LangChain Agent의 동작 원리와 사고방식 분석
본 게시글은 LangChain에서 제공하는 Agent 소스코드를 LLM을 통해 분석한 내용입니다.
LangChain의 Agent 모듈 코드를 분석하면서 AI가 어떻게 사고하고 의사결정을 하는지 살펴보겠습니다. Agent는 자율적으로 행동할 수 있는 AI 시스템으로, 마치 사람처럼 도구를 선택하고 사용하는 방식으로 작동합니다.
Agent의 핵심 구성요소
먼저 Agent 시스템의 주요 구성요소를 이해해야 합니다:
Agent 시스템은 결국 생각하는 두뇌(Agent), 사용하는 도구(Tools), 그리고 이들을 조율하는 관리자(AgentExecutor)로 구성된다. 마치 인간의 사고와 행동 체계와 유사하지 않은가?
Agent의 사고 과정 (Thought-Action-Observation 루프)
Agent는 다음과 같은 루프로 작동합니다:
- 사고(Thought): Agent가 문제를 분석하고 다음에 취할 행동을 결정
- 행동(Action): 선택한 도구를 사용하여 행동 실행
- 관찰(Observation): 행동 결과를 관찰하고 다음 판단의 입력으로 사용
- 이 과정을 반복하며 최종 답변에 도달할 때까지 진행
흥미롭게도 이 루프는 인간의 문제 해결 과정과 놀랍도록 유사하다. 우리도 생각하고, 행동하고, 결과를 관찰한 후 다시 생각하지 않는가? 이것이 AI가 인간의 사고 과정을 모방하는 방식이다.
Return Type의 중요성
Agent의 핵심은 그 Return Type에 있습니다. 이는 단순한 반환 값이 아니라 Agent의 의사결정 자체를 나타내기 때문입니다.
def plan(
self,
intermediate_steps: List[Tuple[AgentAction, str]],
callbacks: Callbacks = None,
**kwargs: Any,
) -> Union[AgentAction, AgentFinish]:
"""주어진 입력을 기반으로 다음에 할 일을 결정"""Agent가 반환할 수 있는 두 가지 핵심 타입:
- AgentAction: "나는 더 정보가 필요해, 이 도구를 사용할게"
- AgentFinish: "충분한 정보를 얻었어, 이것이 최종 답변이야"
Return Type은 단순한 데이터 구조가 아니라 Agent의 의사결정 프로세스 자체다. AgentAction은 "아직 더 알아볼 게 있어"라는 의미이고, AgentFinish는 "이제 결론을 내릴 준비가 됐어"라는 의미다. 이것이 Agent에게 자율성을 부여하는 핵심 메커니즘이다!
주요 컴포넌트 상세 분석
BaseSingleActionAgent / BaseMultiActionAgent
이 기본 클래스들은 Agent가 구현해야 할 핵심 메서드를 정의합니다:
plan: 중간 단계와 입력을 바탕으로 다음 행동 결정aplan: 비동기 버전의 plan
BaseSingleActionAgent는 한 번에 하나의 행동만 결정할 수 있고, BaseMultiActionAgent는 여러 행동을 동시에 결정할 수 있습니다.
이 두 Agent 타입의 차이는 심오하다. SingleActionAgent는 한 번에 하나의 깊은 생각을 하는 반면, MultiActionAgent는 병렬적으로 여러 가설을 탐색할 수 있다. 이는 인간의 집중적 사고와 발산적 사고의 차이와도 비슷하다.
