
⚡ DataBase & SQL
👍 이전의 CS 면접 대비를 위한 DB 학습 기록보다 더 깊게 배울 예정이다.
이전의 학습 기록 1
이전의 학습 기록 2
👍 실습에는 mySQL을 활용한다.
📌 DataBase
⭐ 데이터베이스란?
🔷 여러 사람이 공유하고 사용할 목적으로 통합 관리되는 정보의 집합
- 논리적으로 연관된 하나 이상의 자료의 모음으로 그 내용을 고도로 구조화 함으로써 검색과 갱신의 효율화를 꾀한 것
- 몇 개의 자료 파일을 조직적으로 통합하여 자료 항목의 중복을 없애고 자료를 구조화하여 기억시켜 놓은 자료의 집합체
🔷 데이터의 종류
1) 통합된 데이터 (Integrated Data)
- 각자 사용하던 데이터를 모아서 중복을 최소화하고 데이터 불일치를 제거
2) 저장된 데이터 (Stored Data)
- 문서 형태로 보관되는 것이 아니라 저장장치(디스크, 테이프 등 컴퓨터 저장장치)에 저장됨
3) 운영데이터 (Operational Data)
- 조직의 목적을 위해서 사용되는 데이터를 의미
4) 공용데이터 (Shared Data)
- 여러 사람이 각각 다른 목적의 업무를 위해서 공통으로 사용되는 데이터를 의미
⭐ DBMS(Database Management System)
🔷 데이터베이스 관리 프로그램
- 데이터베이스 조작 인터페이스 제공
- 효율적인 데이터 관리 기능제공
- 데이터베이스 구축 기능 제공
- 데이터 복구, 사용자 권한부여, 유지보수 기능제공
⭐ 데이터베이스의 역사
🔷 1960년대 - 데이터 베이스의 등장
- 계층적 모델 : IBM社-Information Management System (IMS)
- 네트워크모델 : Charles Bachman - Integrated Data Store (IDS)
🔷 1970년대 – 관계형 데이터 베이스 등장
- Edgar F. Codd에 의해 관계형 데이터 모델 소개, IBM社 – System R 개발
🔷 1980년대 – 데이터베이스 성장 및 표준화
- 관계형 데이터베이스 모델( Relational Database Model) 의 성장
- ANSI(American National Standard Institute) 에서 SQL 표준 제정
🔷 1990년대 – 객체 지향과 다양한 관계형 모델 제품 등장
- 객체지향 발전에 따른 데이터 처리 방식 다양화
- Oracle, DB2, MS SQL SERVER 등 다양한 제품 등장 및 발전
📌 관계형 데이터베이스(Relational DB)
🔷 테이블(Table) 기반의 Database
🔷 테이블(Table)
- 실제 데이터가 저장되는 곳
- 행과 열의 2차원 구조를 가진 데이터 저장 장소
🔷 데이터를 테이블 단위로 관리
- 하나의
데이터(record)는 여러속성(Attribute)을 가진다. - 데이터 중복을 최소화
- 테이블 간의 관계를 이용하여 필요한 데이터 검색가능
💡 RDB에 대한 더 자세한 설명은 게시글 최상단에 첨부한 이전 게시물 링크로 대체한다.
📌 SQL(Structed Query Language)
🔷 관계형 데이터 베이스에서 데이터 조작과 데이터 정의를 위해 사용하는 언어
- 데이터 조회
- 데이터 삽입, 삭제, 수정
- DB Object 생성 및 변경, 삭제
- DB 사용자 생성 및 삭제, 권한 제어
💡 표준 SQL은 모든 DBMS에서 사용가능하다.
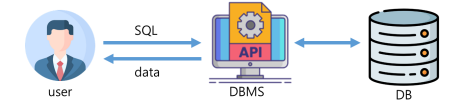
🔷 SQL 특징
- 배우고 사용하기 쉽다
- 대소문자를 구별하지 않는다. (데이터의 대소문자는 구분)
- 절차적인 언어가 아니라 선언적 언어이다.
- DBMS에 종속적이지 않다.
🔷 DML ( Data Manipulation Language) : 데이터 조작 언어
- 데이터베이스에서 데이터를 조작하거나 조회할 때 사용
- 테이블의 레코드를
CRUD(Create, Read, Update, Delete)
| 문장 | 설명 |
|---|---|
| SELECT | 데이터베이스에서 데이터를 조회할 때 사용 |
| INSERT | 테이블에 새 행을 입력할 때 사용 |
| UPDATE | 기존 행을 변경할 때 사용 |
| DELETE | 테이블에서 행을 삭제할 때 사용 |
💡 SELECT가 가장 중요하다!
