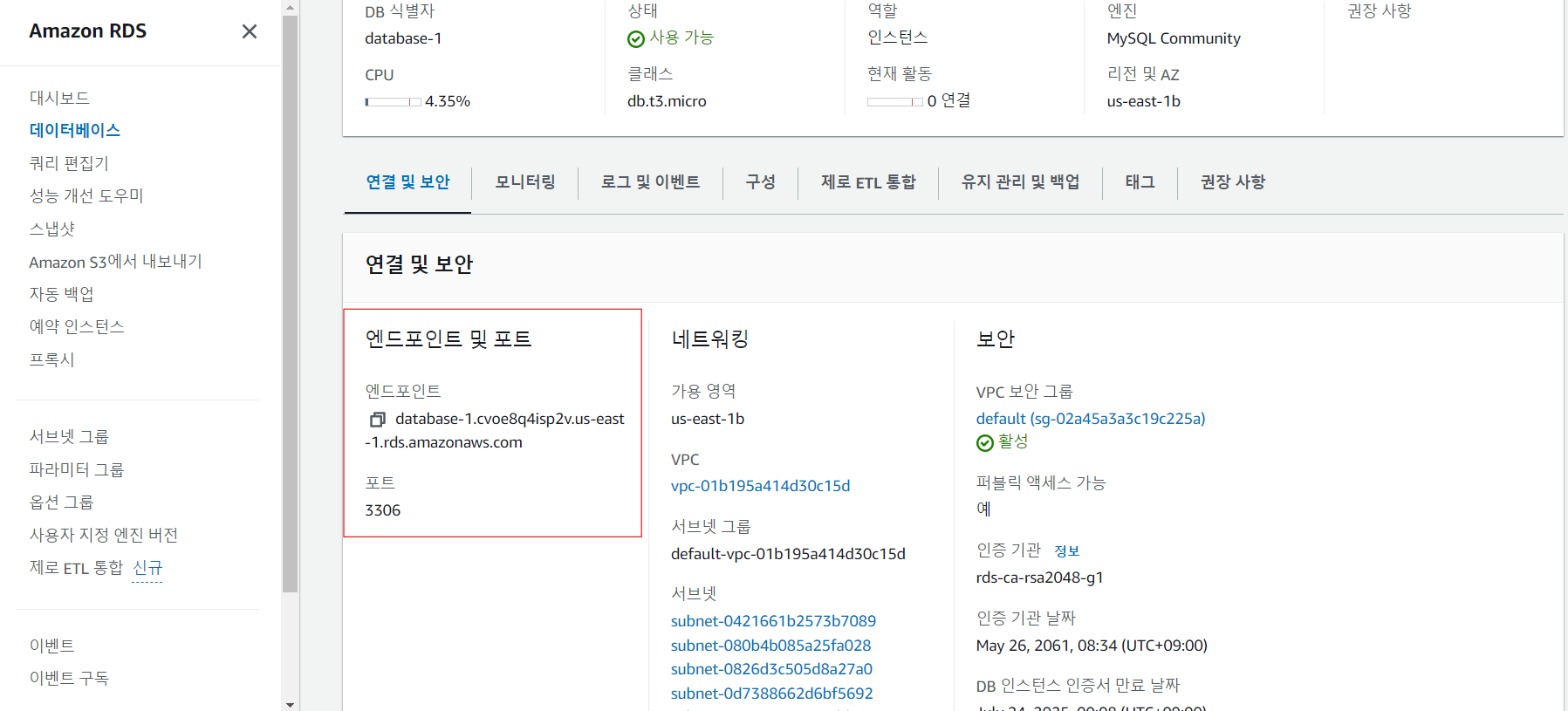
MYSQL RDS 생성aws 관리 콘솔 -> 서비스 -> 데이터베이스 -> RDS -> 데이터베이스 -> 데이터베이스 생성 -> 표준생성, mysql, 템플릿(프리티어) -> mysql접속할 마스터 암호 설정(잊어버리면 안됨) -> 스토리지 자동 조정 활성화 해제 ->
32.데이터 취업 스쿨 스터디 노트 -(30) 데이터베이스 백업 및 불러오기

하단에 -p zerobase 처럼 p옆에 한칸 띄워서 입력하면 비밀번호가 아니라 zerobase라는 데이터베이스로 이동하라는 뜻이다.sql 파일 실행source test01.sql현재 경로에서 파일을 불러오므로 파일명만 작성하면 됨.앞에서 mysql에 접속한 상태여서
33.데이터 취업 스쿨 스터디 노트 -(31) python with mysql
python으로 mysql 접속 후 실행하는 방법jupyter notebook or vscode를 통해 실행mysql에 접속하기 위한 코드사용이 끝났을 때는 연결을 종료해줘라.(자원관리를 위해서)또는
34.데이터 취업 스쿨 스터디 노트 -(32) primary key, foreign key

테이블의 각 레코드를 식별중복되지 않은 고유값을 포함null 값을 포함할 수 없음테이블당 하나의 기본키를 가짐constraint는 생략 가능name과 type이 각가 key가 아니라 이거 두개가 하나의 키다.alter table 테이블명drop primary key;하
35.데이터 취업 스쿨 스터디 노트 -(33) 집계함수
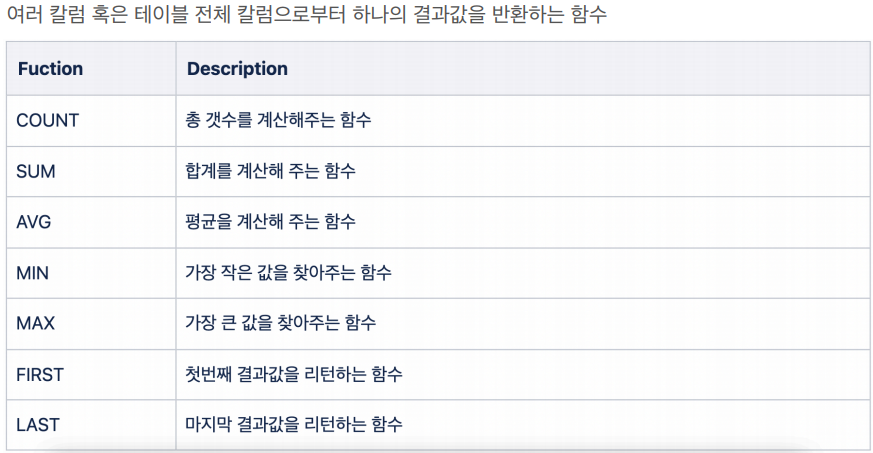
총 개수를 계산숫자 컬럼의 합계를 계산
36.데이터 취업 스쿨 스터디 노트 -(34) Scalar Function(length, round, format 등)
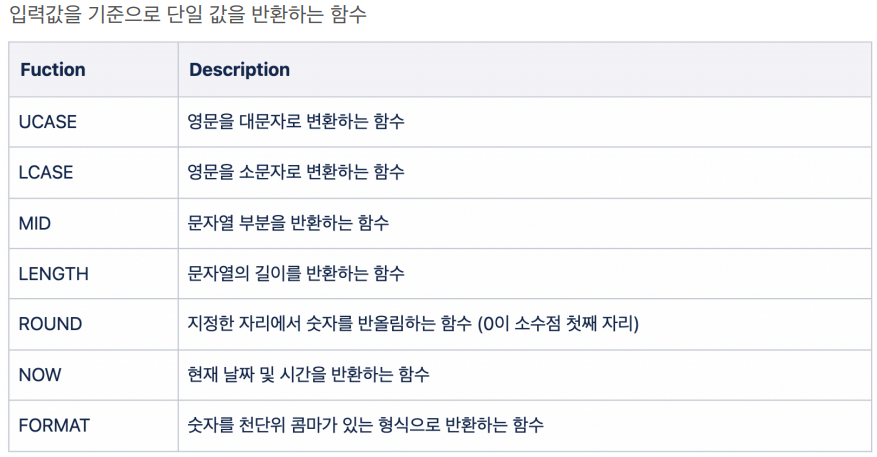
영문을 대문자로 변환하는 함수(가장 많이 씀)영문을 소문자로 변환하는 함수문자열 부분을 반환하는 함수string, start, length뒤에서부터 조회할때는 마이너스(-) 사용문자열의 길이를 반환(많이씀)공백도 포함함지정한 자리에서 숫자를 반올림현재 날짜 및 시간을
37.데이터 취업 스쿨 스터디 노트 -(35) 서브쿼리

스칼라 서브쿼리: select 절에 사용인라인 뷰: from 절에 사용중첩 서브쿼리: where 절에 사용where절에서 사용하는 서브쿼리single row: 하나의 열을 검색하는 서브쿼리multiple row: 하나 이상의 열을 검색하는 서브쿼리multiple col
38.데이터 취업 스쿨 스터디 노트 -(36) Git
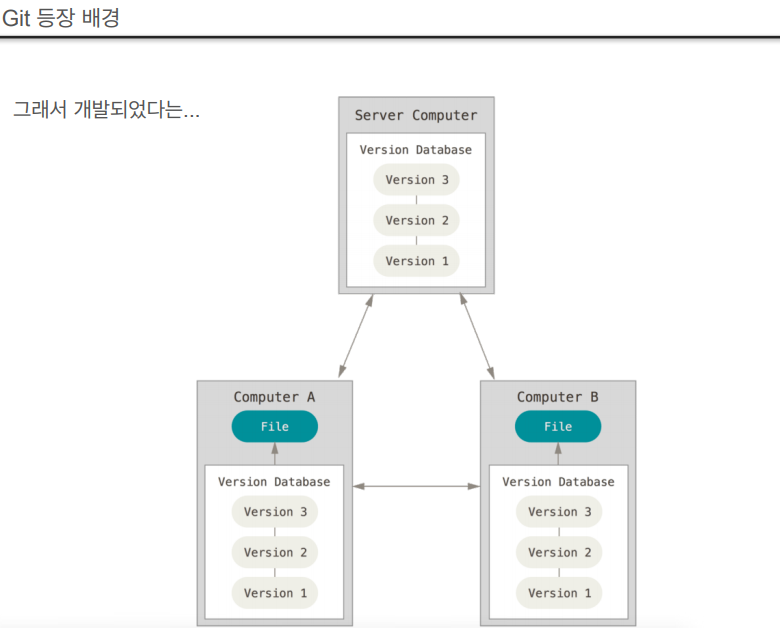
Configuration Management SystemsVersion Control Systems(vcs)버전관리 시스템, 형상관리 시스템, vcs 뭐써봤냐?Source Data + History협업, 작업추적, 복구 등이 가능https://git-scm.c
39.데이터 취업 스쿨 스터디 노트 -(36) Git 로컬, 리모트 레퍼지토리 push/pull
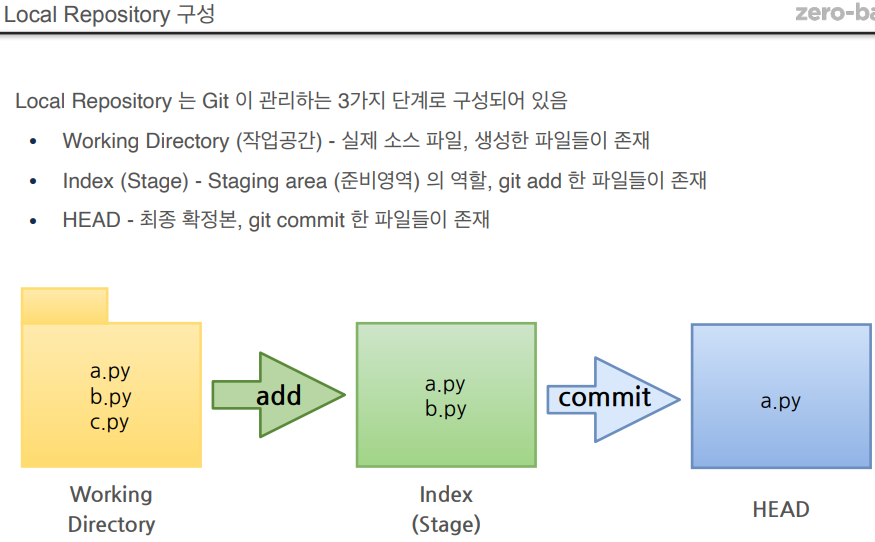
git init을 하면 해당 폴더가 워킹 레퍼지토리가 됨.Working Directory 에 파일을 생성 touch 파일명.확장자Git에 존재하는 파일 확인Working Directory 에서 변경된 파일을 Index (stage)에 추가Index (stage) 에 추
40.데이터 취업 스쿨 스터디 노트 -(37) 누군가 올려놓은 것을 로컬로 가져와 수정, branch 생성/이동/삭제
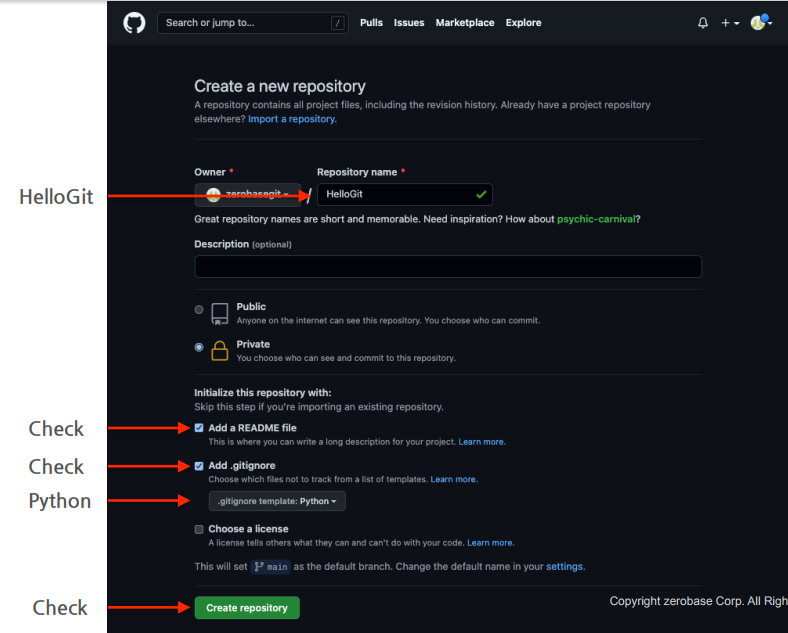
레퍼지토리가 생성되자마자 제일 기본으로 하나의 Branch가 생성되는데 이것이 Default Branch로컬에서 시작해서 remote로 올렸을 때는 masterremote에서 생성했을 때는 main으로 생성됨.이름을 수정할 수 있음.초반에 아무도 공유안했을 때는 이름
41.데이터 취업 스쿨 스터디 노트 -(38) git log, diff (with vscode)
42.데이터 취업 스쿨 스터디 노트 -(39) merge, conflict
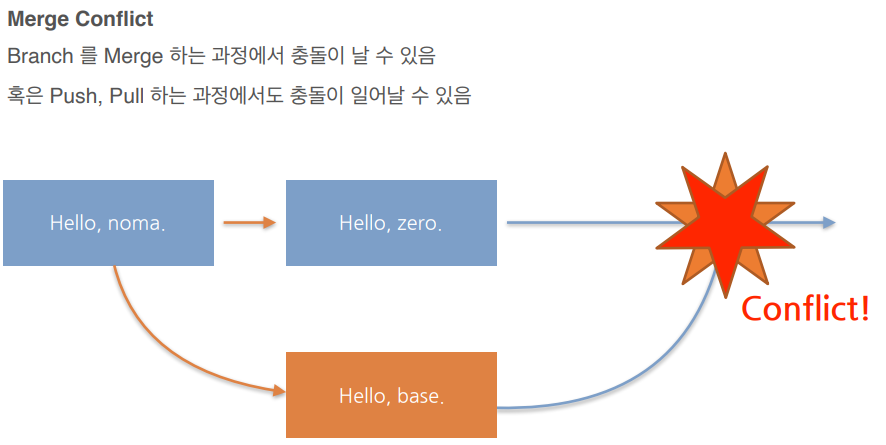
현재 위치한 Branch에 다른 Branch를 병합main branch에 dev branch를 병합하려면1\. main 브랜치로 이동2\. git merge <데브브랜치명>main에 hello, noma 만듬dev2 branch에 hello, noma 복사main
43.데이터 취업 스쿨 스터디 노트 -(40) Tag, README

