명함 검출과 인식 개요



영상의 이진화
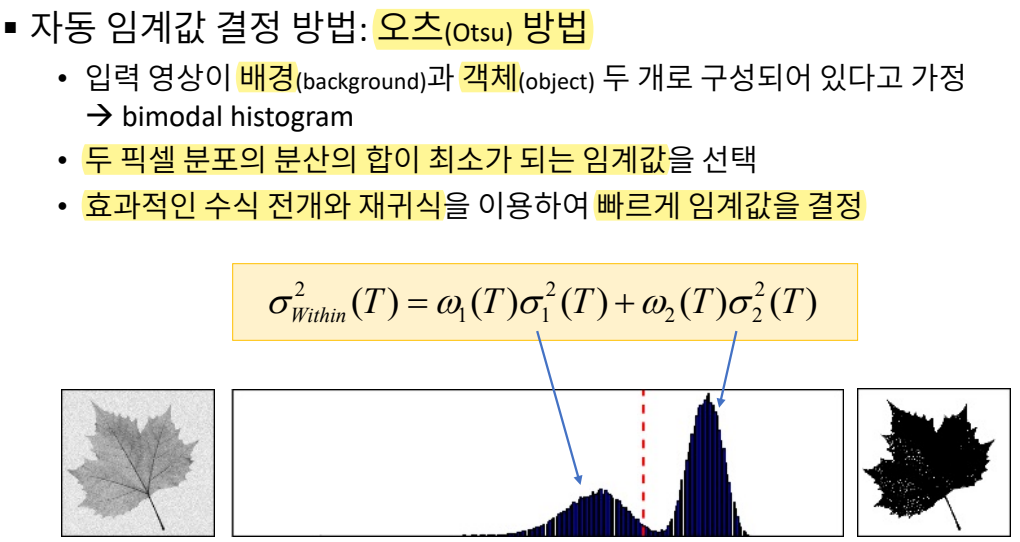
배경 vs 객체를 나누거나 관심있는 영역 vs 관심없는 영역으로 나누기 위해 사용함.

f(x, y)는 픽셀값. T=200 이상은 밝은 영역에 대한 픽셀값이 모여있는 구간이므로 threshold를 200으로 잡음.
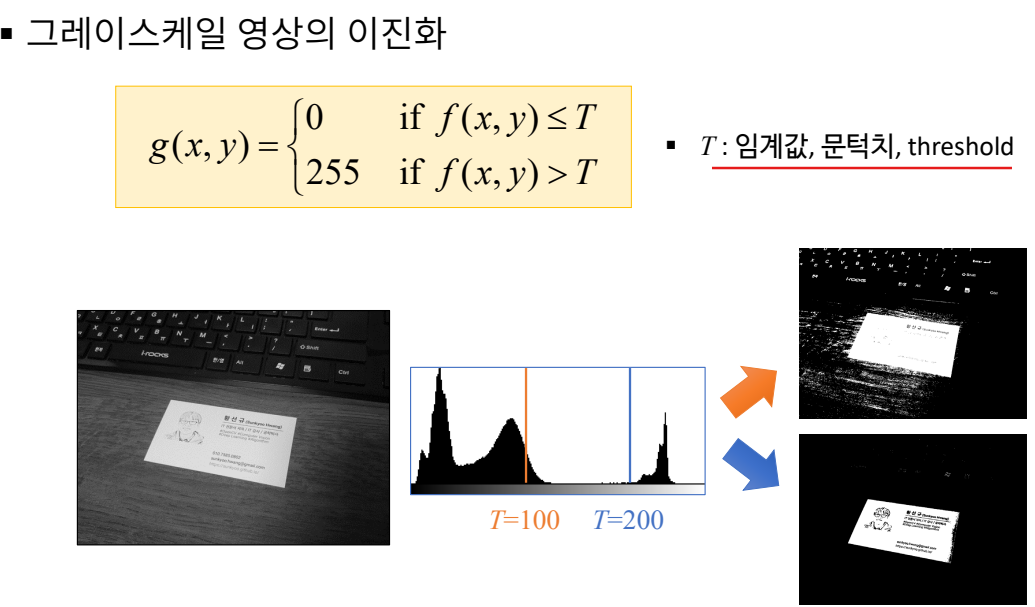
- 임의로 임계값을 줌
- 이진화: threshold보다 작으면 0 크면 255로 픽셀값을 세팅
- 자동 이진화 방식을 사용하면 사용자가 입력한 thresh 값은 무시되고 수행됨.