🔷 DDL ( Data Definition Language) : 데이터 정의 언어
- 데이터 베이스 객체(table, view, user, index 등)의 구조를 정의
| 문장 | 설명 |
|---|---|
| CREATE | 테이블 등 데이터 객체를 생성할 때 사용 |
| ALTER | 테이블 등 데이터 객체를 변경할 때 사용 |
| DROP | 테이블 등 데이터 객체를 삭제할 때 사용 |
| RENAME | 테이블 등 데이터 객체의 이름을 변경할 때 사용 |
🔷 TCL ( Transaction Control Language) : 트랜잭션 제어 언어
- 트랜잭션단위로 실행한 명령문을 적용하거나 취소
COMMIT,ROLLBACK문장이 있다.
💡
COMMIT,ROLLBACK
DML문이 변경한 내용을 관리. 변경사항을 저장하거나 취소할 때 사용한다.
이 때, DML 변경 내용은 트랜잭션 단위로 그룹화 가능하다.
🔷 DCL ( Data Control Language) : 데이터 제어 언어
- Database, Table 접근권한이나 CRUD권한 정의
- 특정 사용자에게 테이블의 검색권한 부여/금지
| 문장 | 설명 |
|---|---|
| GRANT | 데이터베이스 접근권한 부여 |
| REVOKE | 데이터베이스 접근권한 삭제 |
📌 DDL(Data Definition Language)
🔷 데이터베이스 생성
CREATE DATABASE databasename;CREATE DATABASE명령문은 새 데이터 베이스를 생성하는데 사용된다.- 데이터 베이스는 여러 테이블을 포함하고 있다.
- 데이터 베이스 생성시 관리자 권한으로 생성해야 한다.
🔷 데이터베이스 목록 조회
SHOW DATABASES;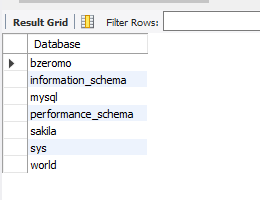
🔷 데이터베이스 수정 및 데이터베이스 문자 집합(Character set) 설정하기
- 데이터 베이스 생성 시 설정 또는 생성 후 수정 가능
- 문자집합은 각 문자가 컴퓨터에 저장될 때 어떠한 ‘코드’ 로 저장되는지 규칙을 지정한 집합이다.
Collation은 특정 문자 집합에 의해 데이터베이스에 저장된 값들을 비교, 검색, 정렬 등의 작업을 수행할 때 사용하는 비교 규칙 집합이다.
-- 주석
-- 기본값 확인
SHOW VARIABLES LIKE 'c%';
-- 사용하는 CHARSET 확인
SHOW CHARACTER SET;
-- 데이터베이스 수정
ALTER DATABASE bzeromodb
-- utf8mb3는 다국어처리 utf8mb4는 이모지까지 가능
DEFAULT CHARACTER SET utf8mb4 collate utf8mb4_general_ci;🔷 데이터베이스 삭제
- 데이터베이스의 모든 테이블을 삭제하고 데이터베이스를 삭제
- 삭제 시,
DROP DATABASE권한 필요 DROP SCHEMA는DROP DATABASE와 동의어IF EXISTS는 데이터베이스가 없을 시 발생할 수 있는 에러를 방지
DROP DATABASE bzeromodb;
DROP DATABASE IF EXISTS bzeromodb;
📌 Data Type (자료형)
🔷 숫자 자료형(Numeric Data Types)
| 데이터유형 | 크기 | (Byte) 정의 |
|---|---|---|
BIT[(M)] | 1 | 비트 값 유형. M은 값 당 비트 수를 나타냄. 1 ~ 64 사이의 값. |
TINYINT[(M)] | 1 | (signed) -128 ~ 127 (unsigned) 0 ~ 255 |
BOOL, BOOLEAN | TINYINT (1)의 동의어. 0은 false, 0이 아닌 값은 true | |
SMALLINT[(M)] | 2 | (signed) -32768 ~ 32767 (unsigned) 0 ~ 65535 |
MEDIUMINT[(M)] | 3 | (signed) -8388608 ~ 8388607 (unsigned) 0 ~ 16777215 |
INT[(M)], INTEGER[(M)] | 4 | (signed) -2147483648 ~ 2147483647 (unsigned) 0 ~ 4294967295 |
BIGINT[(M)] | 8 | (signed) -9223372036854775808 ~ 9223372036854775807 (unsigned) 0 ~ 18446744073709551615 |
🔷 문자 자료형(String Data Types)
| 데이터유형 | 정의 |
|---|---|
CHAR[(M)] | 고정길이를 갖는 문자열을 저장.M은 0 ~255. CHAR(20)인 컬럼에 10글자 저장, 20글자 만큼의 공간을 차지 |
VARCHAR[(M)] | 가변길이를 갖는 문자열을 저장. M은 1 ~65535. VARCHAR(20)인 컬럼에 10글자 저장, 10글자 만큼의 공간을 차지. |
TINYTEXT[(M)] | 최대 255byte |
TEXT[(M)] | 최대 65535byte |
MEDIUMTEXT[(M)] | 최대 16777215byte |
LONGTEXT[(M)] | 최대 4294967295byte |
ENUM('value1','value2',...) | 열거형. 정해진 몇 가지의 값들 중 하나만 저장. 최대 65535개의 개별 값을 가질 수 있고, 내부적으로 정수 값으로 표현된다. |
SET('value1','value2',...) | 집합형. 정해진 몇 가지의 값 들 중 여러 개를 저장. 최대 64개의 요소로 구성 될 수 있고, 내부적으로는 정수 값 이다. |
🔷 날짜 자료형 (Date and Time Data Types)
