pandas
- 파이썬에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
import pandas as pd로 사용함.
cf) from MODULE import function
- MODULE에 포함된 function 이라는 함수만 사용하겠다.
pandas에서 엑셀 및 텍스트 파일 읽기
./ : 현재 디렉토리
../ : 상위 디렉토리
- 한글은 encoding 설정이 필수
.head(): 앞에 5개만 보여줘라
.head(10): 10개만 보여줘라
.tail(): 뒤에 5개만 보여줘라

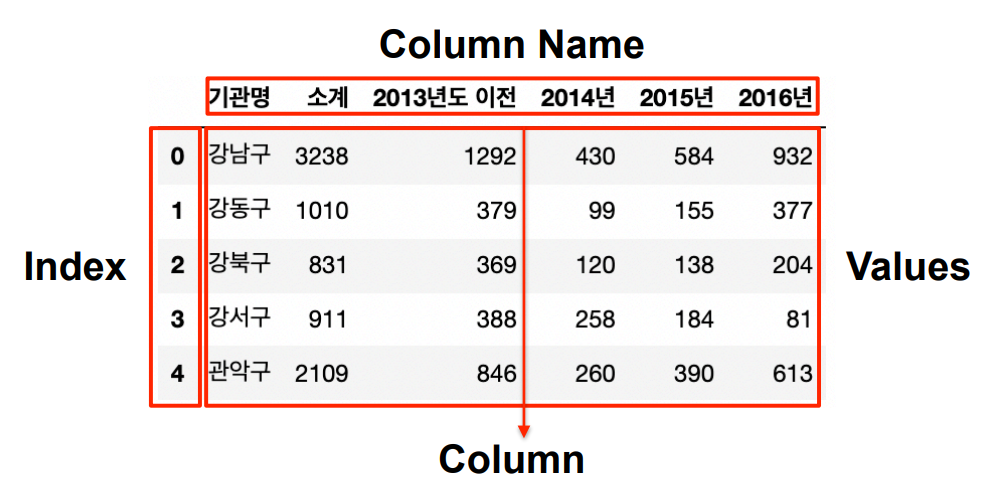
컬럼 확인하기
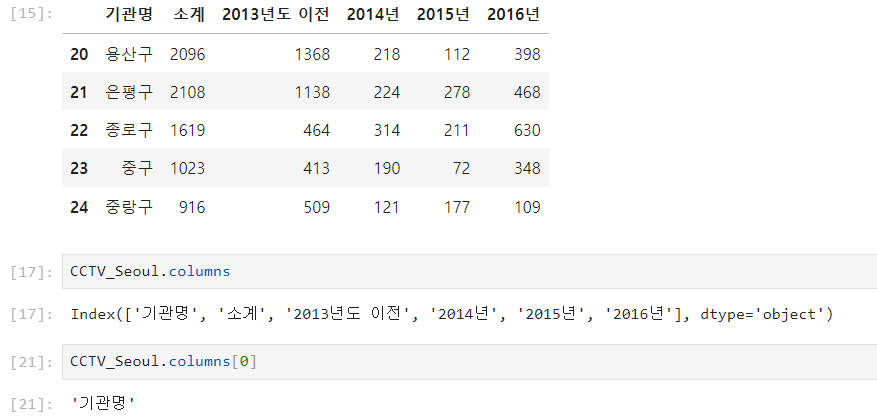
