데이터 취업 스쿨 스터디 노트 -(51) Decision Tree를 이용한 와인데이터 분석(Pipeline, 교차검증(kfold), cross validation, GridSearchCV
제로베이스 데이터 스쿨(Data Science & Analytics)
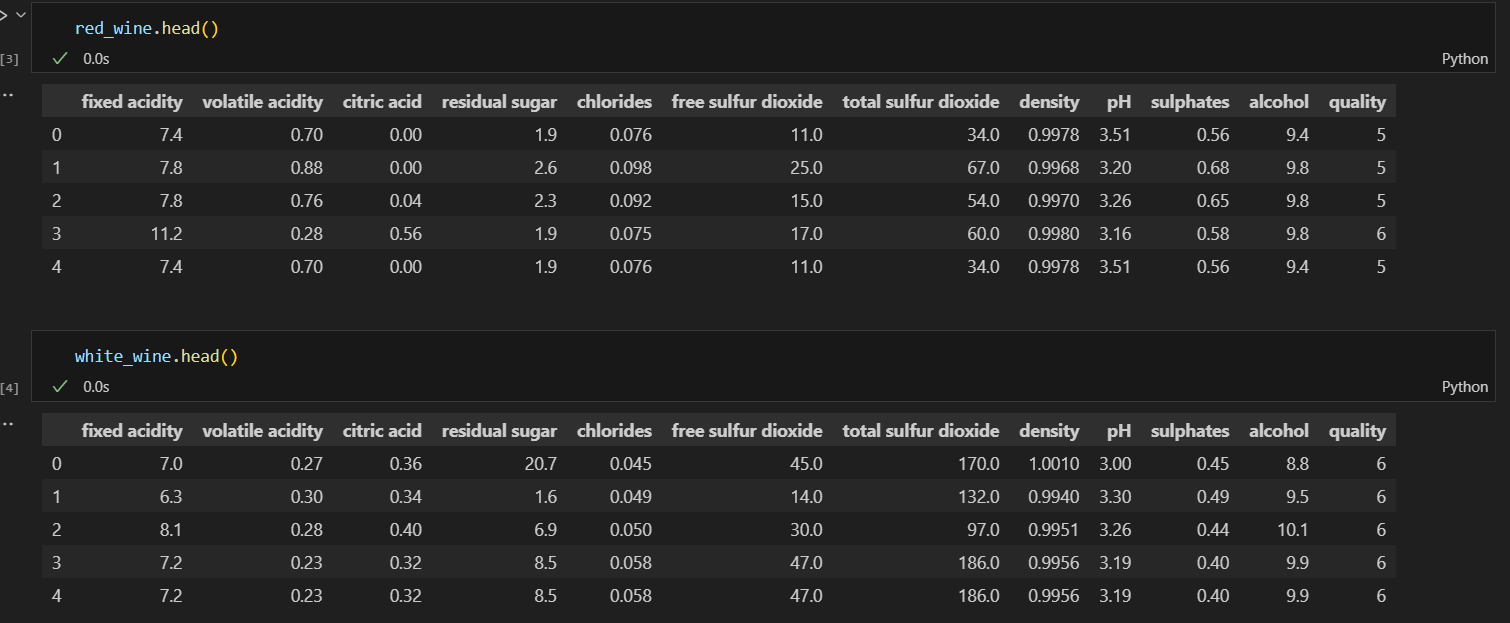
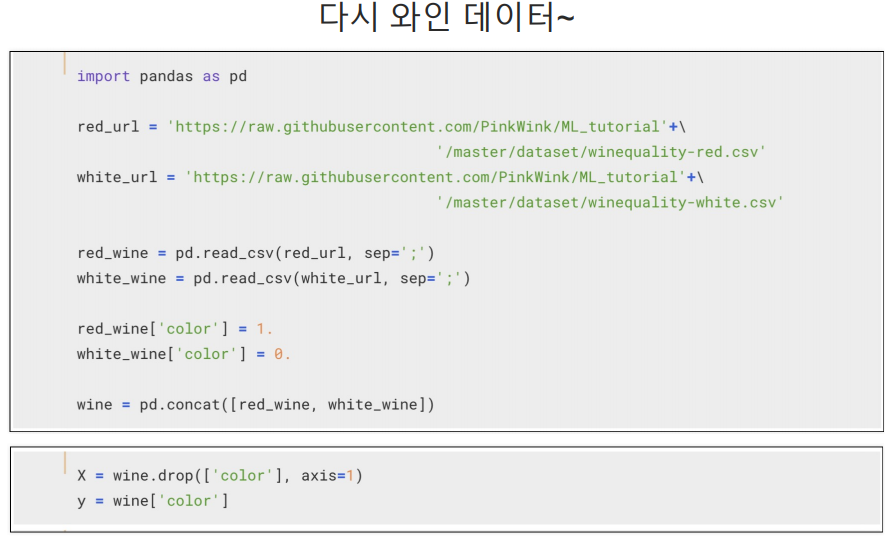
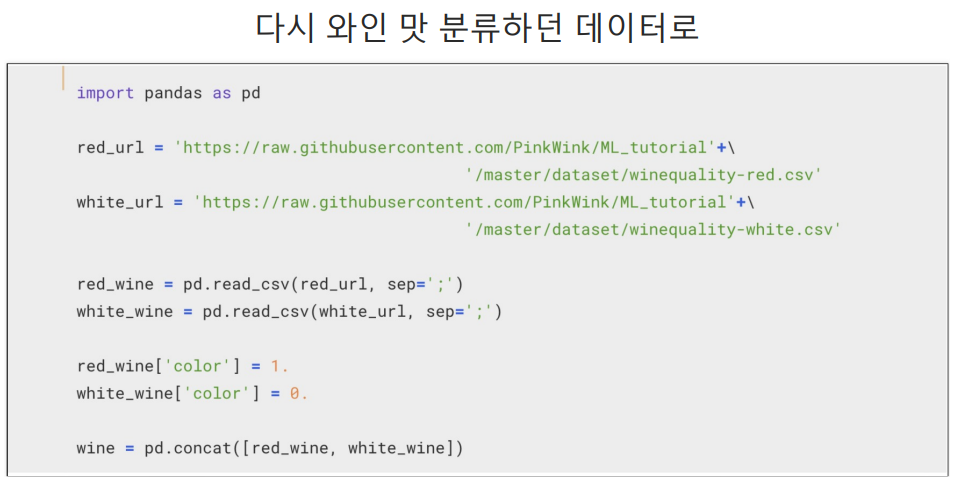
데이터 불러오기

