메세지큐에 Rate Limiter를 곁들인 요청 처리량 제어 프로세스 구현기

최근에 서비스를 하나 출시했습니다. 이름은 블링크라고 하고 AI기반 아카이빙 앱입니다.
꽤나 맛집이니, 한번씩 들러 주시면 좋겠습니다. 링크는 글 아래 첨부할게요🙂
“줄서는 맛집 블링크가 오픈을 했습니다”
목표는 맛있는 음식을 많은 사람들에게 제공을 하는 것입니다.
하지만 맛있는 음식을 제공하기 위한 재료는 값이 비쌌어요.
거덜(?) 날 수 없었던 사장은 감당할 수 있을 만큼만 손님을 받을 수 있는 웨이팅 시스템을 도입하기로 했어요.
진정한 맛집은 손님을 빈손으로 돌려보내지 않아요. 웨이팅을 등록한 손님들에겐 시간이 걸릴지언정 빠짐 없이 메뉴를 제공합니다.
네, 이 글은 블링크가 어떻게 웨이팅을 등록한 손님들의 요청을 누락 없이 대응하는 것에 대한 이야기입니다.
AI 사용료를 통제하고 싶다
블링크는 기본적으로 AI를 사용하는 서비스입니다. AI를 활용하여 유저들이 편하게 컨텐츠 링크를 아카이빙할 수 있도록 자동으로 내용을 요약/분류 하는 기능을 제공해요. 저희는 이러한 기능을 구현하기 위해 생성형 AI를 사용하기로 하였습니다. 이렇게 결정한 이유는 이미 구축된 모델을 사용하여 앱의 시장성을 빠르게 확인하기 위함이었어요.
하지만 생성형 AI에도 단점이 있었죠. 빠른 구축이 가능하다는 장점의 이면에 요청당 비용이 발생한다는 단점이 존재하였습니다. 저희는 사이드 프로젝트이기 때문에 비용이 충분치 못했고, 비용을 통제할 방법이 필요하였습니다.
타 서비스의 해결책
AI는 비용이 값비싼 도구에 해당합니다. 비용으로 고민이 되는 것은 비단 저희뿐만이 아닐것 같았어요. 그래서 타 서비스에서는 어떻게 대응하고 있는지를 확인해보았습니다.
Chat GPT
chat GPT는 AI를 활용한 대표적인 사례이죠.
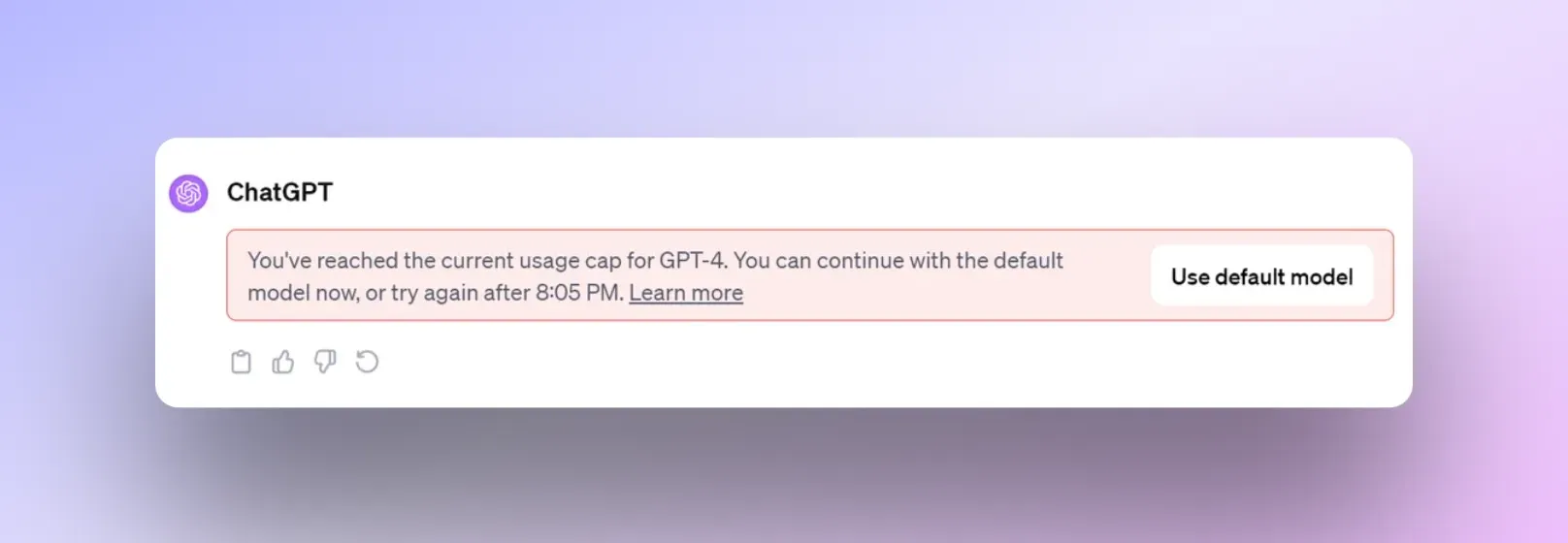
자체적으로 개발한 AI인데도 불구하고, 어느정도 사용하게 되면 사용에 제한이 걸리도록 구현이 되어 있습니다(무료 계정 기준).
