1. value_count
데이터프레임 특정 조건에 해당하는 개수 세기
ex) df[df['brand'] == 스타벅스].value_count()
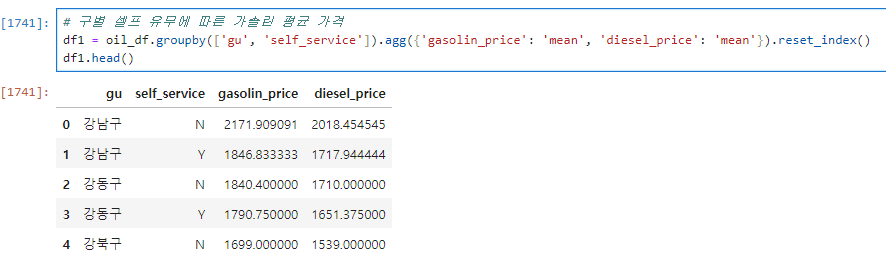
2. groupby()
- reset_index(name='')을 통해 계산된 수를 해당 컬럼에 넣어줌.
df.groupby(['a', 'b'])['아무컬럼 or 원하는 컬럼'].count().reset_index(name='shop_count')두개 컬럼의 평균값을 함께 구하기 위해 agg() 함수 사용
3. 정규표현식 패턴
- 정규 표현식 re.sub()
- re 모듈 사용(파이썬)
- re.sub(pattern, replace, text)
: text 중 pattern에 해당하는 부분을 replace로 대체한다.
정규 표현식에서 .는 임의의 한 문자를 의미하므로, 문자열에서 마침표 .를 정확히 매치하려면 이를 이스케이프(\.) 해야 합니다.
ex) 문자 마지막에 마침표로 끝나는 것을 찾아서 지운다
두개 다 동일한 표현임.ingredients_df.replace(to_replace=r'\.$', value='', regex=True) # .$ : 마침표로 종결 ingredients_df.replace(to_replace=r'[.]$', value='', regex=True)
'\' 는 특별한 메타 문자를 사용할때 사용하므로 문자가 정해져 있다면 사용할 필요가 없다.
ex) ingredients_df.replace(to_replace=r'\. May Contain.*', value='', regex=True) # 앞에 공백 포함여기서 *는 뒤에 문자가 있을 수도 있고 없을수도 있지만 +를 사용하는 경우 반드시 뒤에 문자가 와야한다. 메타문자인 \s+ 와 사용 방법이 조금은 다르다.
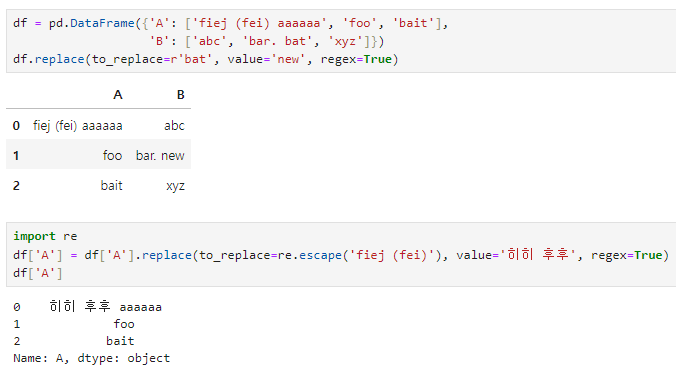
중요!!!!!
정규식에서 괄호는 그룹을 정의하기 위해서 사용됨.
그렇기에 괄호가 포함된 문자를 변경하려면 re.escape() 함수를 사용해야함.
strip()
: 문자열 앞뒤에 있는 모든 공백을 제거
.split()
판다스 Series 속성에서 문자열 객체를 사용할 때는 시리즈.str.split() 형태를 사용한다.
데이터프레임에서 or 형태로 조건 찾기
condition = (ingredients_df['표준 영문명'] == 'a') | (ingredients_df['구영문명'] == 'a')
-> df[condition]
만약 데이터프레임이 비어있지 않다면? 조건식
if not result.empty:
isin
데이터프레임에서 특정 열의 값이 지정된 값의 목록중 하나와 일치하는 경우 해당 행을 필터링함.
ex)
만약 sorted_5code_list = [3, 16, 39, 45, 101] 일때
성분코드가 해당 리스트에 있는 숫자와 동일한 행만 추출
ingredients_df[ingredients_df['성분코드'].isin(sorted_5code_list)]