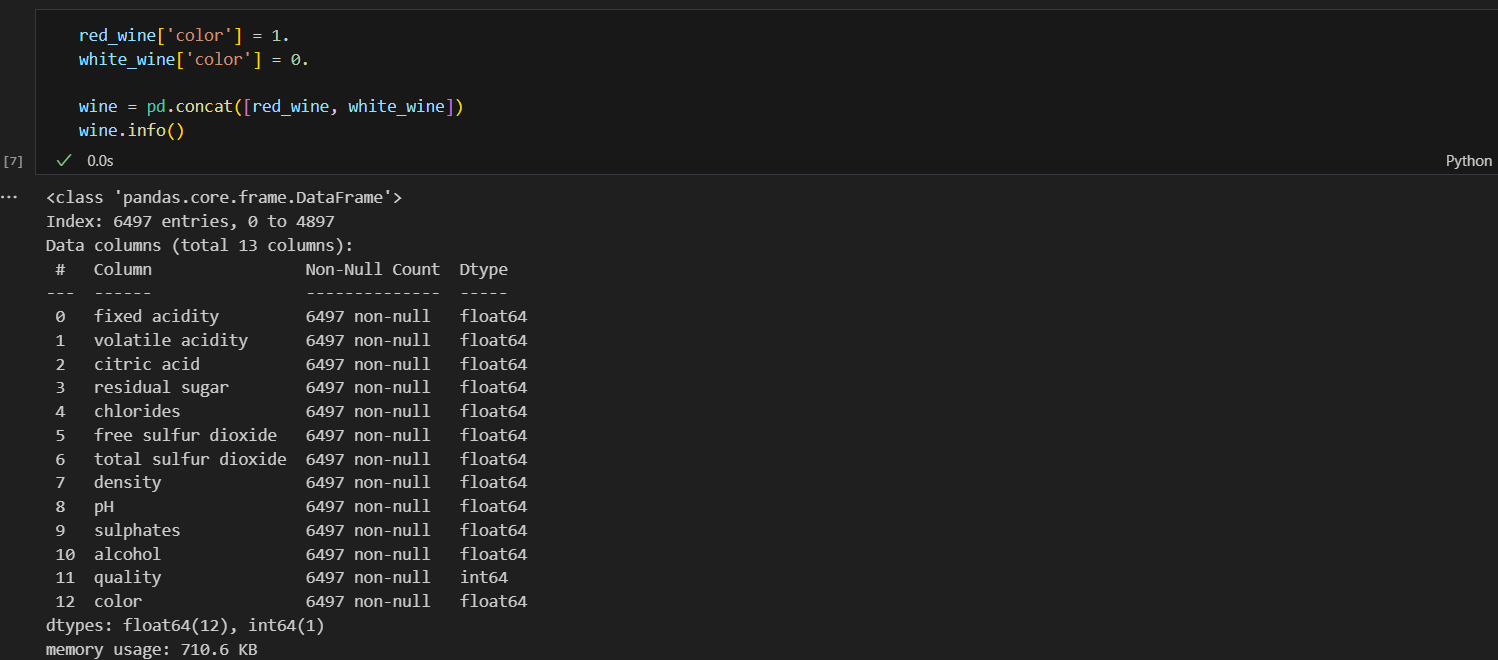
두 데이터를 하나로 합치기
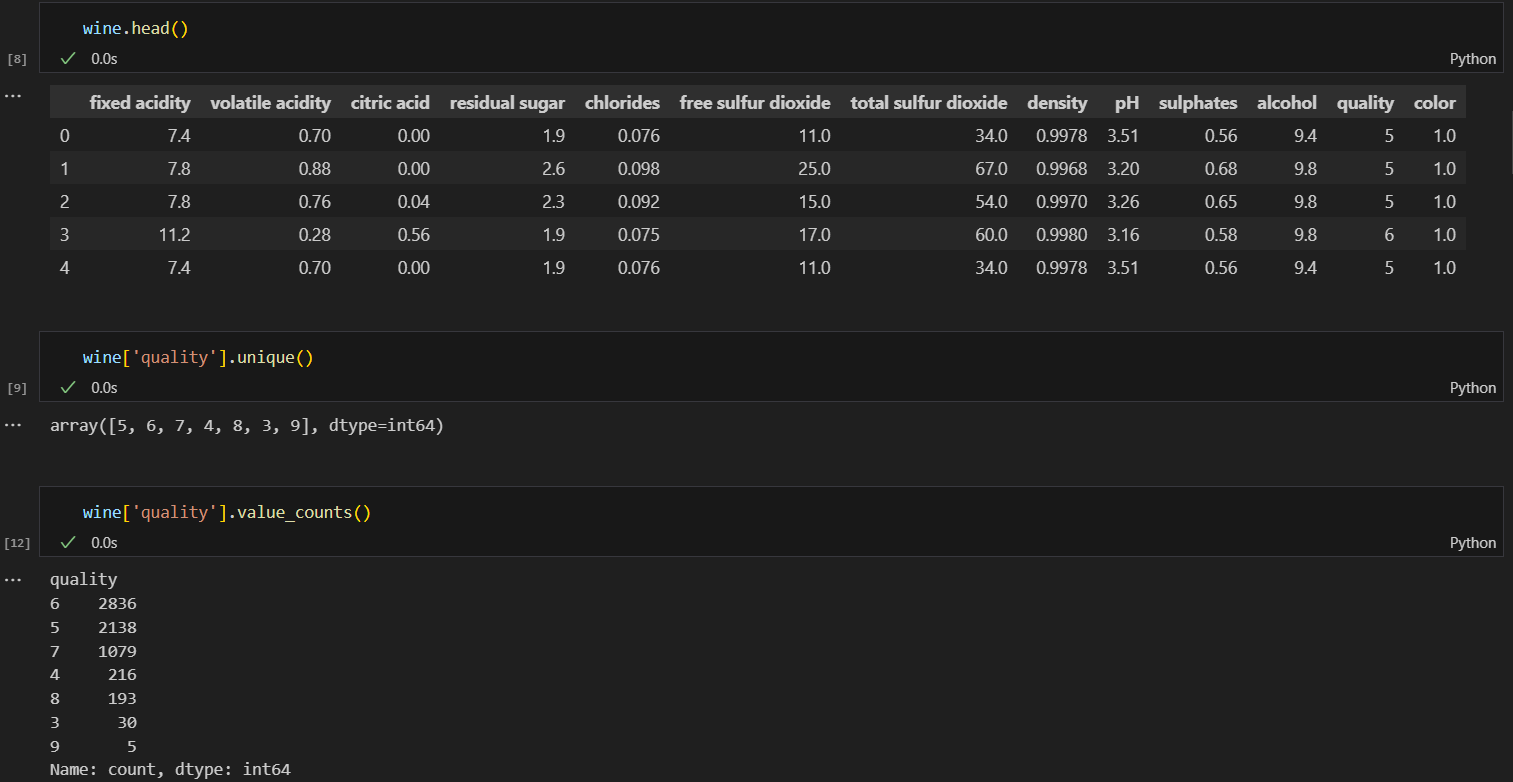
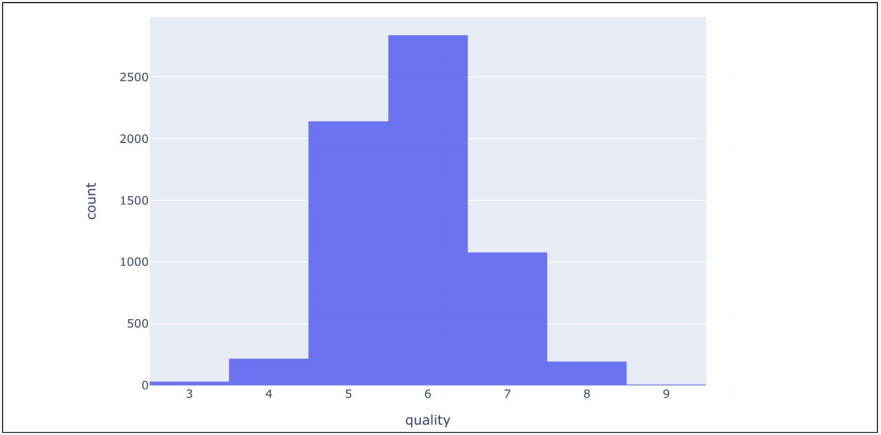
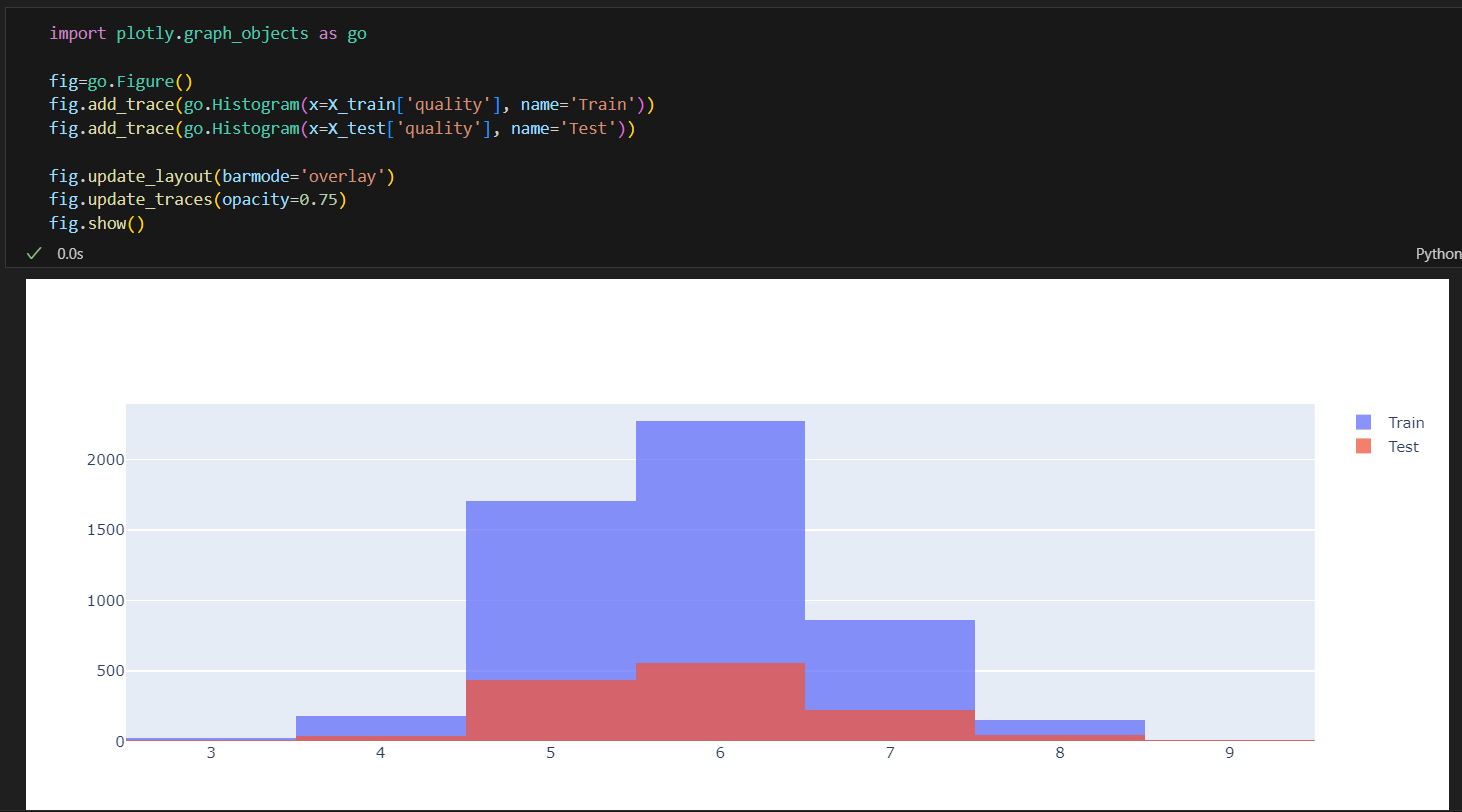
quality컬럼은 3에서 9등급 까지 있다.
히스토그램으로 그려보기