| 데이터유형 | 크기(Byte) | 정의 |
|---|---|---|
DATE | 3 | YYYY-MM-DD (‘1000-01-01'~'9999-12-31') |
TIME | 3 | HH:MM:SS('-838:59:59' ~ '838:59:59') |
DATETIME | 8 | YYYY-MM-DD HH:MM:SS(‘1000-01-01 00:00:00' ~ '9999-12-31 23:59:59') |
TIMESTAMP[(M)] | 4 | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 (1970-01-01 00:00:00 를 0으로 해서 1초단위로 표기) |
YEAR[(4)] | 1 | 1901 ~2155 |
📌 테이블(Table) 생성하기
🔷 자주 사용하는 Options
| 옵션 | 설명 |
|---|---|
NOT NULL | 해당 열의 값은 항상 존재 해야하고, Null이 될 수 없음. |
DEFAULT | 기본 값 설정 |
AUTO INCREMENT | 새 레코드가 추가 시 값을 자동으로 1 증가 시켜 저장 |
PRIMARY KEY | 테이블에서 행을 고유하게 식별하기 위해 사용. |
🔷 제약 조건 (CONSTRAINT)
- 컬럼에 저장될 데이터의 조건을 설정
- 제약조건에 위배되는 데이터는 저장 불가
- 테이블 생성시 컬럼에 지정하거나, constraint로 지정가능(ALTER 를 이용하여 설정가능)
| 제약사항 | 설명 |
|---|---|
NOT NULL | 각 행은 해당열의 값을 포함해야 하며 null값은 허용 되지 않음 |
UNIQUE | 컬럼에 중복된 값을 저장 할 수 없음 , NULL 값은 허용 |
PRIMARY KEY | 기본키, 컬럼에 중복된 값을 저장 할 수 없고 , NULL 값도 허용하지 않음. 주로 레코드를 구분하기 위한 유일한 값을 지정할 때 사용. |
FOREIGN KEY | 특정 테이블의 PK 컬럼에 저장되어 있는 값만 저장. ‘참조키’, ‘외래키’ 라고 불림. |
NULL | 값 허용, 어떤 컬럼에 어떤 데이터를 참조하는지 반드시 지정 |
DEFAULT | 레코드 입력 시, 해당 열의 값이 입력되지 않으면 넣어줄 값을 지정 |
CHECK | 값의 범위나 종류를 지정. MYSQL 8 버전부터 사용가능. 이전 버전의 경우, 제약조건 설정은 가능하나 적용이 안됨 |
🔷 테이블(Table) 스키마
스키마(Schema): 테이블에 저장될 데이터의 구조와 형식- 테이블(Table) 스키마 확인하기
DESCRIBE또는DESC명령어를 이용하여 생성된 테이블 스키마 확인
ex) 유저의 정보를 저장하기 위한 테이블
CREATE TABLE user (
user_num INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
user_id VARCHAR(20) NOT NULL,
user_name VARCHAR(20) NOT NULL,
user_password VARCHAR(20) NOT NULL,
user_email VARCHAR(30),
signup_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
-- 테이블 정보 확인
DESC user;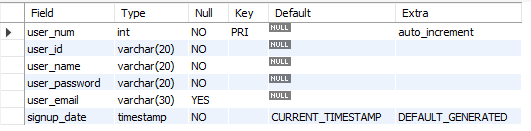
📌 DML
👍 실습에 사용할 DB는 이렇게 생성하였다.
-- 데이터 베이스 생성 및 사용
CREATE DATABASE IF NOT EXISTS bzerodb;
USE bzerodb;
-- 테이블 생성
CREATE TABLE bzerodb_user (
user_num INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
user_id VARCHAR(20) NOT NULL,
user_name VARCHAR(20) NOT NULL,
user_password VARCHAR(20) NOT NULL,
user_email VARCHAR(30),
signup_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
-- 테이블 정보 확인
DESC bzerodb_user;
-- 전체 테이블 데이터 조회
SELECT * FROM bzerodb_user;
🔷 INSERT 문
- 생성시 작성한 모든 컬럼에 입력 값이 주어지면 컬럼이름 생략가능
- 컬럼이름과 입력 값의 순서가 일치하도록 작성
(NULL,DEFAULT,AUTO INCREMENT설정 필드 생략가능)
-- 모든 컬럼 입력
INSERT INTO bzerodb_user
VALUES (1, "bzeromo", "박영규", "12345", "dudrb5260@naver.com", now()); -- now() -> 현재 시각
-- 원하는 컬럼만 입력
INSERT INTO bzerodb_user (user_id, user_name, user_password)
VALUES("kimzeromo", "김영규", "1q2w3e4r!@");
-- 여러행 입력
INSERT INTO bzerodb_user (user_id, user_name, user_password)
VALUES ("leezeromo", "이영규", "0000"),
("jozeromo", "조영규", "1111"),
("5zeromo", "오영규", "2222");
SELECT * FROM bzerodb_user;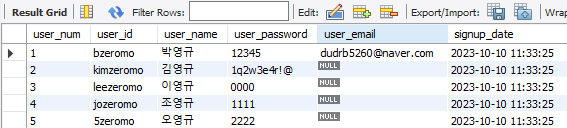
🔷 UPDATE 문
- 기존 레코드를 수정한다.