GPU 소모가 많다보니, 자사 리소스임에도 불구하고 제한량을 걸어둔 것으로 보입니다.
특이점으로는, 재 사용 가능 시각을 설정함으로써 사용량을 제어하는 모습을 보인다는 겁니다.
원티드
원티드 서비스에서는 이력서를 AI가 분석해주는 서비스를 제공합니다.
원티드도 생성형 AI의 API를 활용하여 서비스를 제공한다고 되어있더군요. 그래서 그런지 API quota를 고려하는 듯한 플로우를 보여줍니다.
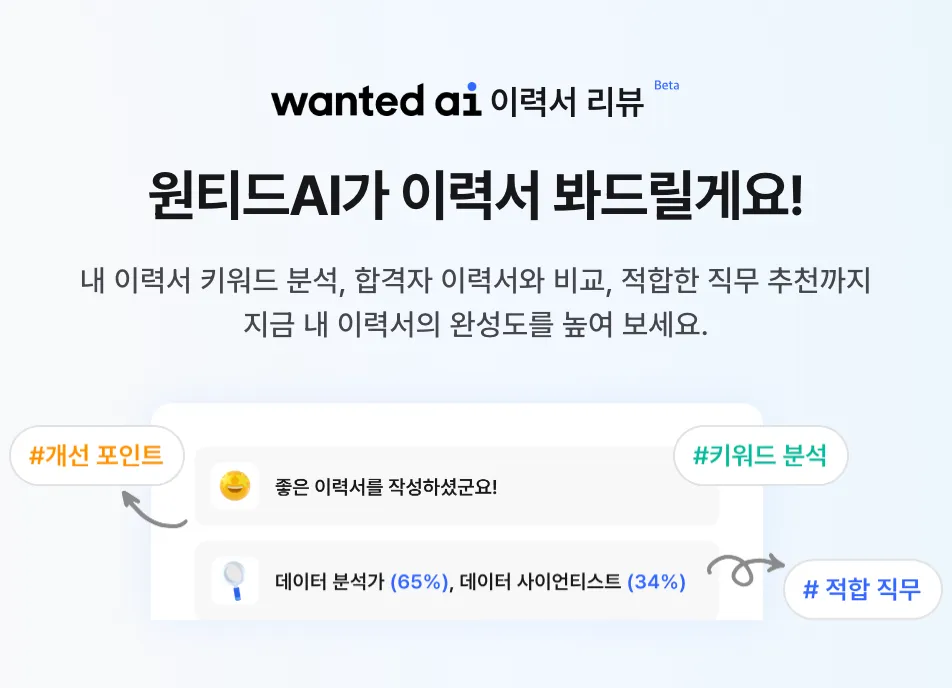
이력서를 작성하고, AI 이력서 리뷰를 신청하면 아래와 같은 화면이 노출되며 결과가 도착하면 알림을 보내준다고 알려줍니다.
내부적으로 비동기 처리한 후에 분석이 완료되면 알림으로 피드백을 주는 것을 보이는데, 최대 24시간까지 걸린다는 것으로 보아서는 메세지큐에 저장한 후 AI 사용량 제한을 설정하여 가능한 수 만큼만 메세지큐에서 fetch하여 동시처리하게 하는 것으로 보입니다.
이렇게 하면 분석에 소요되는 시간을 유저가 대기하지 않아도 되고, 최대 동시 처리 횟수를 설정함으로써 최대 AI 사용량을 원하는대로 제어할 수 있다는 장점이 있겠네요.