특정 버전 (Commit)에 Tag 를 달아놓을 필요가 있을 때 사용
44.데이터 취업 스쿨 스터디 노트 -(41) 기초통계
수학: 정해지지 않은 임의의 값통계학: 조사 목적에 따라 관측된 자료값성별, 주소지(시/군/구), 업종 등과 같이 몇 개의 범주로 구분하여 표현할 수 있는 데이터. 1은 남자, 2는 여자로 표현 가능하나 여기서 숫자의 의미는 없음.명목형 변수: 성별, 혈액형순서형 변수
45.데이터 취업 스쿨 스터디 노트 -(42) 확률
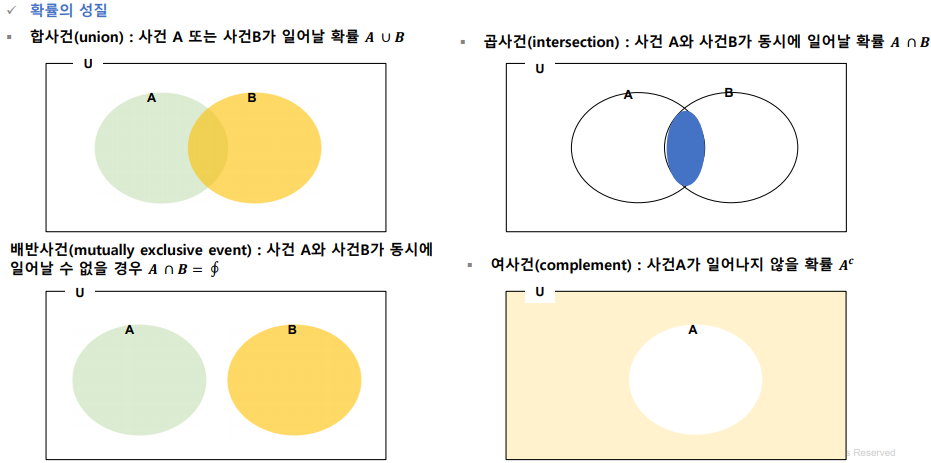
어떤 실험에서 나올 수 있는 모든 가능한 결과들의 집합어떤 시행을 N 번 반복했을 때, 사건 A에 해당하는 결과가 R 번 일어난 경우 r/N 이고, 사건 A가 일어날 상대도수라고 함.N이 무한히 커지면 상대도수는 일정한 수로 수렴하는데, 이 극한값을 사건 A의 통계적
46.데이터 취업 스쿨 스터디 노트 -(43) Tableau
union 테이블을 드래그해와서 먼저 드래그 한 테이블에 갖다대면 '유니온'이라고 뜰 경우 갖다 놓으면 된다. 필드의 이름과 데이터의 유형이 같아야함. 해당 테이블에서 유니온 편집 클릭하면 어떤 것들이 유니온 되었는지 확인할 수 있음. join 옮겨놓은 테이블을 더블
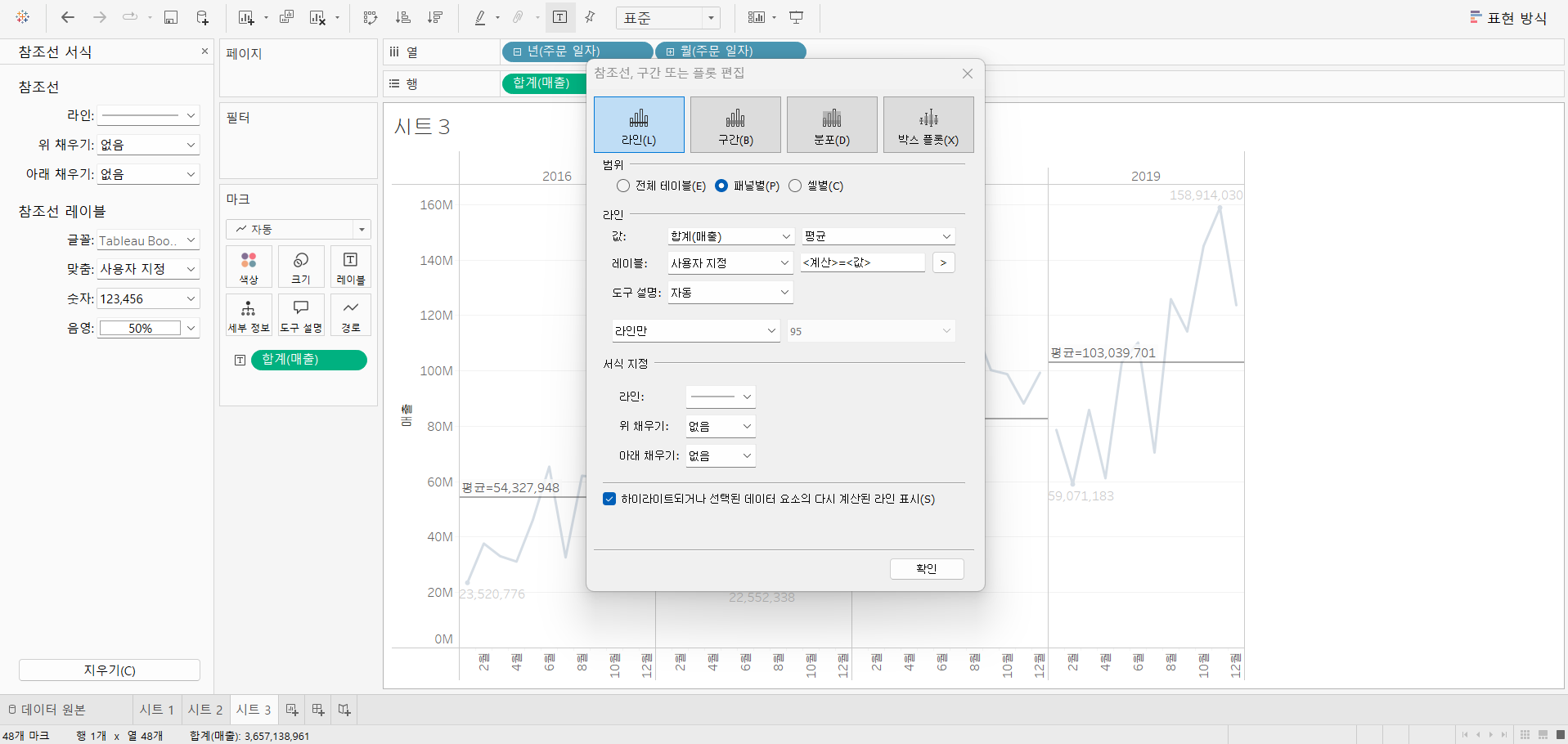
47.데이터 취업 스쿨 스터디 노트 -(44) Tableau 계산
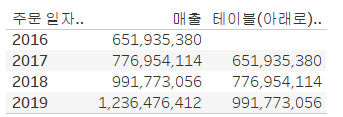
매출을 '퀵 테이블 계산 -> 차이' 로 설정한 뒤 '기준 -> 첫 번째' 로 설정을 하면 모든 년도가 2016년 1월을 기준으로 비교하게 된다.이 경우 해당 년에 국한해서 1월의 값과 비교하고 싶다면 '다음을 사용하여 계산 -> 패널 아래로'로 설정하면 된다.전체에
48.데이터 취업 스쿨 스터디 노트 -(45) Tableau 함수(running, lookup, window, contains, split, replace, left, 날짜함수)
함수 내에 다른 함수가 포함된 함수RUNNING_SUM: 누계 합계RUNNING_AVG: 누계 평균total 함수와 RUNNING_SUM의 차이: RUNNING_SUM은 누적해서 더하는 반면 total 전체값을 다 더한 값이다.lookup(식, 오프셋)현재 행으로부터
49.데이터 취업 스쿨 스터디 노트 -(46) Tableau 표현식(include, exclude, fixed)
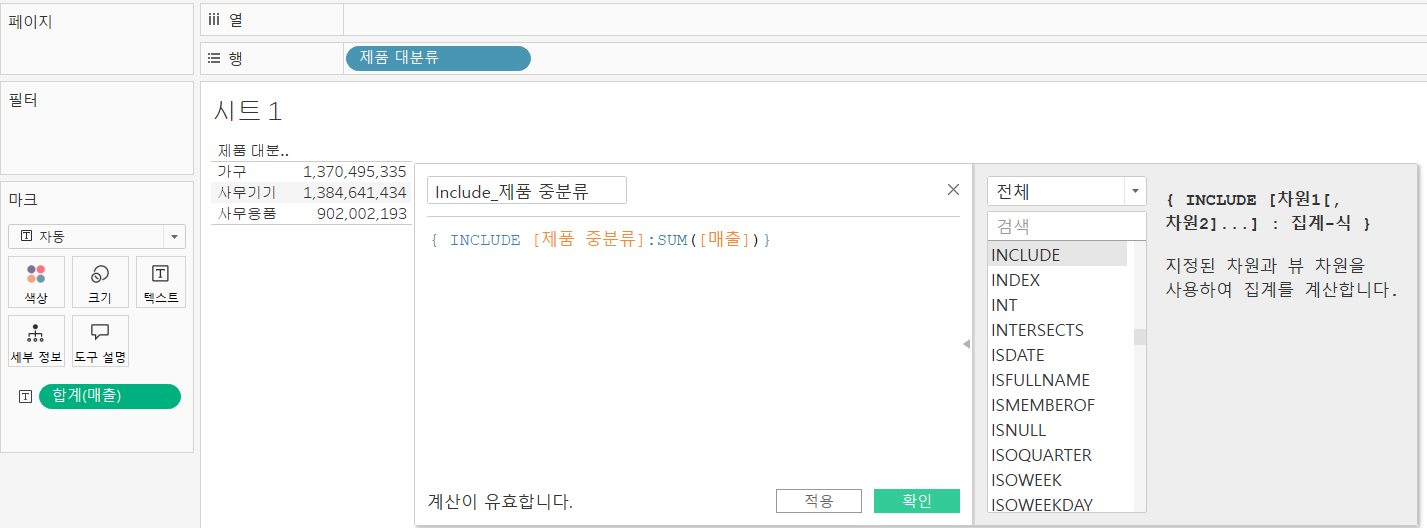
LOD: 세부 수준 식(Level Of Detail){include\[차원1],\[차원2]:sum(\[측정값])}화면에 포함되지 않은 특정 차원을 포함하여 결과를 계산'Include\_제품 중분류' 계산식 더블클릭.값이 동일한 이유는 제품 중분류에서 집계한 값을 제품
50.데이터 취업 스쿨 스터디 노트 -(47) Tableau 작동 순서(테이블 계산, fixed, context)
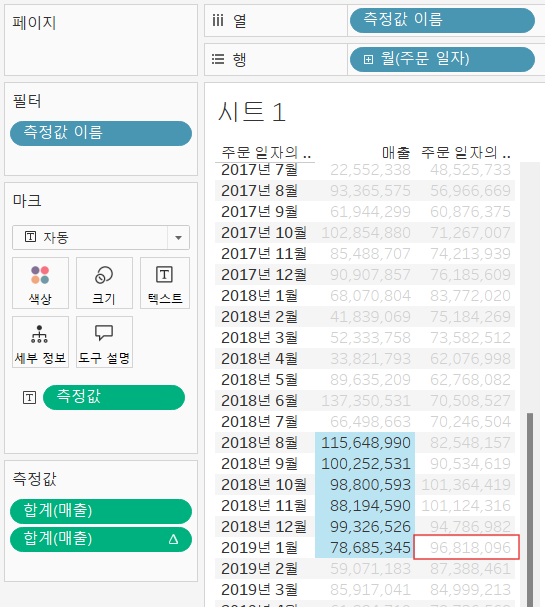
태블로는 계산, 필터의 적용 우선권이 정해져있다. 그렇기에 필터를 사용했을 때 내가 예상한 결과값과 다른 결과가 출력될 수 있다.아래의 예시를 살펴보자.2019년도 최근 6개월의 이동평균을 보기 위해 매출을 '이동평균'으로 '퀵 테이블 계산'을 하면 2019년 1월에는
51.틈새 메모 - EDA 테스트4
DataFrame에서 null(NaN) 값이 있는 행(row) 지우기df.dropna(inplace=True)
52.데이터 취업 스쿨 스터디 노트 -(48) 머신러닝, dicision tree, scikit learn, accuracy, zip
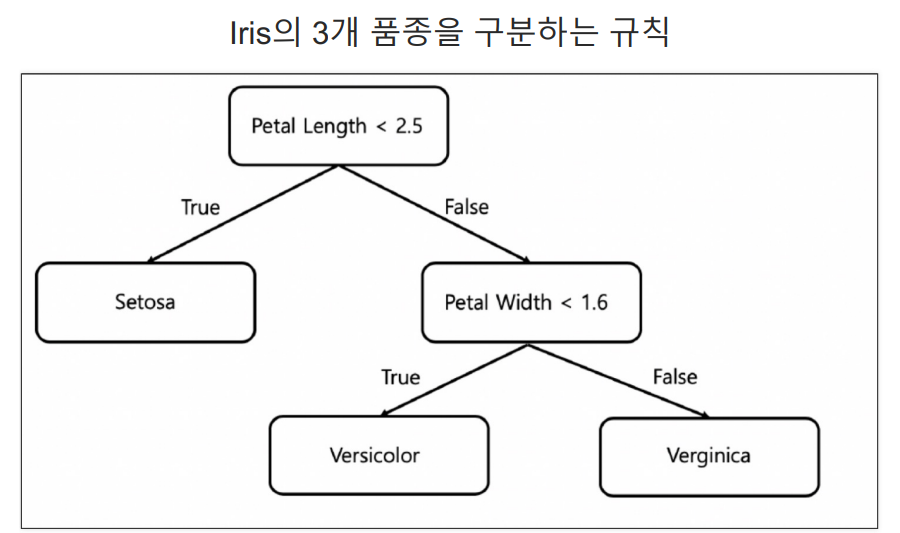
데이터 분석 영역에서는 엔트로피가 높다는 것은 무질서도가 높다는 의미.빨간색 공은 10개, 파란색 공은 6개왜 나누는 기준점을 여기로 잡은거야?다른 곳을 기준점으로 잡아서 나눠도 되잖아?기준점을 잡은 근거를 위해 '지니계수'를 사용함.지니계수가 낮기 때문에 무질서도가
53.데이터 취업 스쿨 스터디 노트 -(49) 머신러닝을 이용한 타이타닉 생존자 예측
데이터 읽기 생존 상황(countplot) 성별에 따른 생존 상황  정규화 Label Encoder, MinMax, Standard, robust
n개의 각각의 클래스에 0부터 n-1까지의 연속된 수치(라벨)를 부여하는 것fit 한 후에 하나씩 트랜스폼하면서 바로 확인할수도 있음.
55.데이터 취업 스쿨 스터디 노트 -(51) Decision Tree를 이용한 와인데이터 분석(Pipeline, 교차검증(kfold), cross validation, GridSearchCV
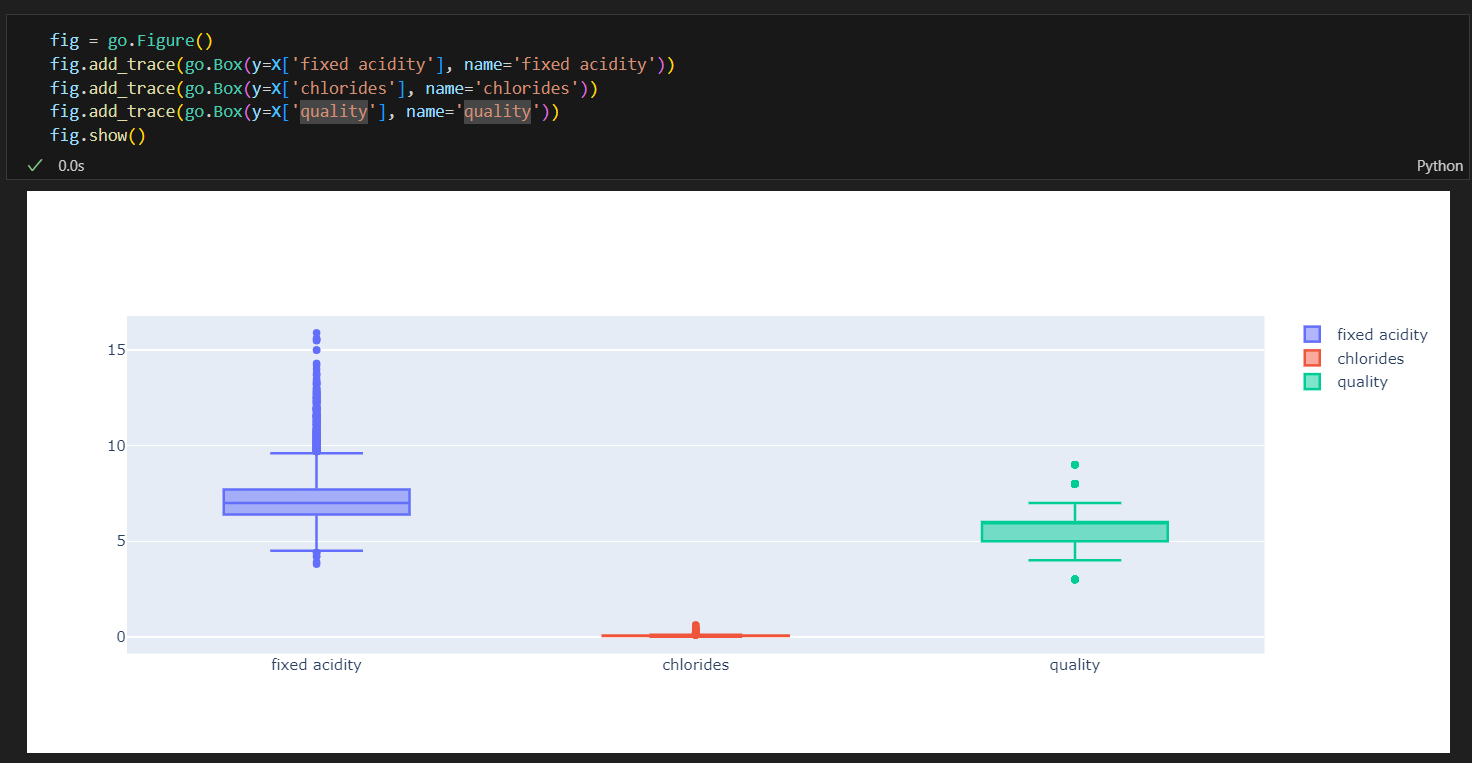
.
56.데이터 취업 스쿨 스터디 노트 -(52) 모델평가(Accuracy, Precision, Recall, f1, ROC)
회귀모델 예측 결과는 연속된 변수 값이 된다.1종 오류: 가설이 아닌데 맞다고 하는거전체 데이터 중 맞게 예측한 것내 모델이 1이라고 예측한 것 중에서 실제 1스펨메일ex) 스펨이라고 예측한 메일 중에서 실제로 스펨이 아닌게 있으면 곤란하다.실제 1들 중에서 1이라고
57.틈새 메모 - EDA 테스트5
문자열 열에서 특정 패턴이 포함되는지를 확인할 때 사용된다.str accessor는 시리즈의 각 요소가 문자열인 경우에 문자열 메서드를 호출할 수 있게 해준다.isin():주로 값이 목록에 포함되는지를 확인할 때 사용된다.예를 들어, 특정 열의 값이 a, b, c 목록
58.데이터 취업 스쿨 스터디 노트 -(53) 함수, boxplot
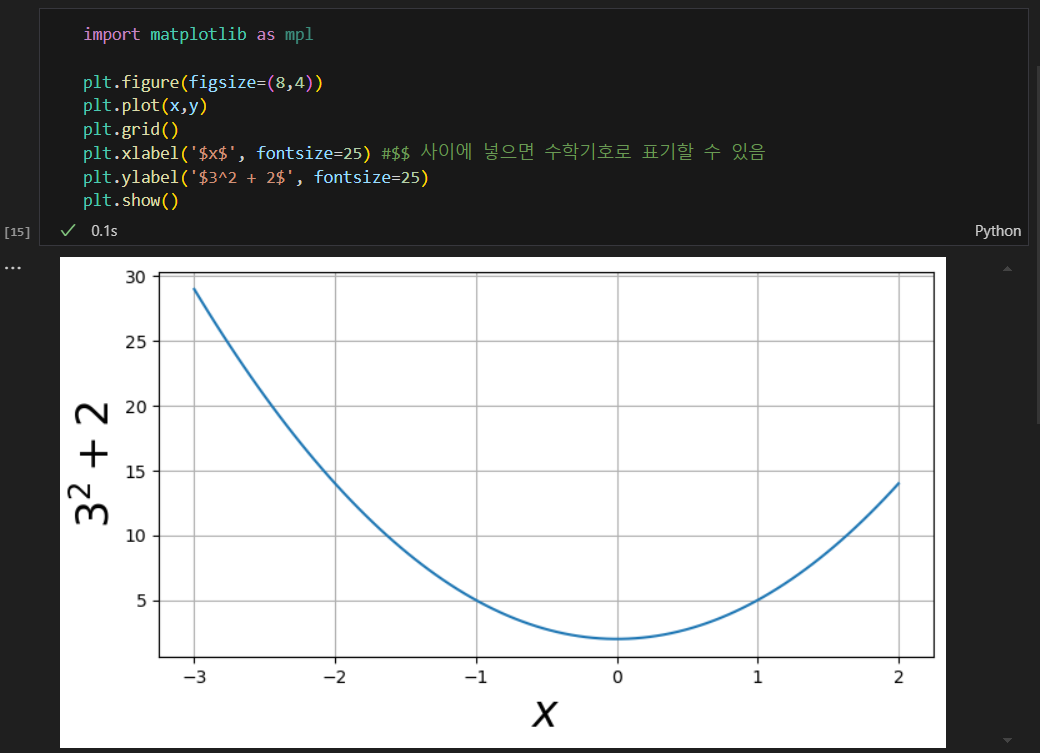
다항함수 지수함수 지수증가  선형 회귀, OLS, 결정계수(rsquared)
정답을 알려주고(=라벨을 붙임) 학습을 하고 새로운 데이터를 줌.내가 가지고 있는 데이터로 먼저 학습을 시킴. 학습을 시킨 모델에게 새로운 데이터를 주는 것이다.카테고리처럼 나눠짐.출력이 연속적인 값. 연속된 범위 안에서 어떤 값을 줬을 때에 대한 결과 값.내가 가지고
60.데이터 취업 스쿨 스터디 노트 -(55) 통계적 회귀

