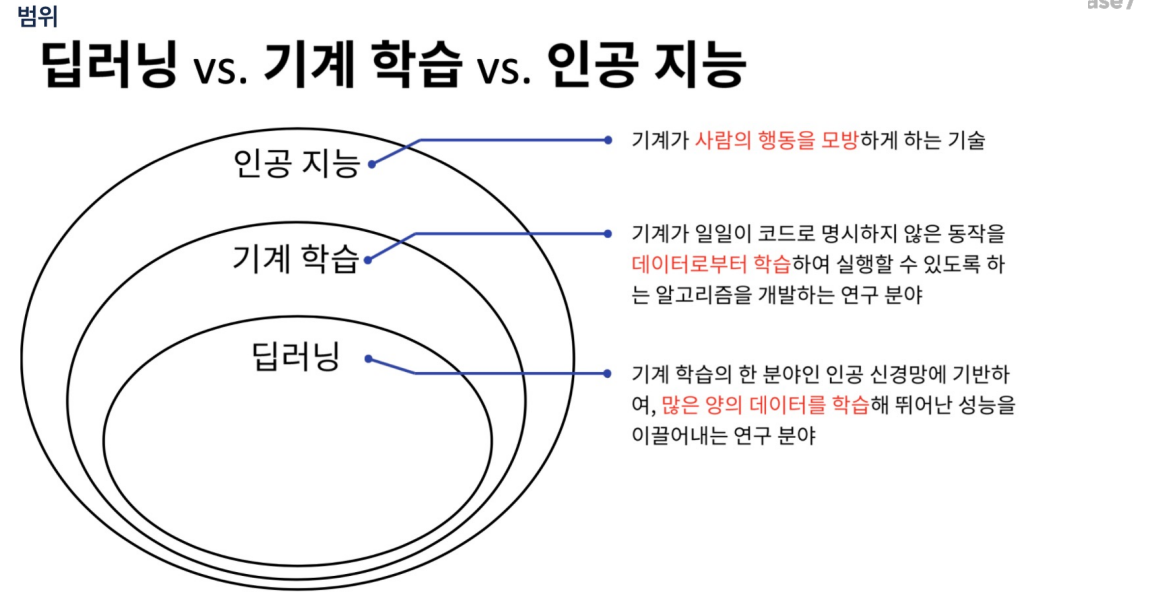
ML, DL
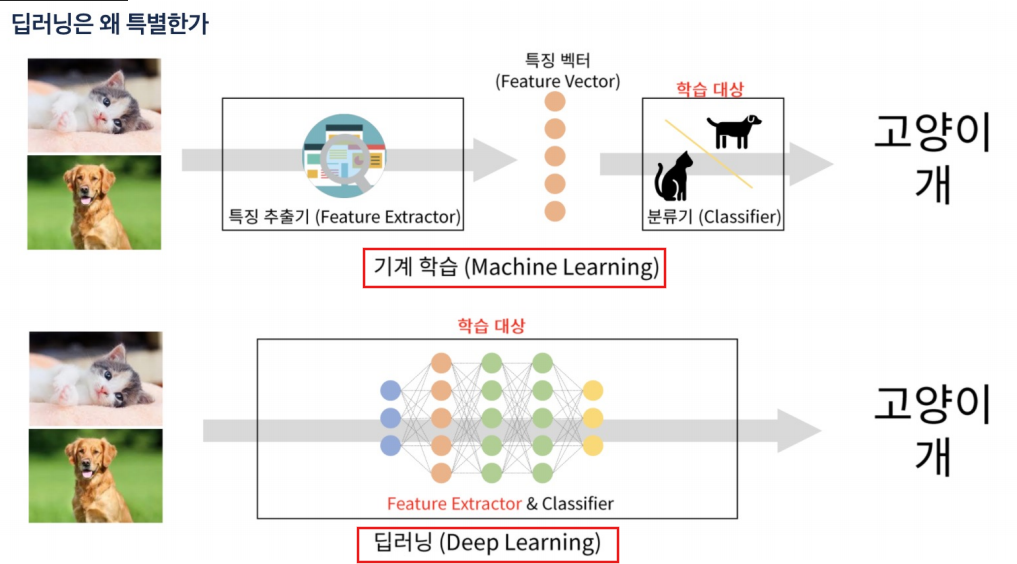
머신러닝은 특징을 찾을 수 있는 수단을 통해 특징을 찾고 학습을 시키지만 딥러닝은 그 특징까지도 직접 찾는다.
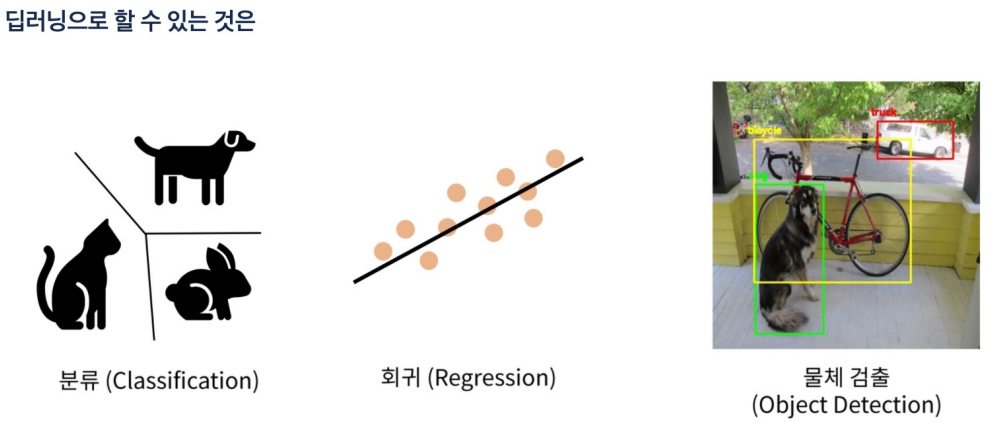
물체 검증 **
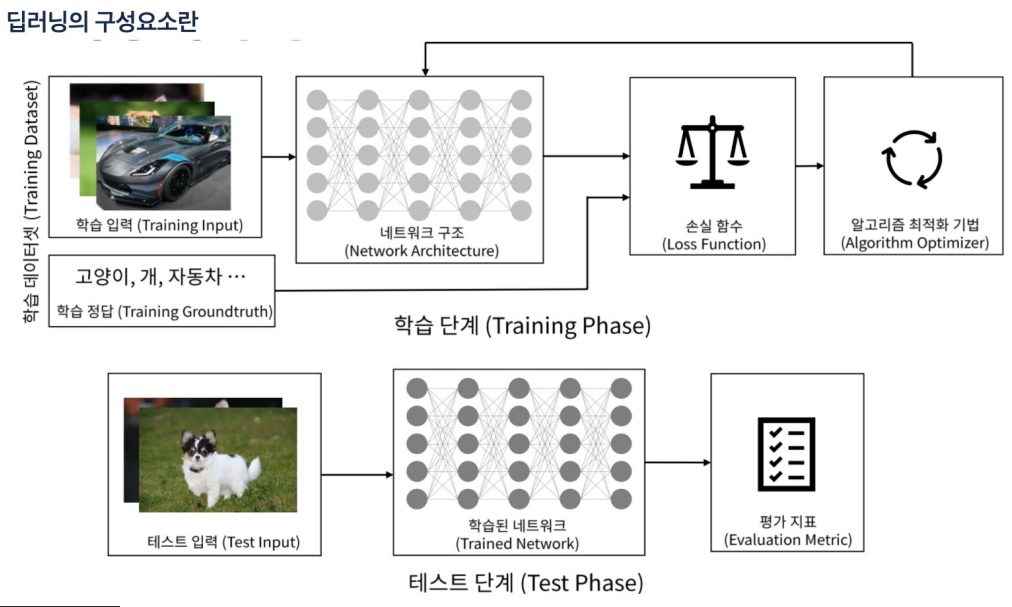
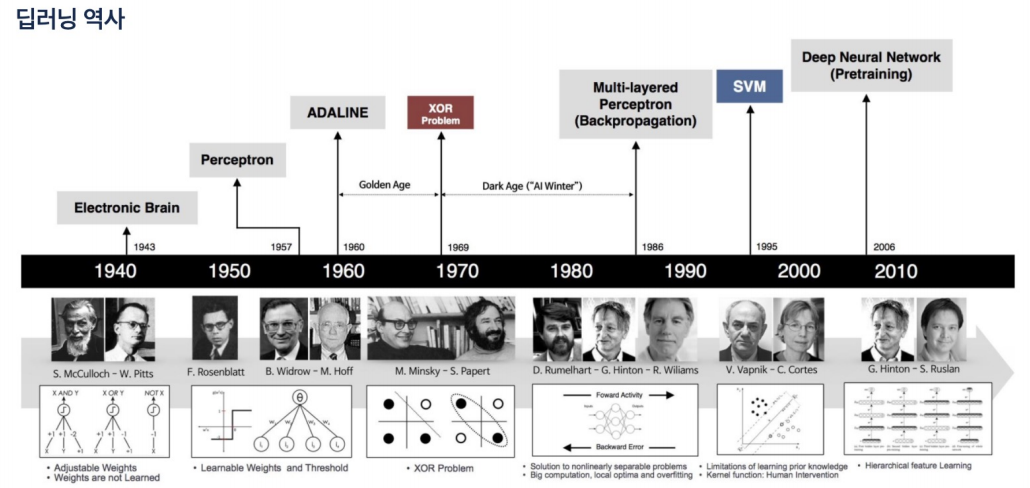
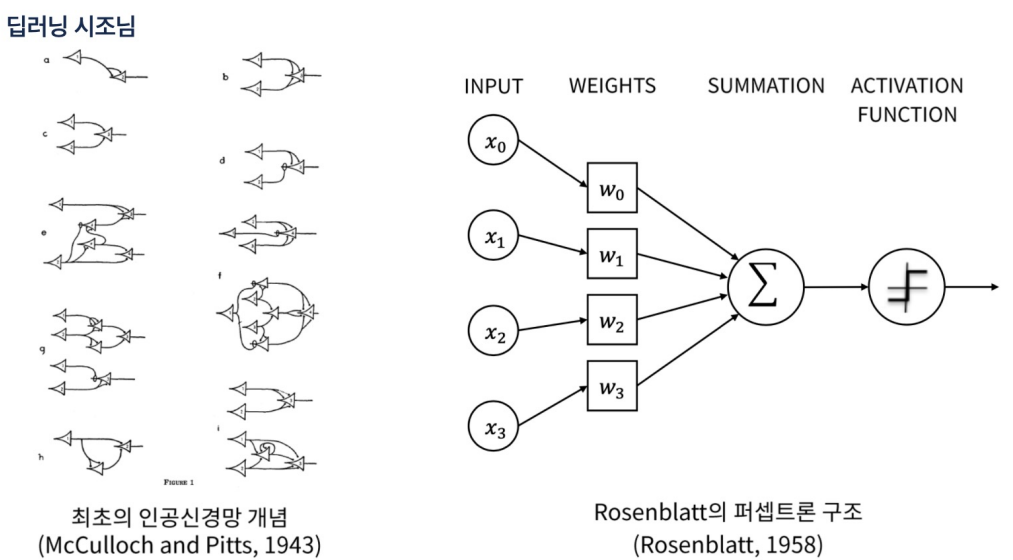
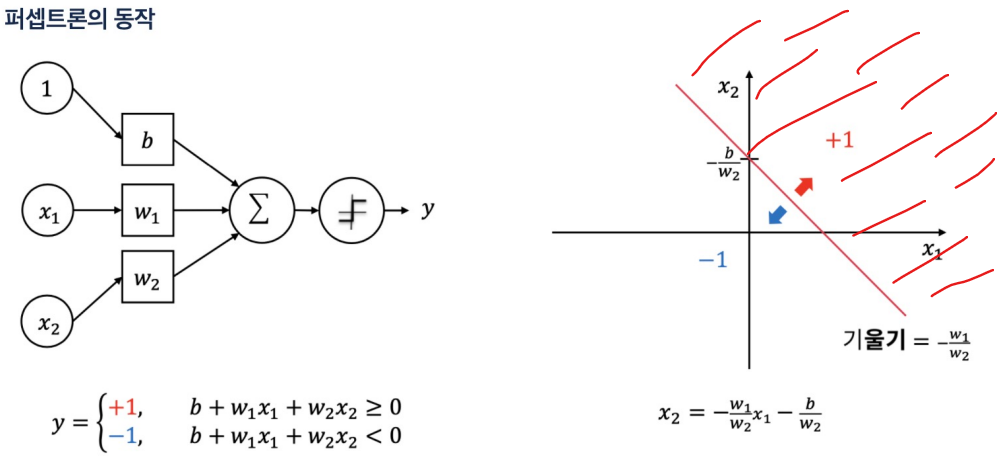
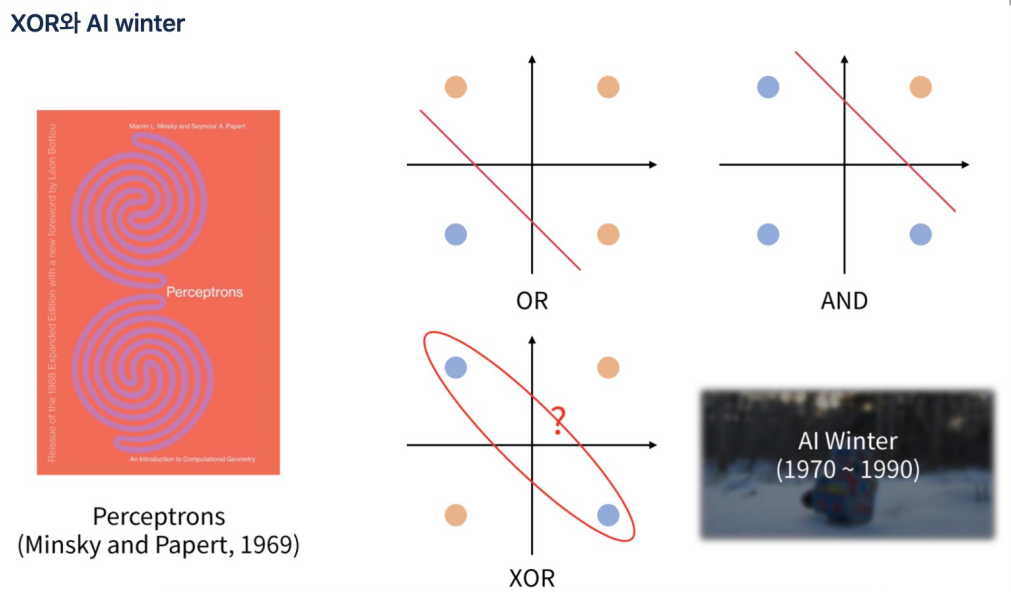
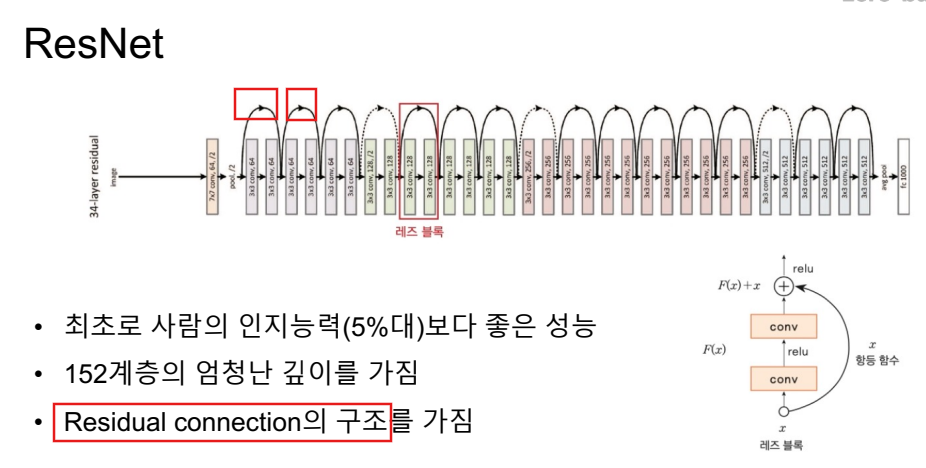