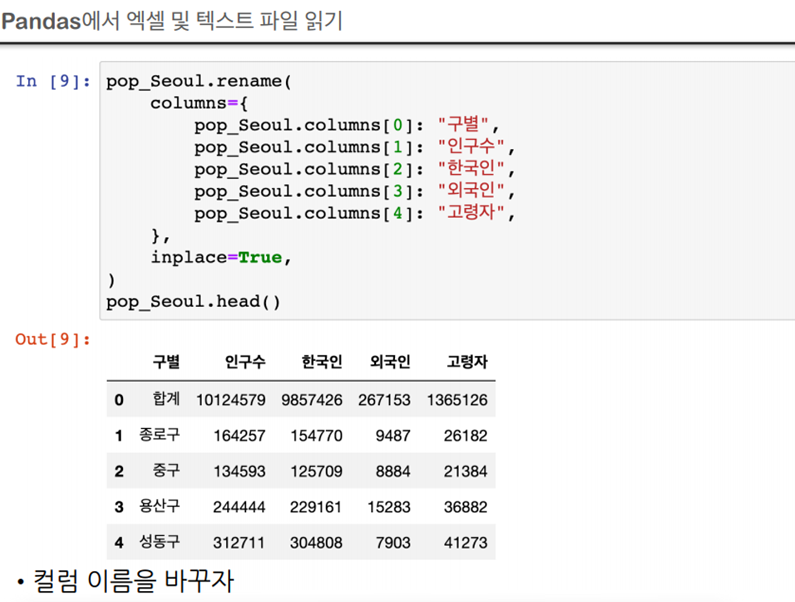
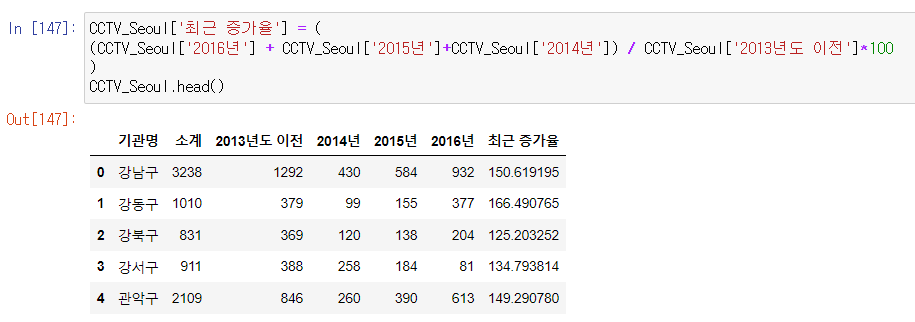
컬럼 이름을 바꾸고 싶다면
: CCTV_Seoul.rename(columns = {CCTV_Seoul.columns[0]: '구별'}, inplace=True)
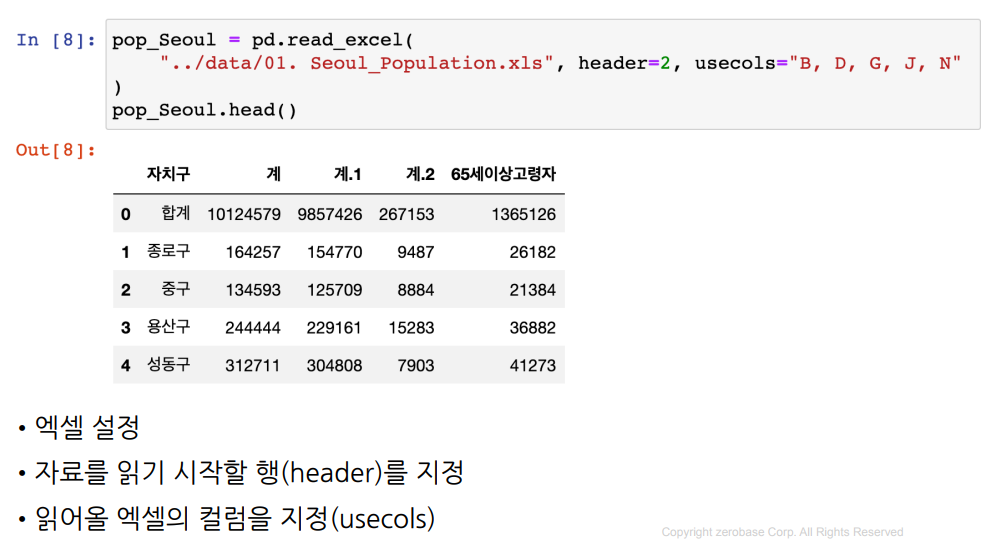
엑셀 불러오기
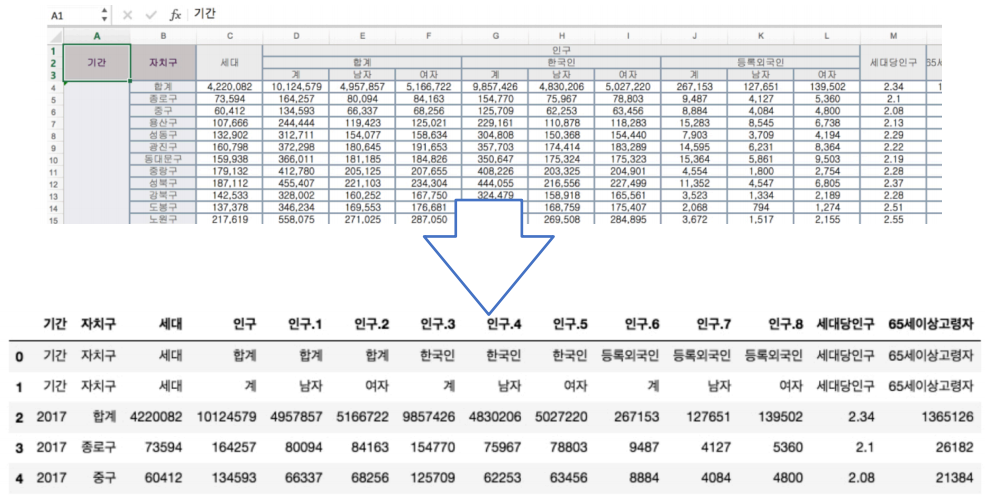
pandas rename 과 같이 구글에 검색하면 pandas 공식 홈페이지에 각 함수들을 어떻게 사용하는지 나와있음. 함수를 다 외우기 보다는 그것을 잘 활용하는 것이 중요함.