AgentExecutor
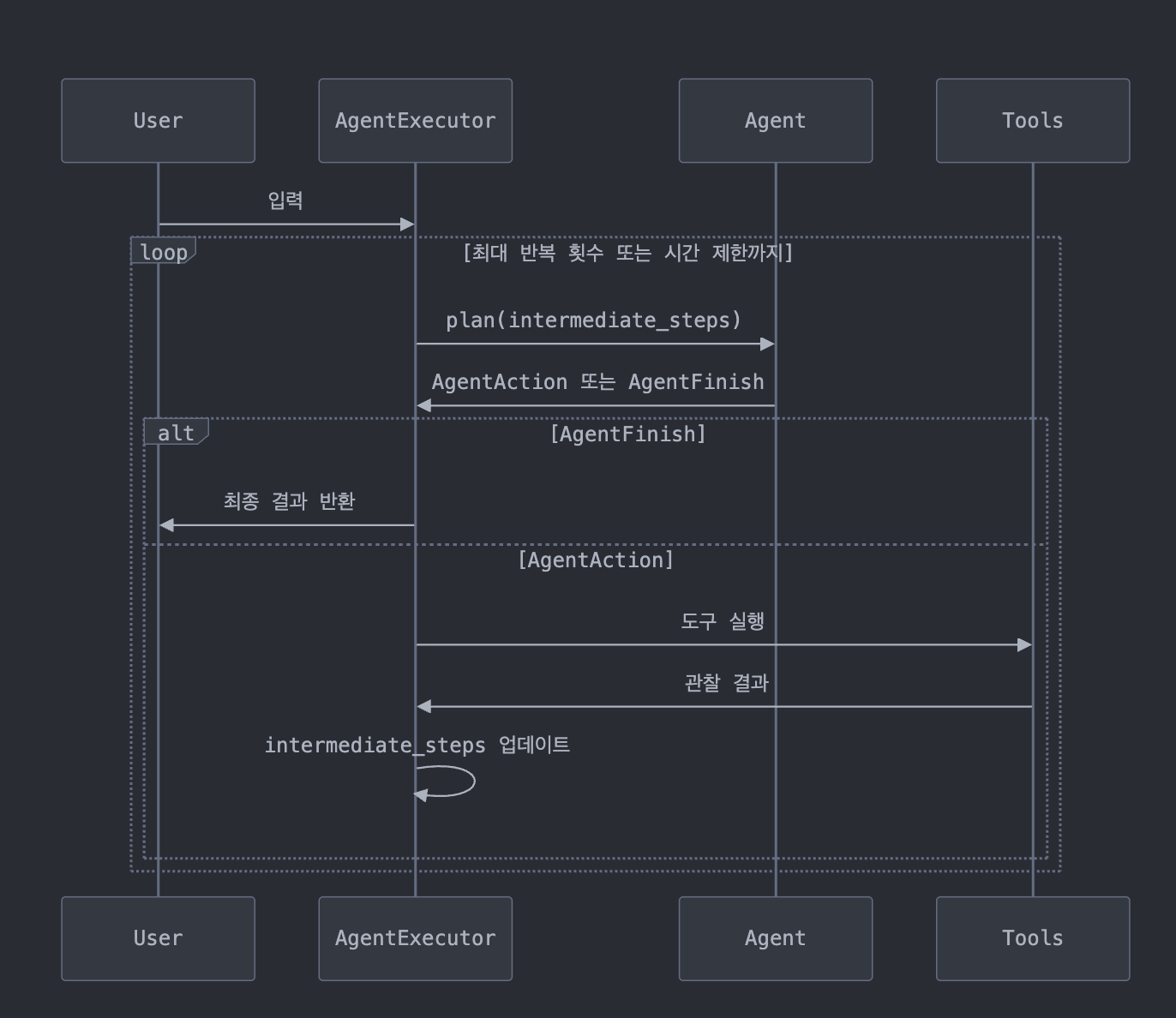
AgentExecutor는 Agent의 실행을 관리하는 핵심 클래스입니다:
def _take_next_step(
self,
name_to_tool_map: Dict[str, BaseTool],
color_mapping: Dict[str, str],
inputs: Dict[str, str],
intermediate_steps: List[Tuple[AgentAction, str]],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Union[AgentFinish, List[Tuple[AgentAction, str]]]:이 메서드는 Agent의 사고-행동-관찰 루프의 한 단계를 실행합니다:
- Agent에게
plan메서드를 호출하여 다음 행동 결정 요청 - 결정된 행동이 최종 답변(AgentFinish)인지 확인
- AgentFinish라면 프로세스 종료, AgentAction이라면 도구 실행 후 결과 관찰
- 결과를
intermediate_steps에 추가하여 다음 단계를 위한 컨텍스트 유지
AgentExecutor는 마치 영화 감독과 같다. 배우(Agent)에게 지시를 내리고, 소품(Tools)을 준비하며, 전체 이야기(프로세스)가 일관되게 진행되도록 관리한다. Return Type에 따라 계속 촬영할지, 컷을 외칠지 결정하는 것이다.