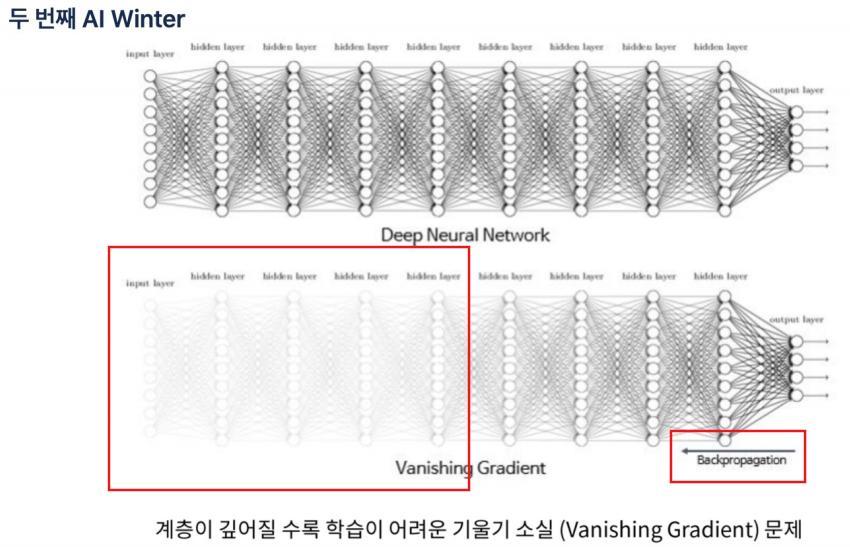
역전파시 오차를 거꾸로 한 단계씩 미분해서 값을 구하고 weight(가중치)를 수정해야함. 그러나 입력층에 가까운 레이어일수록 학습이 잘 되지 않아서 weight가 0에 가깝게 되버리는 문제에 직면함.
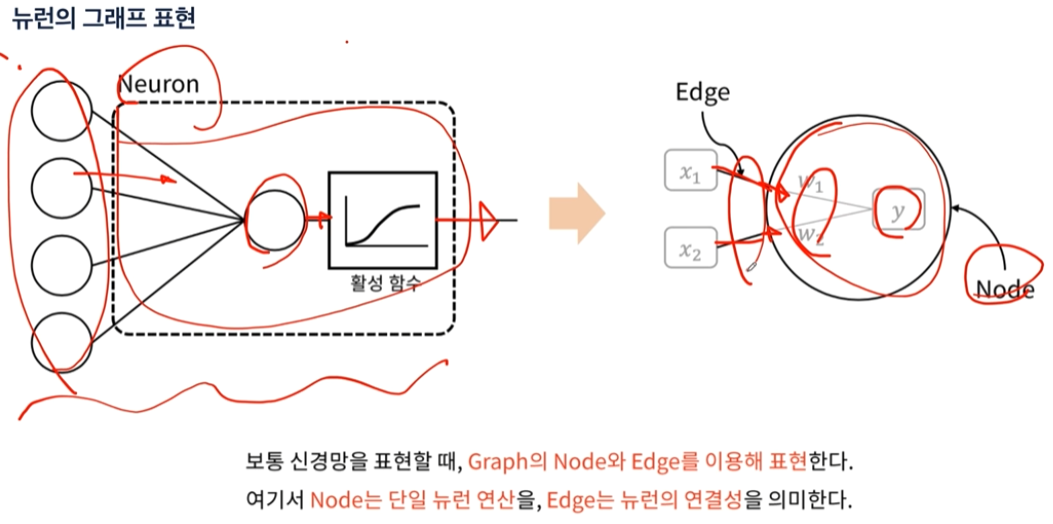
뉴런, 회귀, 분류
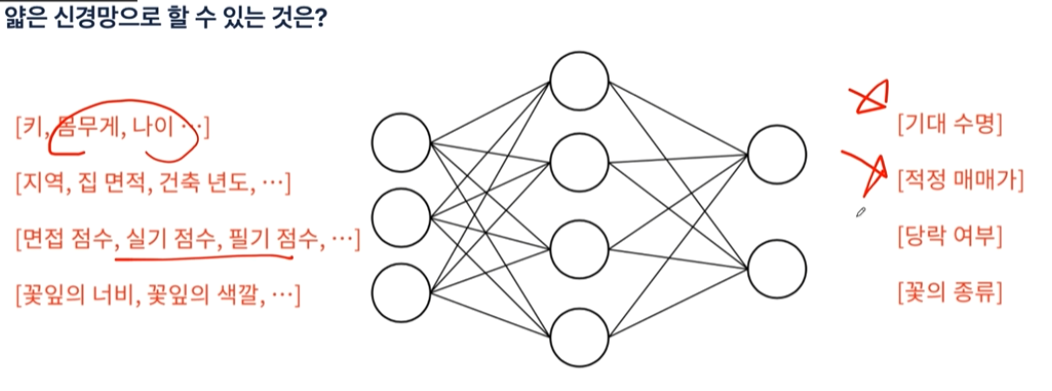
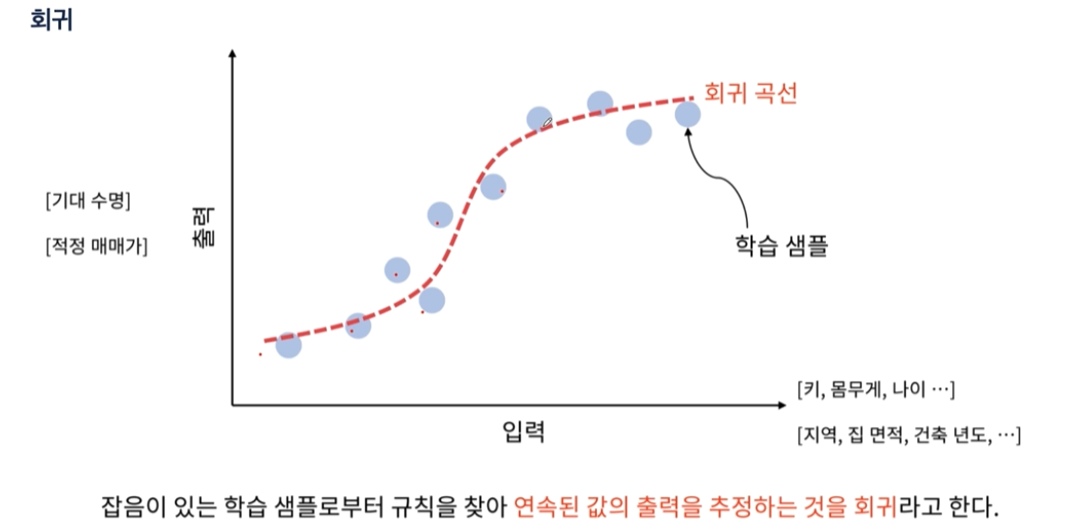
회귀는 데이터를 표현하는 선을 찾는것
분류는 데이터를 구분하는 경계선을 찾는 것
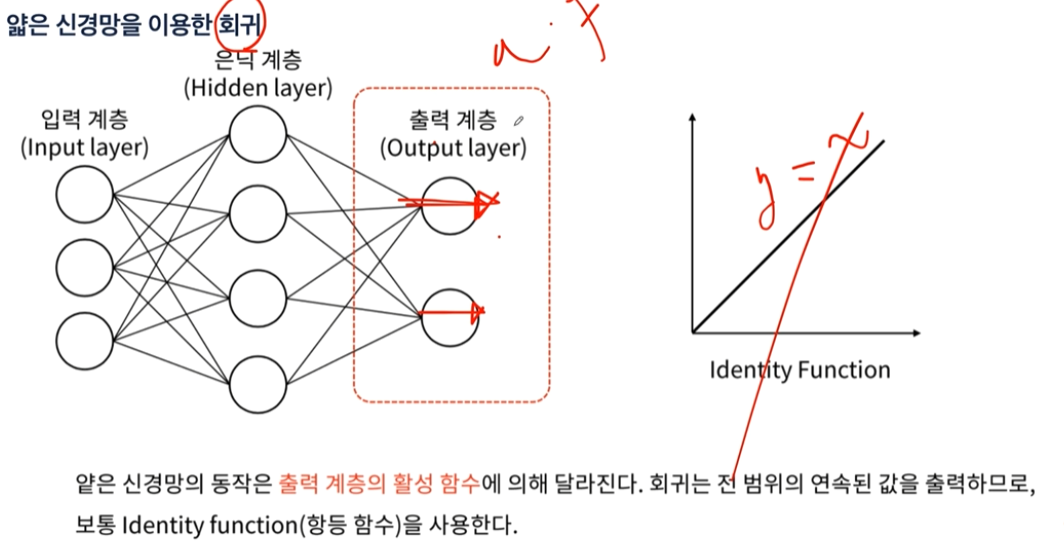
- 회귀를 구현하는 방법은 출력층에 Activation Function(활성함수)를 설정하지 않으면 자동적으로 y=ax의 형태가 된다.