- WHERE 절을 이용해 하나의 레코드 또는 다수의 레코드를 한 번에 수정할 수 있다.
❗ WHERE 절을 생략하면 테이블의 모든 행이 수정된다.
-- 데이터 수정 조건x(safe mode 해제) Edit -> preferences -> SQLEditor -> 맨 아래 체크박스 해제
UPDATE bzerodb_user
SET user_name = 'anonymous';
-- user_num가 3번인 유저의 비밀번호를 1234로 수정
UPDATE bzerodb_user
SET user_password = '1234'
WHERE user_num = 3;
SELECT * FROM bzerodb_user;
🔷 DELETE 문
- 기존 레코드를 삭제한다.
- WHERE 절을 이용해 하나의 레코드 또는 다수의 레코드를 한 번에 삭제 할 수 있다
-- 삭제
-- user_num가 4인 유저 삭제
DELETE FROM bzerodb_user
WHERE user_num = 4;
SELECT * FROM bzerodb_user;
💡 삭제 후에 새로 유저 행을 추가하여도
Auto-Increment로 설정된user_num은 삭제되었던 번호로 내려가는 것이 아니라 그대로 올라가기만 한다.

📌 SELECT 문
👍
SELECT는 가장 중요한만큼 SSAFY에서 제공한 더 복잡한 데이터베이스를 사용한다. DB에 대한 자세한 내용은 이곳에 공개할 수 없다는 점을 양해바란다.
🔷 SELECT 문
- 테이블에서 레코드를 조회하기 위해 사용
- 조회 시 컬럼이름이나 표현식을 조회할 수 있고
별칭(AS, alias)사용이 가능하다 *는 모든 속성을 조회한다.WHERE조건식을 이용하여 원하는 레코드를 조회할 수 있다.
-- 모든 사원 정보 검색
SELECT * FROM emp;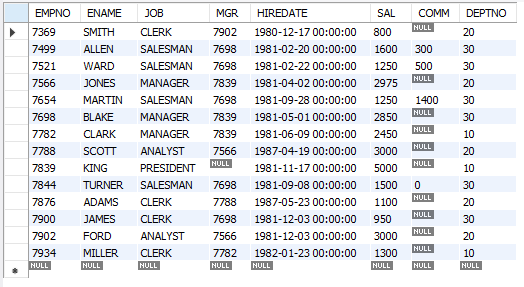
-- 사원이 근무하는 부서번호
SELECT deptno
FROM emp;
-- 사원이 근무하는 부서번호 (중복제거)
-- AS -> Alias(별칭)
SELECT DISTINCT deptno AS "부서번호"
FROM emp;
-- 별명 및 사칙연산
-- as 를 이용하여 조회 시 컬럼이름을 변경할 수 있다. (띄어 쓰기 포함 시 “” 으로 묶어준다)
-- 사원의 이름, 사번, 급여*12 (연봉), 업무 조회
SELECT ename 이름, empno "사번", sal*12 AS 연봉, job AS "업 무"
FROM emp;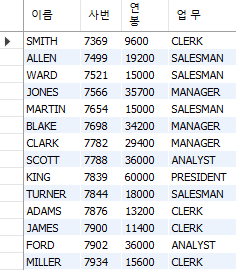
-- 사원의 이름, 사번, 커미션, 급여, 커미션 포함 급여 조회
-- 사칙연산에 null 포함 시 계산이 불가능, IFNULL을 이용해 null일 때 0으로 처리
SELECT ename 이름, empno AS "사번", comm 커미션,
sal AS 급여, sal + comm AS "커미션 포함급여",
sal + IFNULL(comm, 0) AS "커미션 포함급여2"
FROM emp;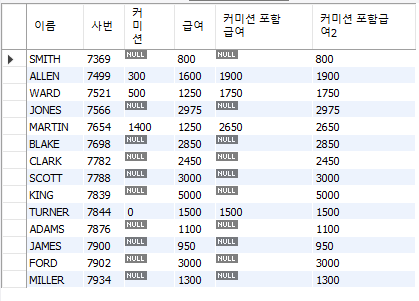
-- CASE FUNCTION
-- CASE 문은 조건을 통과하고 첫 번째 조건이 충족될 때 값을 반환한다.