통계를 하는 사람들이 회귀모델을 구축하는 것과 머신러닝을 하는 사람들이 회귀모델을 구축하는 것은 조금 다르다.업로드중..통계에서는 분포가 정규분포를 잘 따르냐, 나의 데이터는 모집단을 잘 추정하느냐 이런 관점에서 본다.
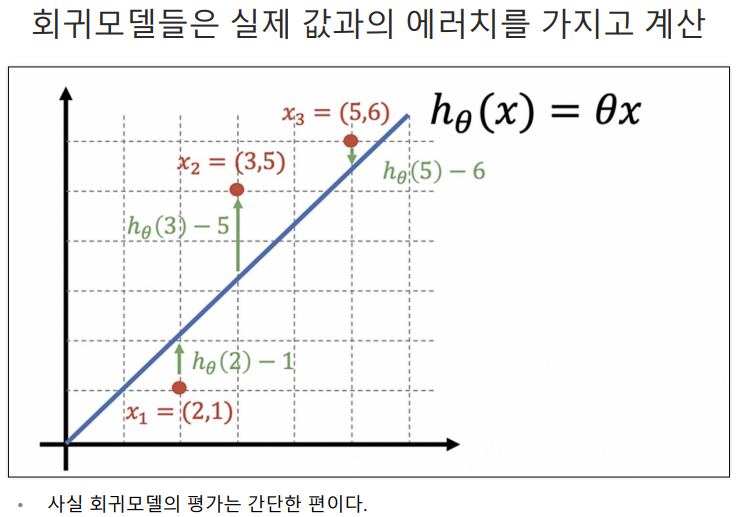
61.데이터 취업 스쿨 스터디 노트 -(56) 선형 회귀 cost function
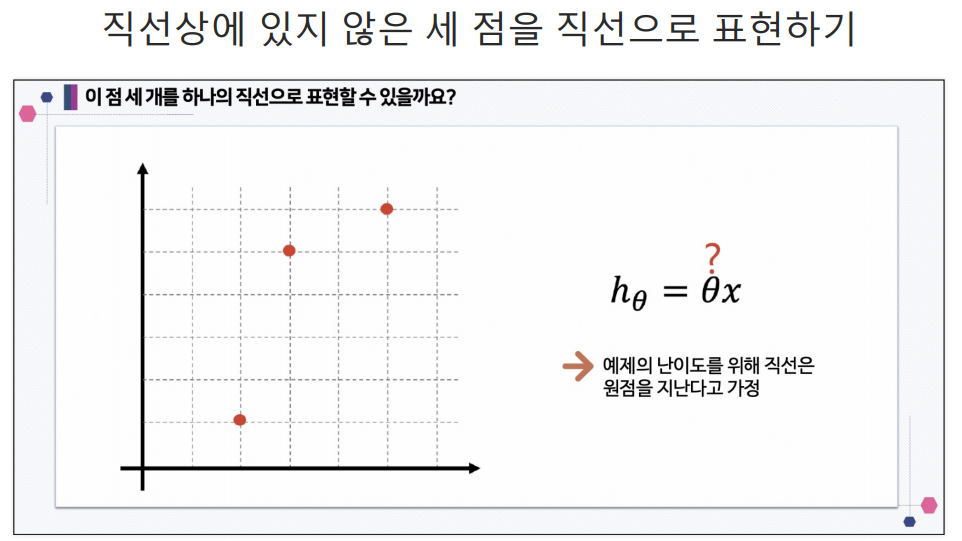
h는 예측값이다.딥러닝에서도 많이 사용함.cost function은 에러를표현하는 도구임.에러가 작을수록 좋으니까 cost function을 최소화 할 수 있는 기울기가 최적의 직선이다.예측하기 위한 직선(h(x) = Θx)을 기준으로 에러(예측값과 실제 값의 차이를
62.데이터 취업 스쿨 스터디 노트 -(57) Logistic Regression 및 실습 + threshold 임의 수정
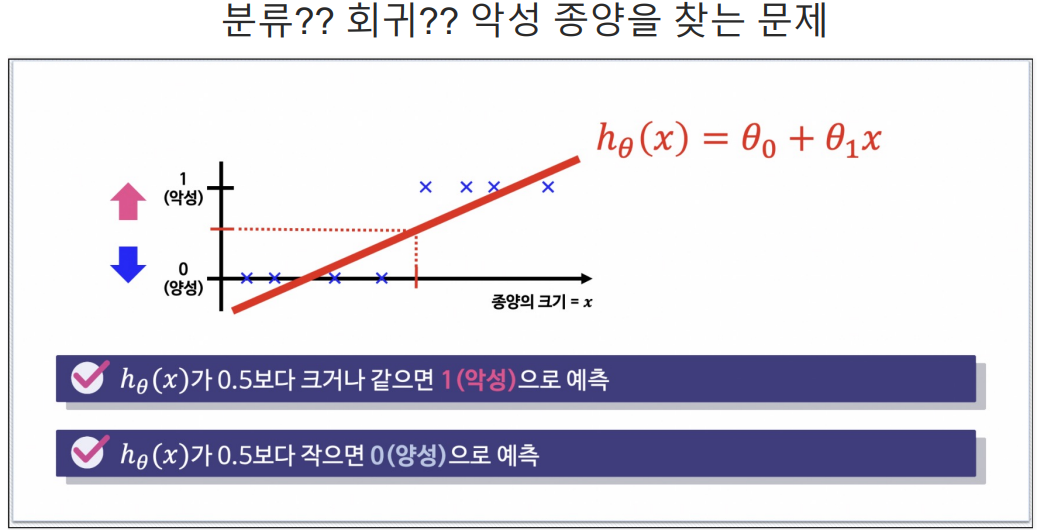
회귀용도로 사용하는 것이 아니라 분류를 하기 위해 사용함.
63.데이터 취업 스쿨 스터디 노트 -(58) 앙상블 기법(voting, bagging - 랜덤포레스트)