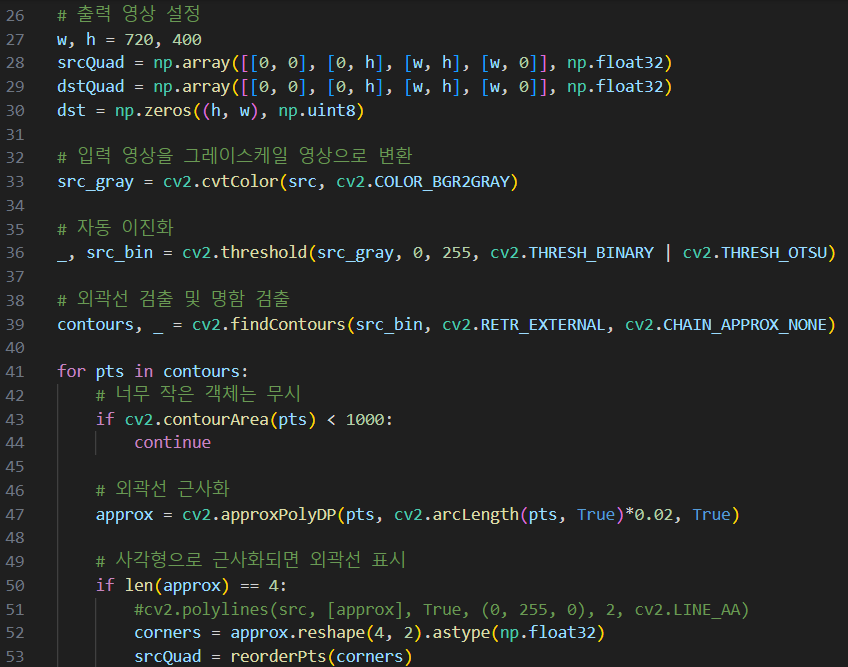
객체의 외곽선 검출
객체 단위 분석
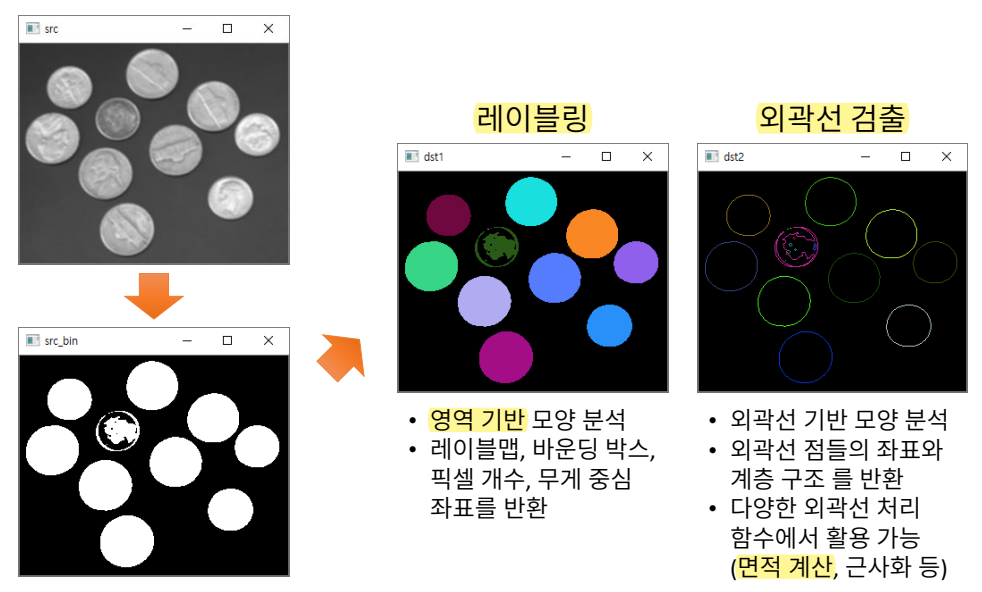
객체의 외곽선 검출
shape에서 k행 2열이지만 c++기반의 코드를 파이썬에 사용하려다보니 3차원으로 표현이 된 부분이 있음.