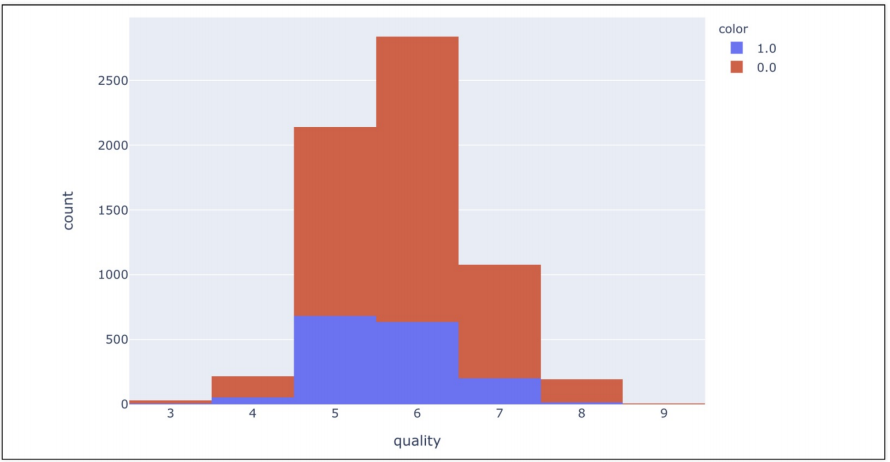
레드, 화이트와인 분류기
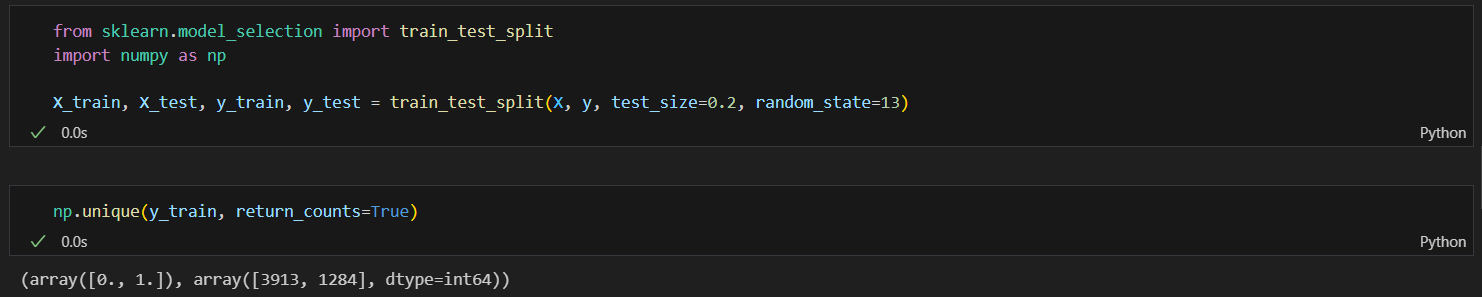
데이터를 훈련용(학습용)과 테스트용으로 나누기
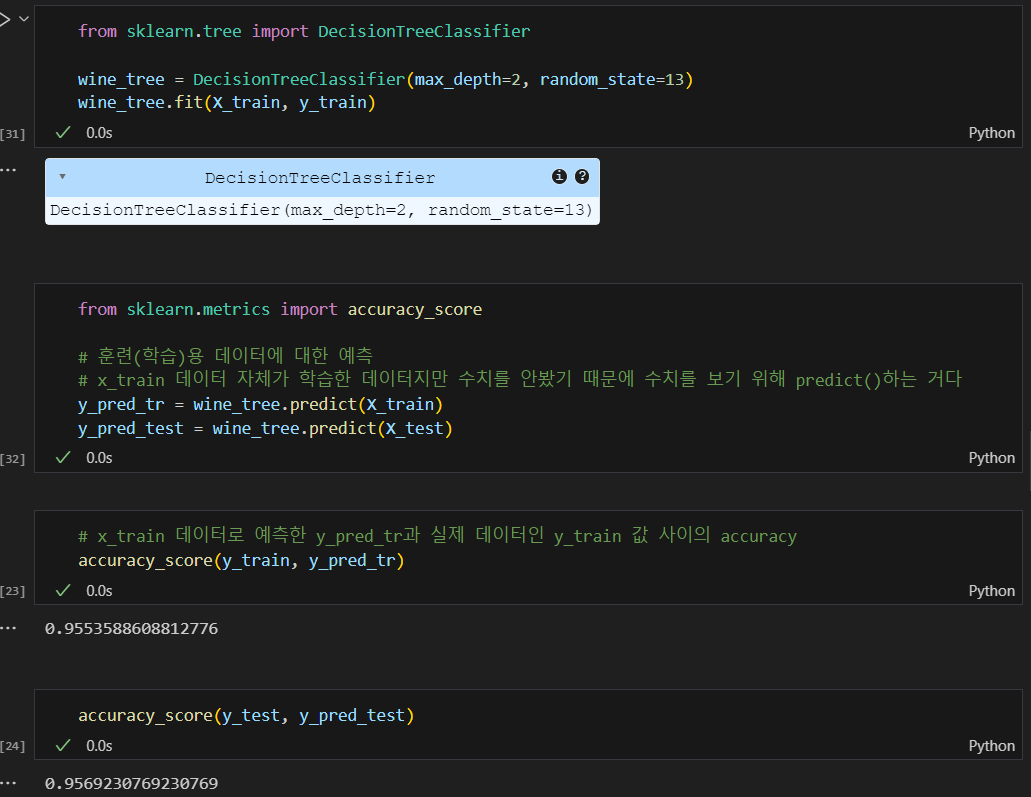
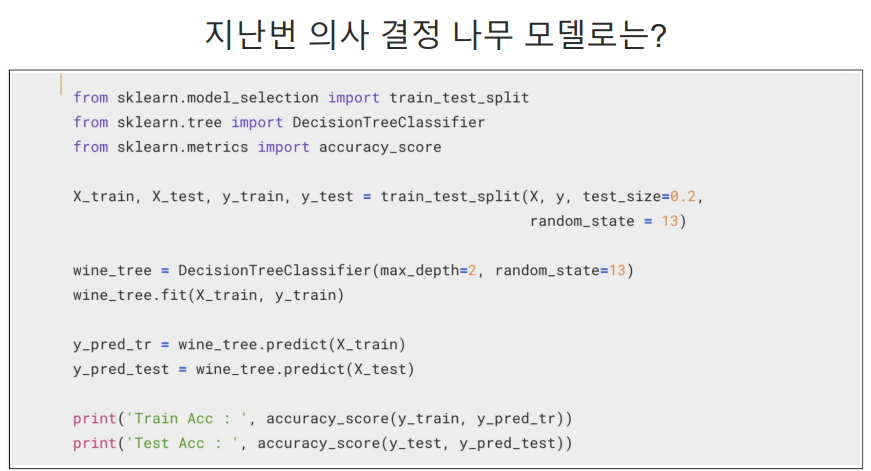
결정나무 훈련
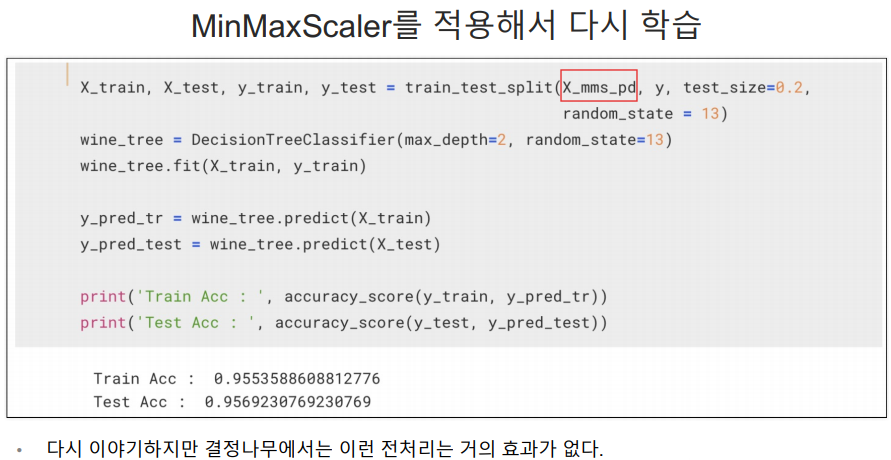
데이터 전처리
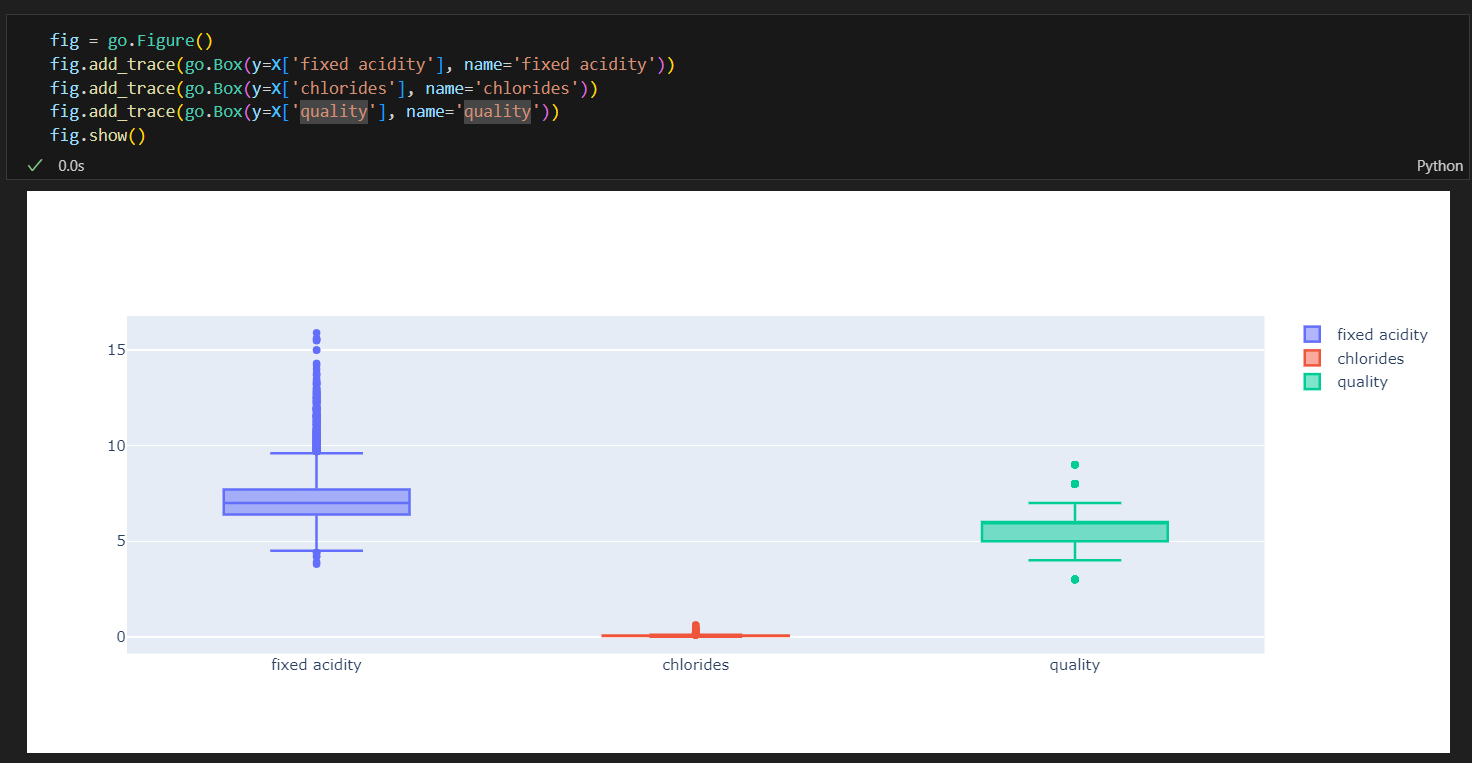
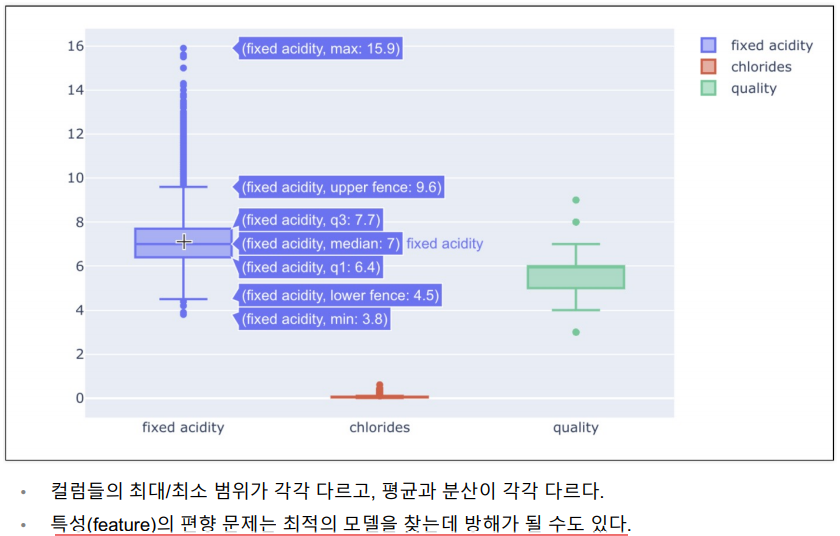
와인 데이터 몇개의 항목에 Boxplot 그리기