-- 조건이 충족되지 않으면 ELSE 절의 값을 반환한다.
SELECT empno, ename, sal,
CASE WHEN sal >= 5000 THEN "고액연봉"
WHEN sal >= 2000 THEN "평균연봉"
ELSE "저액연봉"
END AS "연봉등급"
FROM emp;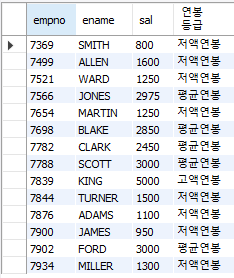
-- WHERE 절은 조건에 맞는 레코드를 조회하기 위해서 사용한다.
-- 부서 번호가 30인 사원중 급여가 1500 이상인 사원의 이름, 급여, 부서번호 조회
SELECT ename, sal, deptno
FROM emp
WHERE deptno = 30 AND sal >= 1500;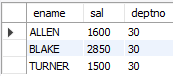
❗ WHERE 절은 SELECT 문장 뿐아니라, UPDATE, DELETE 등 다른 문장에서도 사용됨을 기억하자!
-- 부서번호가 20 또는 30인 부서에서 근무하는 사원의 사번, 이름, 부서번호 조회
SELECT empno, ename, deptno
FROM emp
WHERE deptno = 30
OR deptno = 20;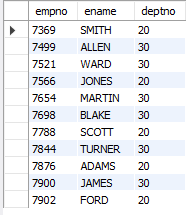
-- != 와 < > 모두 not equal을 의미한다.
-- 부서번호가 20,30이 아닌 부서에서 근무하는 사원의 사번, 이름, 부서번호 조회
SELECT empno, ename, deptno
FROM emp
WHERE deptno != 30 AND deptno <> 20;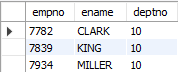
-- NOT - 조건문이 NOT TRUE일 때 레코드를 조회
SELECT empno, ename, deptno
FROM emp
WHERE NOT (deptno = 30 OR deptno = 20);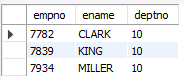
-- IN - 피연산자가 여러 표현 중 하나라도 같다면 TRUE
-- 업무가 MANAGER, ANALYST, PRESIDENT 인 사원의 이름, 사번, 업무조회
SELECT ename, empno, job
FROM emp
WHERE job IN ('MANAGER', 'ANALYST', 'PRESIDENT');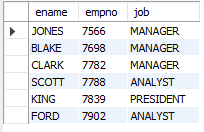
-- 부서번호가 10, 20이 아닌 사원의 사번, 이름, 부서번호 조회
SELECT empno, ename, deptno
FROM emp
WHERE deptno NOT IN (10, 20);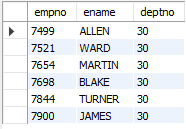
-- BETWEEN – 값이 주어진 범위의 범위 안에 있으면 조회
-- 값은 숫자나, 문자, 날짜가 될 수 있다.
-- 급여가 2000이상 3000이하 인 사원의 사번, 이름, 급여조회
SELECT empno, ename, sal
FROM emp
WHERE sal BETWEEN 2000 AND 3000;
-- WHERE sal >= 2000 AND sal <=3000;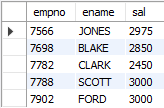
-- 입사일이 1981년인 직원의 사번, 이름, 입사일 조회
SELECT empno, ename, hiredate
FROM emp
WHERE hiredate BETWEEN '1981-01-01' AND '1981-12-31';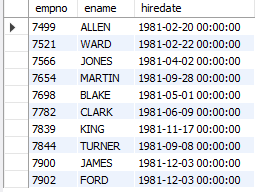
-- 커미션인 NULL 인 사원의 사번, 이름, 커미션 조회
SELECT empno, ename, comm
FROM emp
-- WHERE comm = NULL; -> NULL은 이런 식으로 가져올 수 없다.
WHERE comm IS NULL;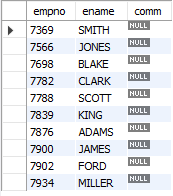
-- 커미션 NULL이 아닌 사원의 사번, 이름, 업무, 커미션 조회
SELECT empno, ename, comm
FROM emp
WHERE comm IS NOT NULL;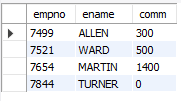
-- LIKE – WHERE 절에서 칼럼의 값이 특정 패턴을 가지는지 검사하기 위해 사용
-- 와일드 카드(%,_)를 이용해 패턴을 표현한다.