cv2.findContours
- 바깥쪽에 있는 외곽선과 안쪽에 있는 외곽선을 계층으로 나눔.
- 근사화: 검출된 외곽선의 좌표를 다 저장하는 것이 아니라 몇몇 좌표만 저장하는 것.



OpenCV 외곽선 함수
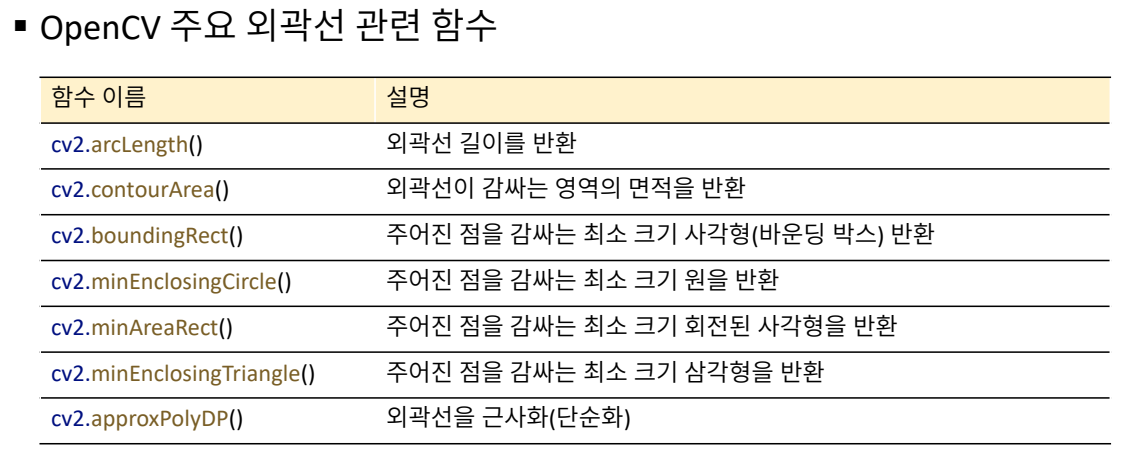
cv2.arcLength()

cv2.contourArea()
일반적으로 면적을 구할 때에는 방향성이 없어서 oriented는 주지 않음.

cv2.approxPolyDP()
epsilon은 근사화 정확도를 결정하는 오차 허용값. 외곽선 전체 길이값 기준으로 2% 정도에 해당하는 길이를 오차의 범위로 한다는 의미.