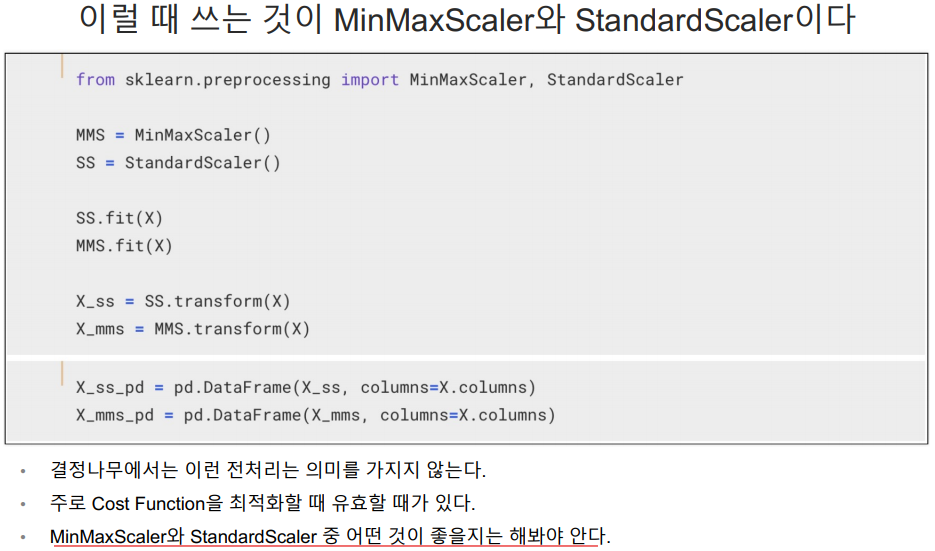
MinMaxScaler

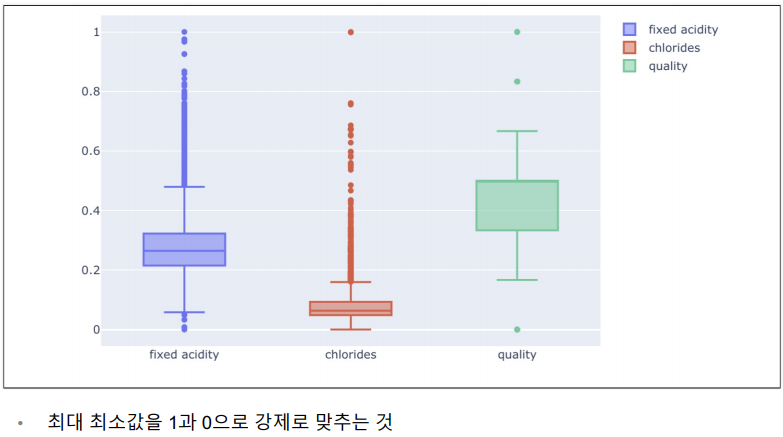
StandardScaler

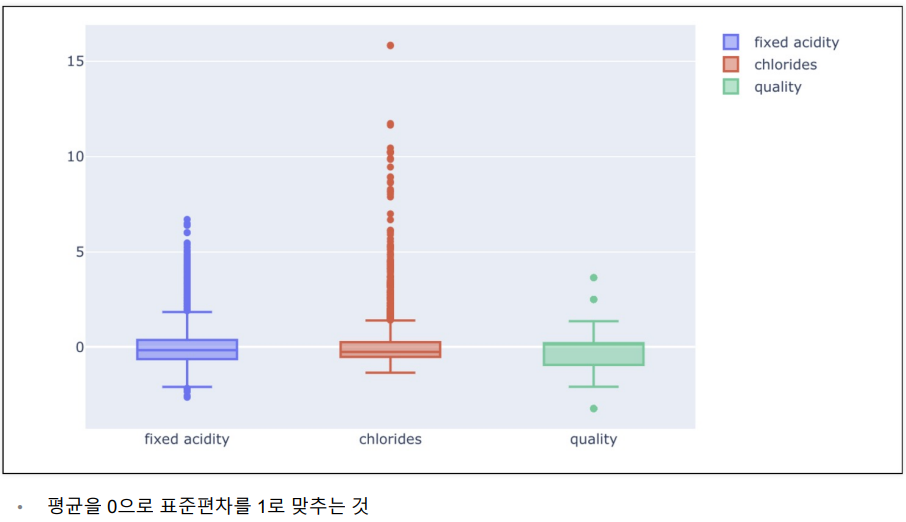
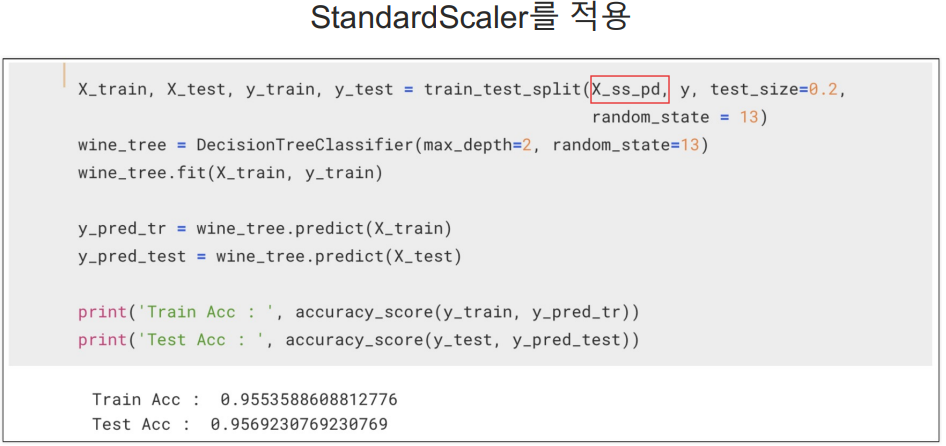
와인맛에 대한 분류 - 이진분석
quality 컬럼을 이진화
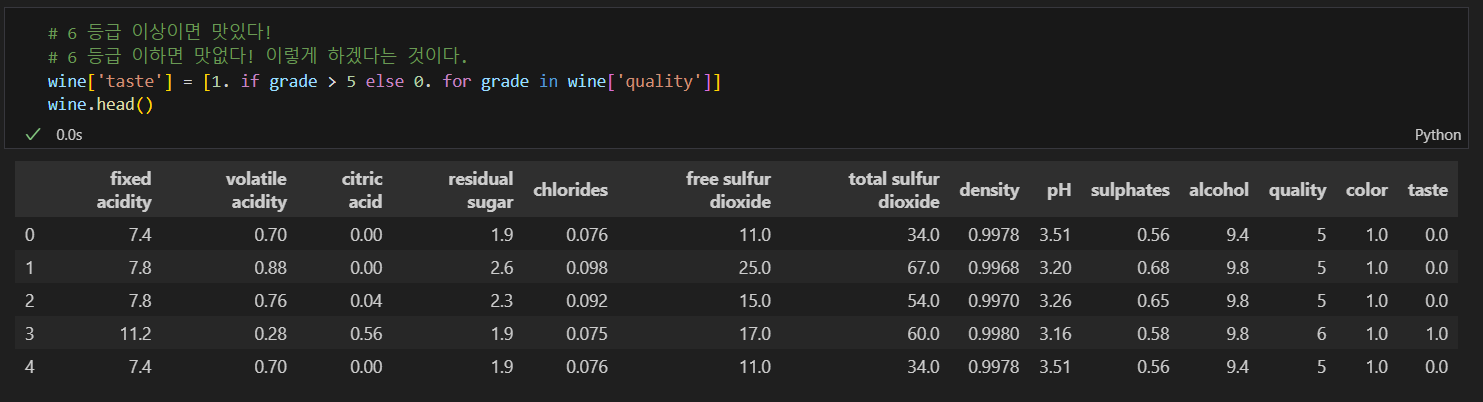
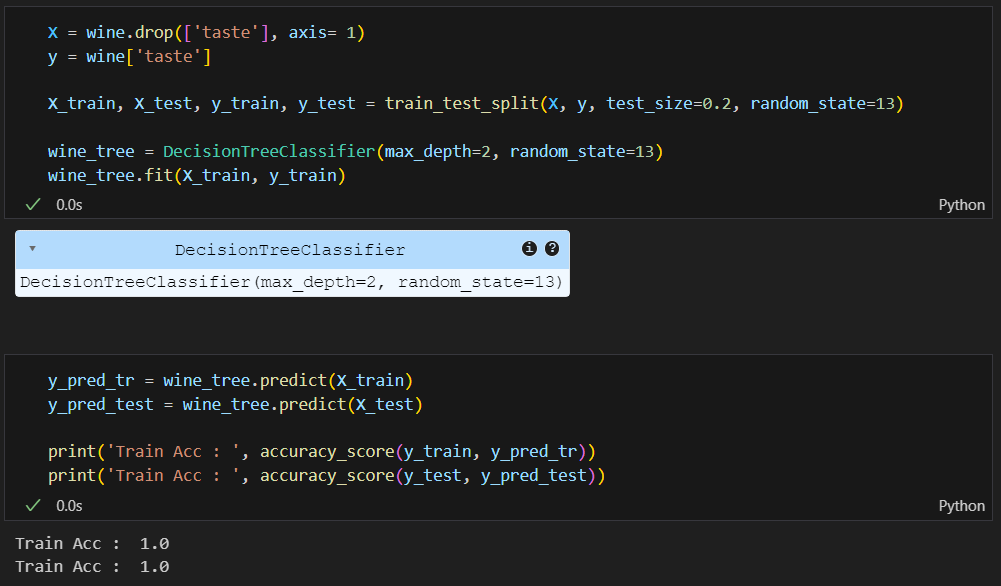
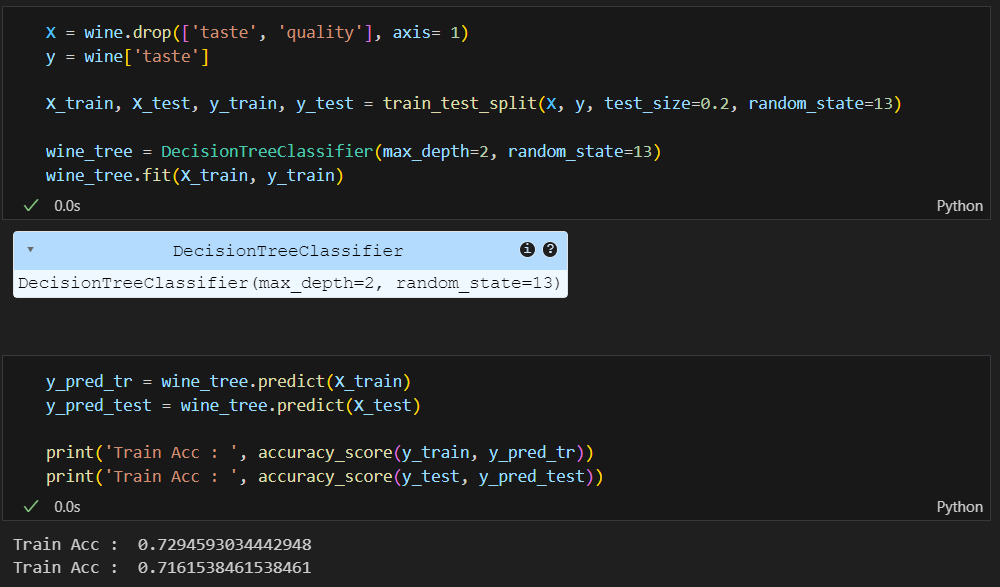
정확성을 확인해보니 100%가 나옴..
100%가 가능한가?
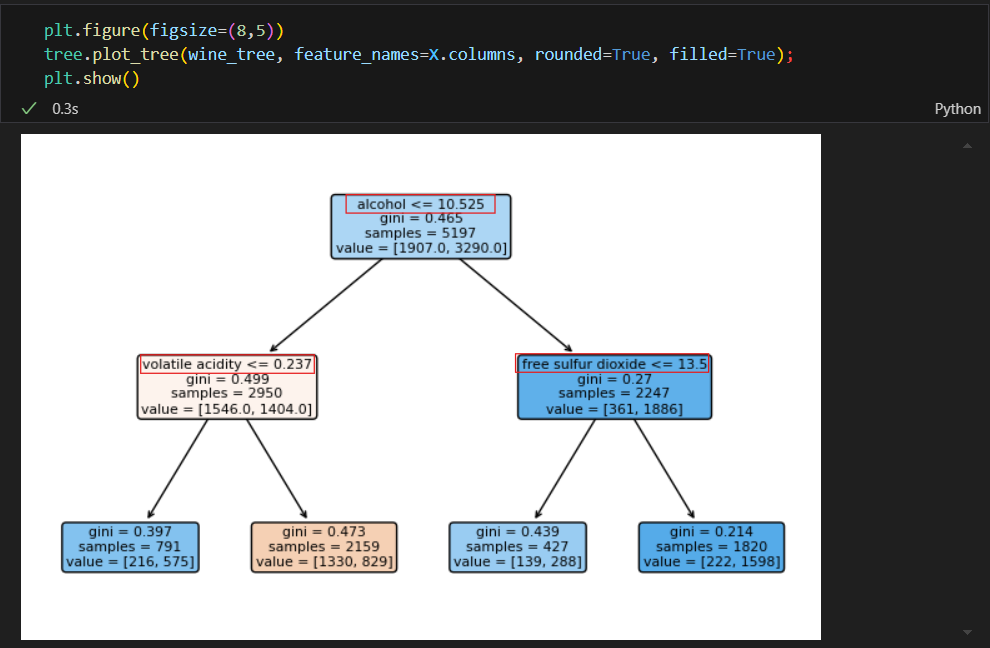
결정나무 트리를 확인해보니 가장 첫번째 기준이 quality로 나눠진 것이다.
이러니 100%가 나올 수 밖에 없다 why? 내가 quality를 기준으로 taste라는 컬럼을 이진화 했으니까
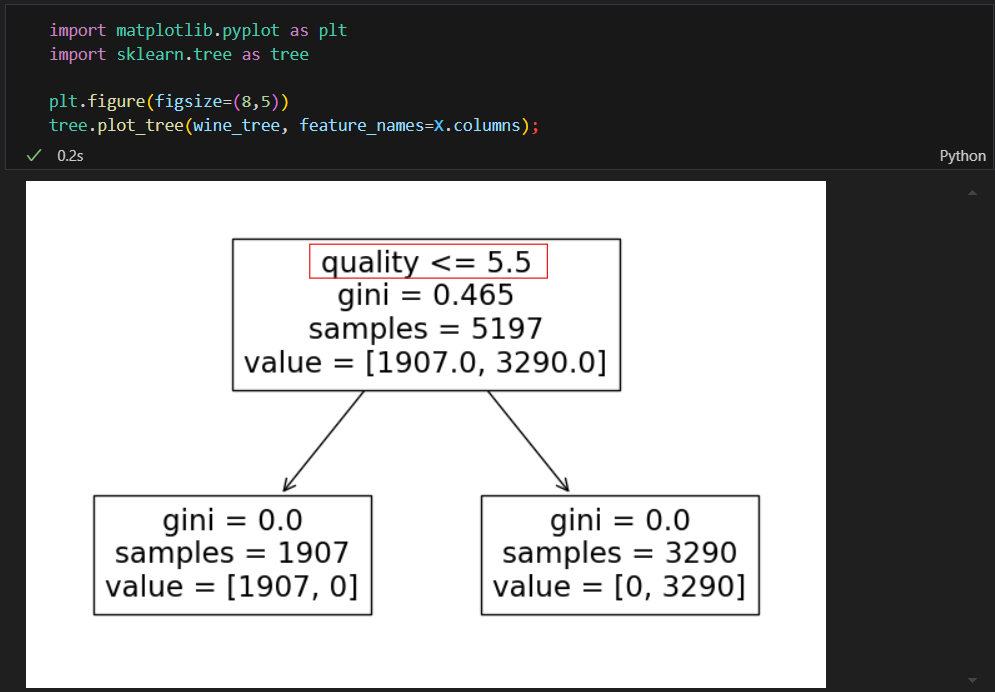