-- 이름이 M으로 시작하는 사원의 사번, 이름 조회
SELECT empno, ename
FROM emp
WHERE ename LIKE 'M%';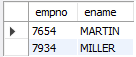
💡 와일드 카드
%: 0개 이상의 문자를 의미
_: 문자 하나를 의미
-- 이름에 E가 포함된 사원의 사번 이름 조회
SELECT empno, ename
FROM emp
WHERE ename LIKE '%E%';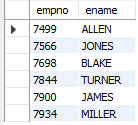
-- 이름의 세번째 알파벳이 'A'인 사원의 사번, 이름 조회
SELECT empno, ename
FROM emp
WHERE ename LIKE '__A%';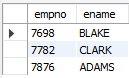
-- ORDER BY: 조회 결과를 오름차순(ASC) 또는 내림차순(DESC)으로 정렬할 때 사용한다. (default : ASC)
-- 정렬 기준(칼럼)을 지정할 수 있다.
-- 모든 직원의 모든 정보를 이름을 기준으로 내림차순 정룔
SELECT *
FROM emp
ORDER BY ename DESC;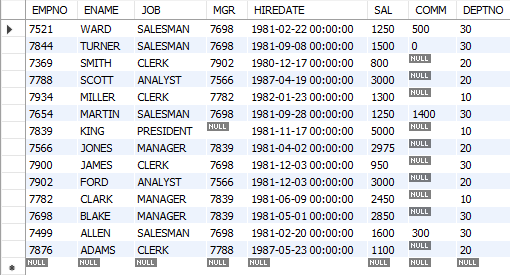
-- 모든 사원의 사번 이름, 급여를 조회 (급여 내림차순)
SELECT empno, ename, sal
FROM emp
ORDER BY sal DESC;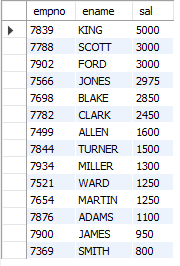
-- 20, 30번 부서에 근무하는 사원의 사번, 이름, 부서번호, 급여 조회 (부서별 오름차순, 급여순 내림차순)
SELECT empno, ename, deptno, sal
FROM emp
WHERE deptno IN (20, 30)
ORDER BY deptno, sal DESC;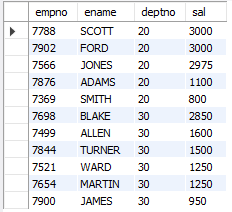
💡 SQL Query문의 실행 순서
FROMandJOIN->WHERE->GROUP BY->HAVING->SELECT->ORDER BY->LIMIT
📌 MySQL 내장 함수
🔷 MySQL은 문자열, 숫자, 날짜, 그 외에 대해서 다양한 함수를 제공한다. 그 중에서 당장 필요한 것만 살펴보겠다.
🔷 숫자 관련 함수(Numeric Functions)
| 함수 | 설명 |
|---|---|
ABS(숫자) | 절대값. |
CEIL(숫자), CEILING(숫자) | 값보다 크거나 같은 정수 중 가장 작은 수 반환. |
FLOOR(숫자) | 값 보다 작거나 같은 정수 중 가장 큰 수 반환. |
ROUND(숫자, 자릿수) | 숫자를 자릿수를 기준으로 반올림하여 반환. |
TRUNCATE(숫자, 자릿수) | 숫자를 자릿수를 기준으로 버림한 수를 반환 |
POW(X, Y) | X의 Y제곱 수를 반환 |
MOD(X, Y) | X를 Y로 나눈 나머지를 반환. |
GREATEST(숫자1, 숫자2, 숫자3, …) | 주어진 수들 중에서 가장 큰 수를 반환. |
LEAST(숫자1, 숫자2, 숫자3, …) | 주어진 수들 중에서 가장 작은 수를 반환. |
-- 2의 3제곱
SELECT POW(2, 3) AS "2^3"
FROM dual;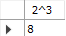
-- 8 나누기 3의 나머지
SELECT MOD(8, 3) AS "8을 3으로 나눈 나머지";
-- 최대값, 최솟값
SELECT greatest(8,17,86,17,100,77,999,2,13,31,97), least(8,17,86,17,100,77,999,2,13,31,97);
-- 반올림
SELECT round(1526.159), round(1526.159, 0), round(1526.159, 1), round(1526.159,2), round(1526.159, 3);
🔷 문자 관련 함수(String Functions)
| 함수 | 설명 |
|---|---|
ASCII | 문자의 아스키 코드 값 반환 |
CONCAT | 두 개 이상의 문자열들을 결합하여 반환 |
FORMAT | 숫자를 “#,###,###,###.##” 와 같은 형식으로 지정하고 반환 |
INSERT | 문자열 내의 지정된 위치에서 특정 수의 문자에 대해 문자열을 삽입 |
INSTR | 문자열에서 지정한 문자열이 처음 나타나는 위치를 반환 |
LOWER | 문자열을 소문자로 변환 |
CHAR_LENGTH | 문자열의 길이를 반환(문자단위) |
LENGTH | 문자열의 길이를 반환(바이트 단위) |
TRIM | 문자열에서 선행 및 후행 공백 제거 |
UPPER | 문자열을 대문자로 변환 |