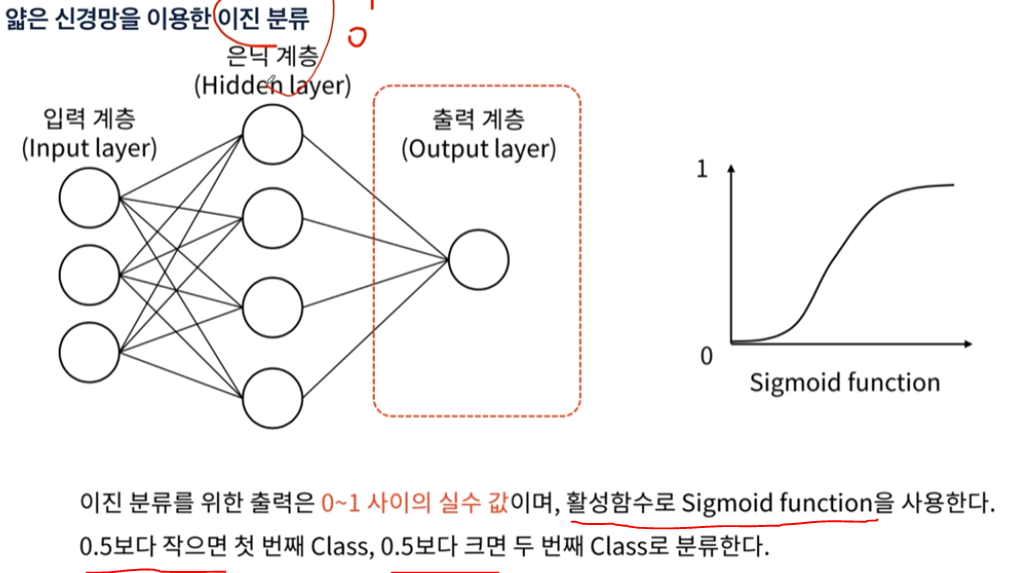
- 또는 시그모이드 함수(결과 0~1)를 출력층에 설정한 후 실제 결과값의 범위를 곱하는 형식으로도 할 수 있다.
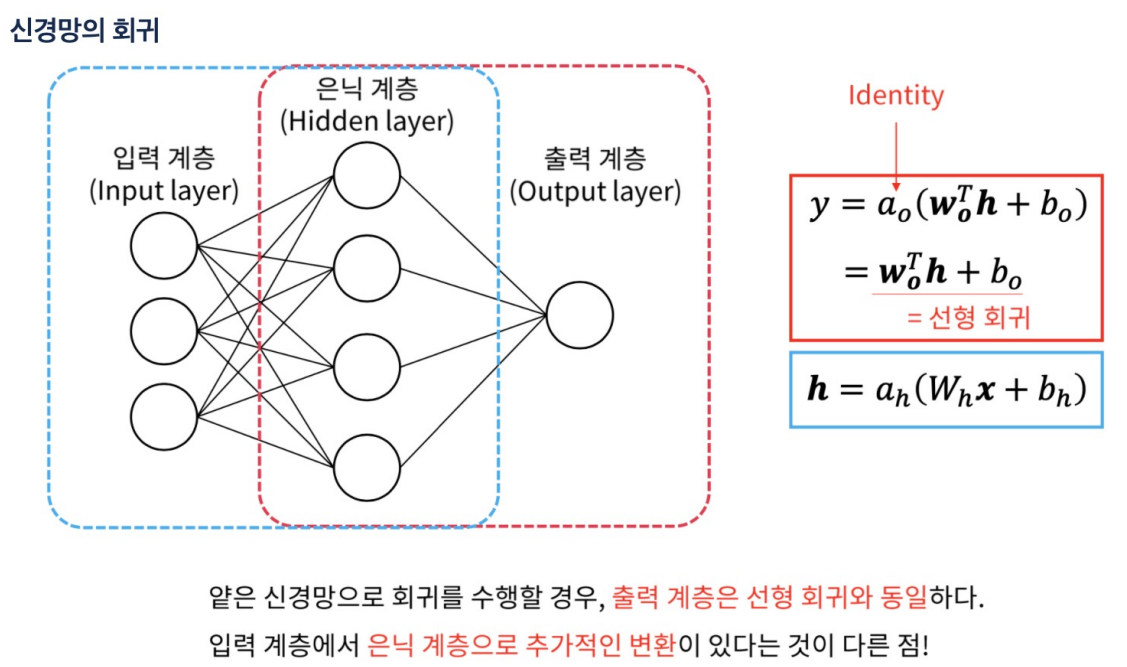
뉴런의 수학적 표현
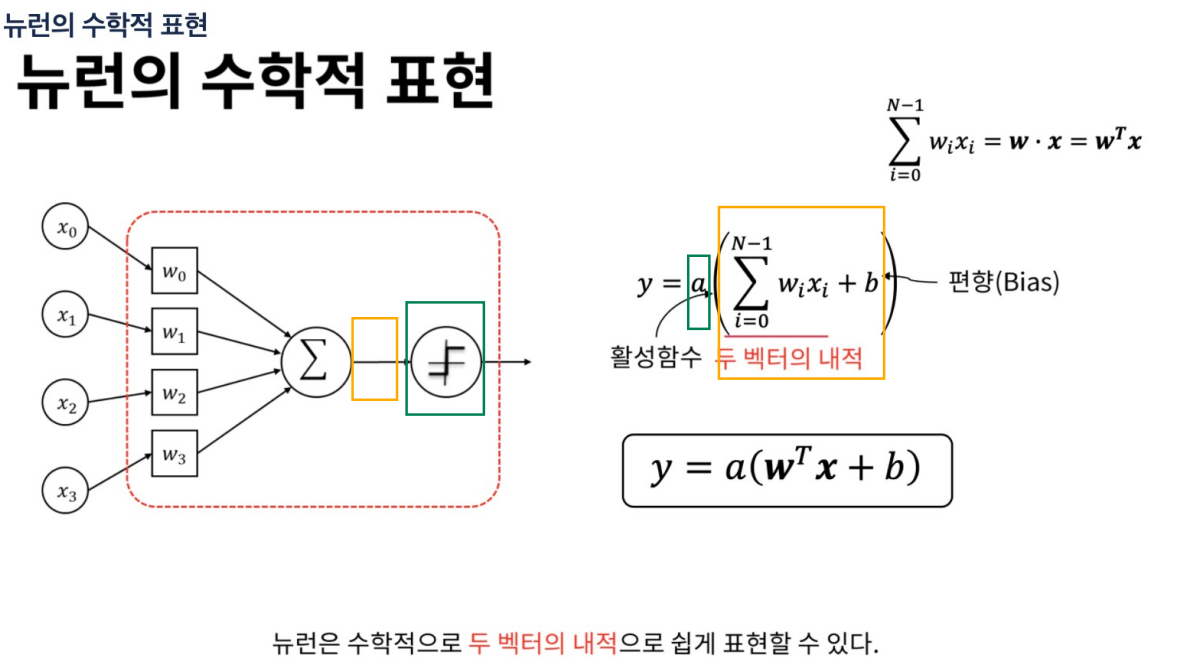
내적: 같은 위치끼리 곱한뒤 다 더하는 것.
활성함수(activation function) a에 넣으면 결과가 나옴.
여기서 weight의 값은 스칼라값.
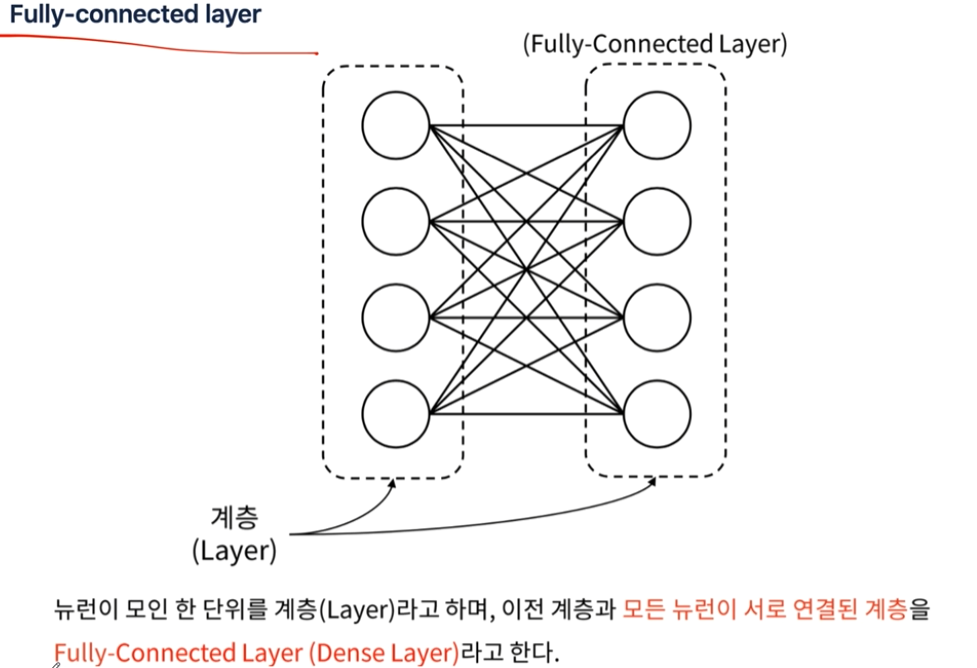
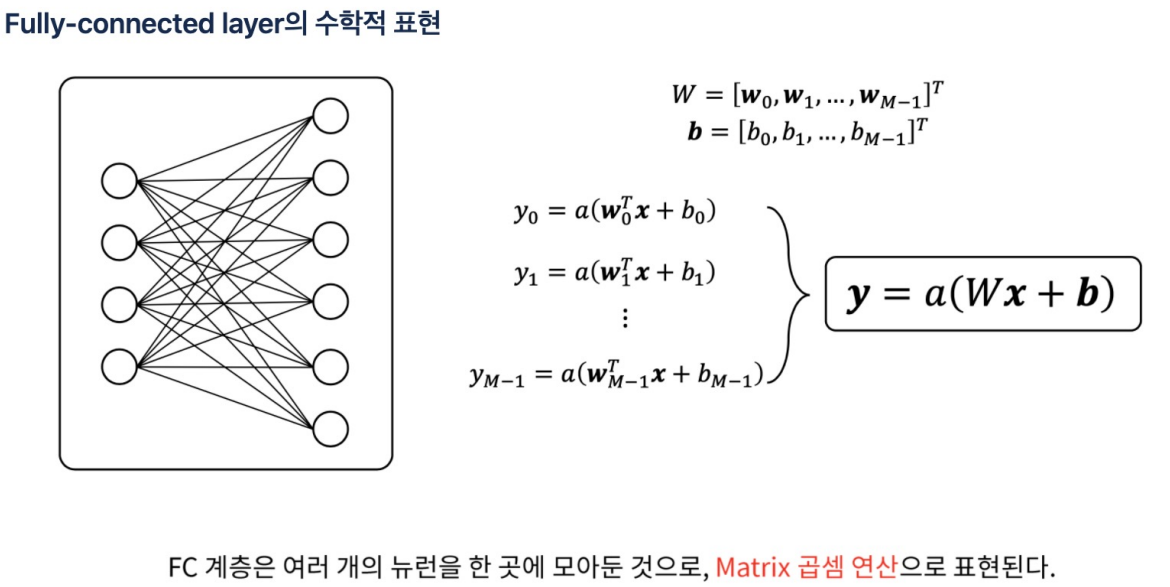
fully-connected layer에서는 weight도 벡터값이다. 각각의 입력이 모든 weight 값과 곱해지므로 weight가 행렬로 들어가야함. bias도 벡터.



