Simple RNN
순환신경망
- 활성화 신호가 입력에서 출력으로 한 방향으로 흐르는 피드포워드 신경망
- 순환 신경망은 뒤쪽으로 연결하는 순환 연결이 있음
- 순서가 있는 데이터를 입력으로 받고
- 변화하는 입력에 대한 출력을 얻음
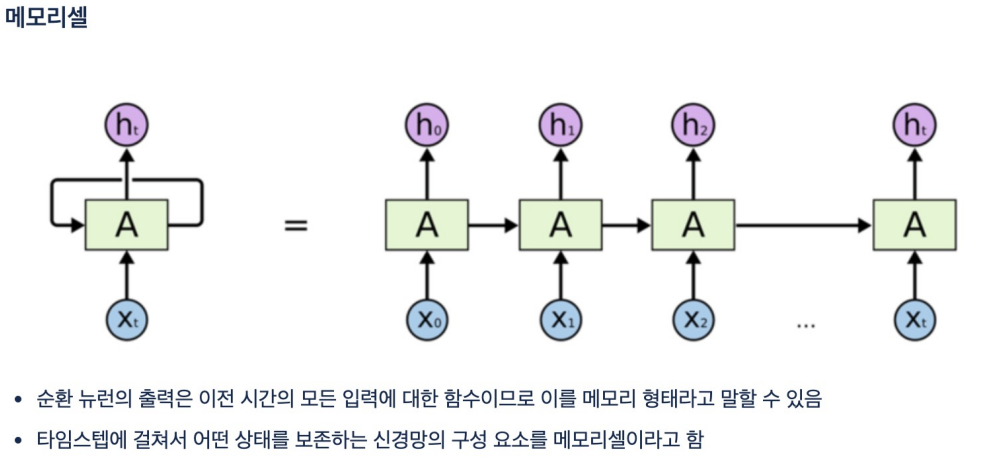
메모리셀
- 이전 셀의 출력을 가지고 다음을 진행함.
- 이전 셀의 출력은 출력층과 다음 진행을 위한 다음 셀의 입력값으로 보내진다.
- 보통의 딥러닝, 머신러닝은 시간의 순서와는 상관 없지만 RNN은 관련이 있음.