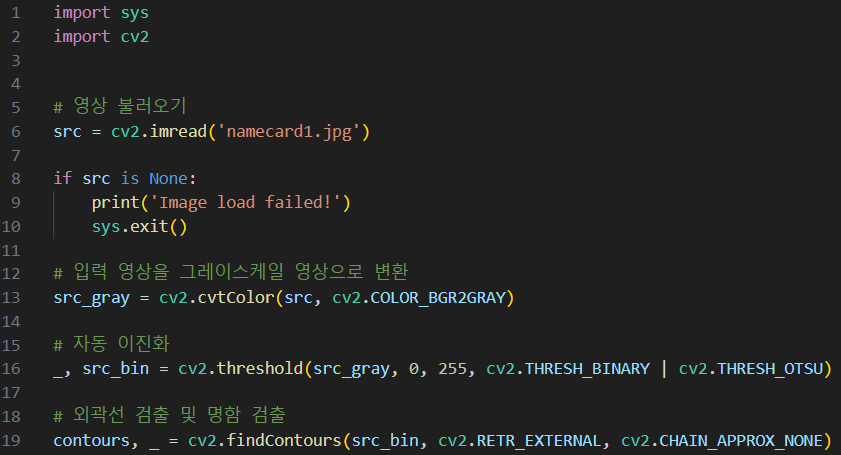
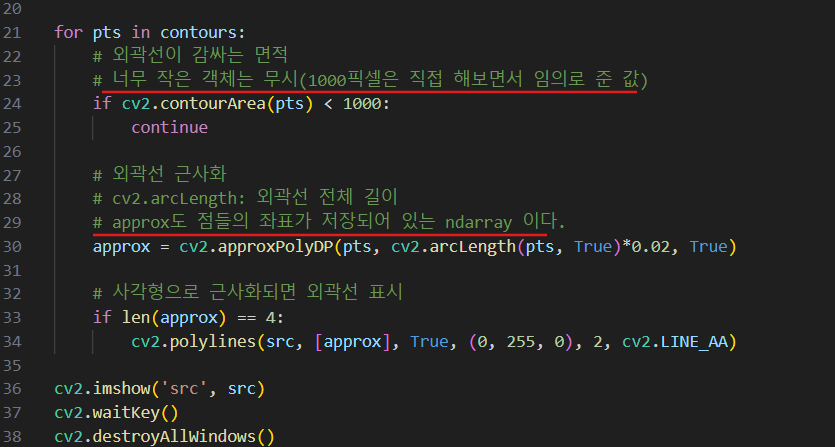

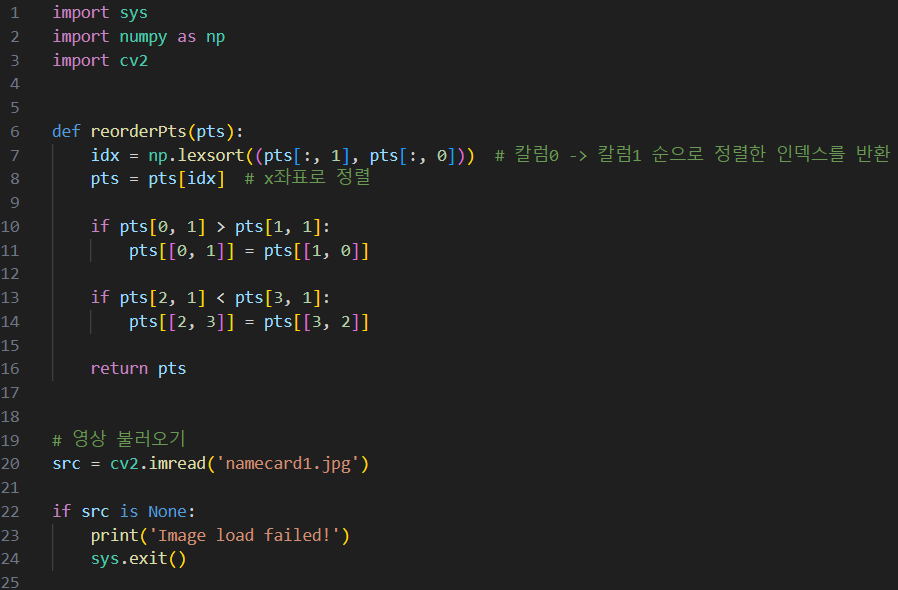
명함 똑바로 펴기
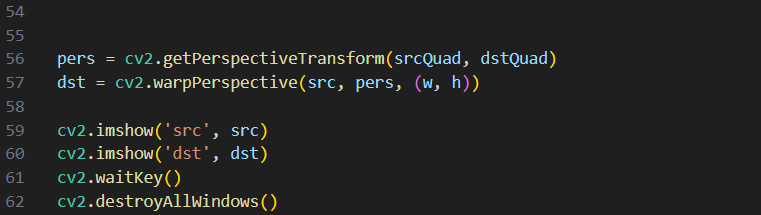
영상의 기하학적 변환

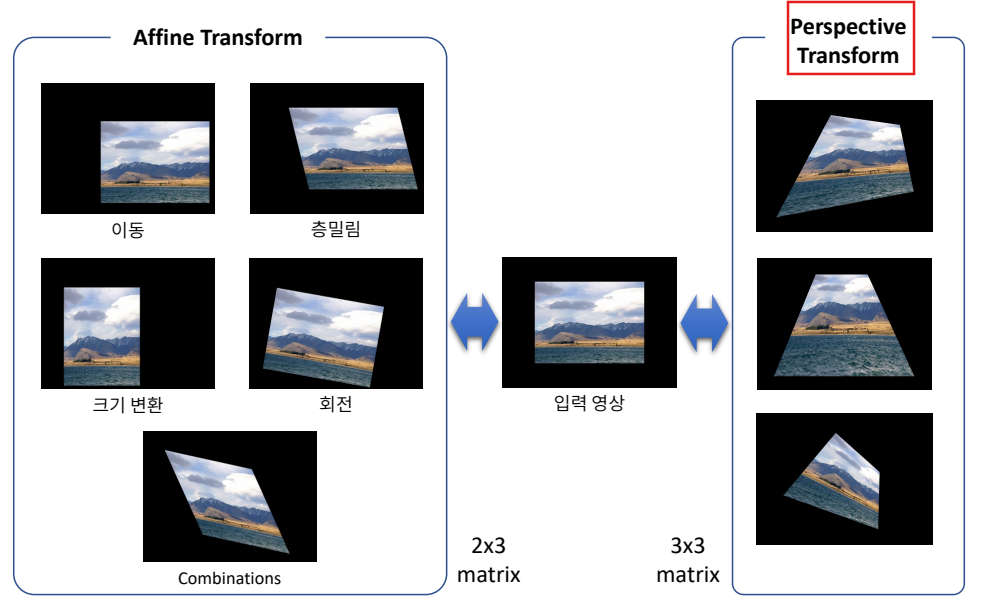