마크다운 하는 방법
#텍스트를 입력한 상태에서 esc를 눌러 왼쪽 세로선을 파란색으로 변하게 한 상태에서 m을 누르면 됨.
#의 개수에 따라 텍스트 크기가 조절됨.
shift + enter를 누르면 아래처럼 바뀜


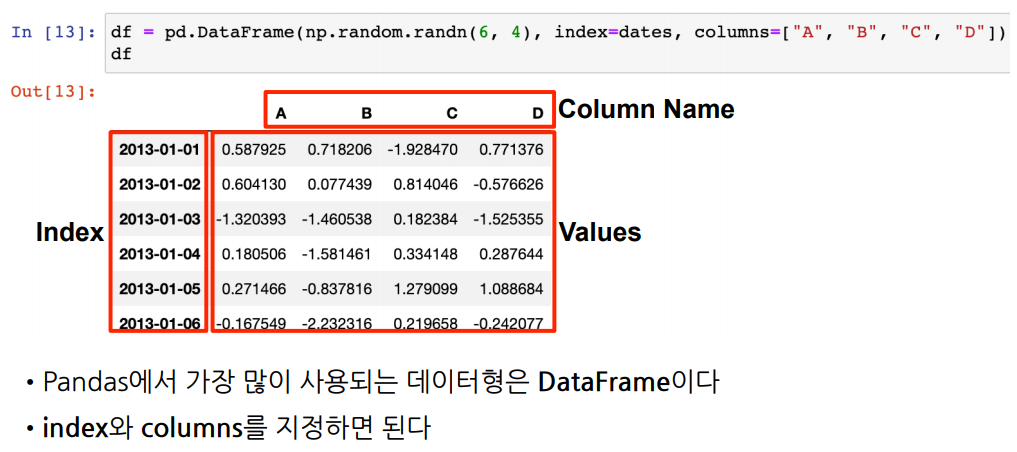
pandas를 구성하는 데이터형을 구성하는 기본은 Series이다.
- 컬럼 기준으로 한줄 한줄이 Series이다.

- index와 value로 이루어져 있다
- 한가지 데이터 타입만 가질 수 있다
날짜 데이터
pd.date_range('start', 'end')
start: 데이터의 시작 날짜/시간 지정
end: 데이터의 끝 날짜/시간 지정
periods: 기간의 수 지정
이 외에도 freq, tz, normalize 등 여러가지가 있다.

모르는 함수는 괄호안에 커서를 놓고 shift+tab을 누르면 함수 정보를 볼 수 있다.
