
⚡ JOIN & SubQuery / DB 모델링
📌 JOIN
🔷 둘 이상의 테이블에서 데이터를 조회하기 위해서 사용
🔷 일반적으로 조인 조건은 PK(Primary Key) 및 FK(Foreign Key)로 구성된다.
- PK 및 FK 관계가 없더라도 논리적인 연관만으로도
JOIN이 가능하다.
🔷 JOIN의 종류
-
INNER JOIN: 조인 조건에 해당하는 칼럼 값이 양쪽 테이블에 모두 존재하는 경우에만 조회,동등 조인(Equi-join)이라고도 한다. N개의 테이블 조인 시 N-1개의 조인 조건이 필요 -
OUTER JOIN: 조인 조건에 해당하는 칼럼 값이 한 쪽 테이블에만 존재하더라도 조회 기준 테이블에 따라LEFT OUTER JOIN,RIGHT OUTER JOIN으로 구분 -
SELF JOIN: 같은 테이블 2개를 조인 -
Non-Equi JOIN: 조인 조건이 table의 PK, FK 등으로 정확히 일치하는 것이 아닐 때 사용
💡 두 테이블을 조인할 때 어떤 테이블을 먼저 읽느냐에 따라 작업량이 달라질 수 있다! 물론 요즘 DB는 알아서 최적화를 해주기 때문에 크게 신경 쓸 필요 없다.
🔷 카타시안 곱(Cartesian Product)
- 두 개 이상의 테이블에서 데이터를 조회할 때
- 조인 조건을 지정하지 않음
- 조인 조건이 부적합 함
- 첫 번째 테이블의 모든 행이 두 번째 테이블의 모든 행에 조인되어 처리됨
-- 2번의 조회를 합치자
SELECT empno, ename, job
FROM emp;
SELECT deptno, dname
FROM dept;
-- 카타시안 곱
-- WHERE 사용 없이는 단순히 두 테이블 행을 곱한만큼 나온다.
SELECT empno, ename, job, emp.deptno, dname
FROM emp, dept;
-- WHERE 사용하여 유의미하게 데이터를 뽑기
SELECT empno, ename, job, emp.deptno, dname
FROM emp, dept
WHERE emp.deptno = dept.deptno;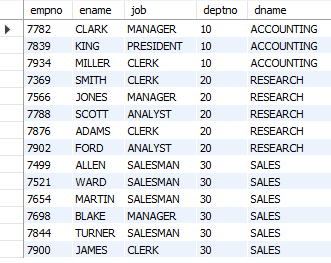
-- 사번 7788인 사원의 이름, 업무, 부서번호, 부서이름 조회
SELECT ename, job, deptno
FROM emp
WHERE empno = 7788;
SELECT dname
FROM dept
WHERE deptno = 20;
-- 두 번 조회할 필요 없이 조인!
-- 조인을 이용하여 작성 (INNER JOIN과 같다)
SELECT ename, job, emp.deptno, dname
FROM emp, dept
WHERE emp.deptno = dept.deptno
AND empno = 7788;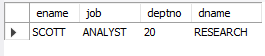
-- INNER JOIN
-- 두 테이블에서 일치하는 값을 가진 레코드를 조회
-- table alias를 지정해 SQL 작성시 쉽게 사용할 수 있다.
SELECT e.ename, e.job, e.deptno, d.dname
FROM emp e
INNER JOIN dept d
ON e.deptno = d.deptno
WHERE e.empno = 7788;
-- 위랑 같다 (USING 키워드는 두 개의 테이블에 동일한 컬럼명이 존재할 때만 사용)
SELECT ename, job, deptno, dname
FROM emp
INNER JOIN dept
USING (deptno)
WHERE empno = 7788;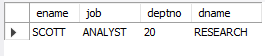
-- 새로운 인원이 들어왔다고 했을 때
INSERT INTO emp
VALUES (1236, "박영규", "MANAGER", 7139, "2023-10-11", 2000, NULL, NULL);
-- 동등조인으로 이름, 부서번호, 부서 이름을 가져오기
-- 새로 추가한 인물은 부서가 없어서 나오지 않는다!