quality 컬럼을 제거하고 학습을 시켜야 와인의 다른 요소들을 기준으로 맛의 기준을 정하는 모델을 올바르게 학습할 수 있음.
Pipeline

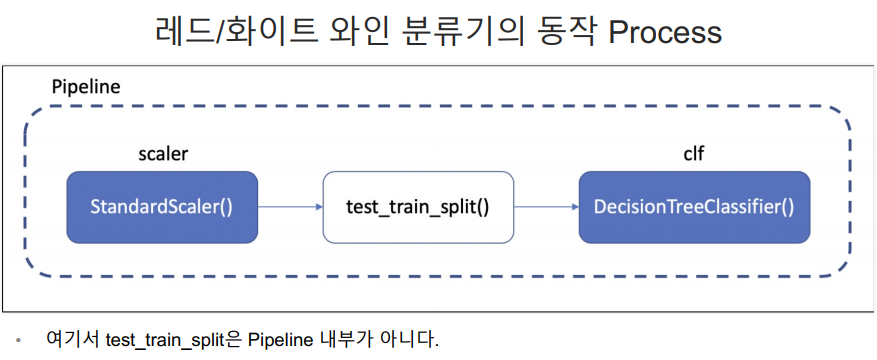

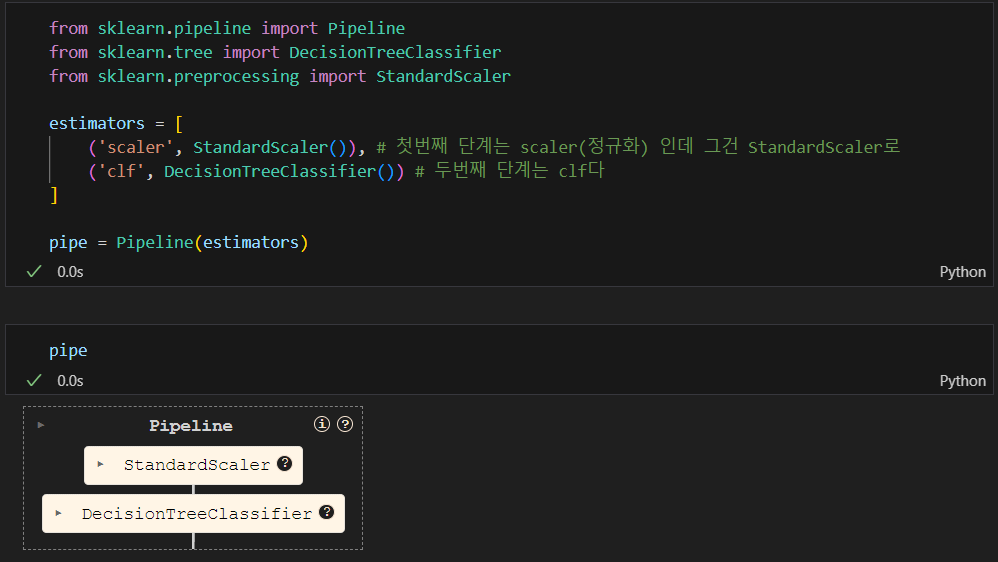
pipeline.step
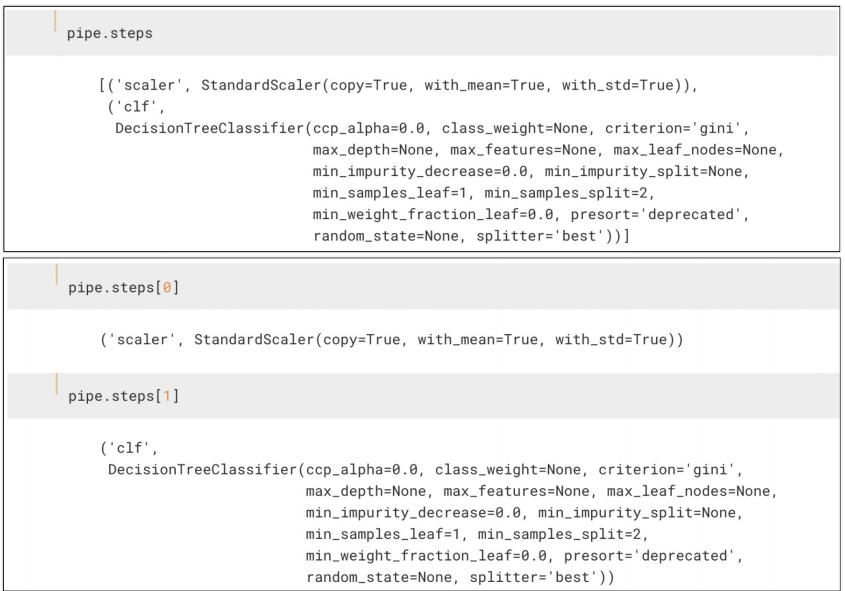