Agent의 사고 과정 (_iter_next_step 메서드)
Agent의 실제 사고 과정은 _iter_next_step 메서드에서 일어납니다:
def _iter_next_step(
self,
name_to_tool_map: Dict[str, BaseTool],
color_mapping: Dict[str, str],
inputs: Dict[str, str],
intermediate_steps: List[Tuple[AgentAction, str]],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Iterator[Union[AgentFinish, AgentAction, AgentStep]]:이 메서드의 핵심 기능:
_action_agent.plan()을 호출하여 LLM에게 다음 행동 결정 요청- 반환된 결과를 분석하여 프로세스 계속 또는 종료 결정
- AgentAction인 경우 해당 도구를 실행하고 AgentStep을 반환
여기서 진정한 마법이 일어난다. LLM의 텍스트 기반 추론이 실제 세계의 행동으로 변환되는 순간이다. text → action → observation → text의 순환이 이루어지면서 Agent는 점점 더 복잡한 문제를 해결해 나간다.
Return Type의 세부 분석
AgentAction과 AgentFinish는 단순한 데이터 구조가 아니라 Agent의 의사결정을 캡슐화한 객체입니다:
-
AgentAction:
tool: 사용할 도구의 이름tool_input: 도구에 전달할 입력log: 로깅을 위한 텍스트 (LLM의 사고 과정)
-
AgentFinish:
return_values: 최종 결과값 (주로 'output' 키를 포함)log: 로깅을 위한 텍스트
-
AgentStep:
action: 실행된 AgentActionobservation: 도구 실행 결과
Return Type은 Agent 시스템의 언어다. AgentAction은 "계속 탐색하겠다"는 신호이고, AgentFinish는 "유레카! 답을 찾았다"는 선언이다. 이 신호 체계가 없다면 Agent는 영원히 헤매거나 너무 일찍 멈출 것이다.
Agent의 구현 방식
LangChain은 Agent를 구현하는 여러 방식을 제공합니다:
- LLMSingleActionAgent: LLM을 기반으로 하는 기본 Agent
- RunnableAgent: Runnable 인터페이스를 사용한 모던한 방식의 Agent
이 두 방식의 주요 차이점은 구현 인터페이스와 유연성입니다. RunnableAgent는 더 현대적인 접근법으로, 다양한 LLM 백엔드와 쉽게 통합될 수 있습니다.
이것은 마치 전통적인 프로그래밍 패러다임과 현대적인 패러다임의 차이와 같다. 오래된 방식이 잘못된 것은 아니지만, 새로운 방식이 더 유연하고 확장 가능한 경우가 많다. Agent 설계에서도 이런 진화가 일어나고 있다.
중간 단계 관리의 중요성
intermediate_steps는 Agent의 메모리 역할을 합니다:
intermediate_steps: List[Tuple[AgentAction, str]]이 구조는:
- 지금까지 Agent가 취한 모든 행동(
AgentAction) - 각 행동의 결과(
str형태의 observation)
를 순서대로 저장합니다.
이 정보는 매 단계마다 LLM에게 제공되어 "여태까지 무엇을 했고, 무엇을 알아냈는지"에 대한 컨텍스트를 제공합니다.
intermediate_steps는 Agent의 작업 메모리다. 인간이 복잡한 문제를 해결할 때 이전 단계를 기억하는 것처럼, Agent도 이 구조를 통해 연속적인 사고를 이어나간다. 이 없이는 Agent는 금붕어처럼 3초마다 모든 것을 잊어버릴 것이다!
프롬프트 구조와 Agent 스크래치패드
Agent 프롬프트에는 반드시 "agent_scratchpad"라는 변수가 포함되어야 합니다:
@model_validator(mode="after")
def validate_prompt(self) -> Self:
"""프롬프트 형식 검증"""
prompt = self.llm_chain.prompt
if "agent_scratchpad" not in prompt.input_variables:
logger.warning(
"`agent_scratchpad` should be a variable in prompt.input_variables."
" Did not find it, so adding it at the end."