선형 회귀
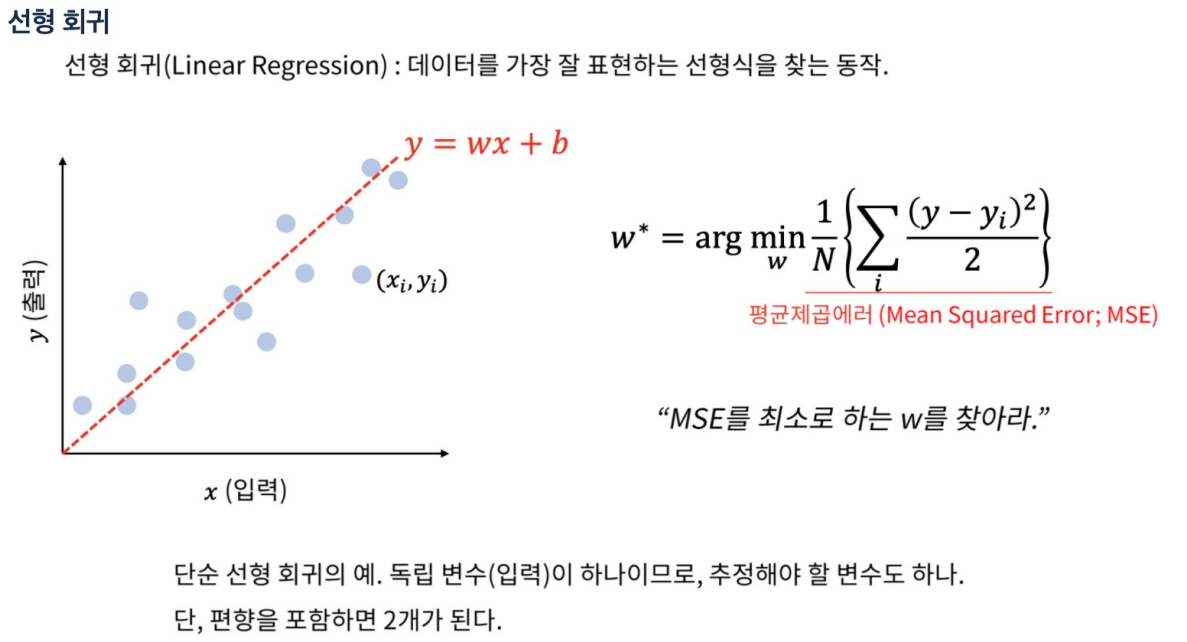
MSE의 크기가 문제가 아니다. 모델에 따라 크기가 줄었는지의 여부를 판단하는 것.

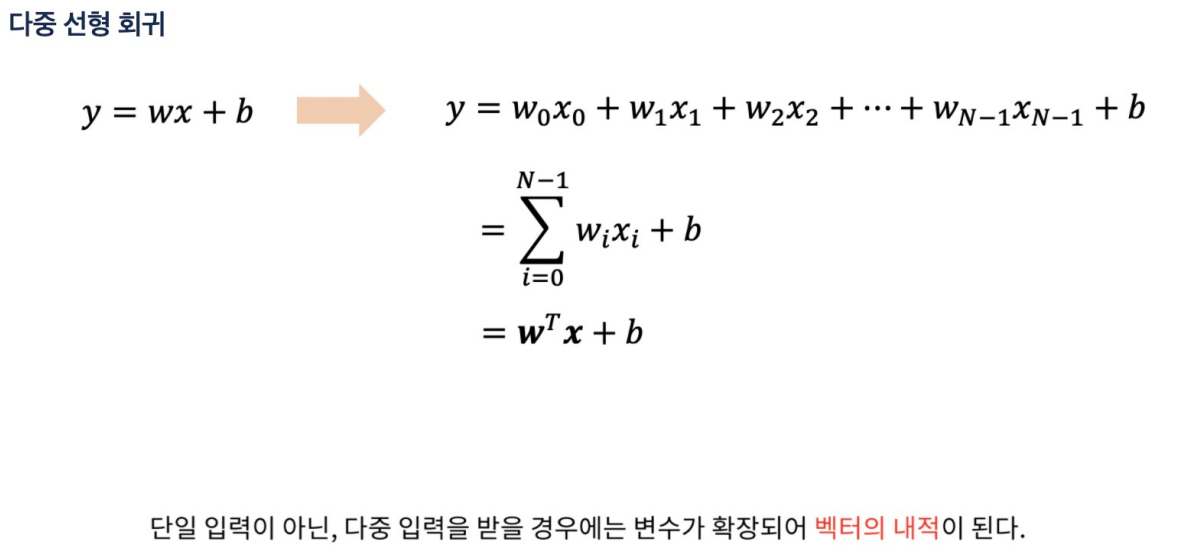
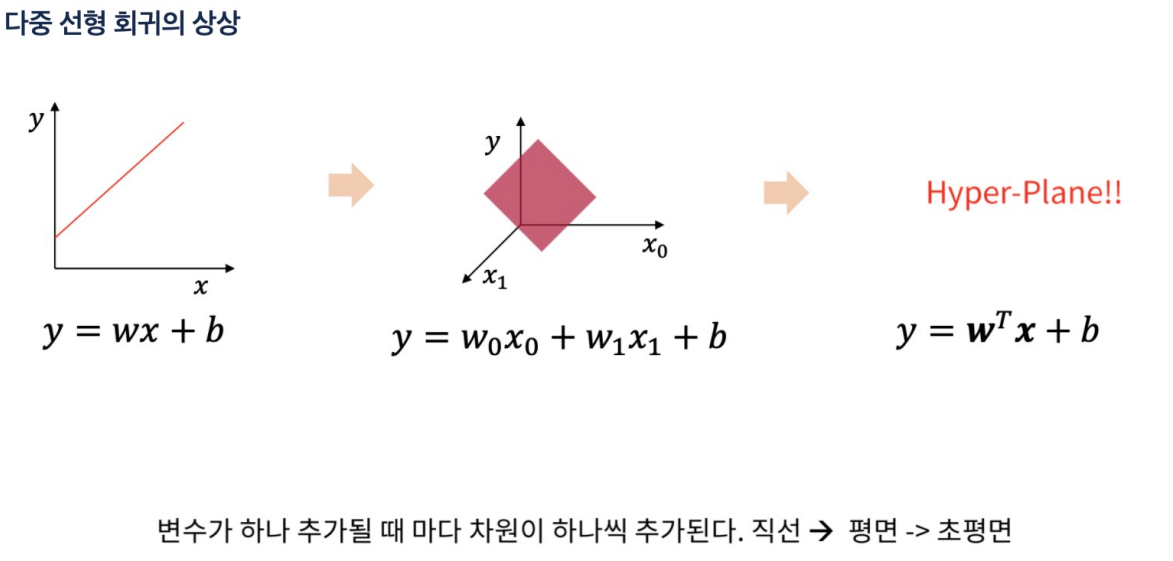
다중 선형 회귀
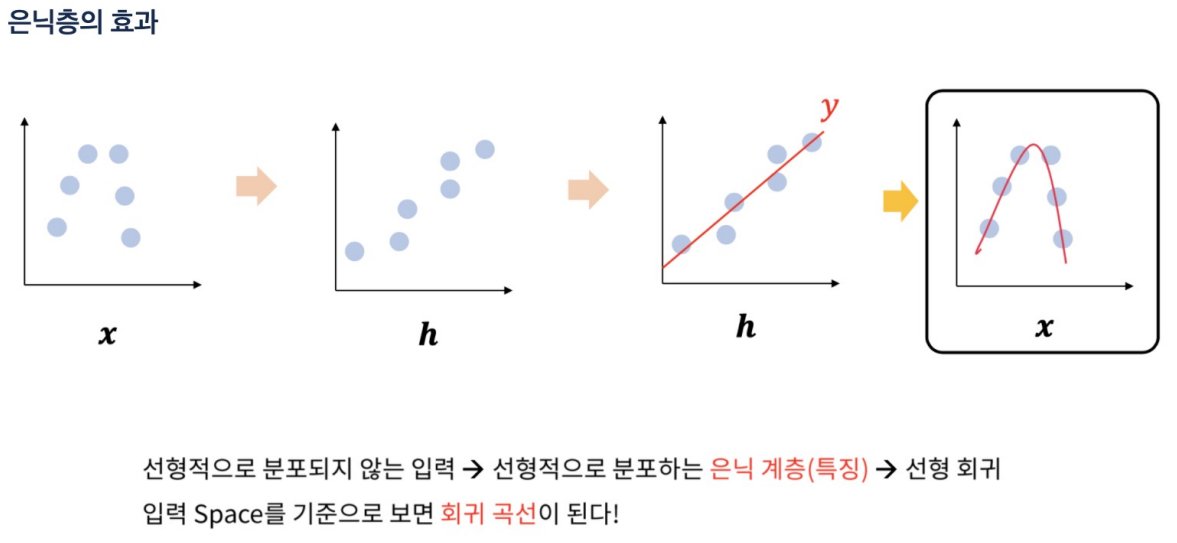
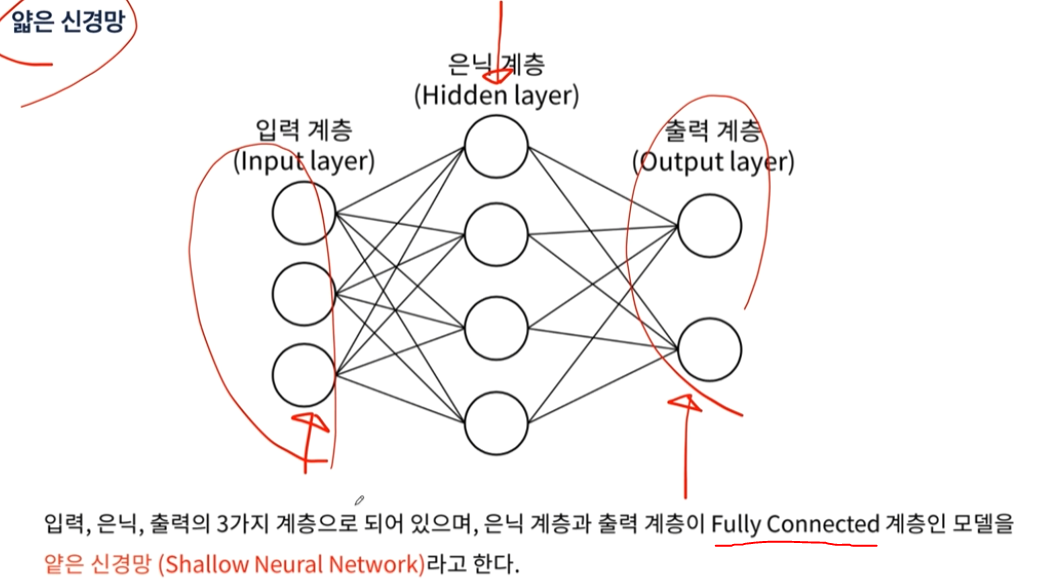
은닉층이 추가되면 직선이 아니라 복잡한 경계면을 만들 수 있다.