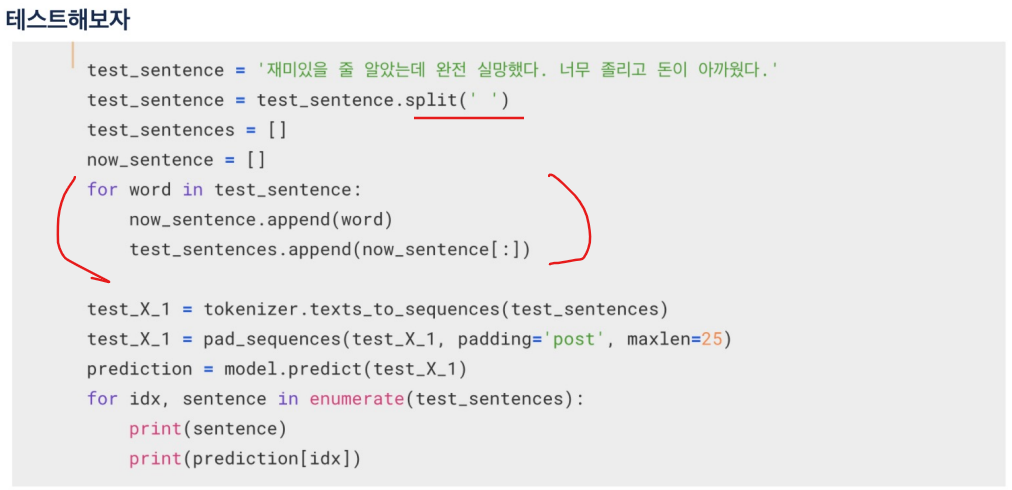
실습



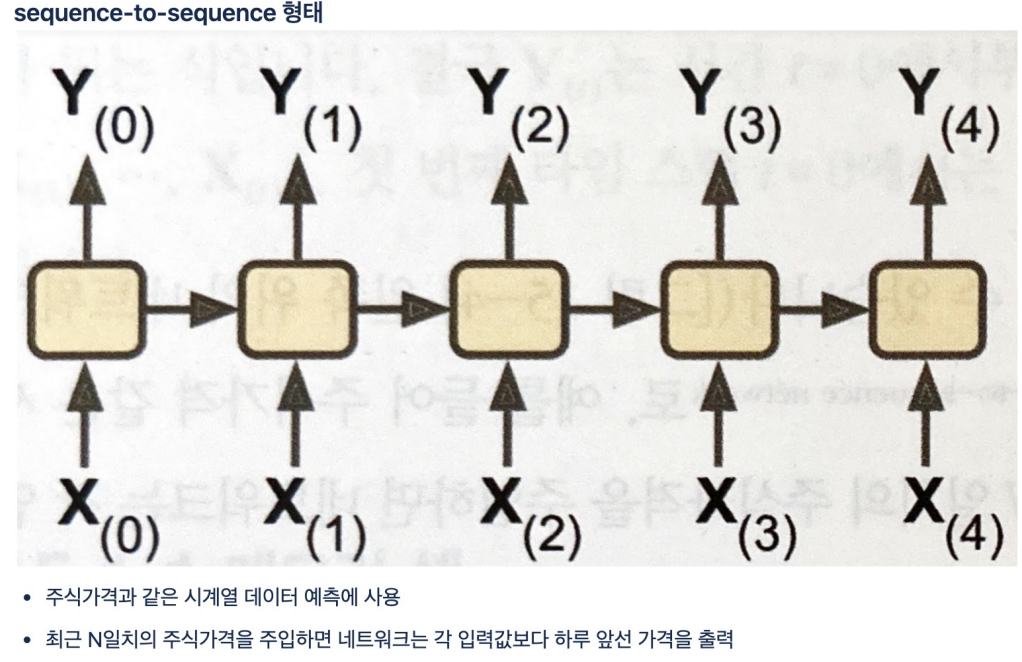
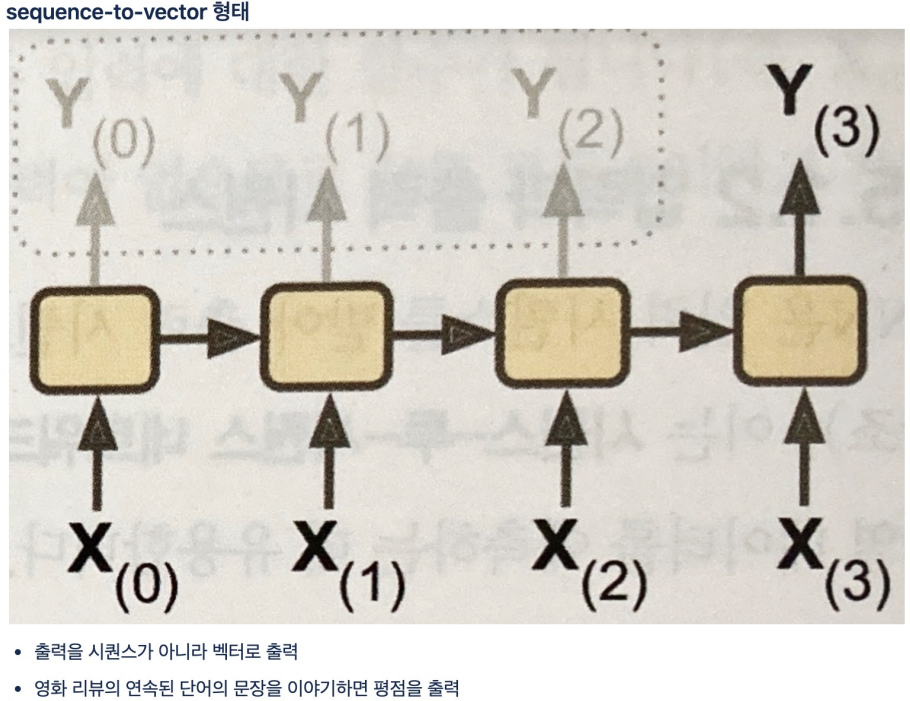
return_sequences=True 이면 sequences to sequences 처럼 모든 셀에서 출력이 있도록 설정하는 것. False이면 마지막 하나만 최종 출력.

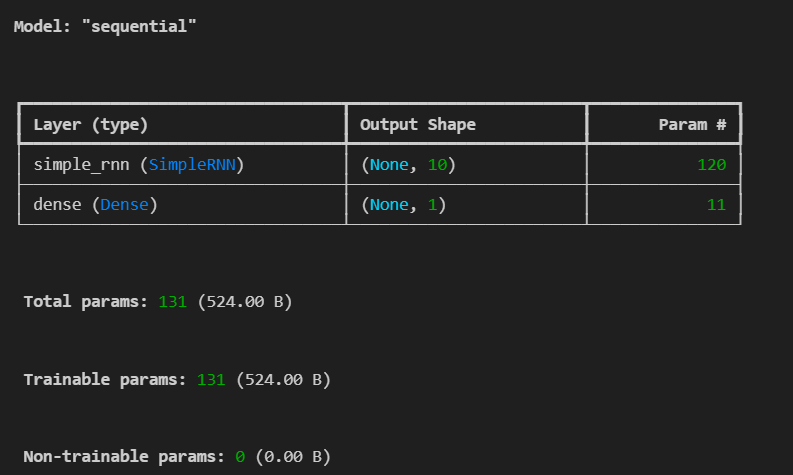
False로 설정했으니 h0, h1, h2 는 받지 않음.