AI 서비스에 공통적으로 보이는 것은 사용량에 제한을 둔다는 것이었어요. 역시 다들 비용 과다 청구에 대한 대비책을 세워두었네요. 동일하게 AI를 사용하는 블링크도 대비책이 필요하다고 생각했어요.
결과적으로는, 원티드의 형태를 차용하기로 하였습니다. API를 통해 AI를 활용한다는 공통점 그리고 텍스트 분석과 분류/요약이 절차상 유사하다는 점을 고려하여 결정하였고, 위 구조를 어떤식으로 재현할 수 있을지를 설계하기 시작하였습니다.
어떤 규칙으로 손님을 받을 것인가?
기본적으로 선착순이 제일 합리적인 규칙일 것 같습니다. 최대 동시 처리량을 정해두고 그보다 초과되는 요청은 제한을 하면 좋을것 같습니다.
웨이팅 맛집으로 앱을 비유했으니, 최대 수 만큼만 요청을 받는 것은 워크인 손님을 받는 것으로 비유하면 될까요?ㅎ
그럼 이제 고민, 식당의 좌석 수 보다 초과된 워크인 손님들은 어떻게 처리를 해야할까요?
Rate Limit: 요청량 제한 알고리즘
위 문제를 해결하기 위해 2가지 알고리즘을 찾아보았습니다.
바로 누출 버킷 알고리즘과 토큰 버킷 알고리즘인데요. 둘 다 초과 요청을 처리하기 위해 고안된 알고리즘이기 때문에 두 알고리즘을 기반으로 구조를 설계해보고자 하였습니다.
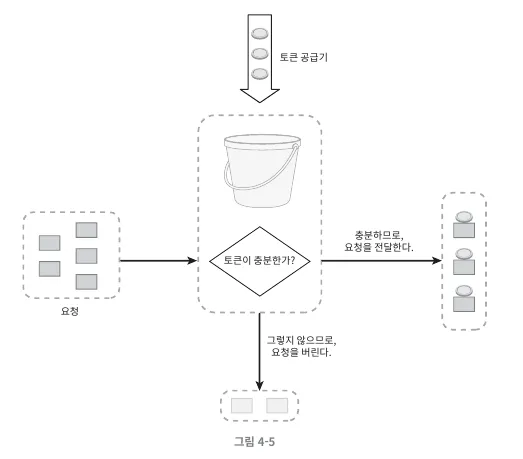
토큰 버킷 알고리즘
토큰 버킷 알고리즘은 일정한 속도로 토큰이 버킷에 추가되며, 작업이 수행되기 위해서는 버킷에서 토큰을 소비하도록 함으로써 요청량을 제한하는 방식입니다. 즉, 토큰이 충분할 때만 요청이나 작업을 처리해요.
토큰이 없을 때에는 요청을 하면 반려가 됩니다.
식당으로 따지면, 테이크아웃 전문점에서 일정한 속도로 최대 N개까지 음식을 내고, 손님들이 순서대로 사가는 알고리즘이라고 할 수 있겠네요. 음식이 없는 경우의 손님은 돌려보내는 형태를 가지고 있어요.
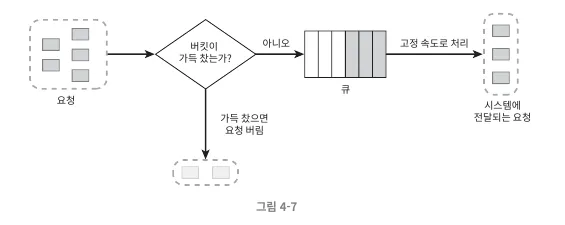
누출 버킷 알고리즘
누출 버킷 알고리즘은 고정된 속도로 요청을 처리합니다. 고정된 사이즈의 큐에 요청을 담아두고 큐가 가득 차면 요청을 반려하는 알고리즘입니다.
이 케이스는 일정한 속도로 음식이 나오는 테이크아웃 전문점에서 최대 N명의 사람까지만 줄을 세우고, N+1명 부터는 돌려보내는 알고리즘으로 비유할 수 있을것 같아요.
좀 이상하지만? 또 길거리에 너무 긴 줄을 세워두면 민원이 들어올 수 있으니, 대충 최대로 줄 설 수 있는 인원을 정해둔거라고 합니다. 맛집의 비애죠(?)