REPLACE | 문자열 내의 모든 부분 문자열을 새 부분 문자열로변환 |
STRCMP | 두 문자열 비교 |
SUBSTR | 문자열에서 부분 문자열 추출 |
LPAD | 특정 길이로 문자열을 다른 문자열의 왼쪽에 채움 |
RPAD | 특정 길이로 문자열을 다른 문자열의 오른쪽에 채움 |
REPEAT | 지정된 횟수만큼 문자열을 반복 |
REVERSE | 문자열을 뒤집고 결과를 반환 |
-- 아스키 코드값 얻기
SELECT ascii('0'), ascii('A'), ascii('a'); 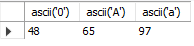
-- concat
SELECT CONCAT('PRESIDENT의 이름은 ', ename, ' 입니다.') AS 소개
FROM emp
WHERE job = 'PRESIDENT'; 
-- 이름의 길이가 5인 직원의 이름을 조회
SELECT ename
FROM emp
WHERE length(ename) = 5;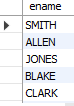
-- 박영규 (length: 데이터의 길이, char_length: 문자열의 길이)
SELECT length('박영규'), char_length('박영규');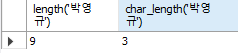
-- 문자열 변경
SELECT replace('Hello abc abc', 'abc', 'bzeromo');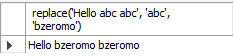
-- 모든 직원의 이름 3자리조회
SELECT substr(ename, 1, 3)
FROM emp;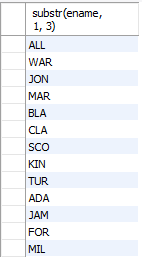
-- LPAD RPAD
-- 두 번째 넣은 수에 처음 넣은 문자열의 길이만큼 오른쪽 혹은 왼쪽에 세번째로 지정한 문자열을 채운다.
SELECT LPAD('BZEROMO',10,'*'), RPAD('BZEROMO',10,'*');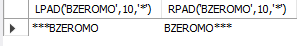
-- REVERSE
SELECT REVERSE('Hi Bzeromo!');
🔷 날짜 관련 함수(Date Functions)
| 함수 | 설명 |
|---|---|
DATE | datetime 표현식에서 날짜 부분을 추출하여 날짜 반환 |
ADDTIME | 시간/날짜/시간에 시간 간격을 추가한 다음 시간/날짜/시간을 반환 |
DATEDIFF | 두 날짜 값 사이의 일 수를 반환 |
DAY | 주어진 날짜의 해당 달의 날짜를 반환 |
NOW, SYSDATE, CURRENT_TIMESTAMP | 현재 날짜와 시간을 반환 |
YEAR | 주어진 날짜의 연도 부분을 반환 |
YEARWEEK | 주어진 날짜의 연도 및 주 번호를 반환 |
DAYNAME | 주어진 날짜의 요일 이름을 반환 |
MONTH | 주어진 날짜의 월 부분을 반환 |
-- 2초 더하기
SELECT addtime("2022-02-13 17:29:21", "2");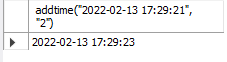
-- 날짜차이
SELECT datediff("2008-02-18", "2006-02-21");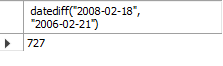
-- 오늘은?
SELECT now(), day(now()), month(now()), year(now()), yearweek(now());
🔷 그 외 기타 중요 함수(Advanced Functions)
| 함수 | 설명 |
|---|---|
BIN | 숫자의 이진 표현을 반환 |
BINARY | 값을 이진 문자열로 변환 |
CAST | 값(모든 유형)을 지정된 데이터 유형으로 변환 |
CONVERT | 값을 지정된 데이터 유형 또는 문자 집합으로 변환 |
IF | 조건이 TRUE이면 값을 반환하고 조건이 FALSE이면 다른 값을 반환 |
NULLIF | 두 표현식을 비교하고 같으면 NULL을 반환. 그렇지 않으면 첫 번째 표현식이 반환 |
IFNULL | 표현식이 NULL이면 지정된 값을 반환하고, 그렇지 않으면 표현식을 반환 |
LAST_INSERT_ID | 테이블에 삽입되거나 업데이트된 마지막 행의 AUTO_INCREMENT ID를 반환 |
🔷 집계 함수(Aggregate Function)
- 여러 값의 집합(복수 행)에 대해서 동작한다.(복수 행 함수, 통계 함수, 그룹함수)
GROUP BY절과 함께 사용해 전체 집합의 하위 집합을 그룹화 한다
| 함수 | 설명 |
|---|---|
AVG | 인수의 평균 값을 반환 |
COUNT | 조회된 행의 수를 반환 |