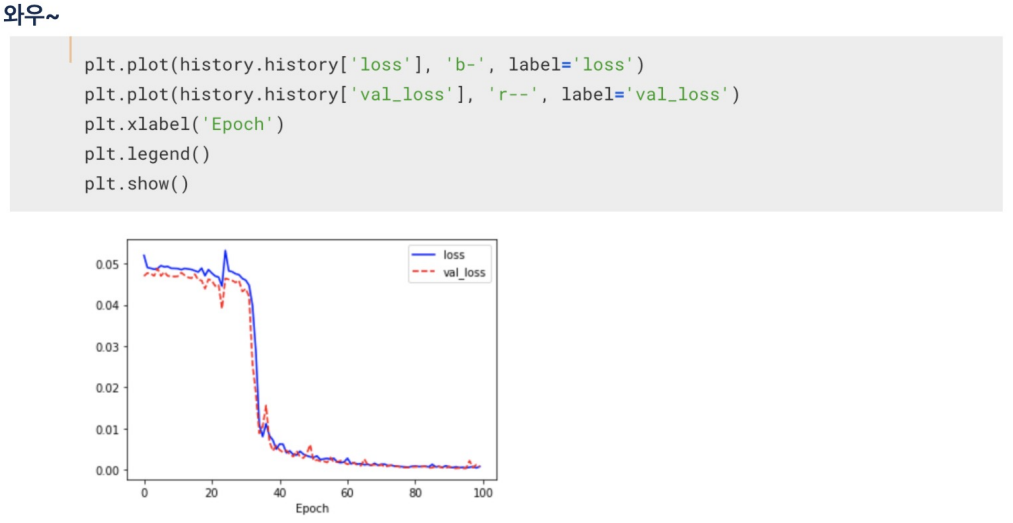
학습
epoch: 모델이 전체 데이터셋을 한 번 학습하는 것.

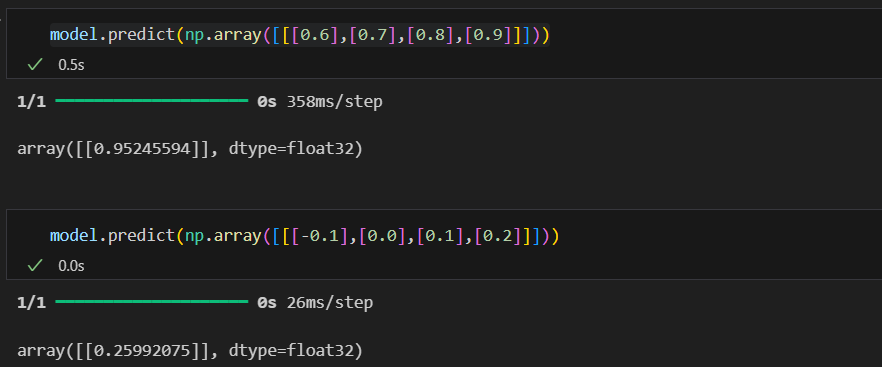
예측 -> 질문해야함
학습을 안한건 아닌데 뭔가가 부족하다고함... 뭐가 부족하다는건지는 모르겠음.
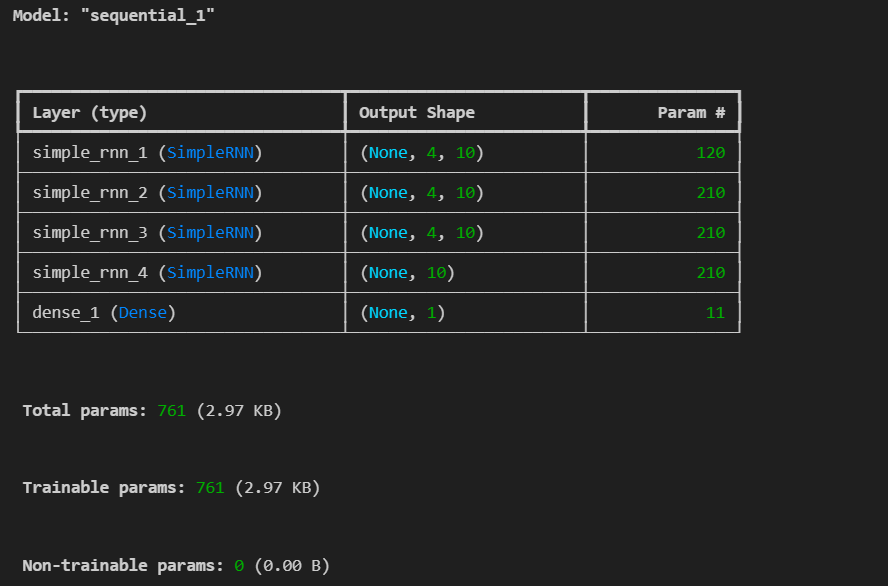
조금 더 복잡한 모델을 만듬
- 하나의 RNN 층은 여러 개의 셀로 구성됩니다. 예를 들어, units=10으로 설정하면, 그 층에는 10개의 셀이 존재.
- return_sequences=True는 각 셀마다 출력을 반환한다는 뜻.
- 각 셀마다 출력을 반환하지 않아도 각각의 타입스텝(각 셀들이 이전 셀의 결과를 입력으로 받아 진행)을 하는데 뭐하러 출력을 반환하냐?

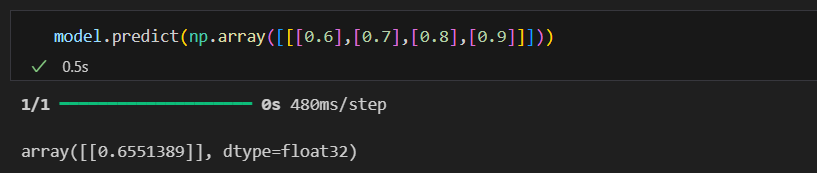
결과를 보면 성능이 조금 더 좋아짐.