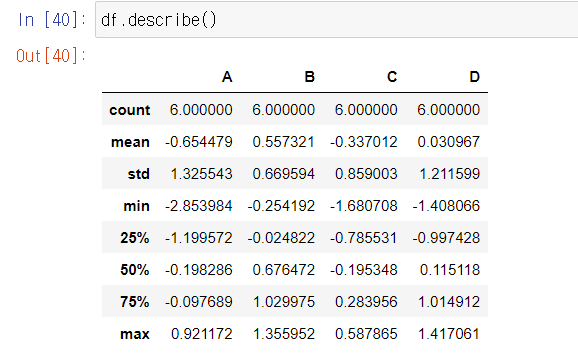
.describe(): 데이터 프레임의 기술통계 정보 확인
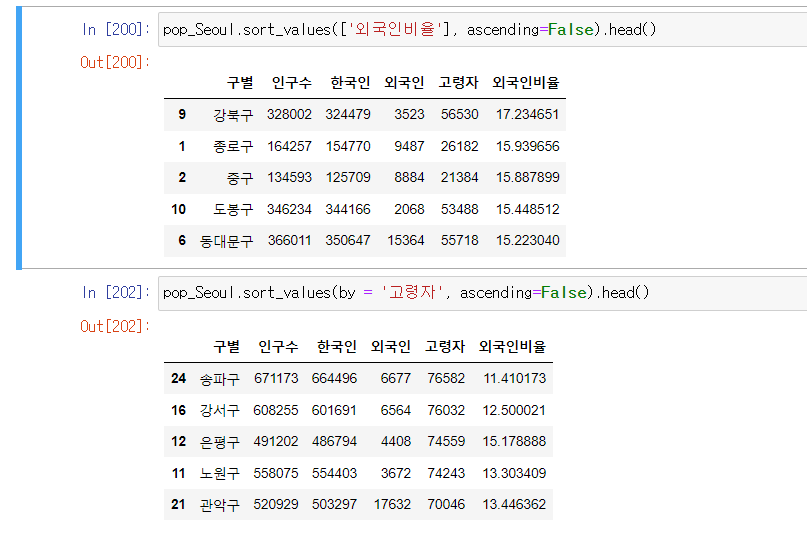
.sort_values(): 데이터 정렬
ex)
df.sort_values(by='B', ascending=False)
B를 정렬 기준으로 잡음, DESC로
한개 컬럼 선택
df['A'] or df.A
인덱스가 문자면 df.A 형태가 가능하지만 숫자면 불가능하다.
두개 이상 컬럼 선택
df[['A','B']]
offset index
[n:m] -> n 부터 m-1 까지
인덱스나 컬럼의 이름으로 slice 하는 경우는 끝을 포함한다
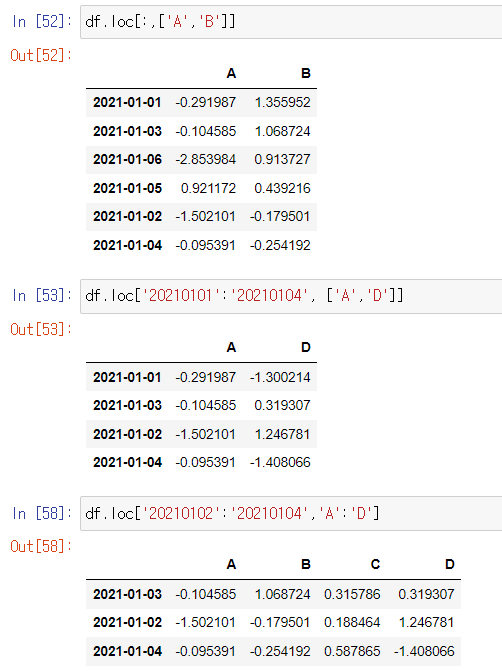