set_params
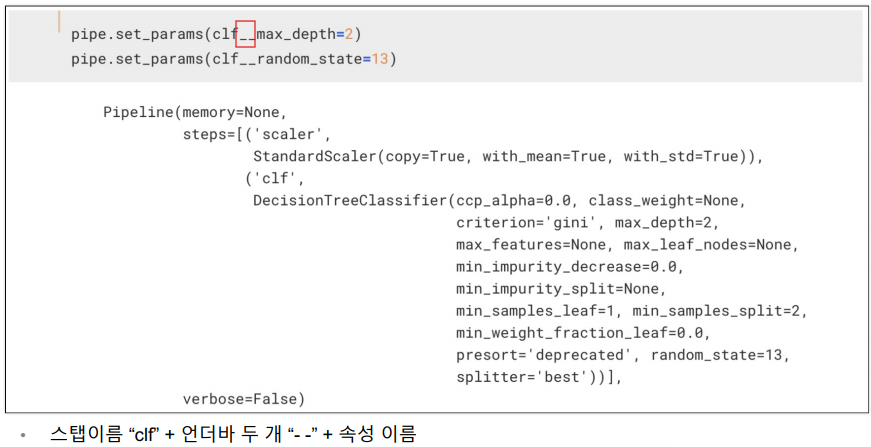

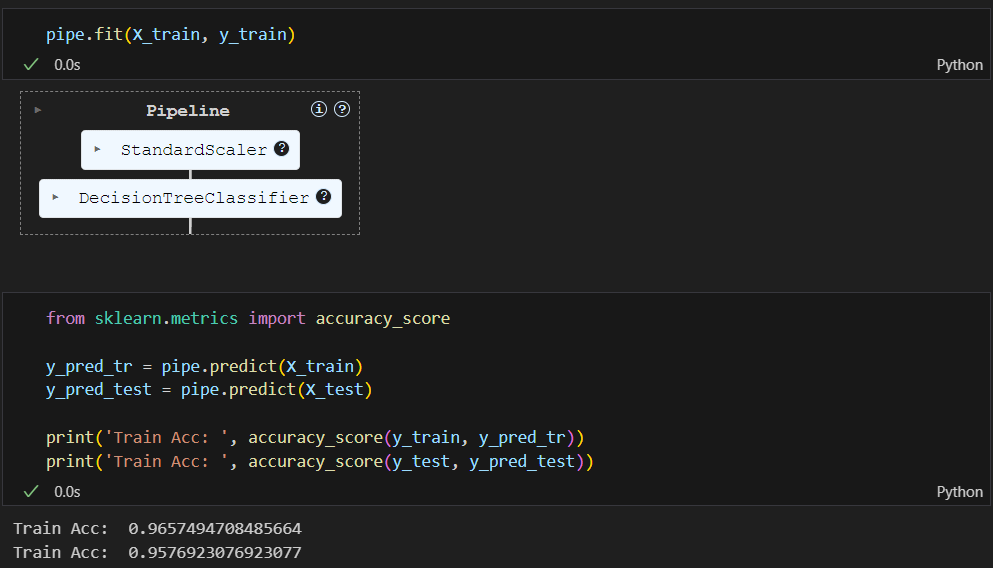
위에서 선언한 pipe에 fit을 하면됨. 그러면 알아서 정규화 하고 결정나무 훈련하고 진행함.
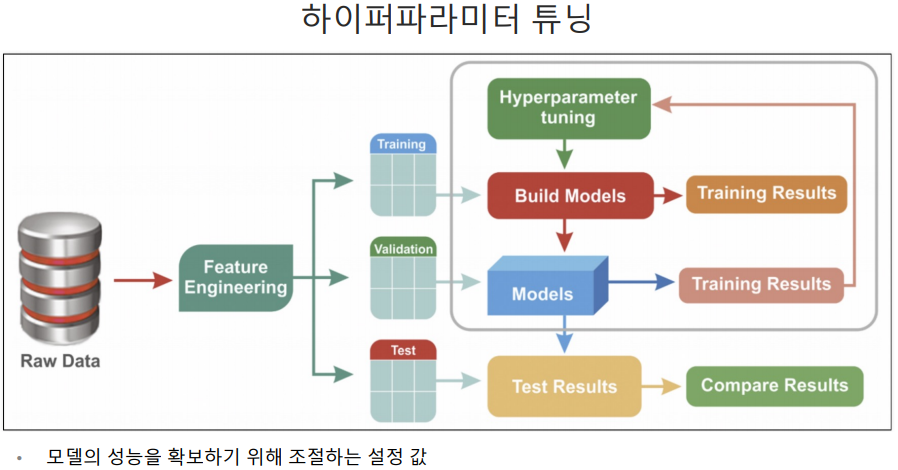
하이퍼파라미터 튜닝

트레인 데이터와 테스트 데이터를 나눠 정확성을 검증하는 것이 holdout

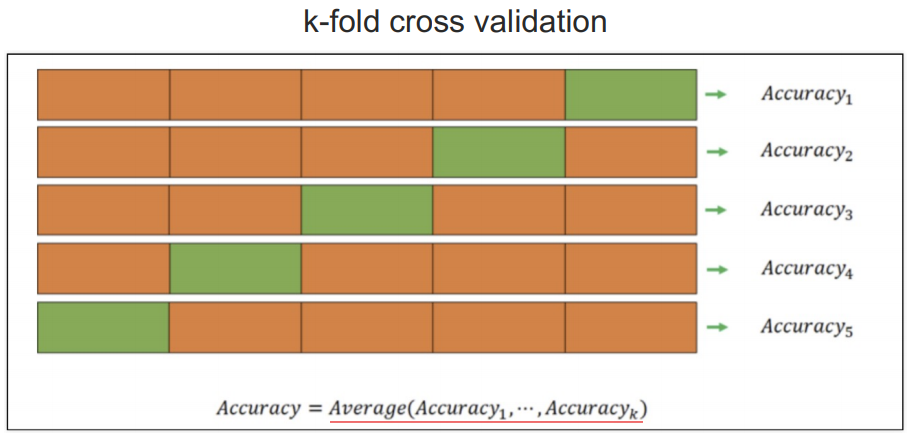
[kfold]
데이터를 K개의 서로 겹치지 않는 폴드로 나눔.
k=5인 경우 전체 데이터 셋이 5개의 폴드로 나누어지고 k-1개 즉, 4개는 훈련용, 1개는 테스트 용으로 돌아가면서 검증고 평균을 구함.
( ex 폴드 1을 테스트용, 폴드 2~5를 훈련용으로 사용 -> 폴드 2를 테스트용 폴드 1, 3~5를 훈련용으로 사용 ... 계속 진행)
예를 들어, 100개의 데이터를 5개의 폴드로 나누면, 각 폴드에는 20개의 데이터가 들어간다. 이때 각 폴드에 들어가는 20개의 데이터의 비율은 신경쓰지 않는다.
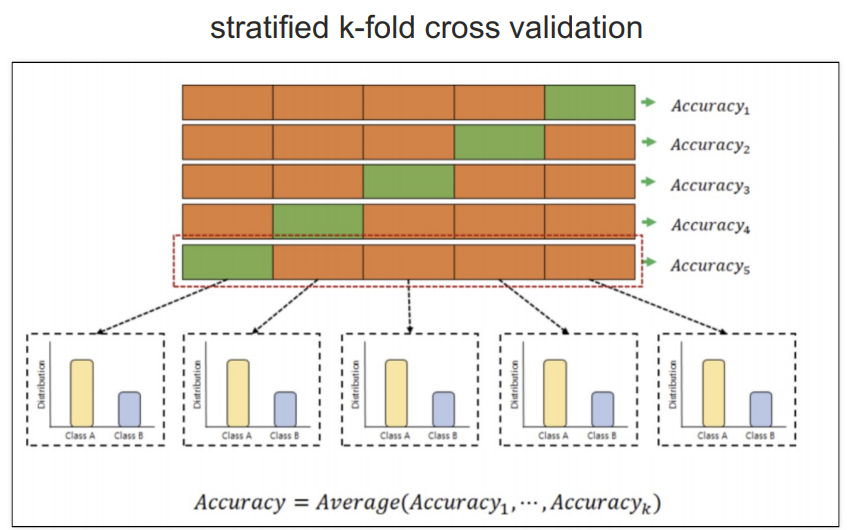
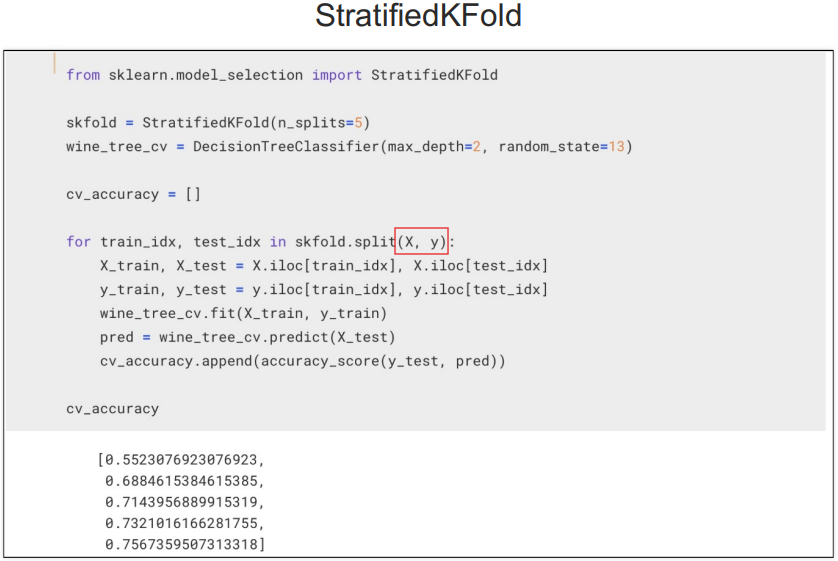
[StratifiedKFold]
다섯개의 클래스가 동일하게 유지되는 stratified k-fold corss validation는 y의 값 즉, 이진으로 분류되는 종속 변수의 비율을 동일하게 유지하겠다는 뜻이다.
전체 데이터에서 와인 맛 평가가 1이 7개, 0이 3개의 비율이라면 5개의 폴드(fold)로 나눌 때 각 폴드에서 y의 비율이 7:3이 되도록 나누겠다는 뜻이다.
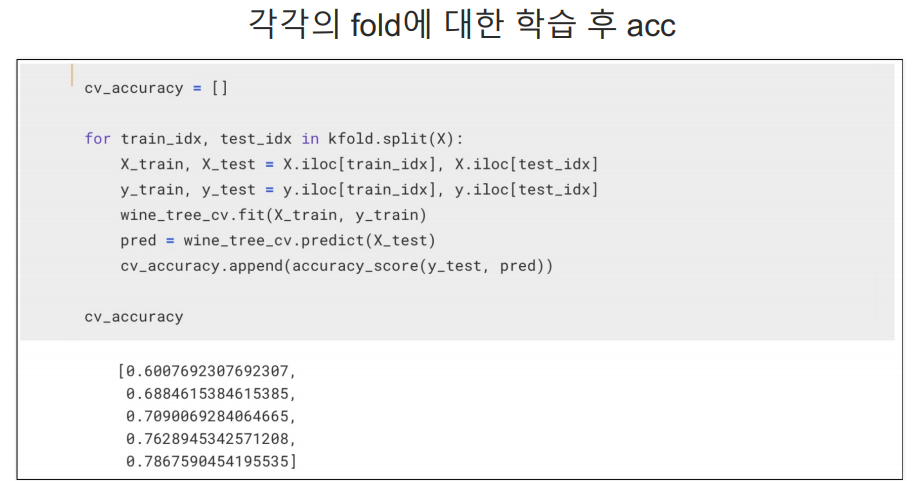
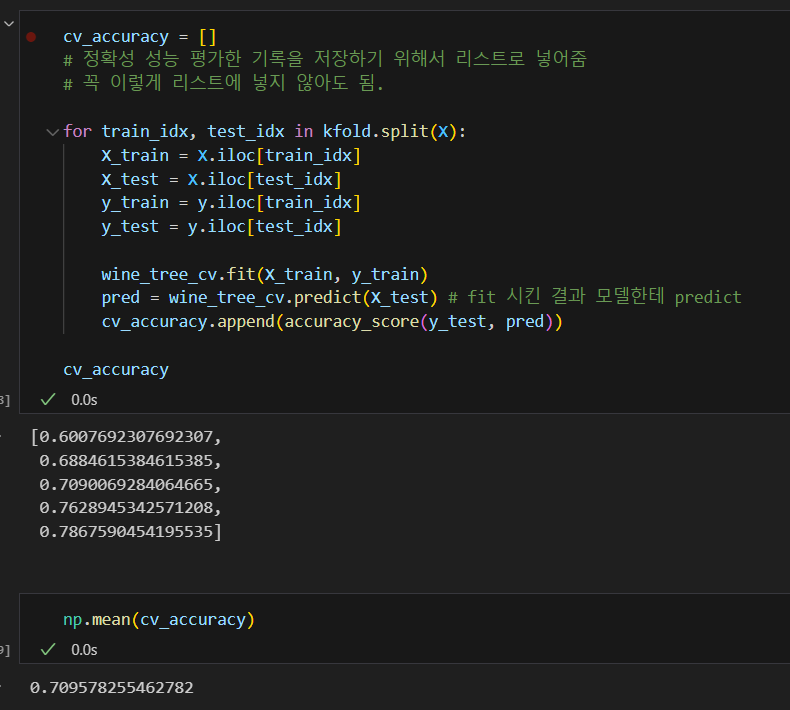
교차검증 구현하기
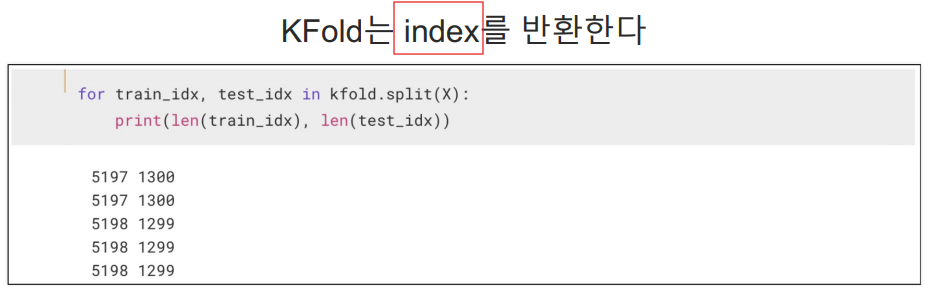
KFOLD는 인덱스를 반환한다. 우리는 그 인덱스를 가지고 train을 하고 test를 하는 것이다.
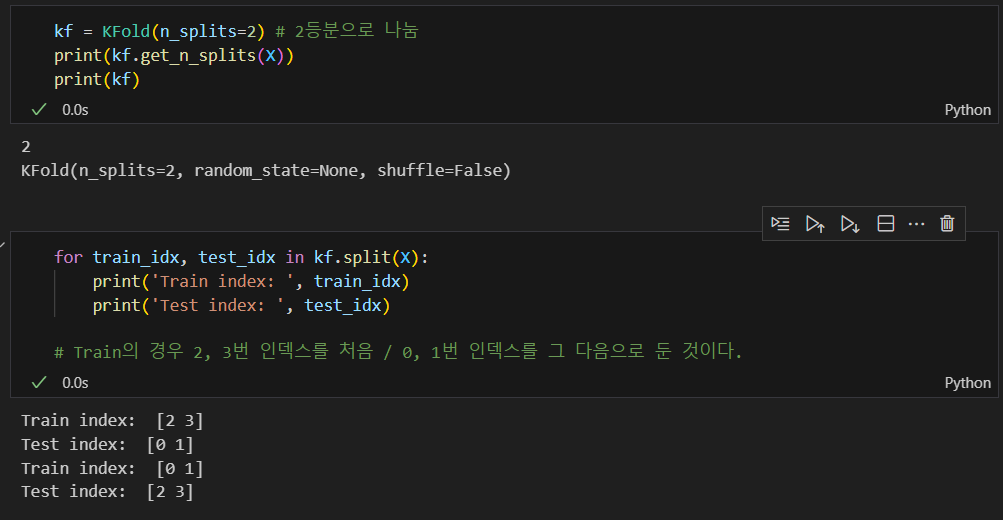