LSTM
simple RNN의 단점
- 입력 데이터가 길어지면 학습 능력이 떨어진다 - Long-Term Dependency 문제
- 현재의 답을 얻기 위해 과거의 정보에 의존해야 하는 RNN이지만, 과거 시점이 현재와 너무 멀어지면 문제를 풀기 어렵다
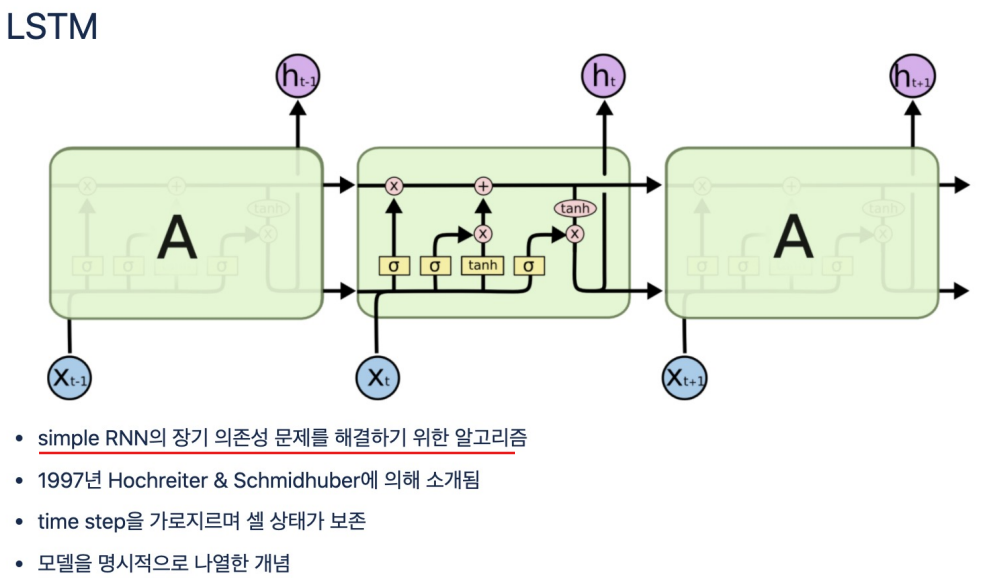
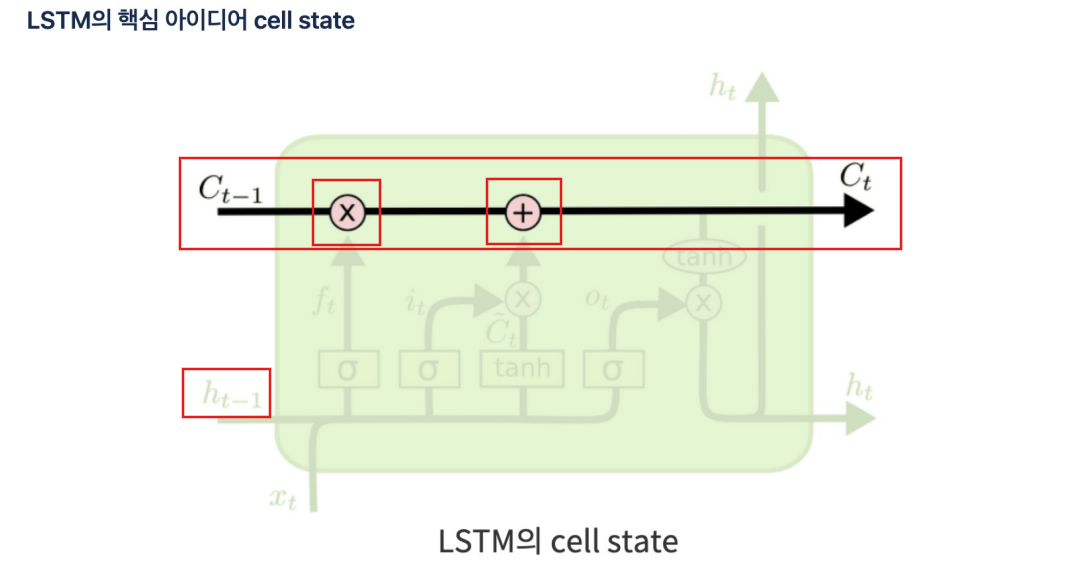