두 알고리즘 중 하나를 선택해서 그대로 구현을 하고 싶었지만, 저희 서비스의 신뢰도를 위해 요청을 버려지는 상황을 만들 수는 없었습니다. 공교롭게도 두 알고리즘 다 수용량을 벗어나는 요청을 그대로 유실시켜버리더라구요.
그래서 두 알고리즘을 잘 혼합하여, 유실 없이도 대기열을 제한된 분당 처리량으로 처리 할 수 있는 알고리즘으로 개량해보기로 하였습니다.
그 결과,
⭐️누출 버킷 알고리즘의 큐 사용에서 착안하여 메세지큐에 요청을 담아두고,
메세지큐에 담긴 요청들을 토큰 버킷 알고리즘을 통해 fetch하게 구성함으로써 요청의 유실 없이 대기열을 소비할 수 있도록 개량⭐️ 할 수 있었습니다!
그렇게 탄생한 구조
설계한 구조를 구조도로 정리해보자면 아래와 같습니다.
1 - 클라이언트가 API 서버에 분석/요약할 링크를 요청으로 보낸다.
2, 3 - API 서버는 메세지큐에 담고 클라이언트에게 바로 응답을 한다.
4, 5, 6 - 잔여토큰 > 0 일 경우 Worker서버에서 메세지를 fetch하여 분석/요약을 처리한다.
7 - 클라이언트에 푸시를 보내 처리가 완료됨을 알린다.
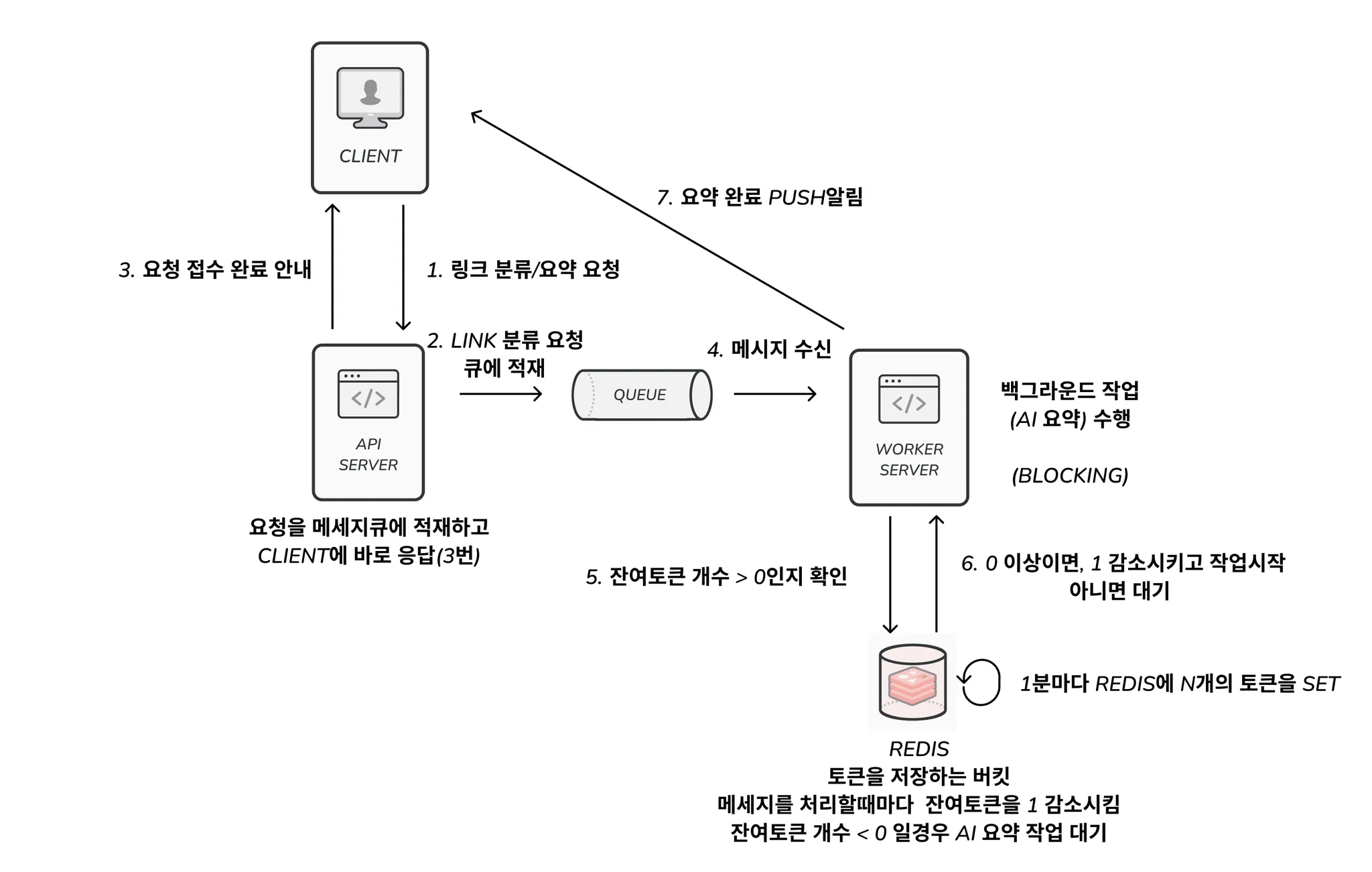
API 요청에 대해서는 메세지큐에 담기만 하고 유저에게 빠른 응답을 줌으로써 유저가 요청을 기다리지 않도록 하고, 대신 요약이 완료되면 푸시를 보내 유저가 확인할 수 있도록 설계하였습니다.