SELECT e.ename, e.deptno, d.dname
FROM emp e, dept d
WHERE e.deptno = d.deptno;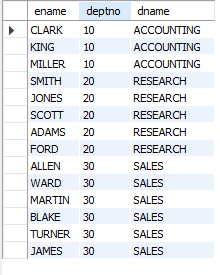
-- OUTER JOIN
-- 한쪽에 기준을 주고 붙이기
-- 없으면 없는 데로
-- 모든 사원을 기준으로 (좌측 테이블)
SELECT e.ename, e.deptno, d.dname
FROM emp e LEFT OUTER JOIN dept d
ON e.deptno = d.deptno;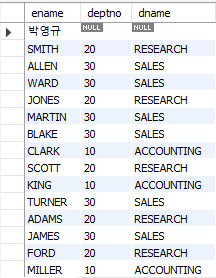
-- 부서 테이블을 기준으로 (우측 테이블)
SELECT e.ename, e.deptno, d.dname
FROM emp e RIGHT OUTER JOIN dept d
ON e.deptno = d.deptno;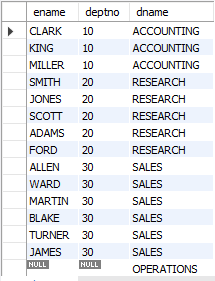
-- 셀프 조인
-- 모든 사원번호, 이름, 매니저 번호, 매니저 이름
SELECT e1.empno, e1.ename, e1.mgr, e2.ename
FROM emp e1, emp e2
WHERE e1.mgr = e2.empno
ORDER BY e2.ename;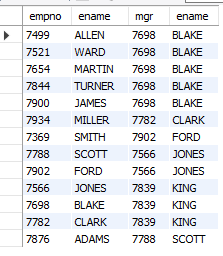
-- INNER JOIN 이라는 키워드를 사용해보자
SELECT e1.empno AS "사번", e1.ename AS 사원이름, e2.empno AS "매니저 번호", e2.ename AS "매니저 이름"
FROM emp e1
INNER JOIN emp e2
ON e1.mgr = e2.empno;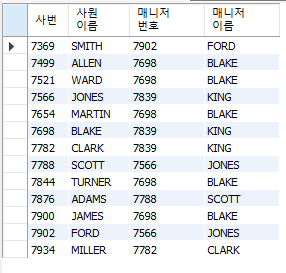
-- KING 이 안나오는 위의 쿼리문과 다르게 KING이 나온다
-- OUTER JOIN이니까!
SELECT e1.empno AS "사번", e1.ename AS 사원이름, e2.empno AS "매니저 번호", e2.ename AS "매니저 이름"
FROM emp e1 LEFT OUTER JOIN emp e2
ON e1.mgr = e2.empno;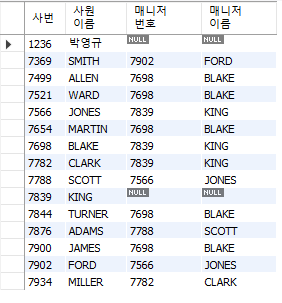
-- 비 동등 조인(Non-Equi JOIN)
-- 조인조건이 table의 PK, FK 등으로 정확히 일치하는 것이 아닐 때 사용
-- 모든 사원의 사번, 이름, 급여, 급여등급을 조회하고 싶다면?
SELECT e.empno, e.ename, e.sal AS "급여", sg.grade AS "급여등급"
FROM emp e, salgrade sg
WHERE e.sal BETWEEN sg.LOSAL AND sg.HISAL
-- WHERE e.sal >= sg.LOSAL AND e.sal <= sg.HISAL
ORDER BY sg.grade DESC, e.sal DESC;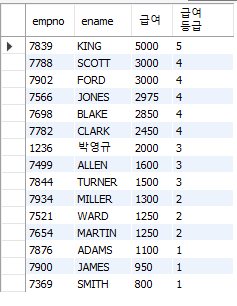
📌 서브 쿼리(Subquery)
🔷 하나의 SQL 문안에 포함되어 있는 SQL문을 의미한다.
- 서브 쿼리를 포함하는 SQL을
외부 쿼리(outer query)또는 메인 쿼리라고 부르며, 서브 쿼리는내부 쿼리(inner query)라고도 부른다. - JOIN의 경우 경우에 따라 쿼리가 복잡해지거나 카타시안 곱으로 인해 속도가 느려질 수 있는데 이 때 JOIN 없이 조회하기 위해서 서브 쿼리가 필요하다.
🔷 서브 쿼리의 종류
- 중첩 서브 쿼리(Nested Subquery) - WHERE 절에 작성하는 서브 쿼리 (단일-행, 다중-행, 다중-열)
- 인라인 뷰(Inline-view) - FROM 절에 작성하는 서브 쿼리
- 스칼라 서브 쿼리(Scalar Subquery) - SELECT 문에 작성하는 서브 쿼리
🔷 서브 쿼리를 포함할 수 있는 SQL 문
SELECT,FROM,WHERE,HAVING,ORDER BYINSERT문의VALUESUPDATE문의SET
🔷 서브 쿼리의 사용 시 주의사항
- 서브 쿼리는 반드시 ()로 감싸서 사용한다.