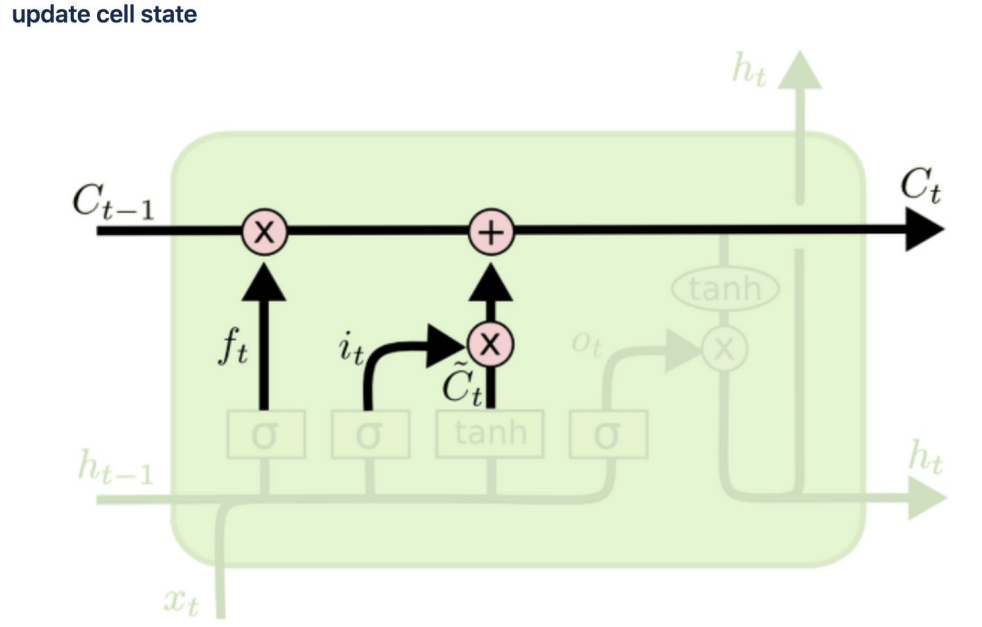
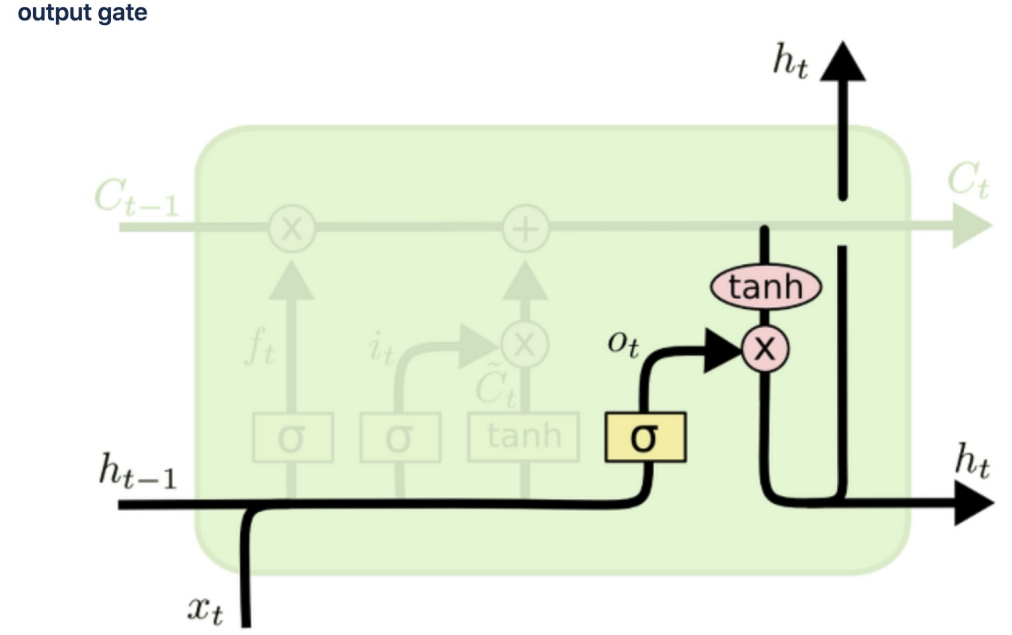
cell state
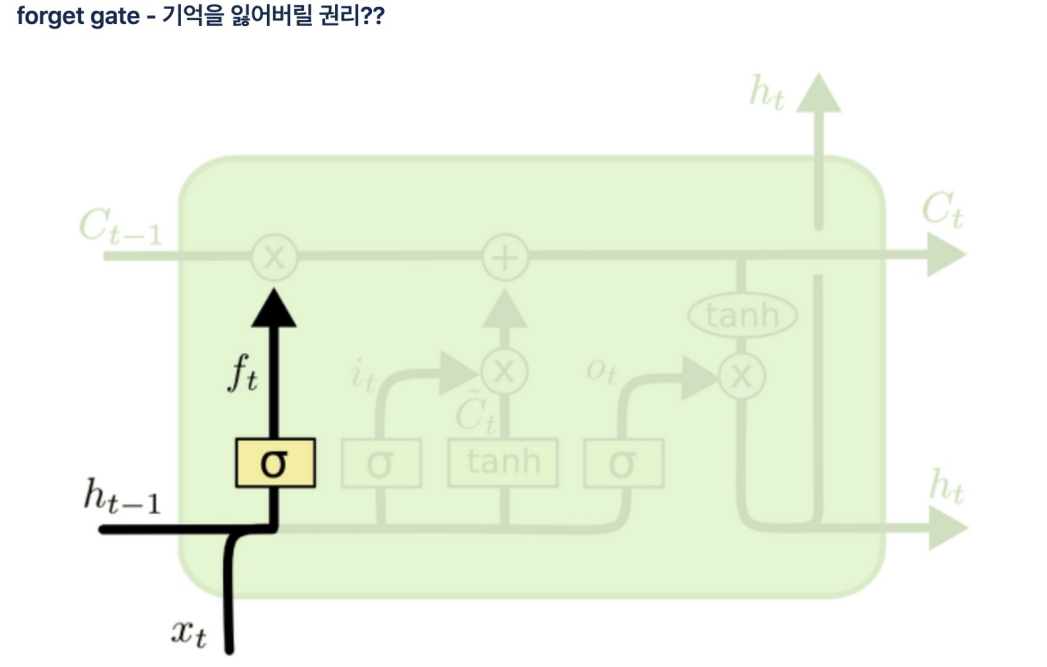
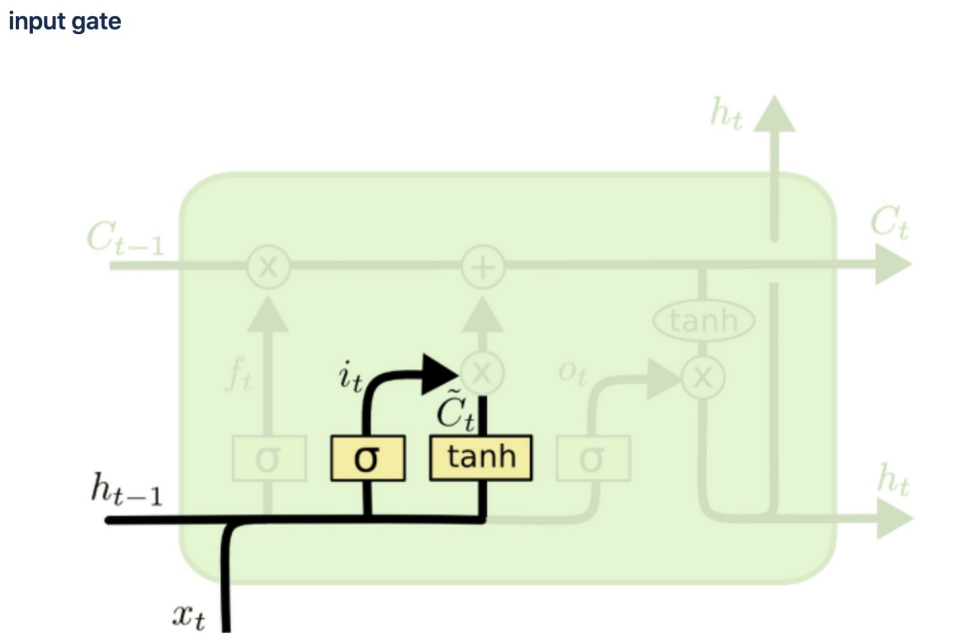
이전 기억을 얼마나 보존할것인지 정하고(ht-1이 시그모이드 함수 통과 후 곱셈) 현재 기억을 얼마나 첨가할지 결정할지 정해서 옆셀로 보내줌




감정분석