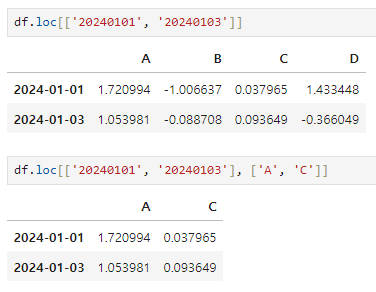
loc: location
index 이름으로 특정 행, 열을 선택한다
특정 행을 정하고 특정 열을 정해 추출
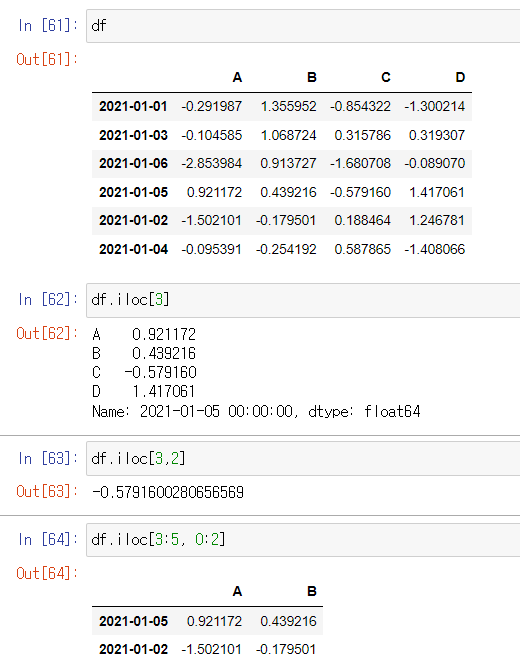
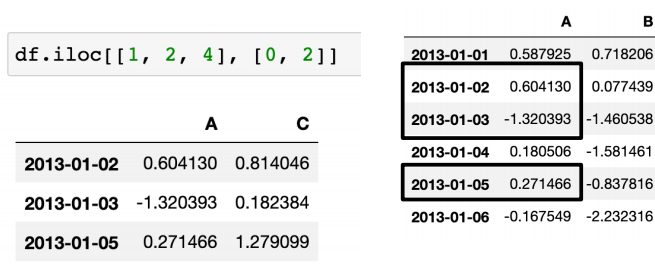
iloc: inter location
- 컴퓨터가 인식하는 인덱스 값으로 선택
- 보이지는 않더라도 0부터 인덱스 값이 메겨져있다.
조건(condition)
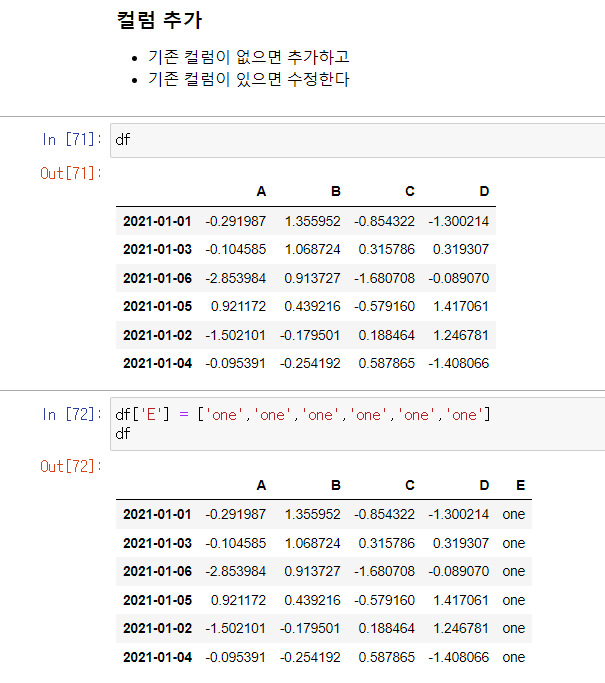
컬럼 추가
isin()
- 특정 요소가 있는지 확인 True, False로
- 표처럼 제대로 출력하려면 해당 데이터프레임으로 한번 더 감싸야함.