- 서브 쿼리는 단일 행 또는 다중 행 비교 연산자와 함께 사용 가능하다.
💡 단일 행 비교연산자는 서브 쿼리 결과가 1건 이하이어야 하고, 복수 행 비교 연산자는 결과 건수와 상관없다.
⭐ 중첩 서브 쿼리
🔷 단일 행
- 서브 쿼리 결과가 단일 행을 반환
-- 1. 매니저의 이름이 KING인 사원의 사번, 이름, 부서번호, 업무
SELECT empno, ename, deptno, job
FROM emp
WHERE mgr = (SELECT empno
FROM emp
WHERE ename = "KING");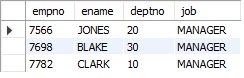
-- 2. 7566번 사원보다 급여를 많이 받는 사원의 이름, 급여를 조회
-- 7566번의 급여
SELECT sal
FROM emp
WHERE empno = 7566;
SELECT ename, sal
FROM emp
WHERE sal > (SELECT sal
FROM emp
WHERE empno = 7566);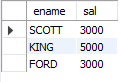
-- 3. 20번 부서의 평균 급여보다 급여가 많은 사원의 사번, 이름, 업무, 급여조회
SELECT AVG(sal)
FROM emp
WHERE deptno = 20;
SELECT empno, ename, job, sal
FROM emp
WHERE sal > (SELECT AVG(sal)
FROM emp
WHERE deptno = 20);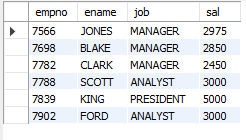
-- 4. 업무가 TURNER와 같고/ 사번 7934인 직원보다 급여/가 많은 사원의 사번, 이름, 업무를 조회
SELECT job
FROM emp
WHERE ename = "TURNER";
SELECT sal
FROM emp
WHERE empno = 7934;
SELECT empno, ename, job, sal
FROM emp
WHERE job = (SELECT job
FROM emp
WHERE ename = "TURNER")
AND sal > (SELECT sal
FROM emp
WHERE empno = 7934);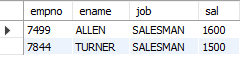
🔷 다중 행
- 서브 쿼리 결과가 다중행을 반환 :
IN,ANY,ALL연산자와 함께 사용
-- 다중행 IN / ANY / ALL
-- 5. 업무가 SALESMAN 인 직원들 중 최소 한명 이상보다 많은 급여를 받는 사원의 이름, 급여, 업무를 조회하시오.
SELECT sal
FROM emp
WHERE job = 'SALESMAN';
-- > ANY (최소값보다는 큼) / < ANY (최대값보다는 작음)
SELECT ename, sal, job
FROM emp
WHERE sal > ANY (SELECT sal
FROM emp
WHERE job = 'SALESMAN');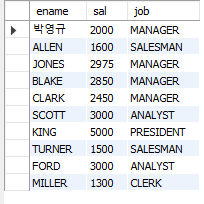
-- 6. 업무가 'SALESMAN'인 모든 직원보다 급여(커미션포함)를 많이 받는 사원의 이름, 급여, 업무, 입사일, 부서번호를 조회하시오.