알고리즘이 똑같음.하드 보팅소프트 보팅확률의 평균을 구해서 높은 값을 선택함.아래 예시는 1이 나올 3가지 확률의 평균은 0.7인데 이 경우 다수결로 1이 많으므로 1을 선택함.랜덤포레스트bagging 기법의 투표 방식임.DecisionTree 여러개를 사용해서 투표하
64.데이터 취업 스쿨 스터디 노트 -(59) 앙상블 기법 (Boosting Algorithm - AdaBoost, kNN)

분류기는 결정나무,
65.Tableau quiz 메모 - 도넛차트, 달력형 차트
매출별 비중을 보기 위해 매출을 각도에 넣는다.그리고 매출을 표기하기 위해 레이블에도 넣음.해당 파이차트를 복제하기 위해 ctrl+마우스 왼쪽키 누르고 드래그해서 오른쪽에 복제함.파이차트 한개의 크기를 키운다.다른 파이차트는 합계 레이블을 제외하고 모두 삭제해준다.이중
66.데이터 취업 스쿨 스터디 노트 -(60) 신용카드 부정 사용자 검출

67.데이터 취업 스쿨 스터디 노트 -(61) 자연어처리 NLP, WordCloud, Konlpy
Java 설치인터넷에다가 윈도우 자바 환경변수 설정 검색해서 설정하기노트북이 오래되서 서로 나눠서 조금씩 설치Punkt, stopwords 설치이 방법으로 하니 Download 눌러도 안되서아래 방법으로 설치실행 확인
68.데이터 취업 스쿨 스터디 노트 -(62) PCA

주성분 분석차원축소와 변수추출 기법으로 널리 쓰이고 있다.변수의 개수가 차원의 개수인데 변수가 너무 많을 때 고차원의 데이터를 낮은 차원의 데이터로 바꿔주는 것.np.random.RandomState(13)RandomState는 13과 같은 시드를 설정할 수 있는데 동
69.데이터 취업 스쿨 스터디 노트 -(63) PCA 실습(eigenface - olivetti 데이터, HAR 데이터)

사람 얼굴 관련 데이터이미지 시각화.images 와 .data의 차이 차원 축소
70.데이터 취업 스쿨 스터디 노트 -(64) PCA 실습 (MNIST)
NIST: 필기체 인식을 위해서 수집한 데이터MNIST: NIST에서 숫자들만 모아놓은것Numpy 배열은 행과 열의 라벨이 없다.빠른 수치 계산이나 벡터화 연산에 좋다.random.choice() 활용
71.데이터 취업 스쿨 스터디 노트 -(65) Clustering(K-Means, make_blobs, 이미지 분할)

나누고 각각의 평균을 찾고 그것을 기준으로 다시 나누고 다시 평균을 찾고 반복하면서 평균이 계속 같은경우 마무리.이 라벨값은 세토사, 버지니카, 버지칼라가 아니다. 군집 중심들의 번호이다.petal length, petal width 두개의 특성만 가지고 학습 시켰으므
72.데이터 취업 스쿨 스터디 노트 -(66) 추천시스템
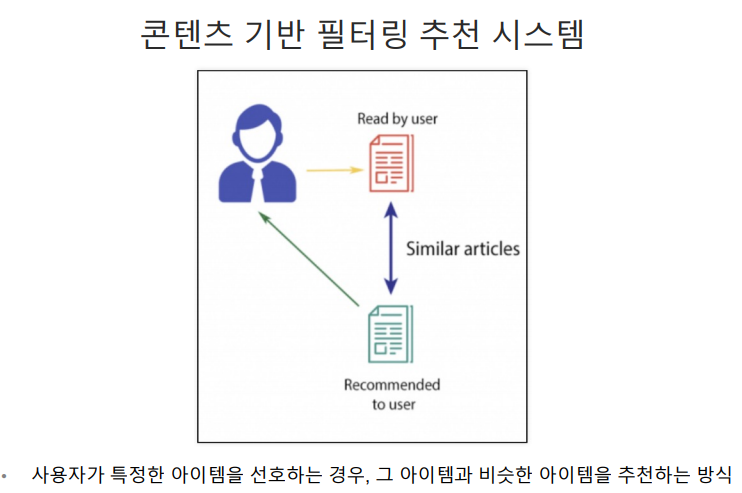
일반적으로는 사용자 기반 보다는 아이템 기반 협업 필터링이 정확도가 더 높음.비슷한 영화를 좋아한다고 취향이 비슷하다고 판단하기 어렵거나매우 유명한 영화는 취향과 관계없이 관람하는 경우가 많고사용자들이 평점을 매기지 않는 경우가 많기 때문.user1은 item1을 4만
73.데이터 취업 스쿨 스터디 노트 -(67) 딥러닝, XOR, MNIST, CNN, one hot encoding

머신러닝을 위한 오픈소스 플랫폼 - 딥러닝 프레임워크Keras라고 하는 고수준 API
74.데이터 취업 스쿨 스터디 노트 -(68) 딥러닝 프레임워크 없이 생으로 이해하기
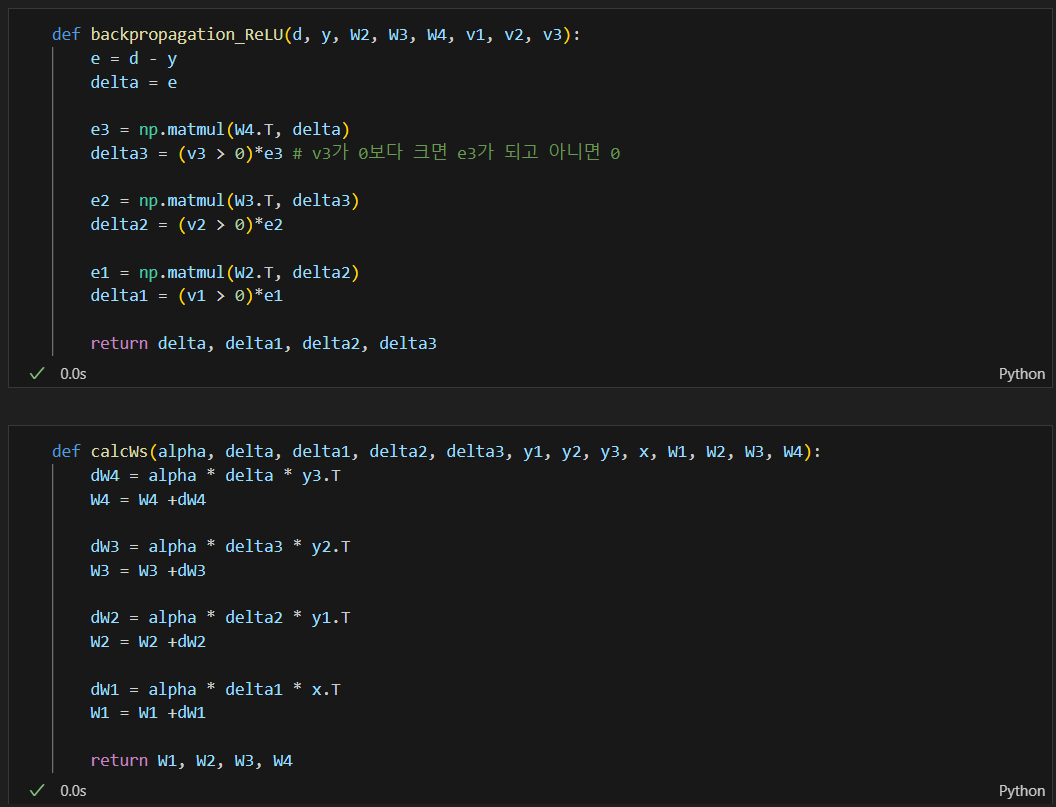
참고) 활성화 함수 소프트맥스 주로 다중 클래스 분류 문제에서 사용됨. 여러 클래스 중 하나를 선택해야 하는 문제(예: 고양이, 개, 새 등 3개의 클래스 중 하나)를 해결할 때, 소프트맥스는 각 클래스에 속할 확률을 계산함. 시그모이드 주로 이진 분류 문제에서 사용
75.데이터 취업 스쿨 스터디 노트 -(69) CNN(LeNET) 실습 - 마스크 여부 분별
LeNET은 신경망 모델중 하나로 손으로 쓴 숫자를 인식하기 위해 개발된 초기의 컨볼루션 신경망(CNN). -> MNIST 데이터 분석에서 사용함.3개의 컨볼루션 레이어와 2개의 풀링 레이어 구조
76.데이터 취업 스쿨 스터디 노트 -(70) 다시 개념 익히기
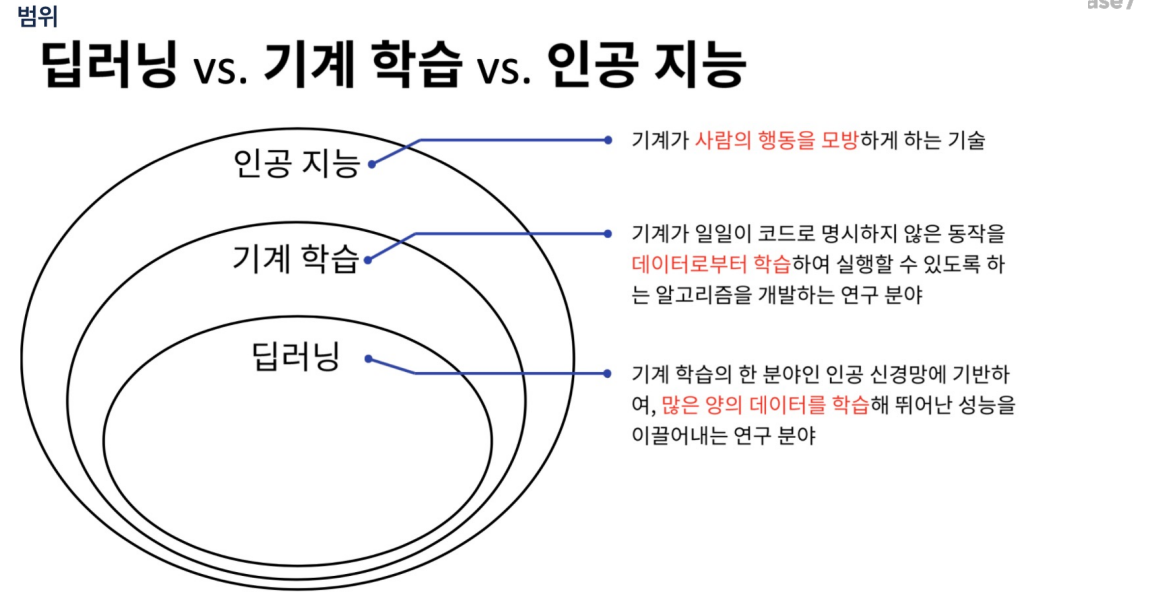
머신러닝은 특징을 찾을 수 있는 수단을 통해 특징을 찾고 학습을 시키지만 딥러닝은 그 특징까지도 직접 찾는다.물체 검증 \*\*역전파시 오차를 거꾸로 한 단계씩 미분해서 값을 구하고 weight(가중치)를 수정해야함. 그러나 입력층에 가까운 레이어일수록 학습이 잘 되지
77.데이터 취업 스쿨 스터디 노트 -(71) pytorch
임포트일반적인 파이썬 코드requires_grad=True -> 기울기를 계산할 수 있게 해줘라.y.backward()z -> x -> a : 2 2 = 4z -> y -> a : 3 10a = 30a=> a= 2.0이라고 했으니 4 + 30(2.0) = 64
78.데이터 취업 스쿨 스터디 노트 -(72) pytorch mnist