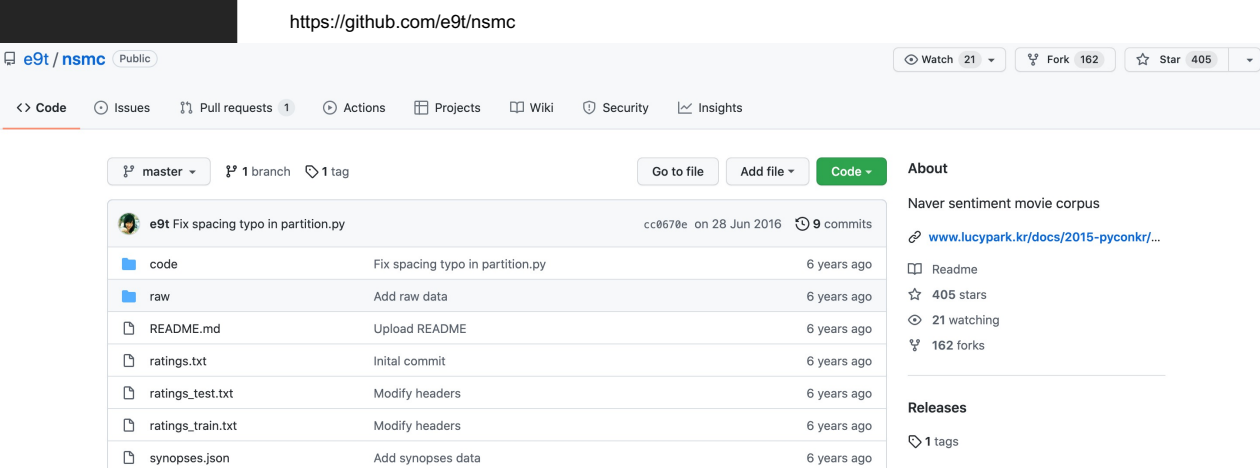
감성분석 Sentiment Analysis
- 입력된 자연어 안의 주관적 의견, 감정 등을 찾아내는 문제
- 이중 문장의 긍정/부정 등을 구분하는 경우가 많음
어떤 내용이 있나 살펴보면
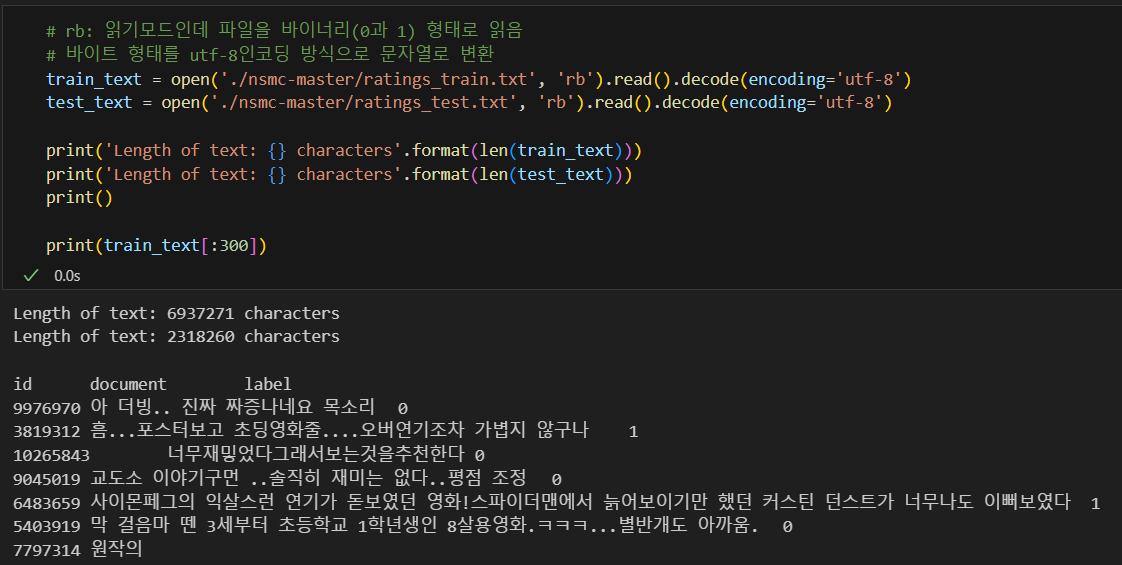



tokenization과 cleaning
- tokenization : 자연어를 처리 가능한 최소의 단위로 나누는 것으로 여기서는 띄어쓰기로 하자