SELECT sal + IFNULL(comm, 0)
FROM emp
WHERE job = 'SALESMAN';
-- > ALL (최대값보다 큼) / < ALL (최소값보다 작음)
SELECT ename, sal, job, hiredate, deptno
FROM emp
WHERE sal > ALL (SELECT sal + IFNULL(comm, 0)
FROM emp
WHERE job = 'SALESMAN');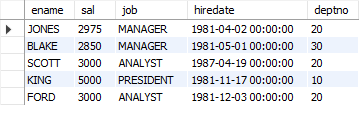
-- 7. 직원이 최소 한명이라도 근무하는 부서의 부서번호, 부서이름, 위치
SELECT DISTINCT deptno
FROM emp;
-- DISTINCT 키워드를 이용해 중첩되는 행은 제거
-- IN은 다중행에 하나라도 일치하면 조회, = ANY 와 같다
SELECT deptno, dname, loc
FROM dept
WHERE deptno IN (SELECT DISTINCT deptno
FROM emp);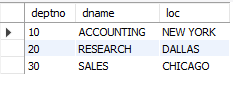
🔷 다중 열
- 서브 쿼리의 결과값이 두 개 이상의 칼럼을 반환하는 서브 쿼리
- PK가 복합키(Composite Key) 이거나, 여러 칼럼의 값을 한꺼번에 비교해야 할 경우 사용
행 생성자(row constructor)를 이용하여 다중 열 서브 쿼리를 비교
-- 다중열
-- 8. 이름이 FORD인 사원과 매니저 및 부서가 같은 사원의 이름, 매니저번호, 부서번호를 조회
SELECT mgr, deptno
FROM emp
WHERE ename = 'FORD';
SELECT ename, mgr, deptno
FROM emp
WHERE (mgr, deptno) = (SELECT mgr, deptno
FROM emp
WHERE ename = 'FORD')
AND ename <> 'FORD';
-- AND ename != 'FORD';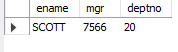
-- 9. 각 부서별 / 입사일이 가장 빠른 / 사원의 사번, 이름, 부서번호, 입사일을 조회
SELECT IFNULL(deptno, '대기발령') , MIN(hiredate)
FROM emp
GROUP BY deptno;
-- 지난 포스팅에서도 언급했다시피 NULL은 연산이 불가능해 걸러줄 필요가 있다.
SELECT empno, ename, deptno, hiredate
FROM emp
WHERE (deptno, hiredate) IN (SELECT IFNULL(deptno, '대기발령') , MIN(hiredate)
FROM emp
GROUP BY deptno);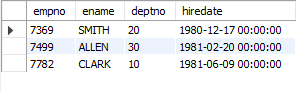
⭐ 상호연관 서브 쿼리
🔷 외부 쿼리에 있는 테이블에 대한 참조를 하는 서브 쿼리를 의미한다.
-- 상호연관 서브쿼리
-- 외부 쿼리의 e를 서브 쿼리가 참조하고 있다.
-- 10. 소속 부서의 평균 급여보다 많은 급여를 받는 사원의 이름, 급여, 부서번호, 입사일, 업무를 조회
SELECT ename, sal, deptno, hiredate, job
FROM emp e
WHERE sal > (SELECT AVG(sal)
FROM emp
WHERE deptno = e.deptno);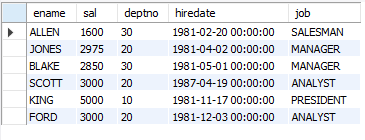
- 테이블에서 행을 먼저 읽어서 각 행의 값을 관련된 데이터와 비교하는 방법 중 하나이다.
- 기본 질의에서 고려된 각 후보행에 대해 서브 쿼리가 다른 결과를 반환해야 하는 경우에 사용한다.
- 서브 쿼리에서는 메인 쿼리의 컬럼명을 사용할 수 있으나, 메인 쿼리에서는 서브 쿼리의 컬럼명을 사용할 수 없다.
⭐ 인라인 뷰(Inline View)
🔷 FROM절에서 사용되는 서브 쿼리
- 동적으로 생성된 테이블로 사용 가능하다. 뷰(View) 와 같은 역할을 한다.
💡 인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 뷰 이기 때문에 데이터베이스에 해당 정보가 저장되지 않는다. 그래서
동적 뷰(Dynamic View)라고도 한다.