download = True : 로컬에서는 False로 해놓으면 매번 다운로드 받을 필요없이 처음 한번만 받고 해당 데이터를 사용할 수 있다.squeeze(): 28,28,1처럼 2차원 이상의 데이터를 사용할 때 1과 같은 숫자를 넣는데 pytorch에서는 1,28,2
79.데이터 취업 스쿨 스터디 노트 -(73) 식물의 사진으로 질병 유무 판단(+전이학습), 꽃이름 맞추기
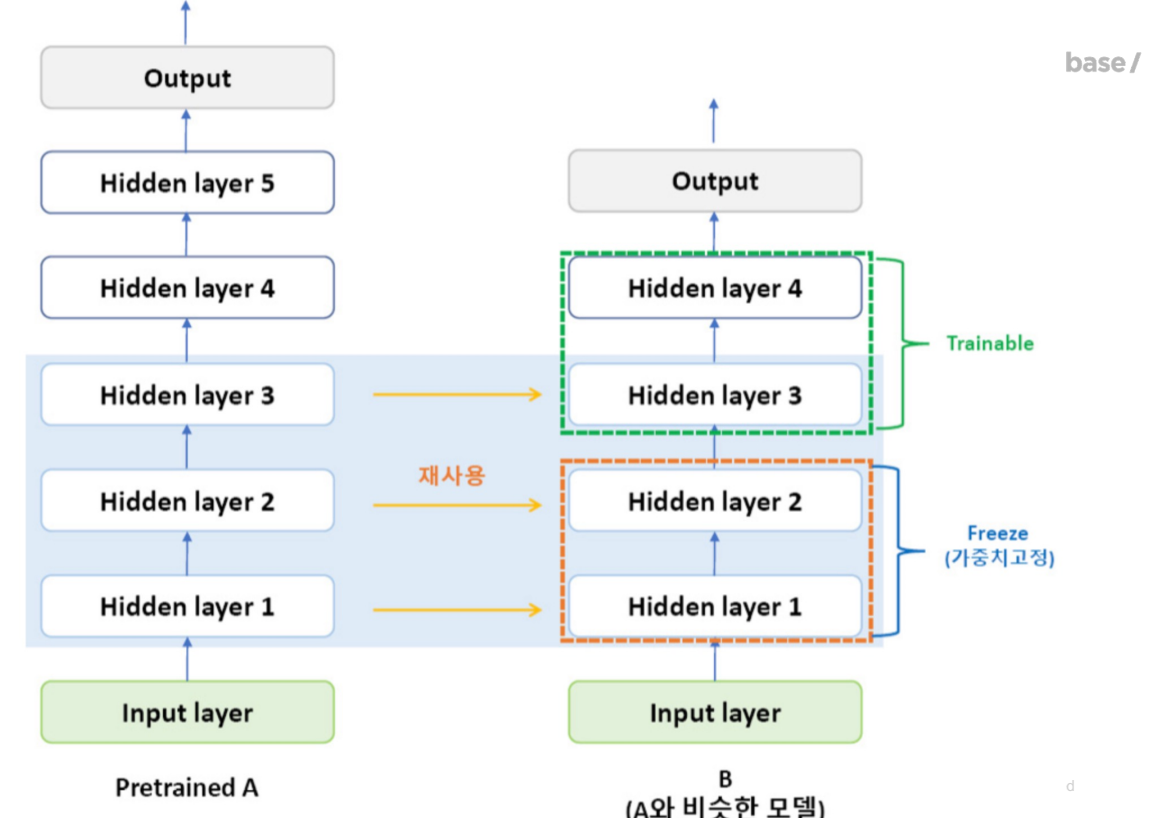
afadsf
80.데이터 취업 스쿨 스터디 노트 -(74) 텐서플로우 오토인코더, 이미지 증강
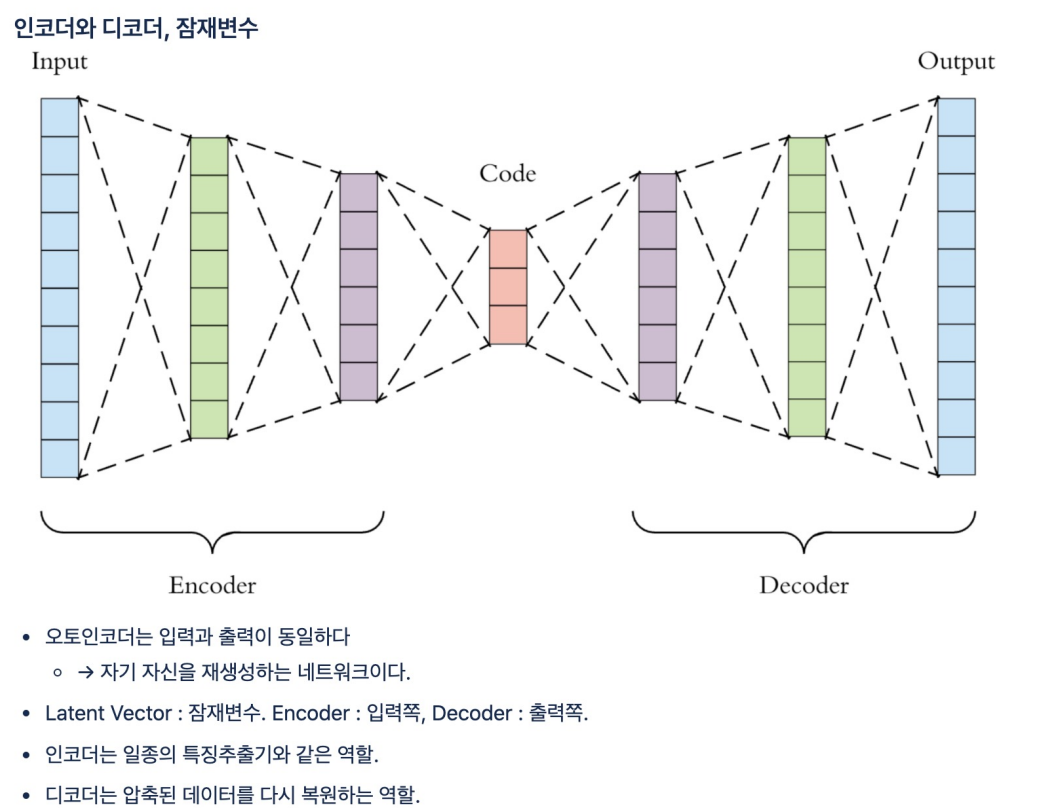
입력을 출력으로 가진다.시작은 28,28 인데 strides=(2,2)여서 2칸씩 이동하니까 Conv2D 한번 지나가면 (14,14), 한번 더 지나가면 (7,7)이되서 7x7x64가 된다.화질이 엄청 좋아짐3번 레이어에서 아웃풋을 뽑음 3번 레이어 -> 즉 오토인코딩
81.데이터 취업 스쿨 스터디 노트 -(75) YOLO
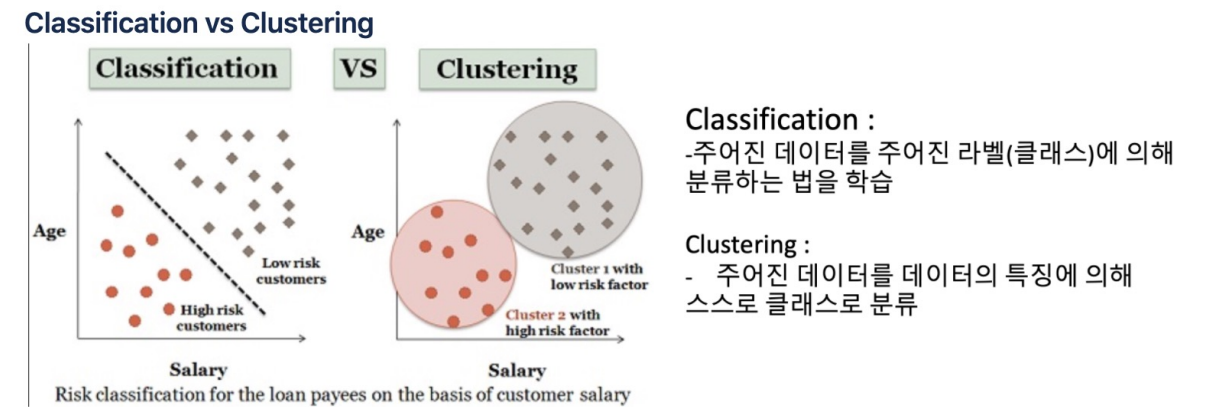
classification: 지도학습clustering: 비지도학습딥러닝이 큰 두각을 나타내고 있는 분야는 이미지이다.object Recognition -> object DetectionMLP(Multi layer Perceptron)의 문제점은 똑같은 1이라는 이미지
82.데이터 취업 스쿨 스터디 노트 -(76) RNN, LSTM, RNN-감정분석
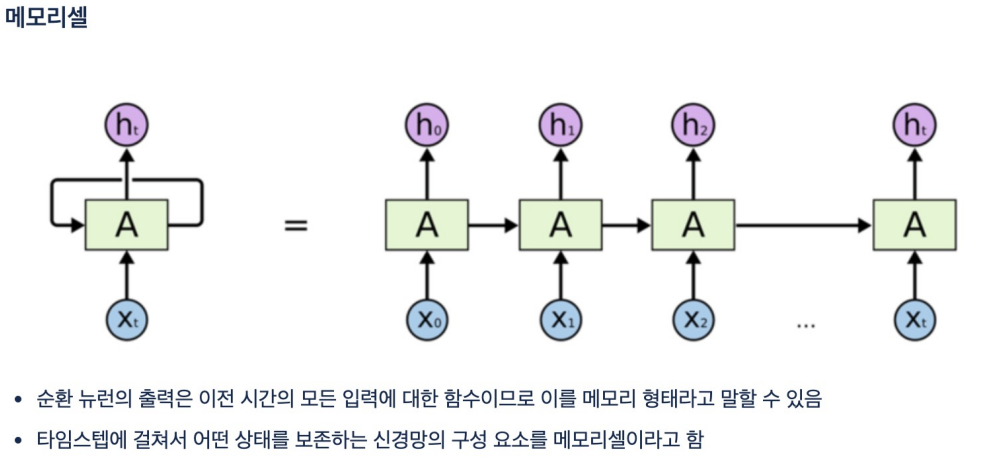
순환신경망활성화 신호가 입력에서 출력으로 한 방향으로 흐르는 피드포워드 신경망순환 신경망은 뒤쪽으로 연결하는 순환 연결이 있음순서가 있는 데이터를 입력으로 받고변화하는 입력에 대한 출력을 얻음메모리셀이전 셀의 출력을 가지고 다음을 진행함.이전 셀의 출력은 출력층과 다음
83.데이터 취업 스쿨 스터디 노트 -(77) 텐서플로우
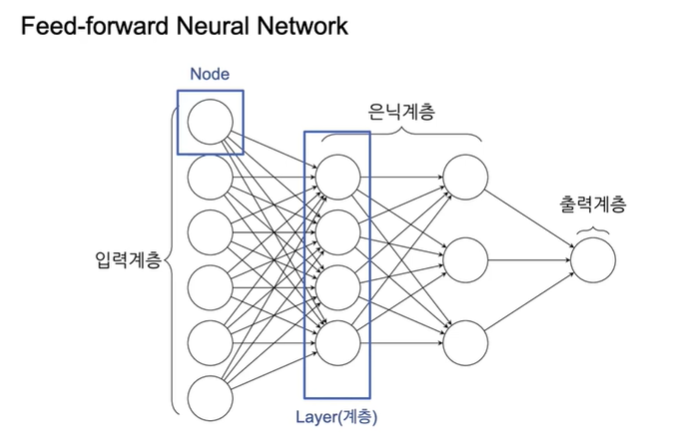
딥러닝의 가장 기본적인 형태연산량이 어마어마하다.딥러닝 모델의 성능이 안나오는 이유중 하나는 파라미터는 엄청 많은데 그거에 대응할 만한 데이터의 수가 부족한 경우가 많다.기존 머신러닝 알고리즘과 딥러닝의 차이는 연산량에서의 비약적인 차이가 있다.이 많은 연산을 빠르고
84.데이터 취업 스쿨 스터디 노트 -(78) Tensor 다루기
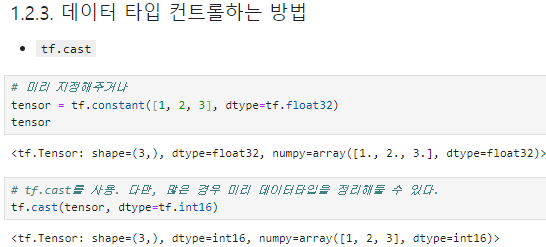
차원이 맞지 않는경우하나는 int인데 다른 하나는 float인 경우tensor 생성시 dtype 지정tf.casttf.random.set_seed()random seed를 관리하지 않으면 운좋을때는 좋게 나오고 운 나쁠때는 안좋게 나옴. 그래서 내가 어떤것으로 진행했는
85.데이터 취업 스쿨 스터디 노트 -(79) 최적화 - 자동미분, linear regression 실습, 당뇨병 데이터, perceptron

