str.contains()
- 문자열 열에서 특정 패턴이 포함되는지를 확인할 때 사용된다.
- str accessor는 시리즈의 각 요소가 문자열인 경우에 문자열 메서드를 호출할 수 있게 해준다.
isin():
- 주로 값이 목록에 포함되는지를 확인할 때 사용된다.
- 예를 들어, 특정 열의 값이 [a, b, c] 목록에 있는지를 확인한다.
- 문자열 패턴을 검색하는 데는 적합하지 않다.
ex) ~: 부정 연산자
df_target[~df_target['시설명'].str.contains('휴관')]
duplicated()
중복된 데이터 True로 반환
ex) df.duplicated(subset='컬럼명')
.sort_index()
index 순으로 재 정렬
.join() 리스트를 문자열로 합치기
ex)
' '.join(row['소재지도로명주소'].split()[2:])
문자열 앞, 뒤 공백제거 strip()
ex)
#str을 사용하면 각 원소에 대해서 strip()을 적용함.df_target_temp['소재지도로명주소'] = df_target_temp['소재지도로명주소'].str.strip()
리스트를 하나의 문자열로 합침. join()
ex)
detail = [] for idx, row in df_target_temp.iterrows(): detail.append(' '.join(row['소재지도로명주소'].split()[2:])) # 구분자를 공백으로 해서 리스트를 문자열로 합침
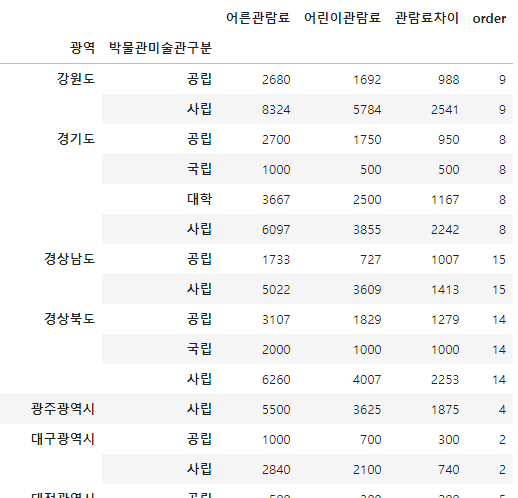
멀티인덱스 맵핑
피벗테이블을 활용해 멀티인덱스 상태로 만들었을 경우 해당 인덱스를 바로 맵핑할 수 없다.
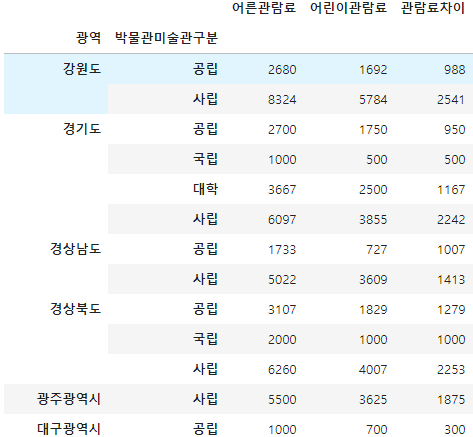
이 경우 get_level_values() 함수를 사용해 특정레벨의 인덱스 값을 가져와 매핑할 수 있다.
딕셔너리 형태로 되어있는 province_dict의 밸류 값을 '광역' 인덱스에 맞춰 맵핑하려면 아래와 같이 작성하면된다.
df_result['order'] = df_result.index.get_level_values('광역').map(province_dict)