모든 요약 요청은 메세지큐에 담아 유실되지 않도록 하였고, 토큰 버킷 알고리즘에 따라 메세지를 fetch함으로써 요청 누락을 방지하면서도 요청량에는 제한을 둔 구조를 완성할 수 있었습니다.
레시피
그럼 이제 이 구조를 어떻게 구현하였는지도 공유를 해보겠습니다.
일단 저는 메세지큐로는 SQS, 토큰을 담을 버킷으로는 Redis(elasticache)를 사용했어요. 그리고 AWS의 Elastic Beanstalk Worker를 사용하여 주기적으로 Redis에 N개의 토큰을 SET하도록 하였습니다.
SQS는 메세지의 개수와 관계없이 큐의 사이즈가 무제한으로 확장되며, 완전관리형으로 제공되어 빠르게 사용할 수 있고, 서버 자체를 AWS로 구성한 만큼 SQS와의 빠른 통합도 가능했기 때문에 선택하였습니다. 비교적 저렴한 가격은 덤이었고, 타 메세지큐 대비 낮은 TPS도(300 TPS) 예상 사용량 대비 충분할 것으로 판단하였습니다.
토큰의 경우 요청당 하나가 정확하게 소비되어야하기 때문에 동시성이 중요한 이슈라고 생각하였습니다. 그래서 빠른 응답속도임에도 동시성 이슈를 방지할 수 있는 Redis를 사용하기로 하였습니다. Redis는 Lua Script를 활용해 동시성 문제를 해결할 수도 있고, atomic operation인 incrby 명령어를 활용하여 동시성 이슈를 피해 토큰을 감소시키는 것도 용이하기 때문에 Redis를 선택하였습니다.
Elastic Beanstalk Worker 같은 경우에는 cron을 설정해두면 자체 메세지큐를 활용하여 다중 서버 환경일때에도 cron 로직이 단 한번 동작시키는 것을 보장되기 때문에 안정성을 높게 평가하여 선택하였습니다.
sqs 설정
일단 SQS Config를 만들어줍니다.
@SqsListner를 사용하여 message를 가져올 예정이기 때문에 아래와 같이 설정을 하였습니다. 이 데코레이터를 사용해서 가져오는 경우 연동된 함수가 예외없이 수행되면 sqs에서 message를 자동으로 삭제합니다.
저는 메세지가 삭제되는 시점을 제가 컨트롤하고 싶어 acknowledgementMode를 MANUAL로 설정하였습니다. 이렇게 설정을 하면 acknowledgement.acknowledge() 를 함수에서 호출해주어야 정상적으로 메세지가 삭제됩니다.