텐서플로에서 자동미분은 tf.GradientTape로 한다.with문 뒤의 코드가 다 실행된 상태로 내부 코드(y=x^2)가 실행된다.GradientTape은 Variable에 대한 미분값만 추정한다. 상수(constant)가 아니다.tf.Variable만 기록 합니다
86.데이터 취업 스쿨 스터디 노트 -(80) 간단한 모델학습 시키기
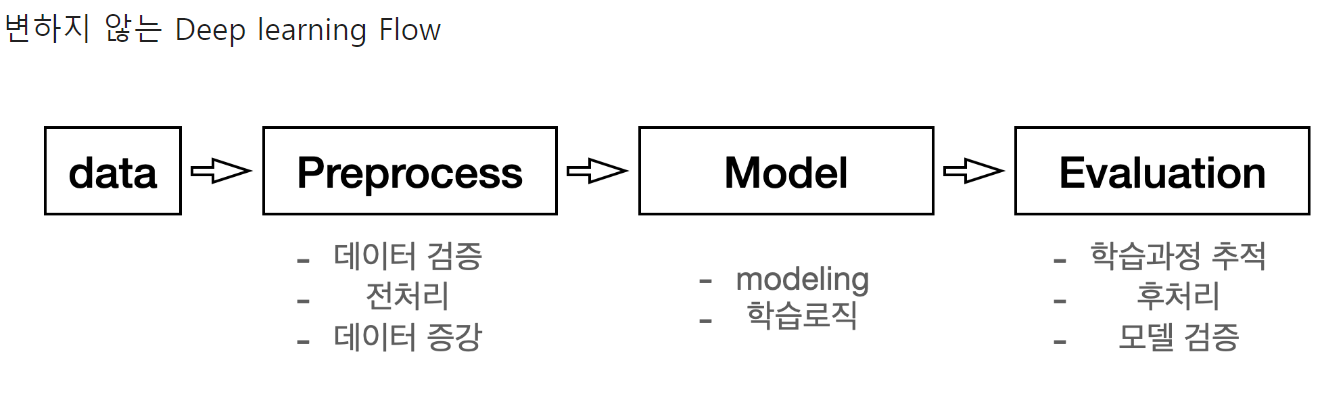
데이터 전처리 스케일링 모델링 CNN(VGGNet)-Sequencial, Functional 모델링, subClass 모델링
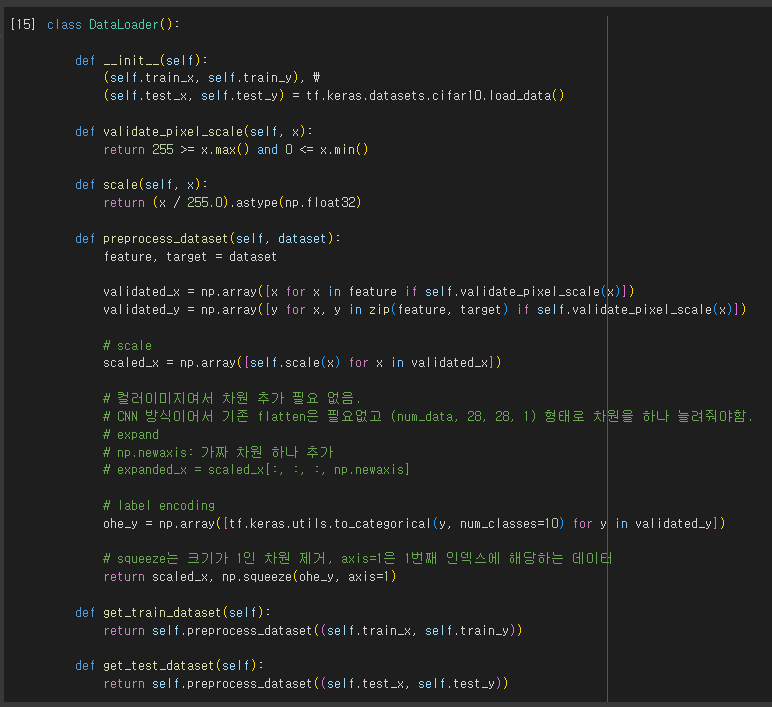
다시 살펴보기 CNN VGGNet에서 사용되는 Layer들 > tf.keras.layers.Conv2D tf.keras.layers.Activation tf.keras.layers.MaxPool2D tf.keras.layers.Flatten tf.keras.layer
88.데이터 취업 스쿨 스터디 노트 -(82) 모델학습
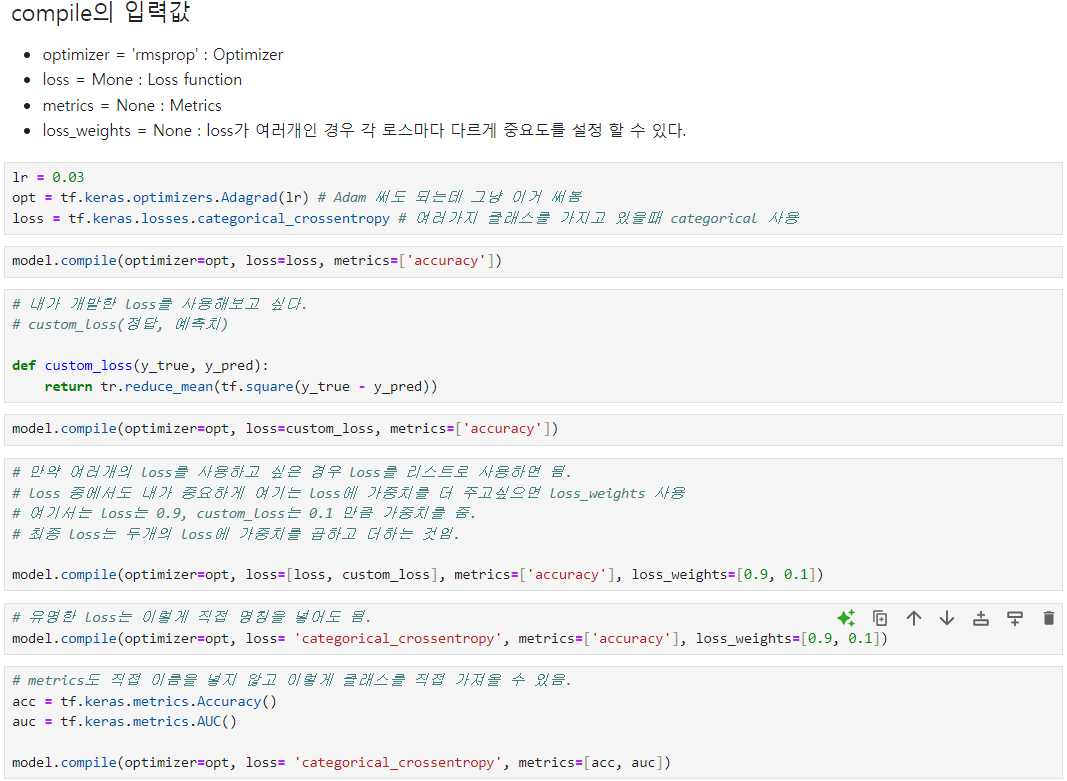
데이터 불러오는 코드는 생략Callback 함수 활용@tf.function 참고
89.데이터 취업 스쿨 스터디 노트 -(83) Tensorboard, 모델 저장/불러오기
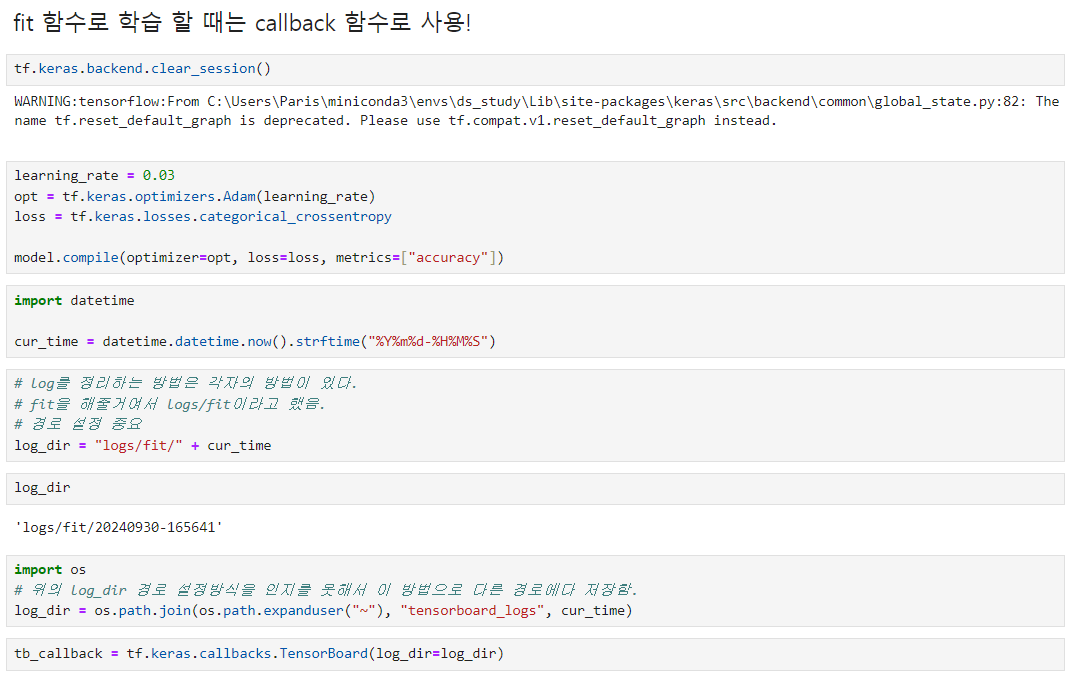
데이터로드는 생략
90.데이터 취업 스쿨 스터디 노트 -(84) 데이터 다루기
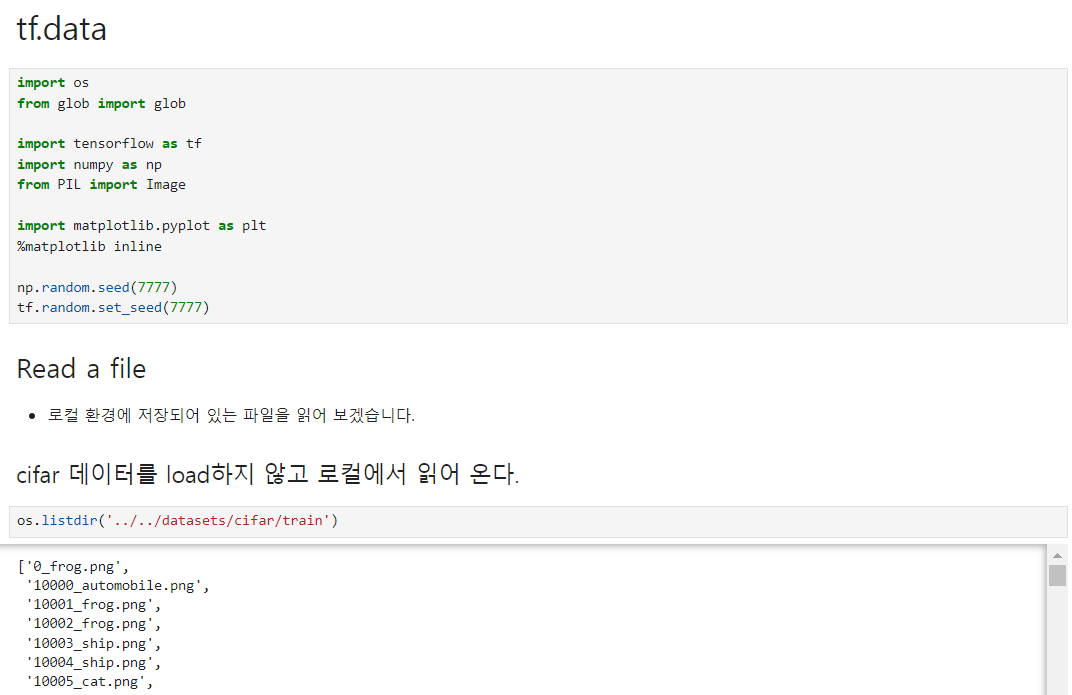
만약 이미지가 수백만장이라면?
91.데이터 취업 스쿨 스터디 노트 -(85) pytorch - Tensor 다루기
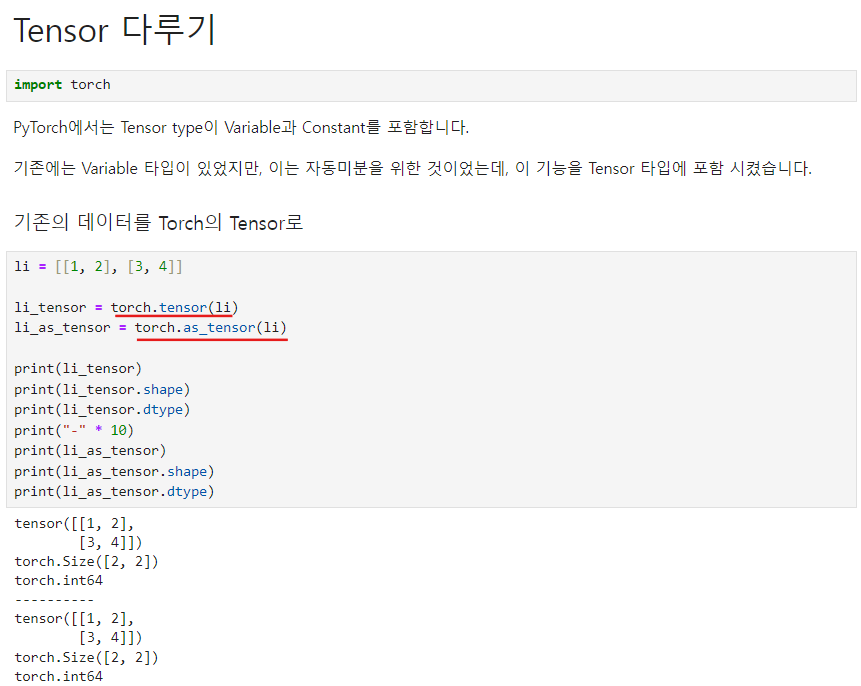
.shape().size()
92.데이터 취업 스쿨 스터디 노트 -(86) pytorch - 자동미분, linearRegression
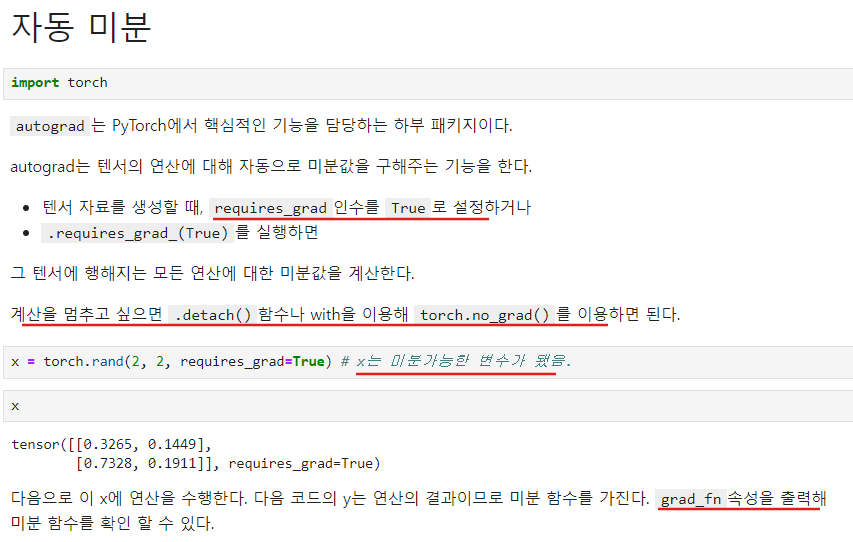
pytorch에는 torch.variable() 이런게 없다. 모든게 Tensor이다.그래도 constant와 variable을 구분해서 미분값을 트래킹해야하므로 이럴때 requires_grad인수를 True로 설정함.
93.데이터 취업 스쿨 스터디 노트 -(87) pytorch - 전체 딥러닝 플로우 구현