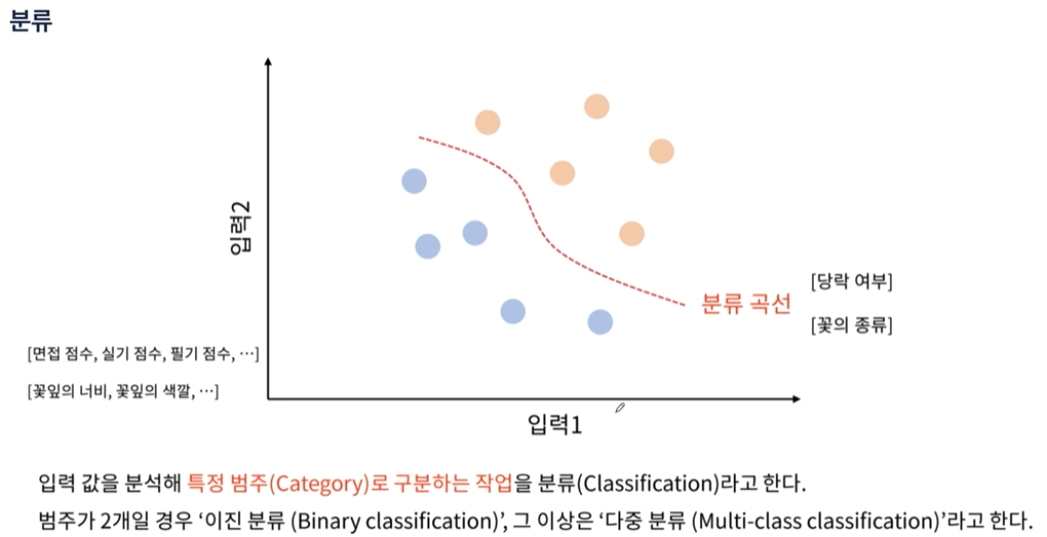
분류
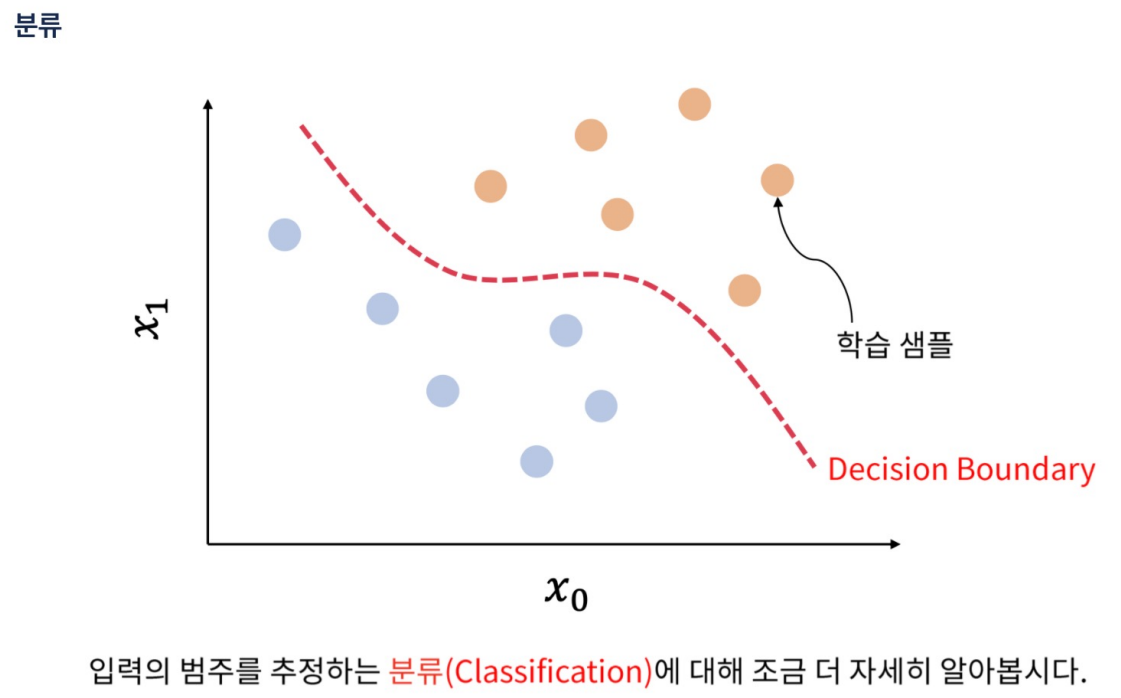
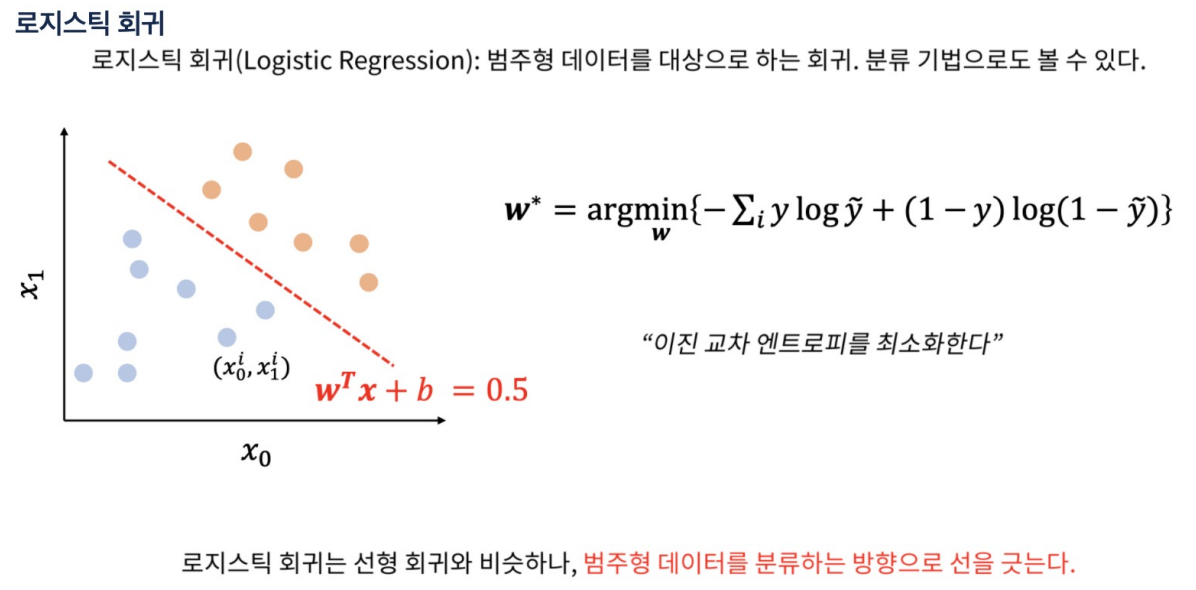
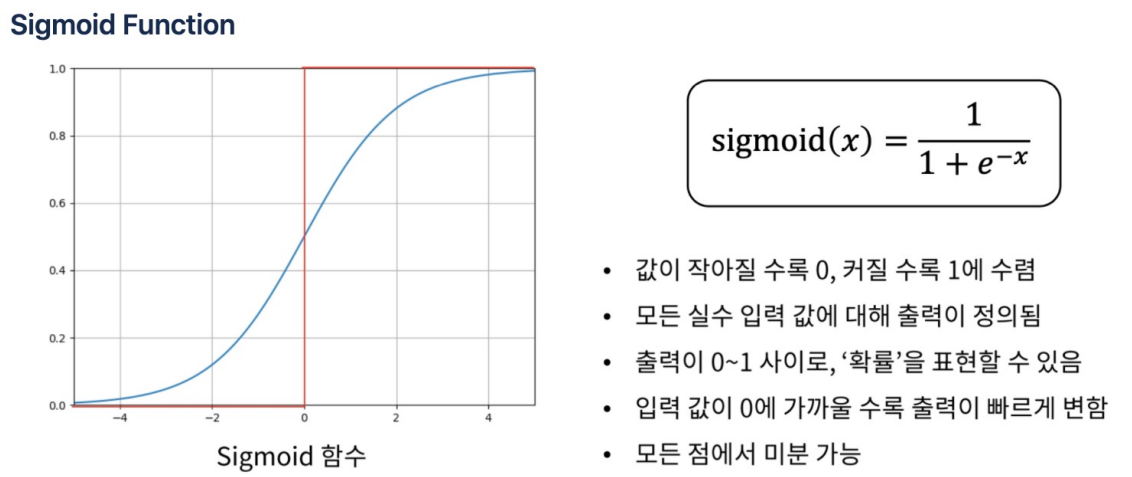
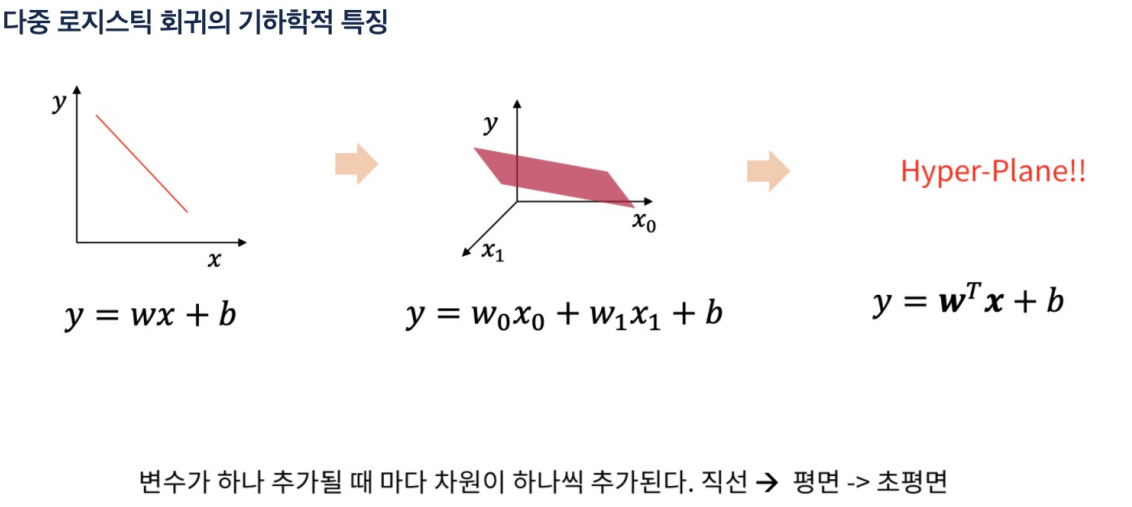
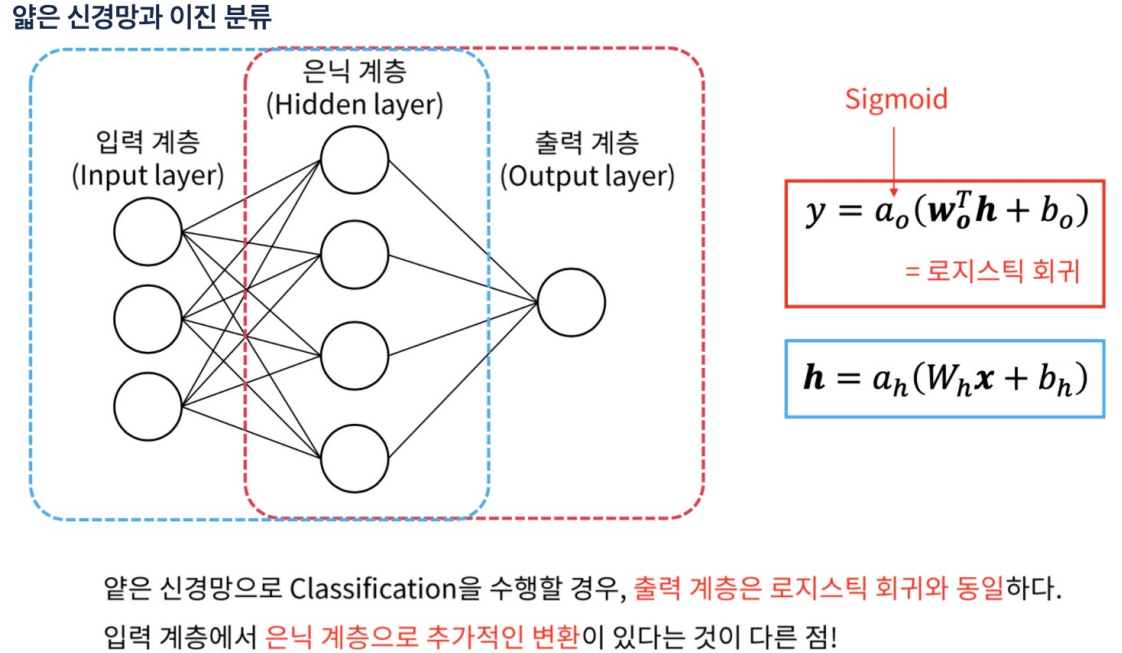
은닉층을 통과하면 x -> h 처럼 바뀜. 그러면 경계 기준선을 그을 수 있다.