perspective Transform은 (3,3) 행렬인데 이중 하나의 원소는 나머지 8개의 원소에 의존적이다. 그래서 나머지 8개의 미지수를 구해야하는데 그러려면 8개의 방정식이 필요하다. 이때 점 하나의 이동관계에서 x, y좌표에 대한 관계에 대한 식들이 하나씩 나오므로 4개의 좌표에서의 이동관계를 알게되면 8개의 미지수를 모 두 알 수 있다. 이로 인해 변환에 필요한 행렬을 구할 수 있다.
cv2.getPerspectiveTransform
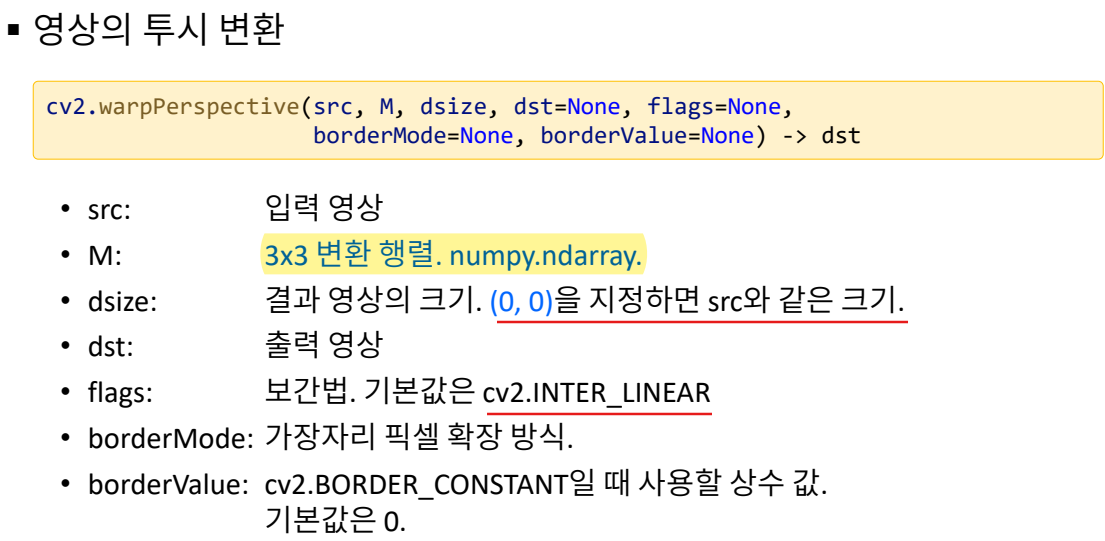
cv2.warpPerspective
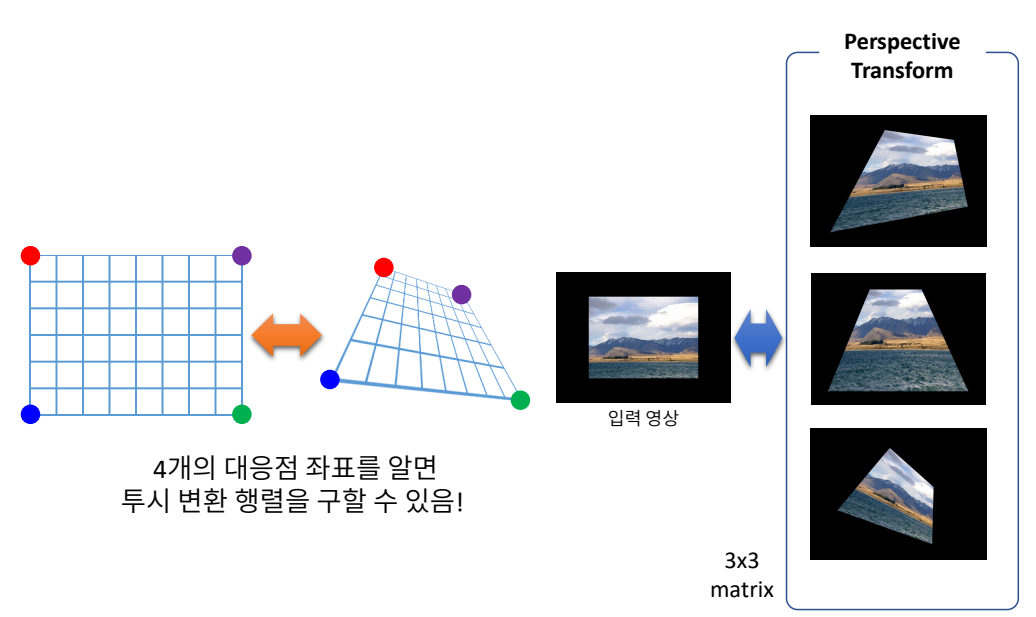

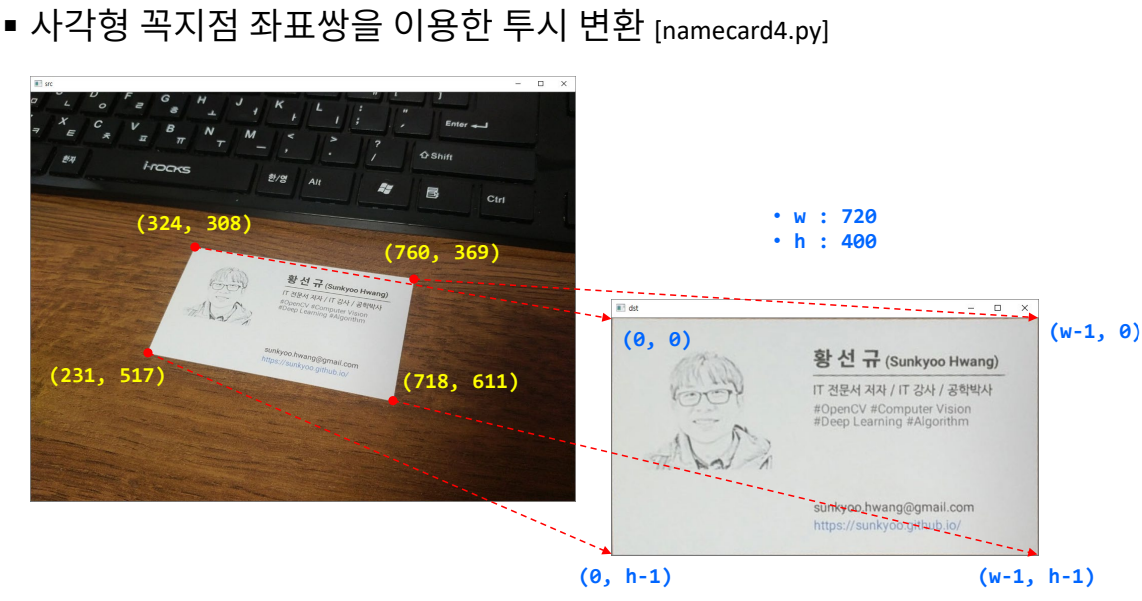
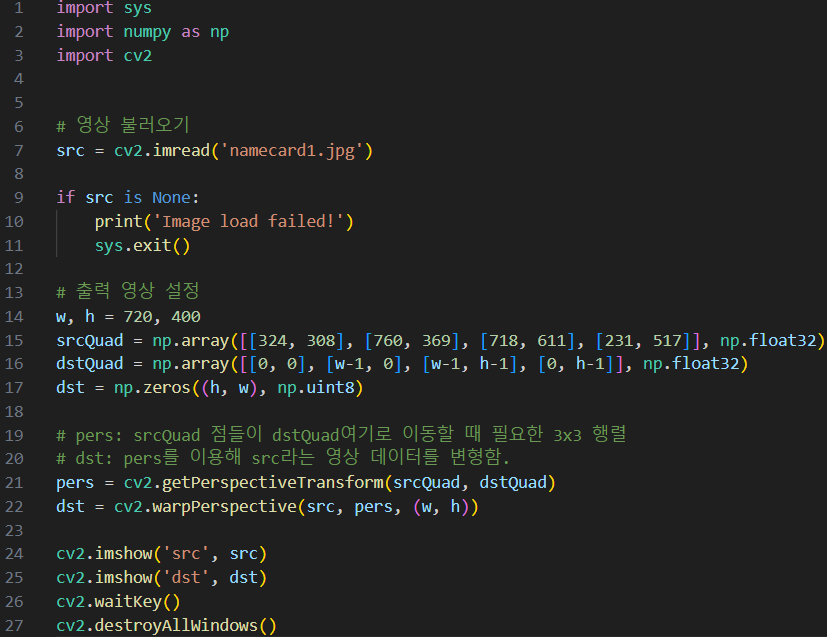
명함 똑바로 펴기(수동)
명함의 비율이 9:5여서 w:720, h:400으로 설정함.
명함 똑바로 펴기(자동)
- 앞에서 4개의 점으로 근사화 시켰기 때문에 approx.shape()의 결과가 4가 나오는 거고, (x,y) 좌표이므로 2이고 C++을 파이썬에서 사용하도록 코드변환한 거여서 의미없는 1이 사이에 껴있는거다.
- cv2.getPerepectiveTransform() 함수가 float32 타입으로 받음.