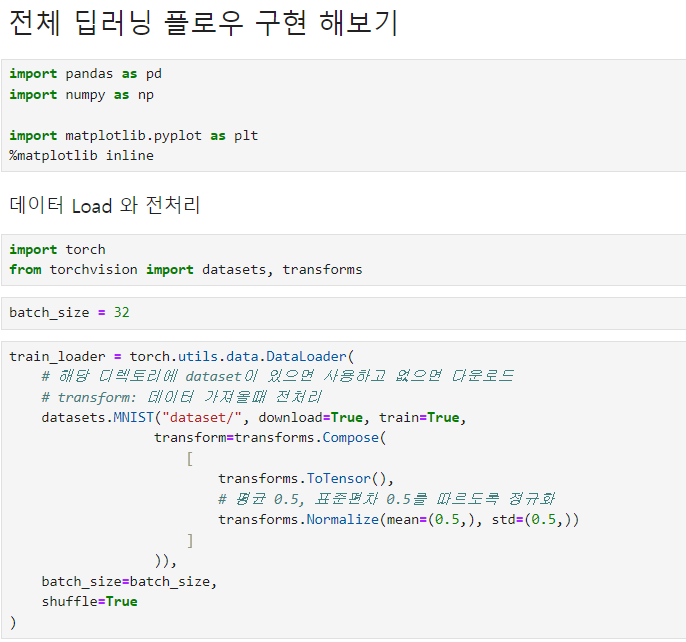
torch.utils.data.DataLoader()transforms.Compose()squeeze()
94.데이터 취업 스쿨 스터디 노트 -(88) pytorch - 모델링
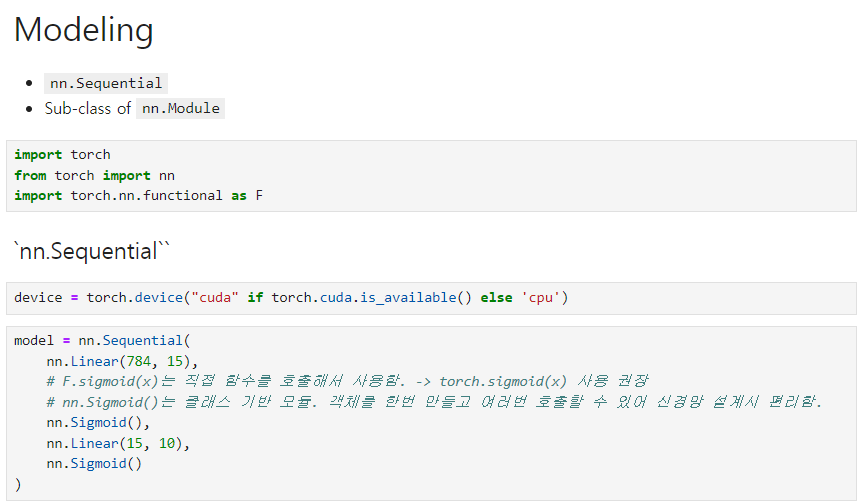
nn.Sequential nn.module sub class 간단한 ResNet 구현  pytorch - 모델 학습, 모델 저장
이전에 만들어뒀던 모델epoch만 바꿔서 기존 학습 방식대로 그대로 학습하면 됨.ex)
96.데이터 취업 스쿨 스터디 노트 -(90) pytorch - DataLoader(이미지 폴더에서 가져오기), Custom dataset
torch.utils.data.DataLoader를 사용함.torch.utils.data.DataLoader는 기본적으로 아래 두 가지 인수를 받음torch.utils.data.dataset.Datasetbatch_size
97.데이터 취업 스쿨 스터디 노트 -(91) pytorch - Transforms
transforms.Resize(512, 512)(image)transforms.RandomCrop(size=(256, 256))(image) transforms.ColorJitter(brightness=1)(image)transforms.Grayscale()(imag
98.데이터 취업 스쿨 스터디 노트 -(92) 컴퓨터 비전 이해
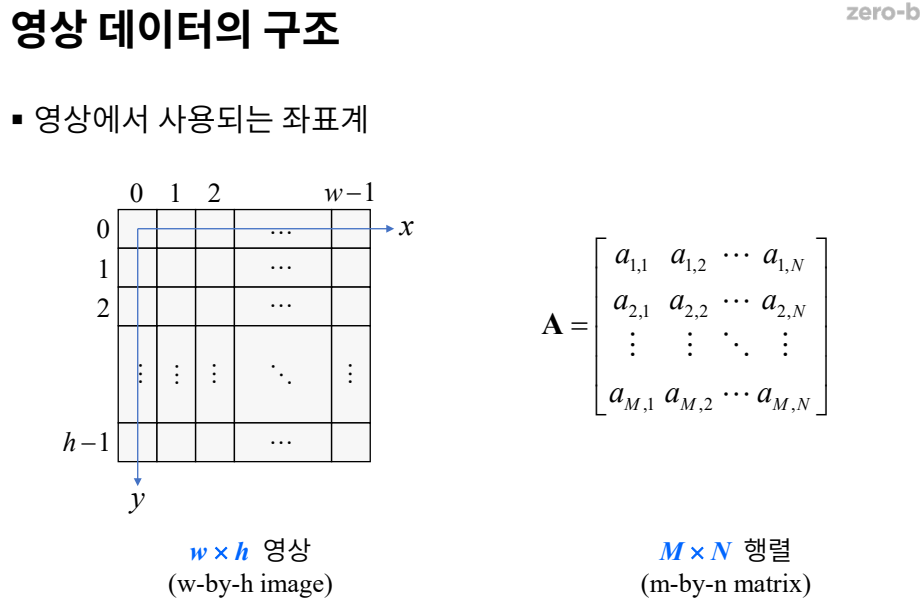
이미지를 표현할때: 가로크기 x 세로크기로 표현함(w x h)행렬을 표현할때: 세로크기 x 가로크기로 표현함(M x N)트루컬러 영상의 특징
99.데이터 취업 스쿨 스터디 노트 -(93) OpenCV, 주요 함수
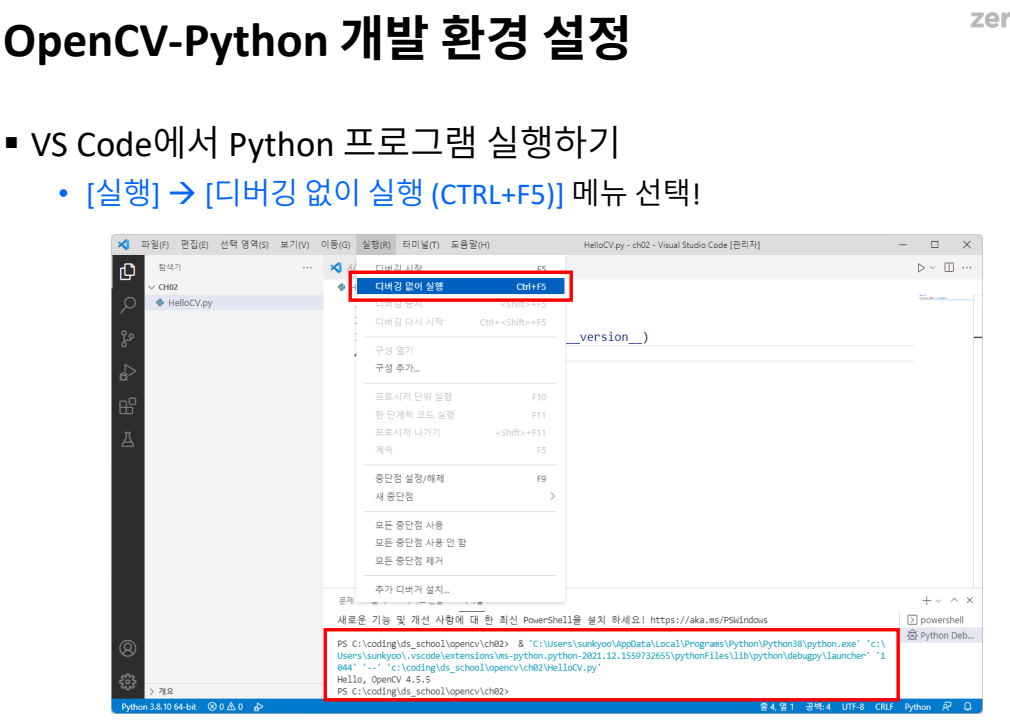
오픈소스로 개발되고있는 컴퓨터 비전/머신 러닝 소프트웨어 라이브러리파일 이름에 확장자까지 입력없어도 cv2.imshow() 명령어가 있으면 영상을 보여준다.window_normal: 마우스로 창 크기 조절할 수 있음.cv2.destroyWindow()cv2.destro
100.데이터 취업 스쿨 스터디 노트 -(94) OpenCV 기초 사용법 #1 (복사, crop, 참조, 마스크, 합성)