@Configuration
class AwsSQSConfig(
@Value("\${spring.cloud.aws.credentials.access-key}")
private val awsAccessKey: String,
@Value("\${spring.cloud.aws.credentials.secret-key}")
private val awsSecretKey: String,
@Value("\${spring.cloud.aws.region.static}")
private val region: String,
) {
/**
* AWS SQS 클라이언트
*/
@Bean
fun sqsAsyncClient(): SqsAsyncClient {
return SqsAsyncClient.builder()
.credentialsProvider {
object : AwsCredentials {
override fun accessKeyId(): String {
return awsAccessKey
}
override fun secretAccessKey(): String {
return awsSecretKey
}
}
}
.region(Region.of(region))
.build()
}
/**
* SysAsyncClient를 사용하여 실제 메세지를 수신하는 역할을 함
* 메세지 수신 서버에만 설정하면 됨
*/
@Bean
fun defaultSqsListenerContainerFactory(sqsAsyncClient: SqsAsyncClient): SqsMessageListenerContainerFactory<Any> {
// 정확한 타입과 별개로 메세지의 json 형식만 일치하면 수신부에서 역직렬화할 수 있도록 messageConverter 설정
val messageConverter = SqsMessagingMessageConverter()
messageConverter.setPayloadTypeMapper { null }
return SqsMessageListenerContainerFactory
.builder<Any>()
// 수동으로 메세지를 삭제하기 위해 AcknowledgementMode.MANUAL로 설정
.configure { opt ->
opt.acknowledgementMode(AcknowledgementMode.MANUAL)
opt.messageConverter(messageConverter)
}
.sqsAsyncClient(sqsAsyncClient)
.build()
}
/**
* 메세지 발송을 위한 SQS 템플릿 설정
* 메세지 발신 서버에만 설정하면 됨
*/
@Bean
fun sqsTemplate(): SqsTemplate {
return SqsTemplate.newTemplate(sqsAsyncClient())
}
}API 서버에서는 아래와 같이 메세지를 적재하는 코드를 작성하여 사용했습니다. message는 json으로 직렬화되며, message를 fetch하는 코드에서는 동일한 형태의 class를 생성하여 역직렬화되도록 해야합니다.
@Component
class FeedSummarizeMessageSenderImpl(
@Value("\${spring.cloud.aws.sqs.summary-request-queue.name}") private val queueName: String,
private val sqsTemplate: SqsTemplate,
): FeedSummarizeMessageSender {
// 메세지를 적재하는 함수
override fun send(message: FeedSummarizeMessage): SendResult<FeedSummarizeMessage> {
return sqsTemplate.send { to ->
to
.queue(queueName)
.payload(message)
}
}
}Worker 서버에서 메세지를 처리하는 부분은 아래와 같습니다. summarizeRequestLimiter.decreaseToken() 를 호출함으로써 로직 처리전 토큰을 하나 감소시키고, 토큰이 남아있었으면 로직을 수행하고, 메세지를 삭제합니다. 토큰이 없었을 경우에는 acknowledgement.acknowledge() 가 호출되지 않기 때문에 메세지가 삭제되지 않고 다시 fetch 될 수 있게 합니다.
sqs는 메세지를 수신할때 바로 큐에서 삭제하는 대신 메세지가 안보이도록 처리합니다. 그리고 acknowledgement.acknowledge() 가 호출이되는 시점에서야 메세지가 삭제됩니다.
acknowledgement.acknowledge() 처리되지 않는 메세지는 visibiliy timeout 이후에 큐에 다시 나타나 재 수신이 가능해집니다.
@Component
class SummaryRequestListenerImpl(
private val feedSummarizerService: FeedSummarizerService,
private val summarizeRequestLimiter: SummarizeRequestLimiter
) : SummaryRequestListener {
@SqsListener("\${spring.cloud.aws.sqs.summary-request-queue.name}")
override fun summarizeFeed(
message: Message<FeedSummarizeMessage>,
@Headers headers: MessageHeaders,
acknowledgement: Acknowledgement
): PromptResponse? {
// TOKEN이 남아있을 때에만 요청을 처리한다.
if (summarizeRequestLimiter.decreaseToken() > 0) {
// TODO 이 메서드에 요약 처리 로직을 추가해야함. 아래 메소드 구현 필요.
val payload = message.payload
feedSummarizerService.summarizeFeed(payload)
// 정상적으로 요청을 처리한 경우에만 메세지큐에서 요청을 삭제한다.
acknowledgement.acknowledge()
}
return null
}
}SummarizeRequestLimiter는 RedisClient를 활용하여 아래와 같이 구현하였습니다. decreaseToken는 decr 메소드를 활용해 redis의 토큰 값을 1감소 시키는 함수입니다.