- cleaning은 불필요한 기호를 제거하는 것


14만개 정도가 단어 개수가 40개도 안됨.
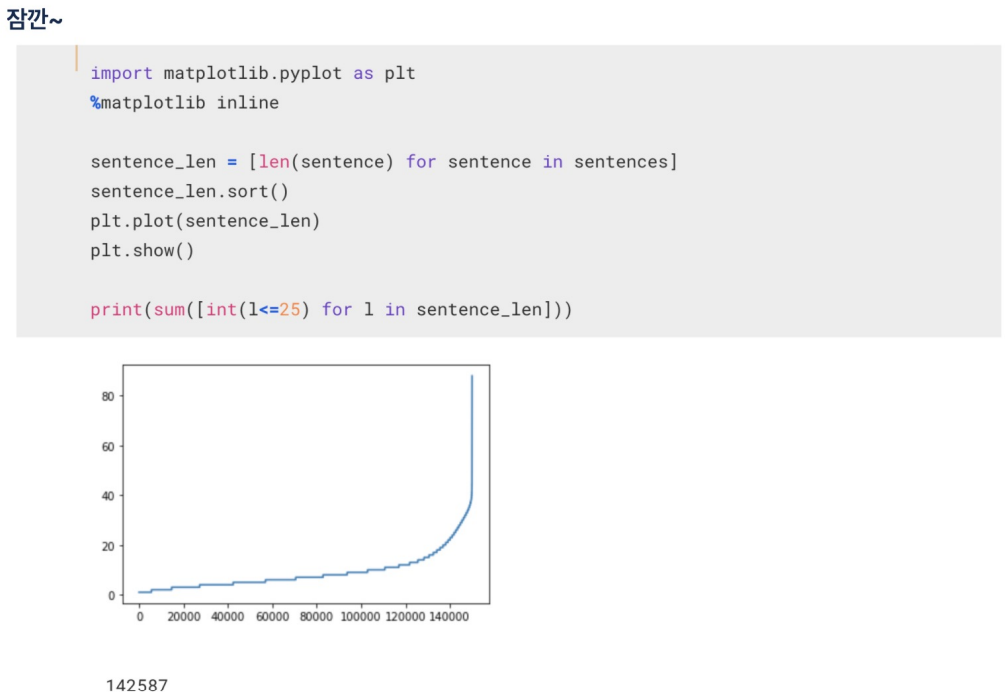
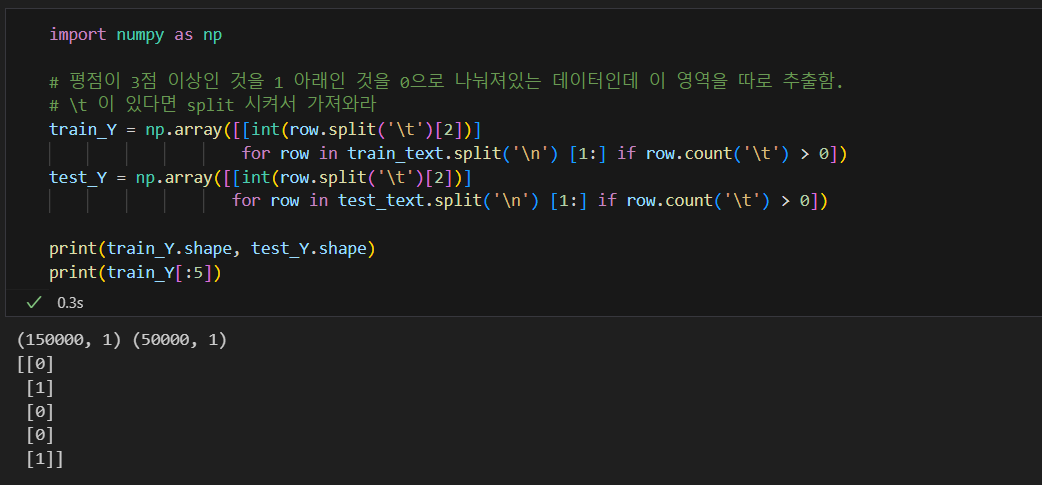
데이터 크기 맞추기
- 학습을 위해 네트워크에 입력을 넣을때 입력 데이터는 그 크기가 같아야 한다
- 입력 벡터의 크기를 맞춰야하는데, ..