MAX | 최대값 반환 |
MIN | 최소값 반환 |
SUM | 합 반환 |
STD | 표준편차 반환 |
-- 모든 사원에 대하여 사원수, 급여총액, 평균급여, 최고급여, 최저급여 조회
SELECT COUNT(*) 사원수, SUM(sal) 급여총액 , AVG(sal) 평균급여, MAX(sal) AS "최고급여", MIN(sal) AS "최저급여"
FROM emp;
-- 모든 사원에 대하여 부서, 사원수, 급여총액, 평균급여, 최고급여, 최저급여를 부서별로 조회하고, 소수점 둘쨰자리 반올림
SELECT deptno 부서, COUNT(*) 사원수, SUM(sal) 급여총액, ROUND(AVG(sal), 2) 평균급여, MAX(sal) 최고급여, MIN(sal) 최저급여
FROM emp
GROUP BY deptno;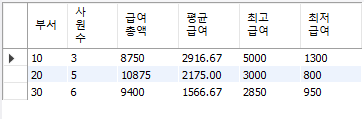
-- 모든 사원에 대하여 부서, 업무, 사원수, 급여총액, 평균급여, 최고급여, 최저급여를 부서별, 직급별로 조회
SELECT deptno 부서, job 업무, COUNT(*) 사원수, SUM(sal) 급여총액, ROUND(AVG(sal), 2) 평균급여, MAX(sal) 최고급여, MIN(sal) 최저급여
FROM emp
GROUP BY deptno, job
ORDER BY deptno;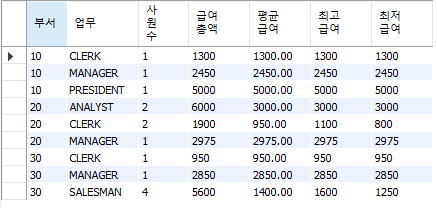
-- 모든 사원에 대하여 이름, 부서, 업무, 사원수, 급여총액, 평균급여, 최고급여, 최저급여를 부서별, 직급별로 조회
SELECT ename 이름, deptno 부서,job 업무, COUNT(*) 사원수, SUM(sal) 급여총액,
ROUND(AVG(sal),2) 평균급여, MAX(sal) 최고급여, MIN(sal) 최저급여
FROM emp
GROUP BY deptno,job;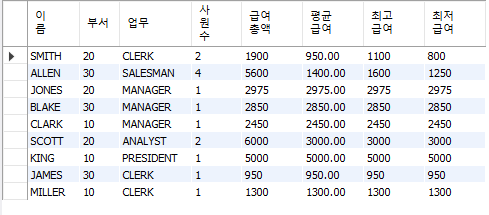
-- 급여(커미션포함) 평균이 2000이상인 부서번호, 부서별 사원수, 평균급여(커미션포함) 조회
SELECT deptno, COUNT(*) 사원수, ROUND(AVG(sal+IFNULL(comm, 0)),2) AS "평균급여(커미션포함)"
FROM emp
GROUP BY deptno
HAVING AVG(sal + IFNULL(comm, 0)) >= 2000;
📌 트랜잭션 (Transaction)
🔷 커밋(Commit) 하거나 롤백(Rollback) 할 수 있는 가장 작은 작업 단위
-
커밋(Commit): 트랜잭션을 종료하여 변경사항에 대해서 영구적으로 저장하는 SQL -
롤백(Rollback): 트랜잭션에 의해 수행된 모든 변경사항을 실행 취소하는 SQL
| 이름 | 설명 |
|---|---|
START TRANSACTION | 트랜잭션을 시작함. COMMIT, ROLLBACK이 나오기 전까지 모든 SQL 을 의미 |
COMMIT | 트랜잭션에서 변경한 사항을 영구적으로 DB에 반영 |
ROLLBACK | START TRANSACTION 실행 전 상태로 되돌림. |
💡 MySQL에서는 기본적으로 세션이 시작하면 autocommit 설정 상태이다. 그러므로 MySQL은 각 SQL 문장이 오류를 반환하지
않으면 commit 을 수행한다.
-- 오토커밋 안하겠다고 설정
set autocommit = 0;
-- 트랜잭션을 위한 새 테이블 생성
USE bzerodb;
CREATE TABLE test_table(val VARCHAR(20));
-- 롤백
START TRANSACTION;
INSERT INTO test_table VALUES ('A');
INSERT INTO test_table VALUES ('B');
INSERT INTO test_table VALUES ('C');
INSERT INTO test_table VALUES ('D');
ROLLBACK;
SELECT * FROM test_table;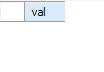
-- 커밋
START TRANSACTION;
INSERT INTO test_table VALUES ('B');
INSERT INTO test_table VALUES ('z');
INSERT INTO test_table VALUES ('e');
INSERT INTO test_table VALUES ('r');
INSERT INTO test_table VALUES ('o');
COMMIT;
SELECT * FROM test_table;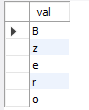
SQLD도 취득한 나에게 이정도는 쉽지~
라고 할 수 없는 것 같다.