)
prompt.input_variables.append("agent_scratchpad")
if isinstance(prompt, PromptTemplate):
prompt.template += "\n{agent_scratchpad}"이 스크래치패드는 intermediate_steps의 정보를 LLM이 이해할 수 있는 형태로 변환한 것입니다:
def _construct_scratchpad(
self, intermediate_steps: List[Tuple[AgentAction, str]]
) -> Union[str, List[BaseMessage]]:
"""Agent가 사고 과정을 이어갈 수 있게 해주는 스크래치패드 구성"""
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
thoughts += f"\n{self.observation_prefix}{observation}\n{self.llm_prefix}"
return thoughts스크래치패드는 Agent의 내적 독백이다. 마치 셜록 홈즈가 사건을 해결하면서 자신의 추론 과정을 중얼거리는 것과 같다. 이 독백이 LLM에게 제공되어 일관된 사고 흐름을 만들어낸다.
코드를 통한 흐름 파악: 소스코드 예시
이제 날씨 도구를 사용하는 구체적인 Agent 코드 예시를 통해 흐름을 살펴보겠습니다.
먼저 날씨 정보를 제공하는 간단한 도구를 @tool 데코레이터를 사용해 정의합니다:
from langchain.tools import tool
from langchain.agents import AgentType, initialize_agent
from langchain_openai import ChatOpenAI
# 날씨 정보를 제공하는 도구 정의
@tool
def get_weather(location: str) -> str:
"""특정 도시의 현재 날씨 정보를 조회합니다.
Args:
location: 날씨를 알고 싶은 도시 이름
Returns:
현재 날씨 정보 문자열
"""
# 실제로는 날씨 API를 호출하겠지만, 예제를 위해 하드코딩된 결과 반환
weather_data = {
"서울": "맑음, 기온 15°C, 습도 45%",
"부산": "흐림, 기온 18°C, 습도 80%",
"제주": "비, 기온 20°C, 습도 95%",
}
return weather_data.get(location, f"{location}의 날씨 정보를 찾을 수 없습니다.")
# LLM 초기화
llm = ChatOpenAI(temperature=0)
# 도구 등록 - @tool 데코레이터로 정의한 함수를 직접 리스트에 추가
tools = [get_weather]
# Agent 초기화
agent = initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# Agent 실행
result = agent.invoke({"input": "서울의 날씨는 어떤가요?"})
print(result["output"])위 코드가 실행되는 상세 과정을 Return Type의 관점에서 분석해보겠습니다:
-
입력: 사용자가 "서울의 날씨는 어떤가요?"라고 질문합니다.
-
AgentExecutor 시작:
- AgentExecutor가
_call메서드를 통해 실행을 시작합니다. - 초기
intermediate_steps는 빈 리스트[]입니다.
- AgentExecutor가
-
Step 1 - 도구 선택 (사고 → 행동):
-
Agent는 다음 코드 라인에서
plan메서드를 호출합니다:next_step_output = self._take_next_step( name_to_tool_map, color_mapping, inputs, intermediate_steps, run_manager=run_manager, ) -
plan메서드 내부에서 LLM이 판단하여 다음과 같은 사고를 합니다:I need to get the current weather information for Seoul. -
이 사고 결과로 AgentAction 객체를 반환합니다:
AgentAction(tool="get_weather", tool_input="서울", log="I need to get the current weather information for Seoul.")
-
-
도구 실행 및 관찰:
-
AgentExecutor가 지정된 도구를 실행합니다:
observation = tool.run( agent_action.tool_input, verbose=self.verbose, color=color, callbacks=run_manager.get_child() if run_manager else None, **tool_run_kwargs, ) -
get_weather("서울")호출 결과로 다음 문자열이 반환됩니다:"맑음, 기온 15°C, 습도 45%" -
이 관찰 결과가
intermediate_steps에 추가됩니다:intermediate_steps = [(AgentAction(...), "맑음, 기온 15°C, 습도 45%")]
-
-
Step 2 - 최종 판단 (관찰 → 최종 답변):
- 업데이트된
intermediate_steps와 함께 다시 Agent의plan메서드가 호출됩니다. - LLM은 이전 단계의 행동과 관찰 결과를 포함한 컨텍스트를 받습니다:
Action: get_weather Action Input: 서울 Observation: 맑음, 기온 15°C, 습도 45% - 이제 LLM은 충분한 정보를 얻었다고 판단하고 AgentFinish 객체를 반환할 것입니다.:
```python AgentFinish( return_values={"output": "서울의 날씨는 현재 맑고, 기온은 15°C, 습도는 45%입니다."}, log="Based on the weather information I received, I can provide an answer." ) ```그런데 여기서.. log가 진짜로 어떻게 나오는지를 잘 파악 및 활용한다면, Agent제어에 더 도움을 줄 것같음.