- 여기서는 긴 문장은 줄이고, 짧은 문장은 공백으로 채우자
- 15만개의 문장 중에 대부분이 40단어 이하로 되어 있음
문장을 25개 단어까지만 나타내도록 짤라줌

pad_sequences: 자연어처리에서 문장의 길이가 다를때 동일한 길이로 맞추기 위해 0으로 채워줌. (value의 기본값이 0으로 설정되어 있음)

모델구성
- 0과 1만 볼거면 시그모이드 함수를 사용해도 됨.
- 하지만 (1,0)을 긍정으로 보고 (0,1)을 부정으로 본다고 하면 softmax
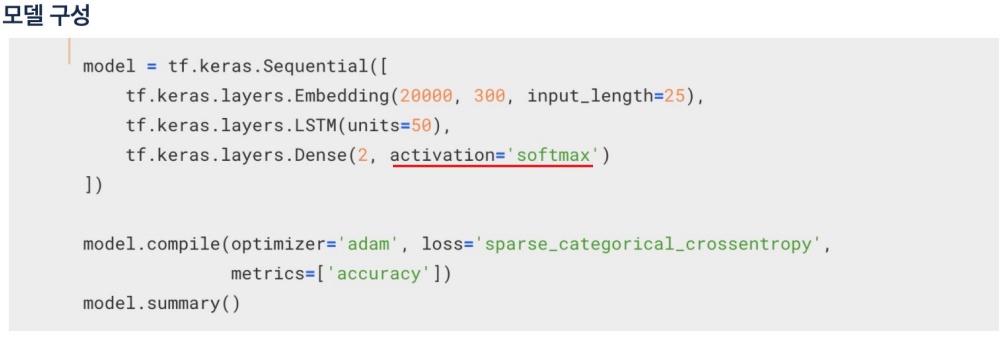

일단 나는 이렇게 안나옴.

학습
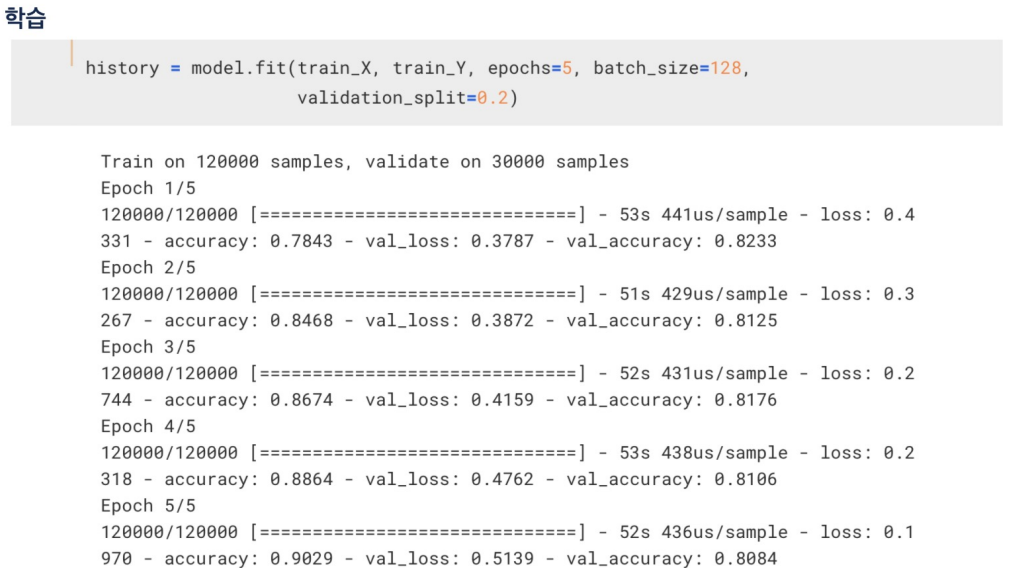
띄어쓰기로 분리시키고 리스트로 만들고