숫자 옆 빨간 점을 누르고 상단에서 Run -> 디버깅 시작하면 빨간 점부분까지만 실행된다. 그리고 img1 같은 변수에 마우스를 올려놓으면 속성 정보를 볼 수 있고 또한 좌측 Local에서도 확인할 수 있다.디버깅 종료하려면 상단 빨간 네모 누르면 됨.shape이 튜
101.데이터 취업 스쿨 스터디 노트 -(95) OpenCV 기초 사용법 #2 (그리기 함수, 카메라/동영상 처리, 동영상 저장)

원을 그리거나 문자열을 출력할 때 cv2.LINE_AA를 주로 선택함.shift는 사용할 일이 거의 없음선 두께를 음수값을 주면 내부를 채운다.
102.데이터 취업 스쿨 스터디 노트 -(95) 명함 검출과 인식

배경 vs 객체를 나누거나 관심있는 영역 vs 관심없는 영역으로 나누기 위해 사용함.f(x, y)는 픽셀값. T=200 이상은 밝은 영역에 대한 픽셀값이 모여있는 구간이므로 threshold를 200으로 잡음. 임의로 임계값을 줌이진화: threshold보다 작으면 0
103.데이터 취업 스쿨 스터디 노트 -(96) 얼굴 검출

shape에서 앞의 두 차원은 제외하고 뒤에 2개의 차원을 이용해 2차원 형태의 행렬로 변환해 사용함.c는 정확도의 개념(얼굴일 확률)(x1, y1), (x2, y2)는 왼쪽 상단 모서리, 오른쪽 하단 모서리의 좌표이다. 입력 영상의 사이즈에 해당하는 것이 아니라 전체
104.데이터 취업 스쿨 스터디 노트 -(97) GPT 및 자연어처리
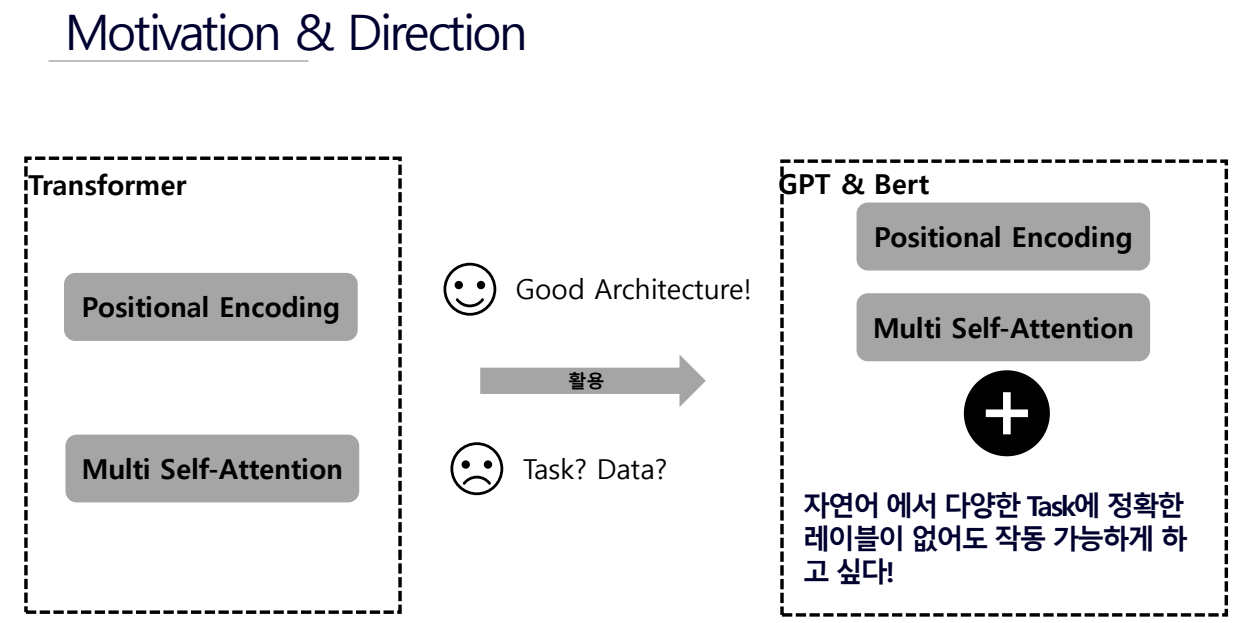
의미 단위로 쪼개는 것어떤 의미 단위로 쪼갤 것이냐하나의 문장을 여러 개로 나누고 나눈 토큰들의 결합분포로 문장에 대해서 확률을 계산 기본적으로 문장에 대해서 길이가 번역 or 생성된 문장이 길이가 얼마나 비슷한지 측정함.자연어처리는 정량적인 분석이 힘들긴 하다.
105.데이터 취업 스쿨 스터디 노트 -(98) Transformer
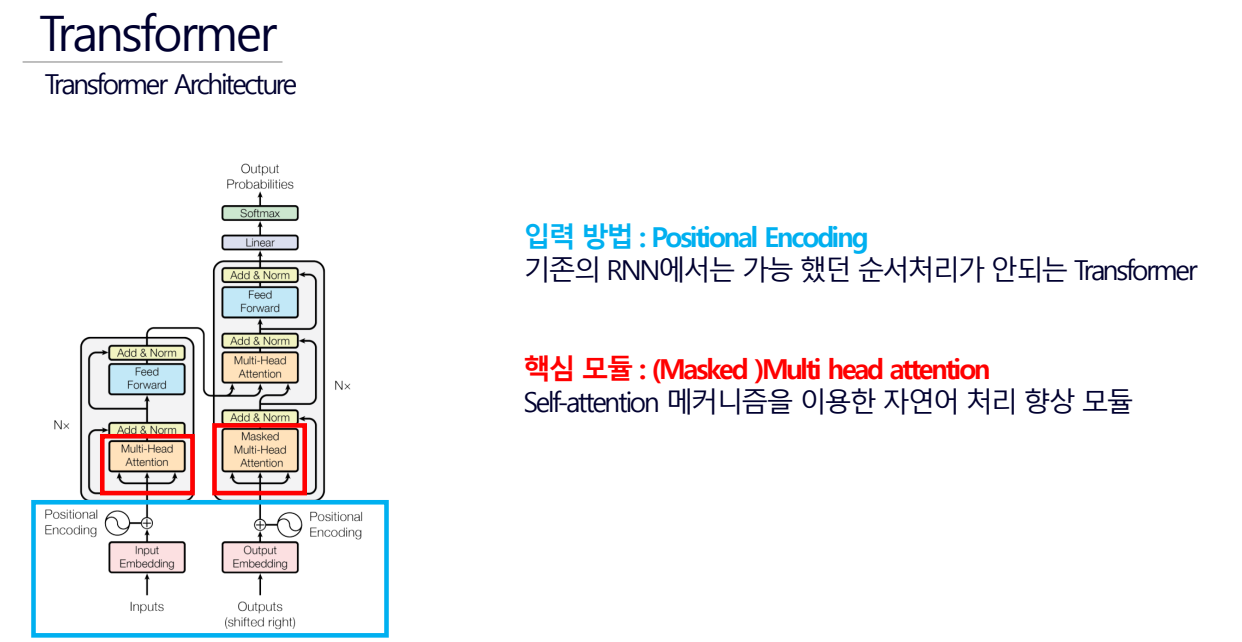
106.데이터 취업 스쿨 스터디 노트 -(99) BERT, GPT

인풋데이터는 많은데 레이블은 적다.Fine tunning은 pre train을 먼저하고 거기서 학습된 weight를 가지고 Fine tunning을 함.레이머마다 파라미터를 고정시킬 수 있다.내가 해결하려는 데이터셋이 적을 때 그거와 유사한 다른 데이터셋에서 프리 트레
107.데이터 취업 스쿨 스터디 노트 -(100) Hugging face 라이브러리
일반 버전: pip install transformers개발자 버전: pip install transformerssentencepiece허깅 페이스에 있는 데이터셋: pip install datasets
108.YOLO를 활용한 식재료 분류 및 요리 레시피 추천 딥러닝 프로젝트#1
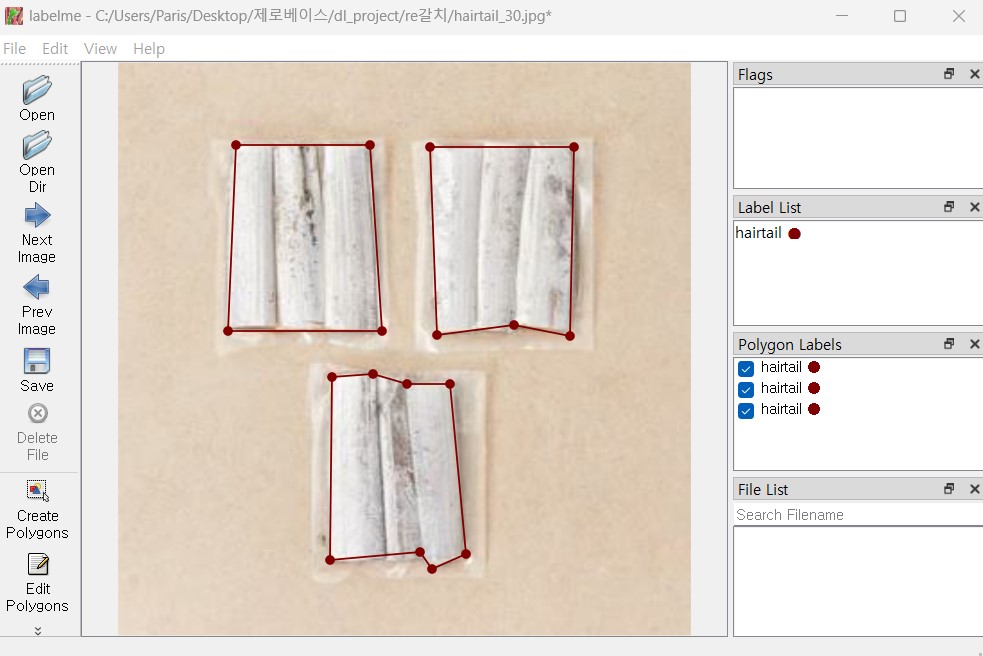
1인 가구가 증가하고 특히나 오늘은 무엇을 먹을지 고민하는 것들은 특히나 자취를 하는 사람들에게는 언제나 고민이 되는 부분이다. 이런 부분들을 조금 더 수월하게 해결하기 위해 냉장고 속 식재료를 YOLO 모델을 통해 인식하고 해당 재료로 만들어 먹을 수 있는 음식과 레
109.YOLO를 활용한 식재료 분류 및 요리 레시피 추천 딥러닝 프로젝트#2(Chatgpt api 연동)
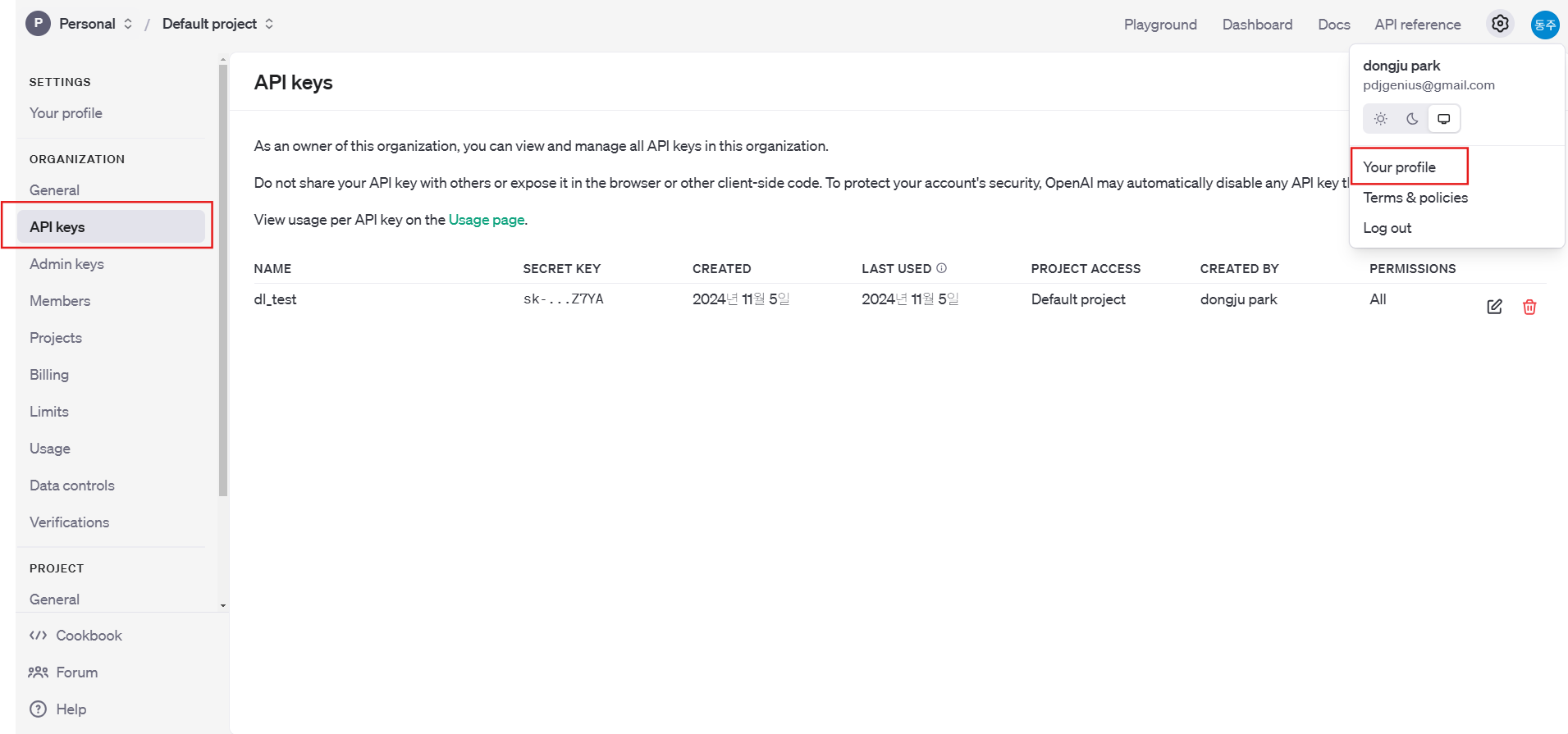
https://platform.openai.com/docs/overview?lang=python위 링크를 참고해도 되지만 초보자를 위해서 딱 이렇게 하면 된다라는 정보가 없어 이 간단한 코드를 테스트 해보는데도 정말 오랜 시간이 걸렸다. 처음에는 결제를 해야하
110.YOLO를 활용한 식재료 분류 및 요리 레시피 추천 딥러닝 프로젝트#3 (추가 라벨링 이미지 병합 주의!)
이미지 분류 학습결과 고등어의 성능이 너무 좋지 않게나왔다.물론 고등어 이미지를 더 구해서 학습시키는 방법이 제일 좋지만 최종 발표까지의 시간이 얼마 없어 수정할 수 있는다른 부분을 살펴봤다.그 와중에 학습한 이미지의 평가를 위한 val 폴더에있는 고등어의 이미지가 아
111.8시간의 사투. MMDetection 설치와 호환 버전의 중요성

나는 아직도 모르는 것이 많다. 공식 문서를 보는 것 부터 문제를 찾고 코드를 다루는 것 까지 부족한 것 투성이다. 특히나 프로그램이나 라이브러리를 설치할 때는 "최신 버전이 무조건 좋은거 아닌가?"라는 생각 때문에 최신 버전을 선호한다.하지만 파이썬을 다루면서 이 생