ex) df[df['E'].isin(['two', 'five'])]
특정 컬럼 제거 del, drop
- del
- drop
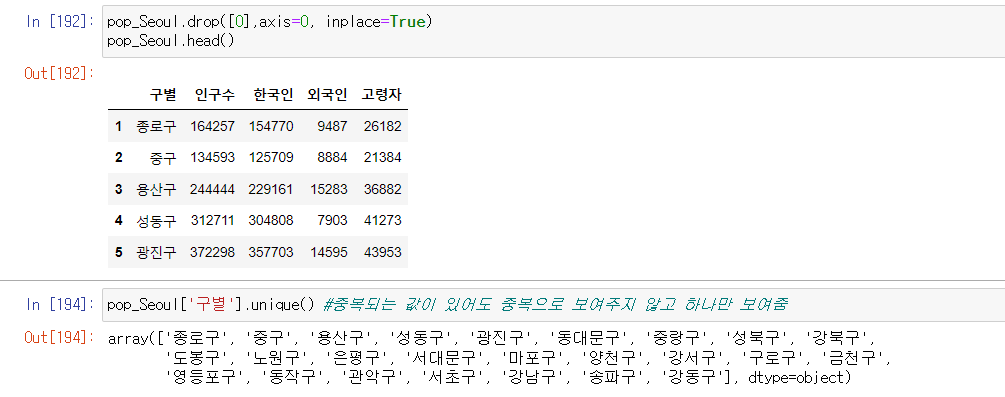
df.drop([0,1,2], axis=0, inplace=True) # 가로로 0,1,2 인덱스 행 제거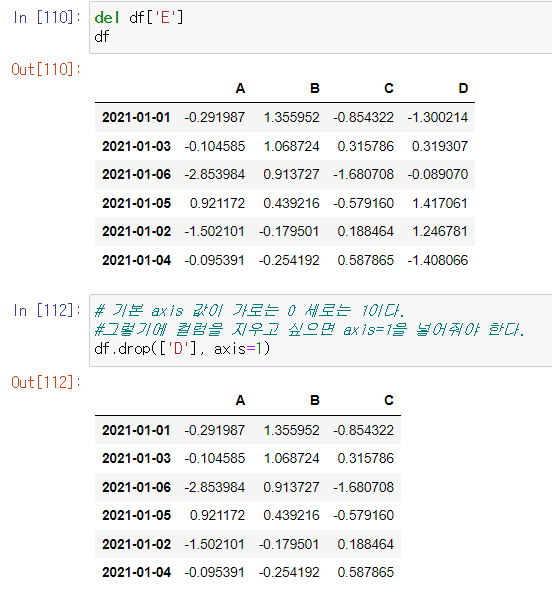
unique()
중복되는 값이 있어도 중복으로 보여주지 않고 하나만 보여줌
cf) sort_values() 함수를 사용할 때 by='컬럼명' 이랑 ['컬럼명']이랑 똑같다.
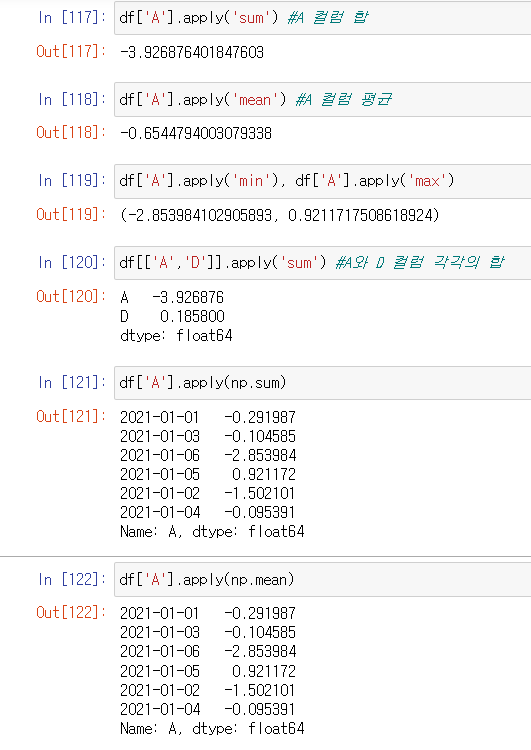
apply()
함수를 적용한 결과값이 출력됨.