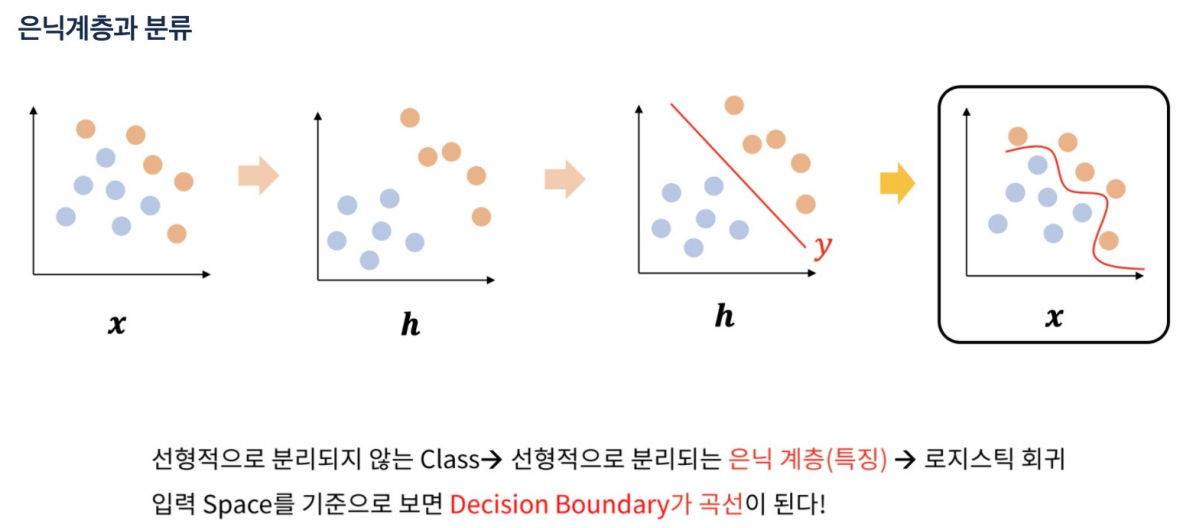
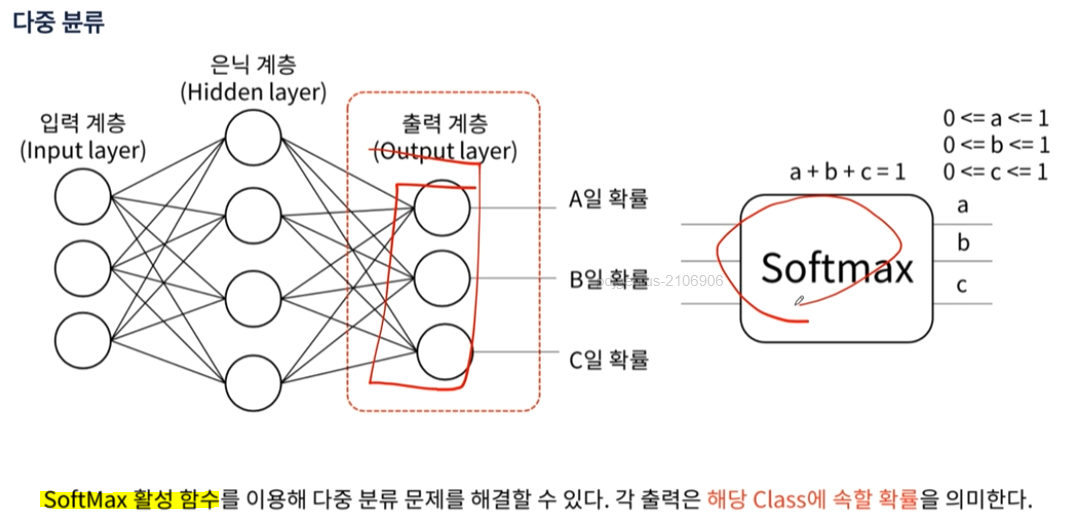
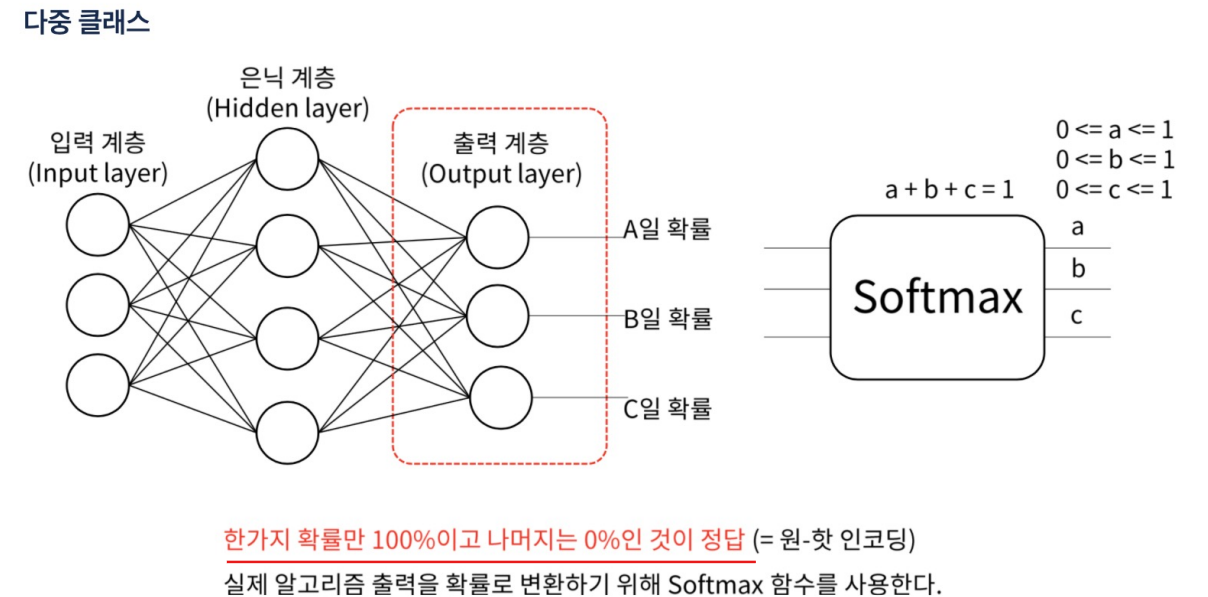
다중 분류
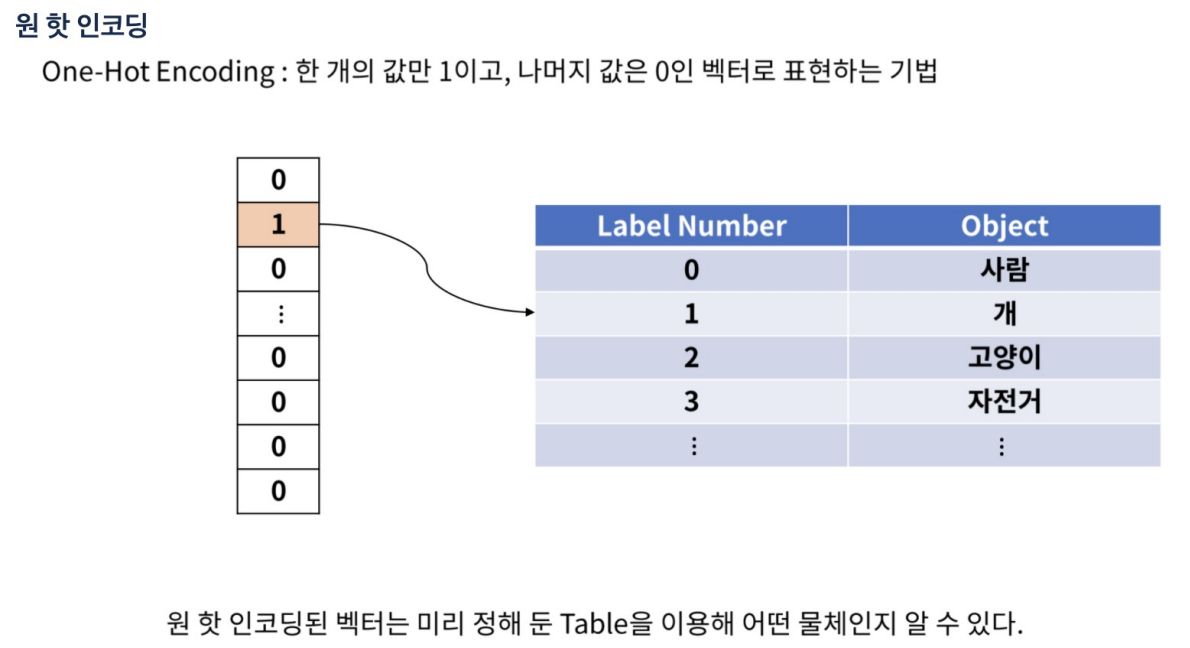
원 핫 인코딩
만약 라벨을 1~100까지로 설정했으면 실제로는 100에 해당하는 결과인데 3으로 예측했다고 오차가 크다고 할 수 없다. 이런것을 방지하기 위해 원 핫 인코딩을 사용함.