- 업데이트된
-
프로세스 종료:
-
AgentExecutor는 AgentFinish를 감지하고 최종 결과를 반환합니다:
return self._return( next_step_output, intermediate_steps, run_manager=run_manager ) -
사용자에게 최종 답변이 전달됩니다:
"서울의 날씨는 현재 맑고, 기온은 15°C, 습도는 45%입니다."
-
실제 Agent 실행 시 내부적으로 다음과 같은 출력이 생성됩니다:
> 사용자 입력: "서울의 날씨는 어떤가요?"
I need to get the current weather information for Seoul.
Action: get_weather
Action Input: 서울
Observation: 맑음, 기온 15°C, 습도 45%
Based on the weather information I received, I can provide an answer.
> 최종 응답: 서울의 날씨는 현재 맑고, 기온은 15°C, 습도는 45%입니다.이 과정에서 Return Type이 마법처럼 작동한다. AgentAction은 LLM에게 "도구를 사용해 더 알아봐야 해"라는 신호를 보내고, AgentFinish는 "이제 모든 퍼즐 조각을 갖추었으니 답변을 할 수 있어"라는 신호를 보낸다. 이것이 바로 Agent가 사람처럼 판단하고 행동하는 비밀이다.
만약 다른 질문인 "제주도는 지금 날씨가 어때요?"를 입력하면, Agent는 동일한 사고 패턴을 따르지만 다른 도구 입력과 관찰 결과를 생성합니다:
Action: get_weather
Action Input: 제주
Observation: 비, 기온 20°C, 습도 95%
> 최종 응답: 제주도는 현재 비가 내리고 있으며, 기온은 20°C, 습도는 95%입니다.이렇게 Agent는 매번 다른 입력에 대해 동일한 사고 루프를 적용하면서 필요한 도구를 선택하고 결과를 관찰한 후 최종 판단을 내립니다. Return Type(AgentAction 또는 AgentFinish)을 통해 이 과정이 제어되며, 이것이 바로 Agent가 자율적으로 사고하고 행동하는 핵심 메커니즘입니다.
이 예제는 `@tool` 데코레이터만 사용해 도구를 정의하고, 그 함수를 직접 `tools` 리스트에 추가하는 방식입니다. 이렇게 하면 코드가 더 간결해지고, `Tool.from_function()` 같은 추가 변환 과정이 필요 없습니다. `@tool` 데코레이터가 함수를 자동으로 LangChain 도구 형식으로 변환해 주기 때문입니다.
## 결론
LangChain의 Agent 시스템은 인간의 사고 과정을 모방한 복잡한 구조를 가지고 있습니다. 사고-행동-관찰의 루프와 명확한 Return Type을 통해 Agent는 스스로 의사결정을 내리고 도구를 사용하여 문제를 해결합니다.
Return Type은 이 시스템의 핵심으로, Agent가 계속해서 탐색할지(`AgentAction`) 아니면 최종 결론을 내릴지(`AgentFinish`)를 결정합니다. 이 메커니즘이 Agent에게 자율성을 부여하고 복잡한 작업을 순차적으로 해결할 수 있게 만듭니다.
> Agent 시스템은 단순한 코드 이상의 의미를 가진다. 이는 인간의 사고 프로세스를 알고리즘화한 것으로, LLM의 언어 능력과 도구 사용 능력을 결합하여 목적 지향적인 지능을 만들어낸다. 가장 흥미로운 점은 Return Type을 통해 '생각의 흐름'을 제어한다는 것이다. 이것이 바로 LangChain Agent의 사고 방식의 핵심이다.