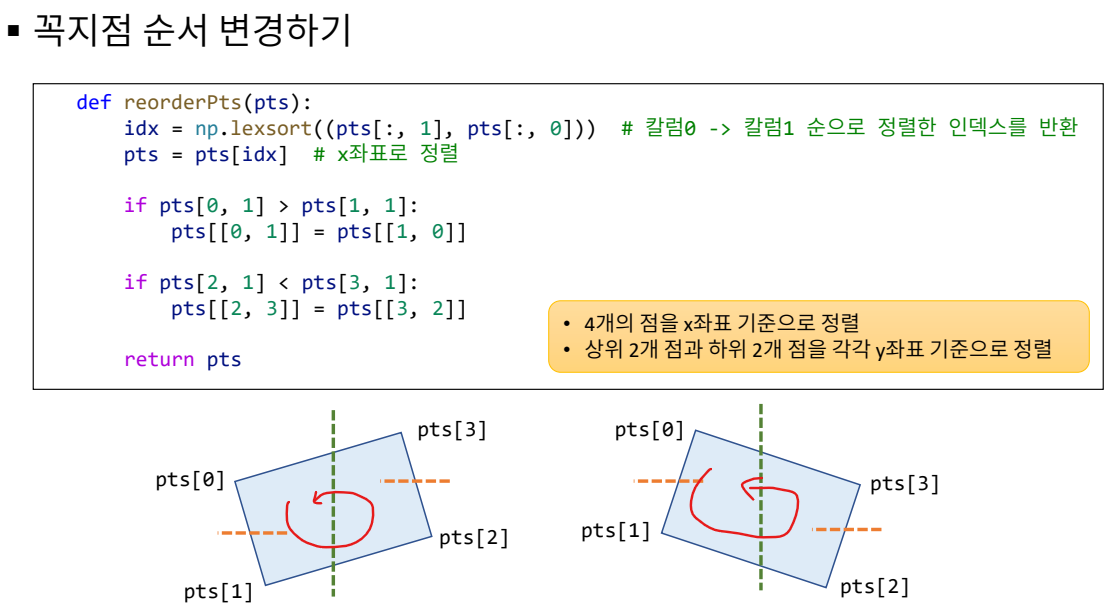
x좌표 기준으로 정렬한 후, y좌표에 따라 좌표의 순서를 조정하는 작업- pts는 네 개의 점으로 구성된 배열. 배열의 형태는 (4, 2)이고 각 점은 (x, y)로 구성.
- pts[:, 1]은 y 좌표, pts[:, 0]은 x 좌표를 의미
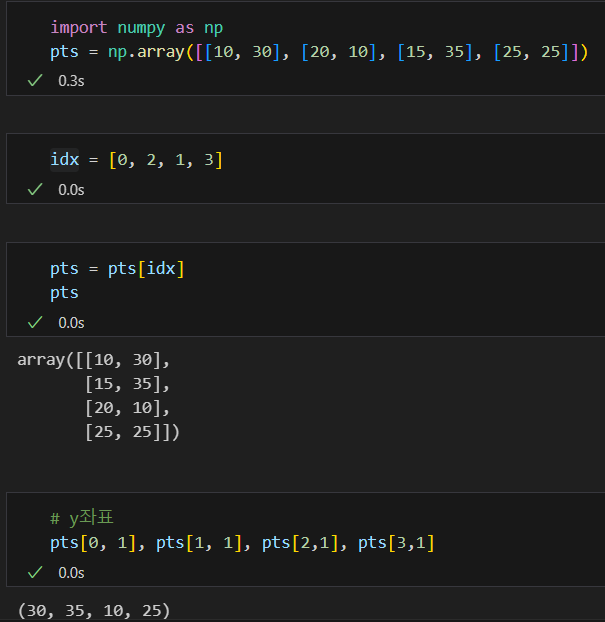
np.lexsort()는 x값을 우선 정렬한 후, y값을 두 번째 기준으로 정렬함. idx는 [0, 2, 1, 3] 이런 형식으로 결과가 출력됨.- 즉 pts = pts[idx]는 배열을 x좌표 기준으로 정렬하는 것임.
- if문 설명
첫 번째 점의 y값이 두 번째 점의 y값보다 크면(즉, 아래쪽에 있다면), 두 점의 순서를 바꾼다.
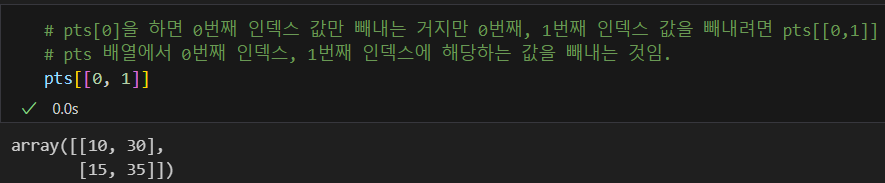
pts[[0, 1]] = pts[[1, 0]]는 인덱스 교환을 의미한다. y값이 작은 원소를 0번째 인덱스에 배치한다는 의미.- 결과적으로 pts의 인덱스에 배치된 원소를 보면 왼쪽 상단에서 부터 반시계 방향으로 좌표가 배치된 상태가 됨.
참고) 이해를 위해 중요!
실행 코드