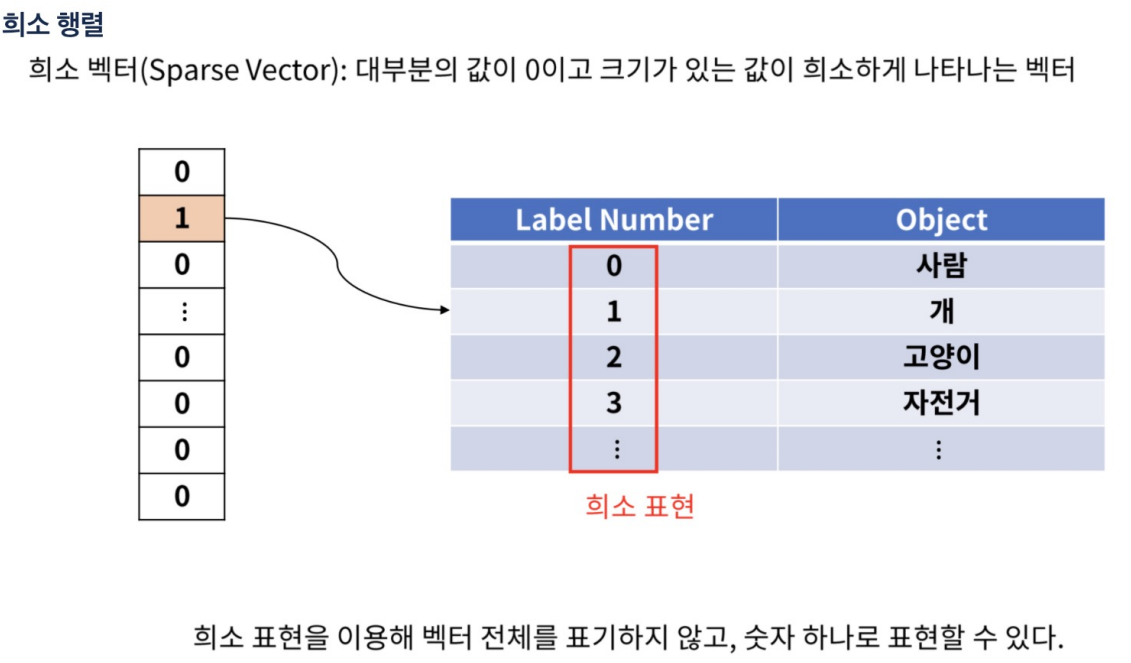
희소 행렬
다 0이고 특별한 몇개만 0이 아니라면 그 위치와 값만 알려주는 것.
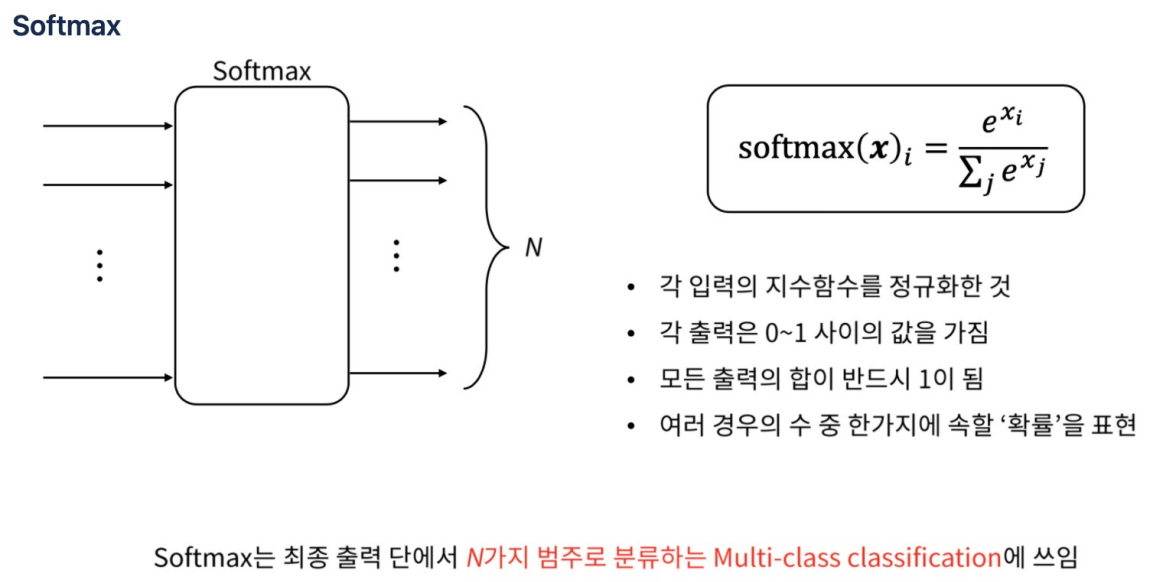
softmax
- 원 핫 인코딩이 나오면 무조건 softmax가 나온다.
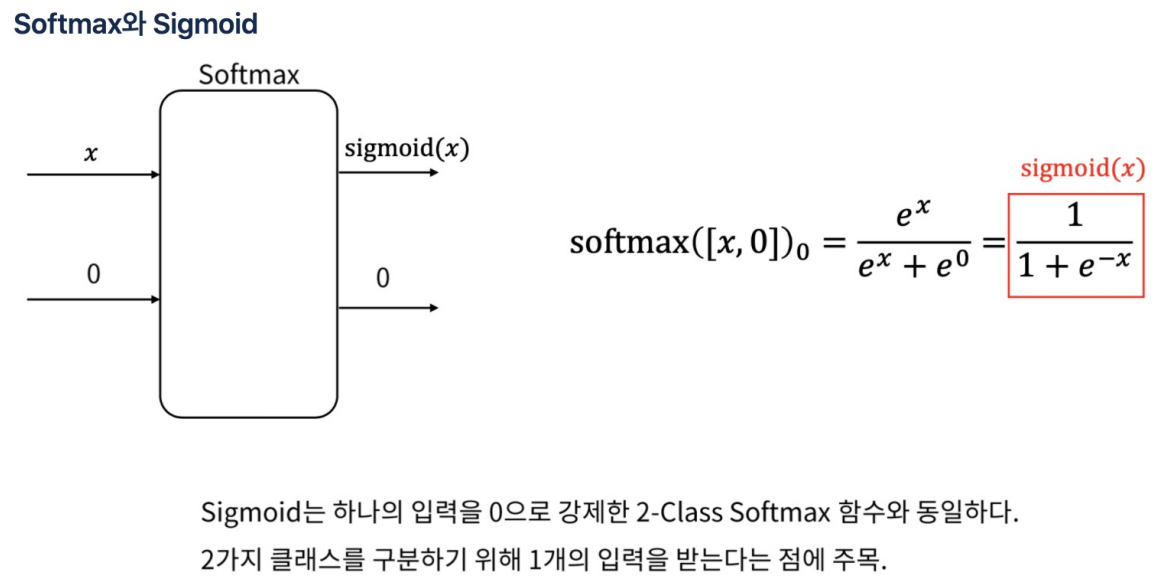
- softmax는 다중분류에서 사용.
- 하지만 입력을 1개로하면 이진분류에서 사용 가능.
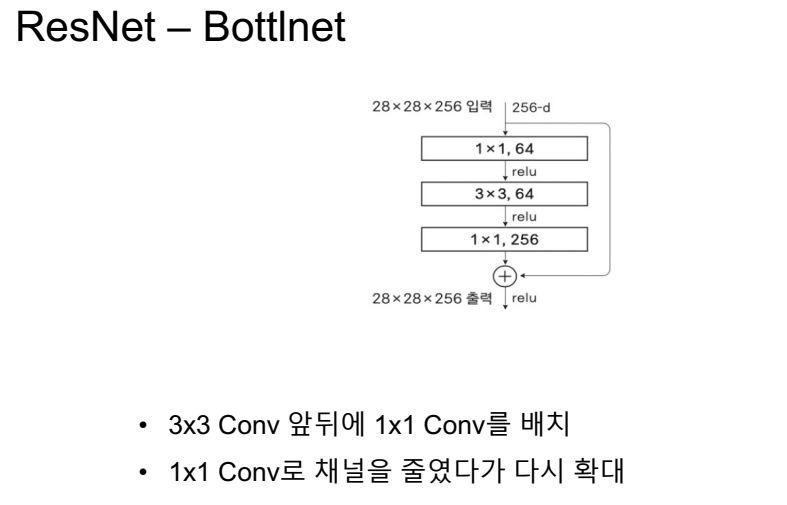
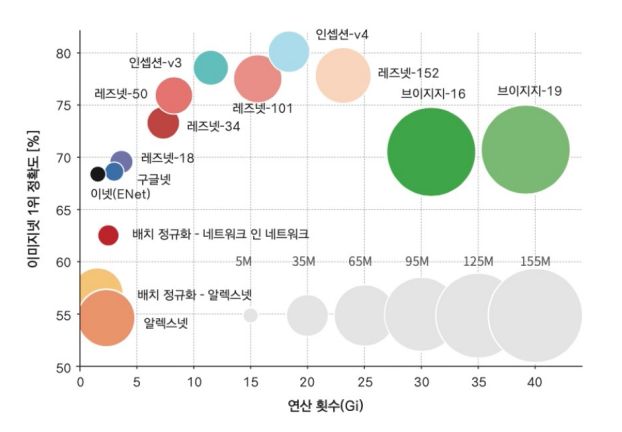
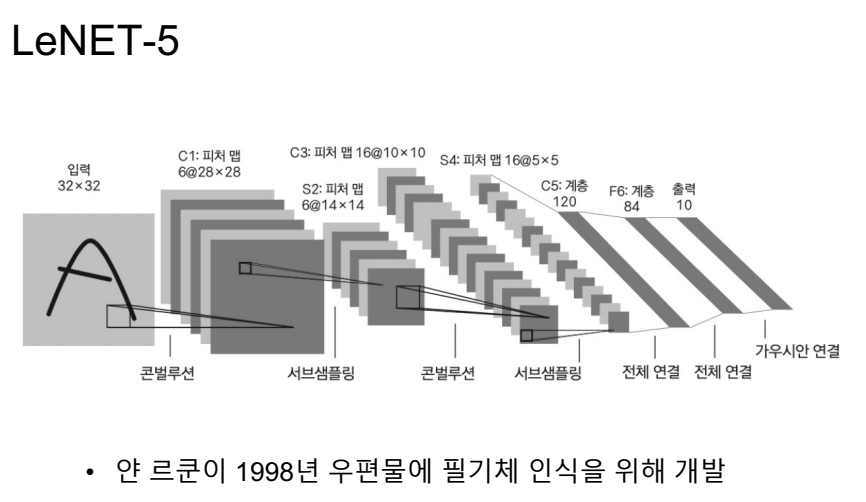
CNN 계열의 네트워크
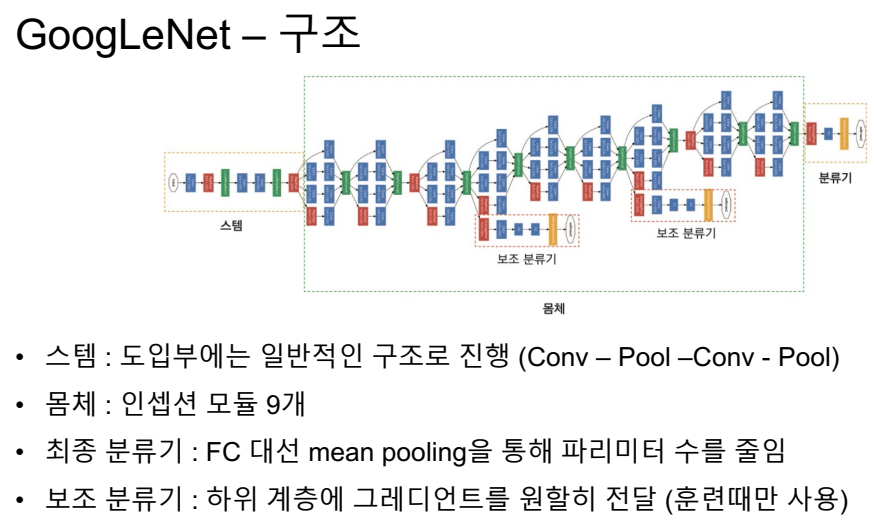
LeNET은 cnn을 통해서 어떤 성과를 얻을 수 있는지 확실하게 보여준 네트워크.