주로 5로 나눠서 교차 검증을 많이 한다

만약 내가 StratifiedKFold를 사용하고 싶다면
데이터 셋에 있는 클래스(타겟 데이터)의 분포의 비율과 동일하게 각 폴드에 데이터를 분할하는 방식이다.
StratifiedKFold는 이진으로 나눠진 y클래스가 동일한 비율로 들어가야 하므로 split(X)로 사용하지 못하고 split(X,y)로 사용해야함.

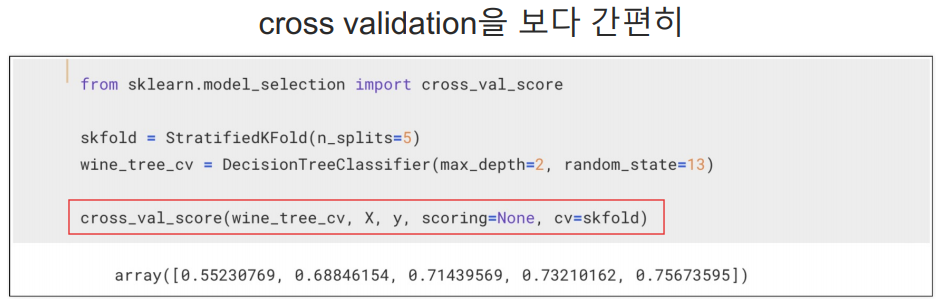
보통은 cross validation을 사용해서 위의 코드를 간소화 한다.
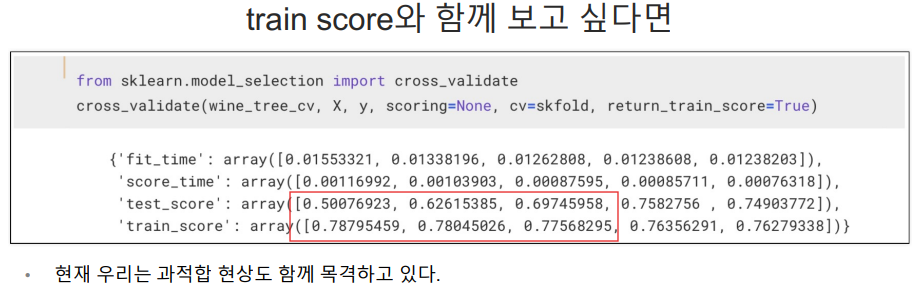
train score와 함께 보고 싶다면
- 위의 cross_validate_score는 각 폴드에서의 모델 성능 점수
- 아래의 cross_validate 에서 나오는 결과 중에 test score에 해당됨.
- cross_validate는 더 많은 정보를 포함하는 딕셔너리다.
빨간 박스 영역을 보면 train score는 높은데 test score는 낮아 과적합이 보임.
하이퍼파라미터 튜닝

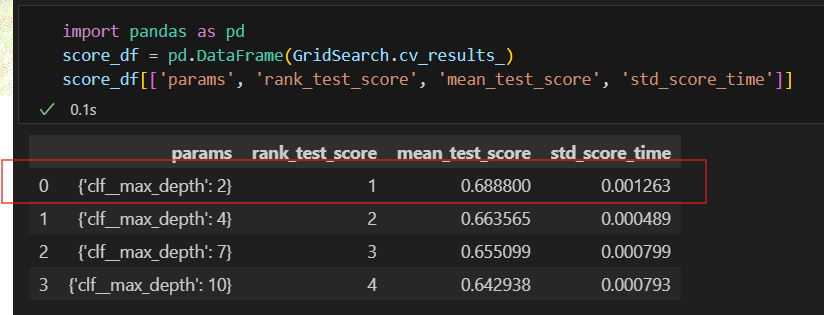
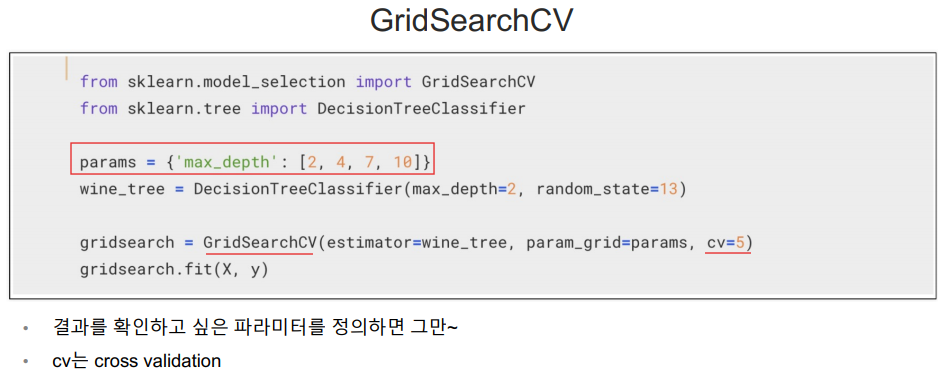
GridSearchCV
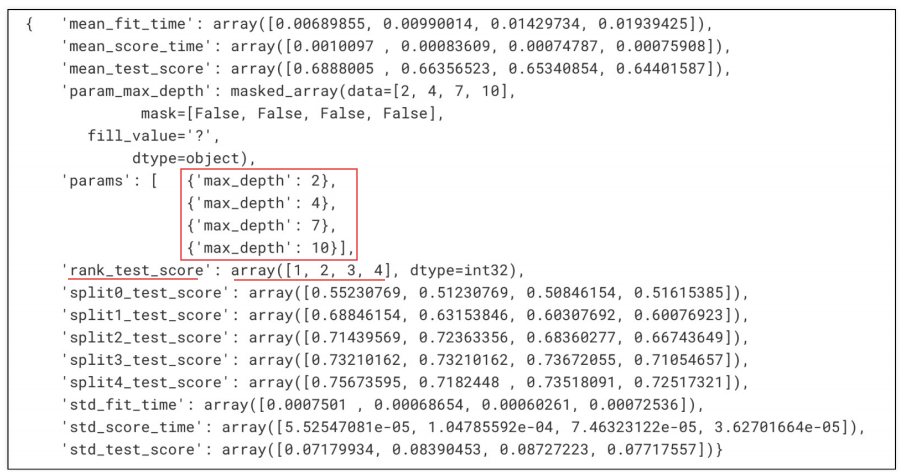
지정된 분류기(wine_tree)에 params 값을 넣어서 니가 알아서 5개로 나눠서 kfold(cv=5) 해라
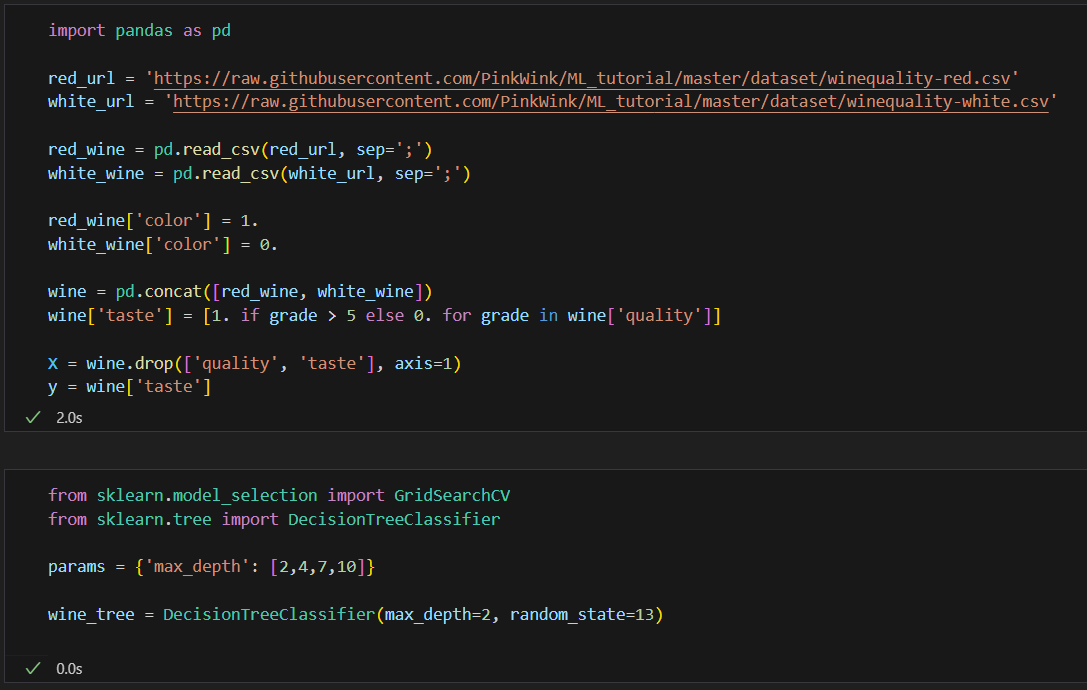
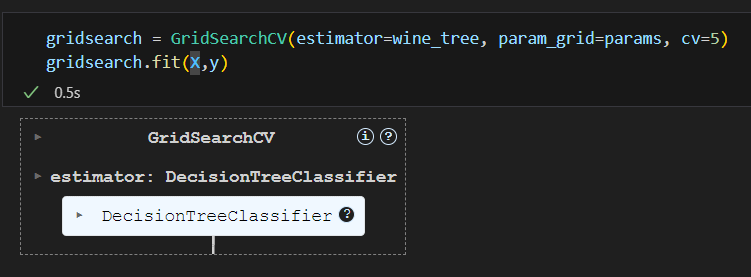