pandas에서 데이터 프레임을 병합하는 방법
- pd.concat()
- pd.merge()
- pd.join
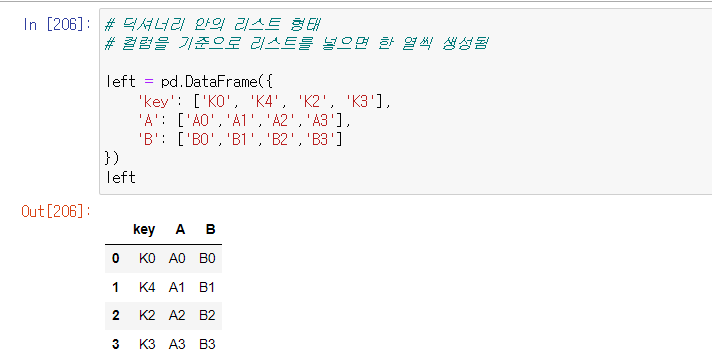
데이터프레임 생성 2가지 방법
1.딕셔너리 안의 리스트 형태
- 컬럼을 기준으로 리스트를 넣으면 한 열씩 생성됨
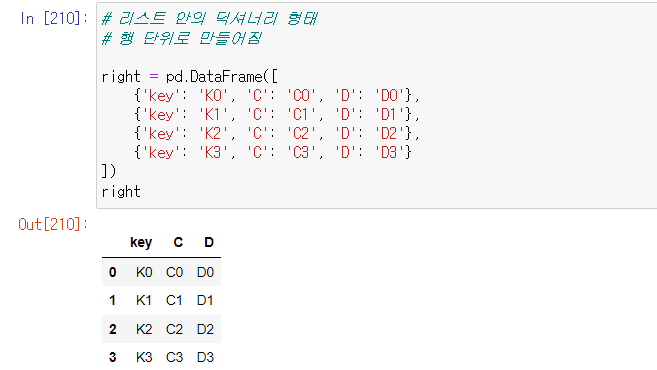
2.리스트 안의 딕셔너리 형태- 행 단위로 만들어짐
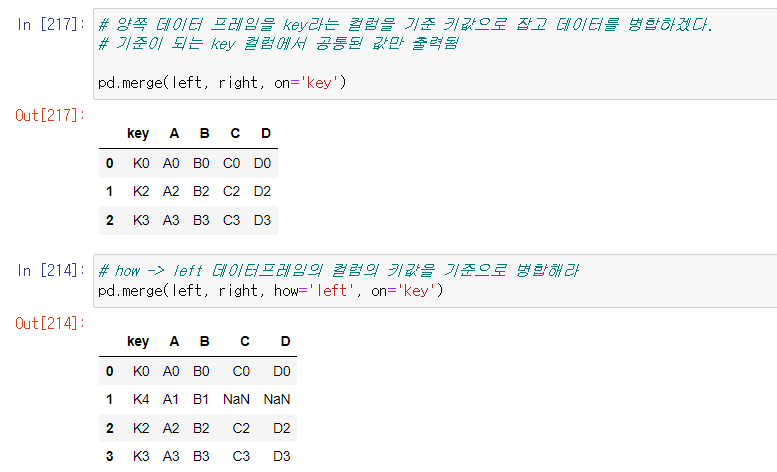
pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 한다.
- 기준이 되는 키 값은 두 데이터 프레임에 모두 포함되어 있어야 한다.

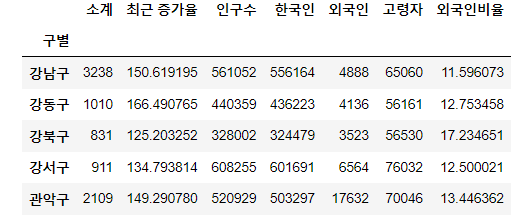
인덱스 변경 set_index
- set_index()
- 선택한 컬럼을 데이터 프레임의 인덱스로 지정
data_result.set_index('구별', inplace=True)
인덱스를 변경 후 0부터 시작하도록 초기화.
df.reset_index(drop=True, inplace=True) # drop: True기존의 인덱스를 새로운 컬럼으로 추가하지 않음.
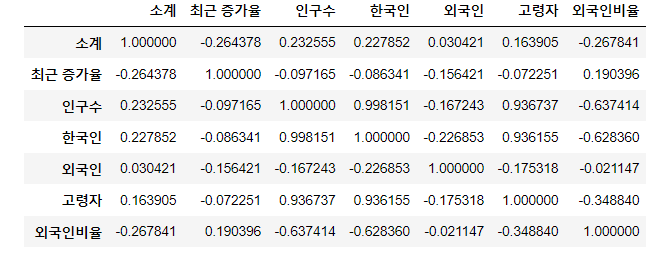
상관계수
- corr
- correlation의 약자
- 상관계수가 0.2 이상인 데이터를 비교
cf) 추가 메모
데이터프레임 1000의자리 숫자 콤마 지우기
ex)
df.replace(',','', regex=True) # regex=True(정규표현식) 이거 없으면 정확히 일치하는 것만 바꿈데이터 타입 변경
apply(), astype() 둘다 동일한 방식으로 사용 가능
ex)
df['컬럼명'].astype(float)
df['컬럼명'].apply(float)그냥 이렇게만 끝나면 실행했을 때만 변경되고 다시 원래대로 돌아감.
그렇기에
df['컬럼명'] = df['컬럼명'].astype(float)
이렇게 해야 실제 데이터에 반영됨.