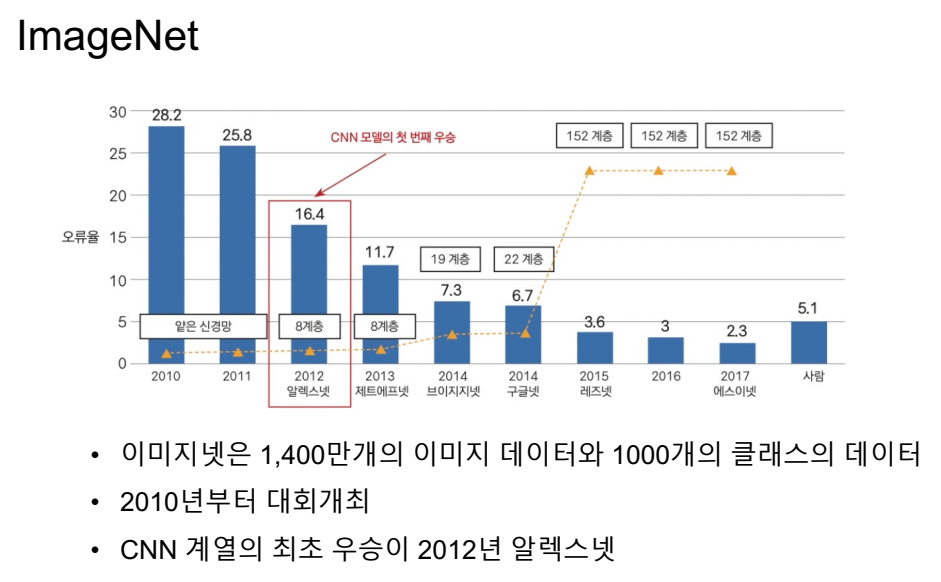
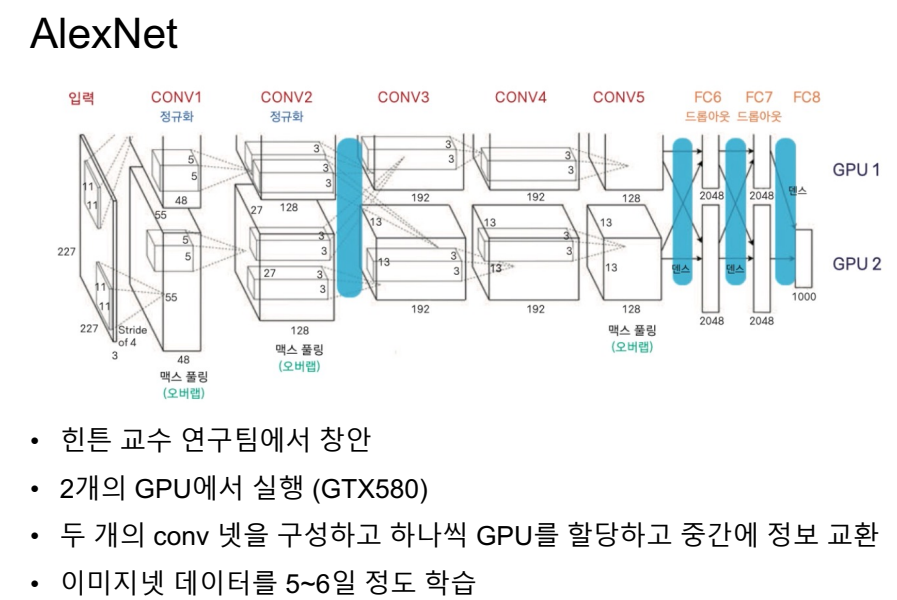
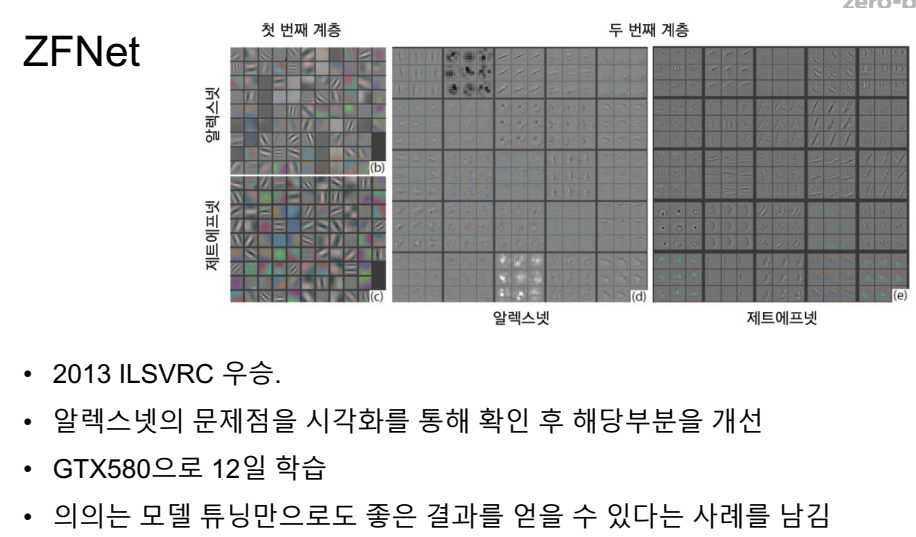
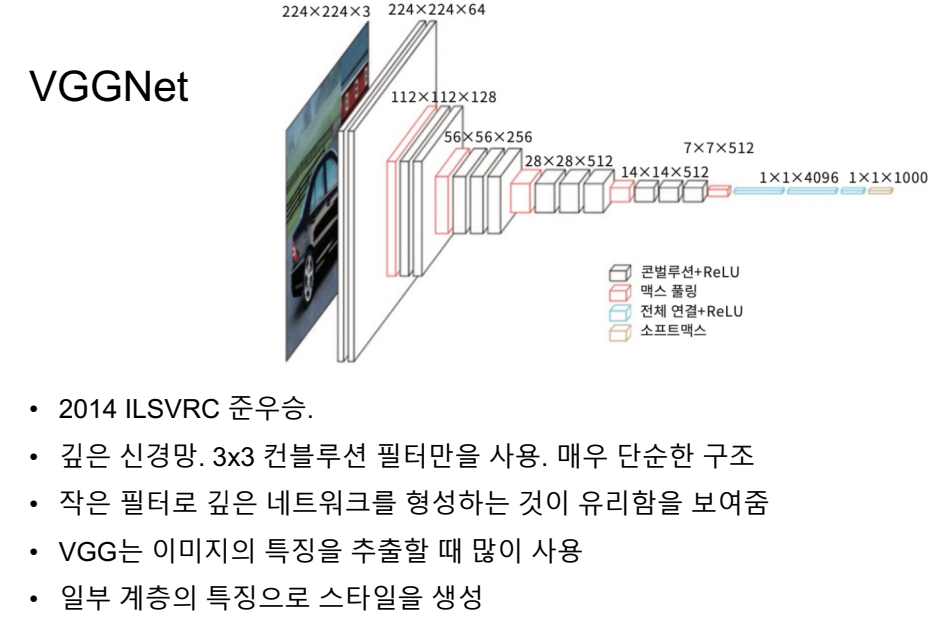
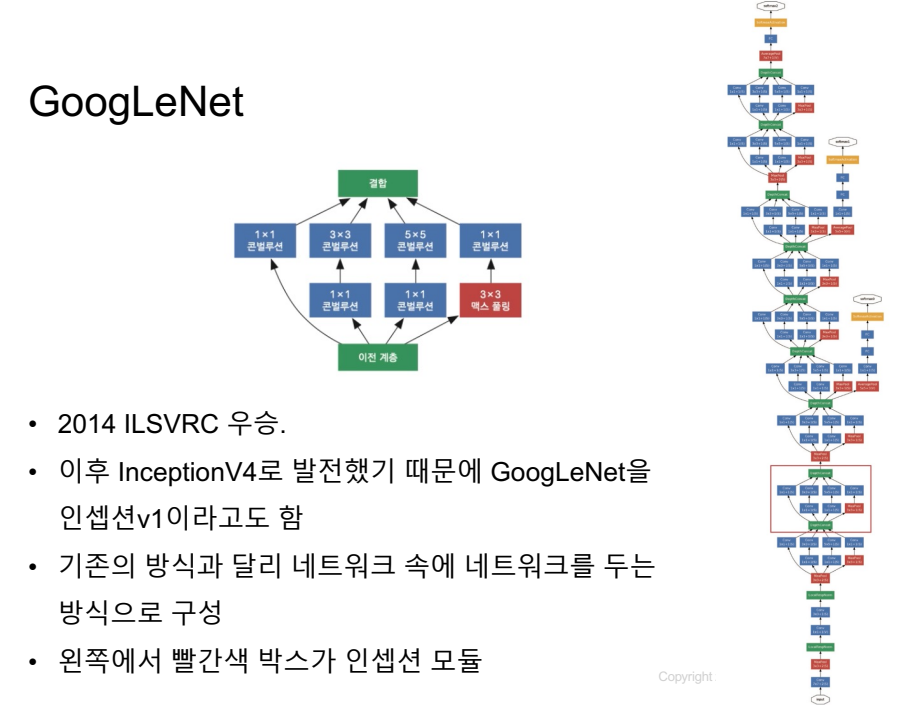
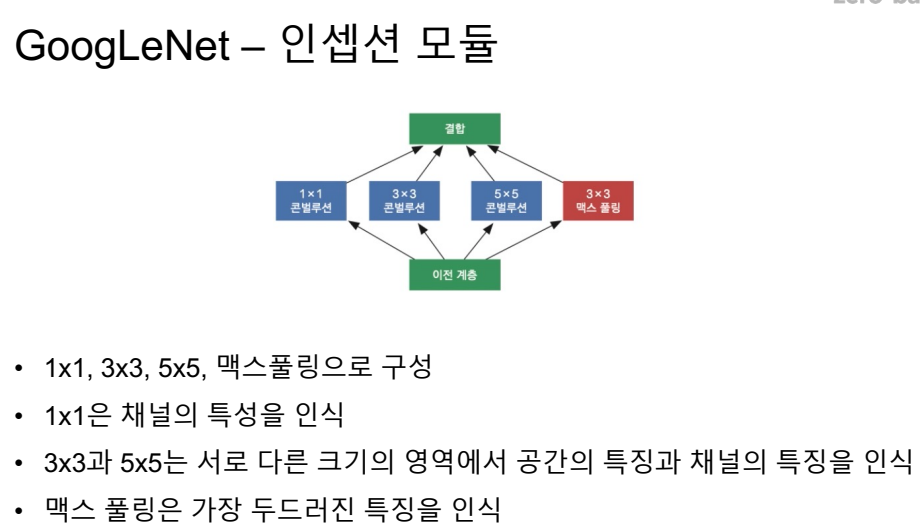
중간중간 아웃풋을 넣어둠.