@Component
class SummarizeRequestLimiterImpl(
private val redisClient: RedisClient
): SummarizeRequestLimiter {
val REFILL_TOKEN_COUNT = 15
override fun decreaseToken(): Long {
val remainCount = this.redisClient.decr(RedisKey.SUMMARIZE_REQUEST_TOKEN_COUNT.name).let { it ?: 0 }
return remainCount
}
override fun refillToken() {
this.redisClient.set(RedisKey.SUMMARIZE_REQUEST_TOKEN_COUNT.name, REFILL_TOKEN_COUNT.toString())
}
}worker 크론으로 토큰 리필
토큰을 다시 채워주는 주기적 작업을 처리하기 위해 Elastic beanstalk worker의 cron 기능을 사용하였습니다. api를 만들어두고, cron.yaml에 cron 규칙을 정의해주면 내부적으로 cron 규칙에 맞게 api 호출하여 주기적 작업이 처리되게 합니다.
저는 아래와 같이 Controller를 구성하고 cron.yaml을 추가하였습니다.
@RestController
@RequestMapping("/feed-summarizer")
class FeedSummarizerControllerImpl(
private val feedSummarizerService: FeedSummarizerService
): FeedSummarizerController {
@PostMapping("/refill-token")
override fun refillToken(): ResponseEntity<Unit> {
this.feedSummarizerService.refillToken()
return ResponseEntity.ok().build()
}
}# cron.yaml
version: 1
cron:
- name: 'refill token'
url: '/feed-summarizer/refill-token'
schedule: '* * * * *'테이스팅
API를 호출하여 정상적으로 요청이 처리되는지 확인해봅시다.
토큰이 존재하는 경우
이렇게 링크를 입력하면
푸시와 함께 아래와 같이 분류 폴더와 키워드, 요약 내용이 저장됩니다.
Redis의 토큰값도 정상적으로 하는 것을 확인할 수 있었습니다. 토큰 최대값을 15로 설정해두었는데, 9까지도 잘 감소하는군요.

토큰이 없는 경우
토큰이 0일 경우에도 실험을 해보겠습니다.

연달아서 3개의 요약 요청을 보내보면,
토큰 값이 -3으로 감소하고

메세지큐에는 3개의 메세지가 남아있는 것을 확인할 수 있습니다. 토큰이 없을 경우 요청이 잘 제한 되는군요!🎉
Result
이제 저희는 AI의 최대 지출 비용을 컨트롤할 수 있는 권한을 얻었습니다.
비용 폭탄의 두려움에서 자유로워졌어요!
아래와 같은 공식으로 N을 조정함으로써 수도꼭지를 잠구고 풀듯 비용을 유연하게 제한할 수 있게되었습니다.
월별 최대 AI 사용량 지출 = 분당 토큰의 개수(N) AI 1회 호출 비용 30
위와 같은 과정을 통해 요청을 유실없이 처리하면서도, 분당 처리량에 제한을 두어 비용효율적·안정적으로 요청을 처리하는 구조를 설계하고 구현할 수 있었습니다.
API에 처리량을 제한하고자 하는 니즈는 꽤나 일반적인것 같습니다. 위와 같은 구조에 비즈니스 로직만 구현하여 추가한다면 다들 어렵지 않게 처리량 제한 구조를 구현하실 수 있을 것이라고 생각합니다.
물론 아직 개선할만한 포인트는 좀 더 있을것 같습니다. 토큰 유무와 관계 없이 메세지큐에서 일단 메세지를 fetch하고 보니 메세지큐의 불필요한 요청이 꽤나 발생하는 것 같습니다. 이 부분은 좀 더 개선할 수 있을지 고민해봐야겠네요.
좀 더 추상화를 해서 인프라와 비즈니스 로직만 추가하면 바로 처리량 제한 로직을 붙일 수 있도록 개선하는 것도 좋은 과제가 될 것 같아요.
개인적으로 만족스러운 점은 문제를 확실히 정의하고 논리적인 사고 과정을 통해 문제를 풀어냈다는 점인것 같습니다.
문제를 정확히 정의한 후 필요한 지식들을 파악하고 새롭게 습득하여 빠르게 원하는 결과를 만들어 냈다는 점에서 개발자로서 한 발짝 성장한 것 같아 뿌듯하네요🙂
이 글이 비슷한 고민을 하고 있는 또 다른 개발자들에게 도움이 되었으면 좋겠습니다.
긴글 읽어주셔서 감사합니다!🤩
가기 전에 스토어 링크 하나만 첨부하고 하겠습니다. 한번씩 사용해보시고 피드백 달아주시면 매우 감사하겠습니다.