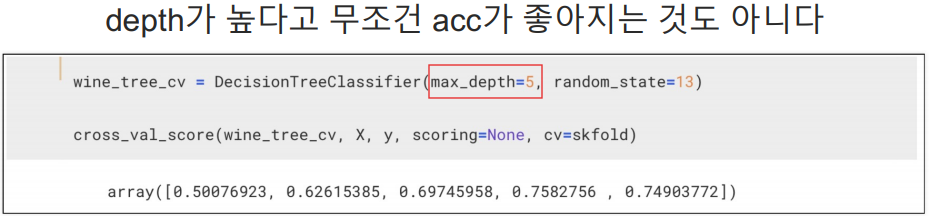
depth 2,4,7,10의 순위는 1,2,3,4
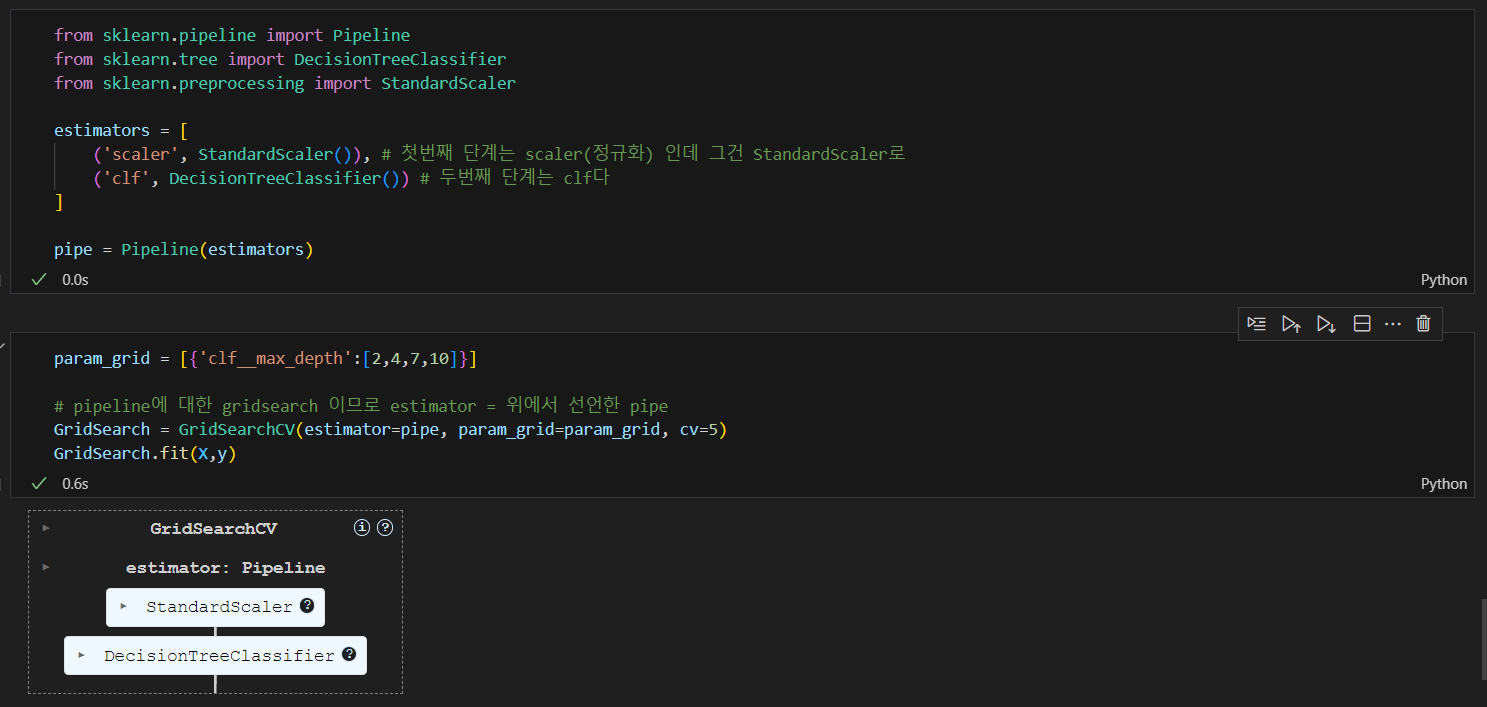
Pipeline을 적용한 모델에 gridsearch를 적용하고 싶다면
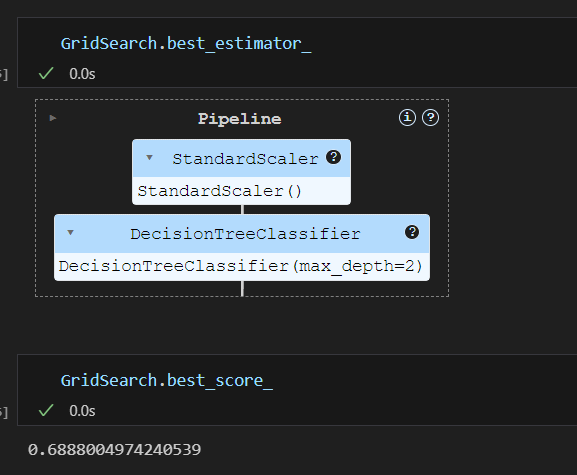
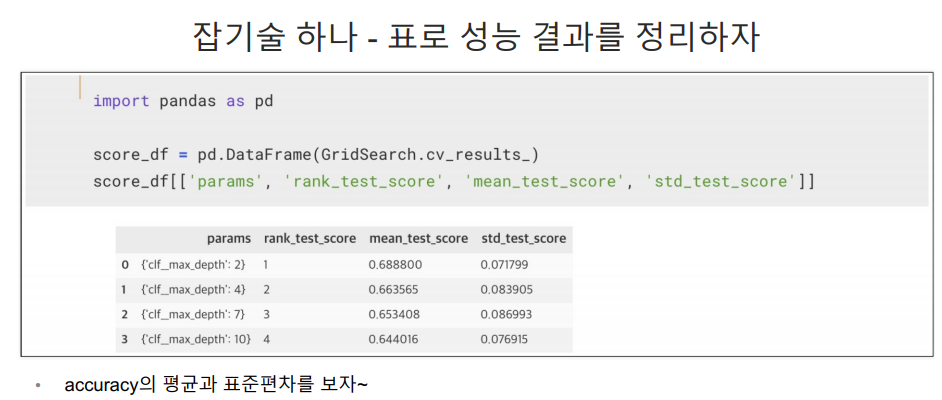
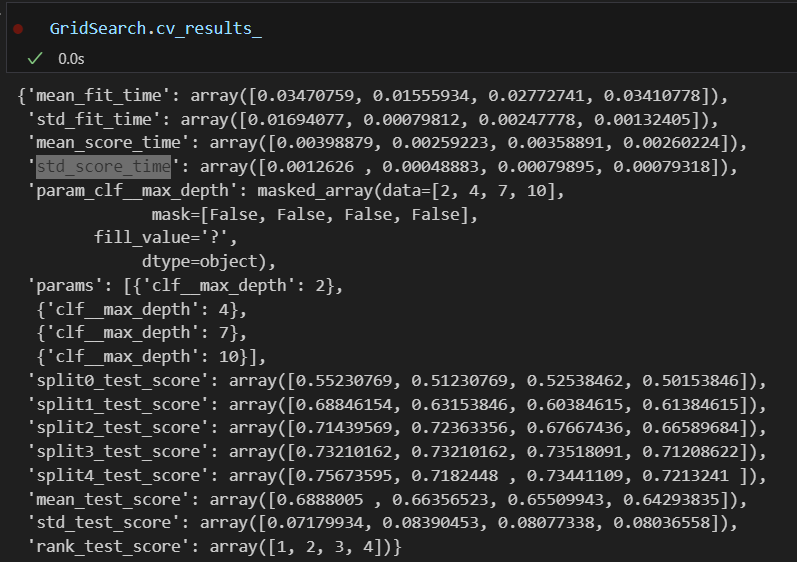
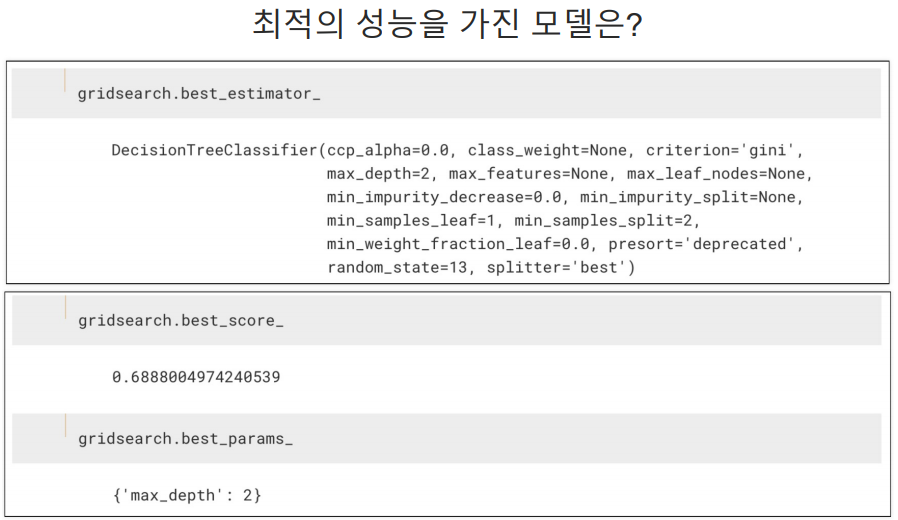
내가 지정한 파라미터 중에서 depth:2가 가장 좋은 파라미터다.
std_score_time은 모델 평가 시간의 표준편차로 짧을수록 모델 평가가 더 일관되었음을 의미함.