-- 인라인 뷰(FROM 절에 서브쿼리)
-- 11. 모든 사원의 평균급여보다 적게 받는 사원들과 같은 부서에서 근무하는 사원의 사번, 이름, 급여, 부서번호를 조회
SELECT AVG(sal)
FROM emp;
SELECT DISTINCT deptno
FROM emp
WHERE sal < (SELECT AVG(sal) FROM emp);
SELECT e.ename, e.empno, e.sal, e.deptno
FROM emp e, (SELECT DISTINCT deptno FROM emp WHERE sal < (SELECT AVG(sal) FROM emp)) AS d
WHERE e.deptno = d.deptno;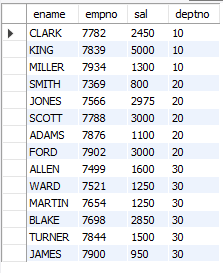
-- 12. 모든 사원에 대하여 사원의 이름, 부서번호, 급여, 사원이 소속된 부서의 평균 급여를 조회 (단, 이름 오름차순)
SELECT deptno, AVG(sal) AS avgsal
FROM emp
GROUP BY deptno;
SELECT e.ename, e.deptno, e.sal, d.avgsal
FROM emp e, (SELECT deptno, AVG(sal) AS avgsal
FROM emp
GROUP BY deptno) d
WHERE e.deptno = d.deptno
ORDER BY e.ename;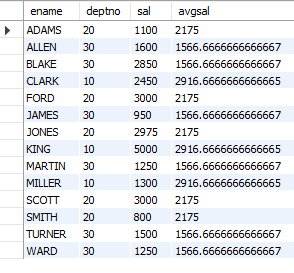
⭐ TOP-N
🔷 LIMIT
- 결과 집합에서 지정된 수의 행만 필요한 경우
LIMIT절을 사용 - 하나 또는 2개 양의 정수를 인자로 받음
- 첫 번째 인자 : offset, 두 번째 인자 개수, 첫 번째 인자를 생략 할 경우 기본값은 0
SELECT empno, ename, sal
FROM emp
ORDER BY sal DESC limit 5, 5;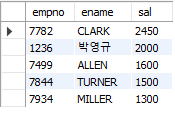
⭐ 스칼라 서브 쿼리 (Scalar Subquery)
🔷 하나의 행에서 하나의 컬럼 값만 반환하는 서브 쿼리
🔷 다음과 같은 경우에 사용가능
- GROUP BY를 제외한 SELECT의 모든 절
- INSERT 문의 VALUES
- 조건 및 표현식 부분
- UPDATE 문의 SET 또는 WHERE절에서 연산자 목록
-- 스칼라서브쿼리
-- SELECT 에 스칼라 서브 쿼리 사용
-- 13. 사원의 이름, 부서번호, 급여, 소속부서의 평균 급여를 조회
SELECT ename, deptno, sal, (SELECT AVG(sal) FROM emp WHERE deptno = e.deptno) AS avgsal
FROM emp e;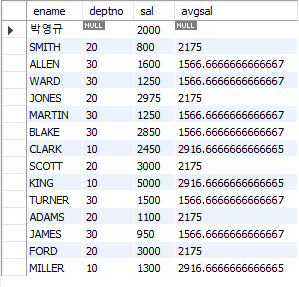
-- SELECT 에 스칼라 서브 쿼리 사용
-- 14. 부서번호가 10인 부서의 총 급여, 20인 부서의 평균 급여, 30인 부서의 최고, 최저 급여
SELECT (SELECT SUM(sal) FROM emp WHERE deptno = 10) AS SUM10,
(SELECT AVG(sal) FROM emp WHERE deptno = 20) AS AVG20,
(SELECT MAX(sal) FROM emp WHERE deptno = 30) AS MAX30,
(SELECT MIN(sal) FROM emp WHERE deptno = 30) AS MIN30
FROM dual;
-- ORDER BY 에 스칼라 서브 쿼리 사용
-- 15. 모든사원의 번호, 이름, 부서번호, 입사일을 조회 (단, 부서이름기준으로 내림차순)
UPDATE emp SET deptno = 40 WHERE empno = 4168;
SELECT empno, ename, deptno, hiredate
FROM emp e
ORDER BY (SELECT dname
FROM dept
WHERE deptno = e.deptno) DESC;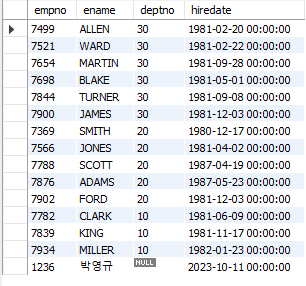
⭐ 그 외의 서브 쿼리 활용
-- 서브 쿼리를 이용한 CREATE 문
-- 테이블을 카피
CREATE TABLE emp_copy
(SELECT * FROM emp);
-- emp table 구조만 emp_blank 라는 이름으로 복사하여 생성
-- WHERE 1 = 0 은 약속과도 같다.
CREATE TABLE emp_blank
(SELECT * FROM emp WHERE 1 = 0);
-- 서브 쿼리를 이용한 INSERT 문
-- 부서 번호가 30인 사원의 모든 정보를 emp_blank에 INSERT
INSERT INTO emp_blank
(SELECT * FROM emp WHERE deptno = 30);
SELECT * FROM emp_blank;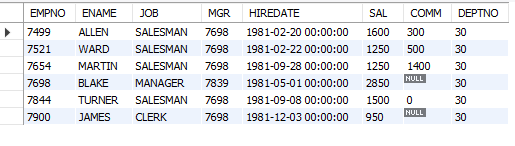
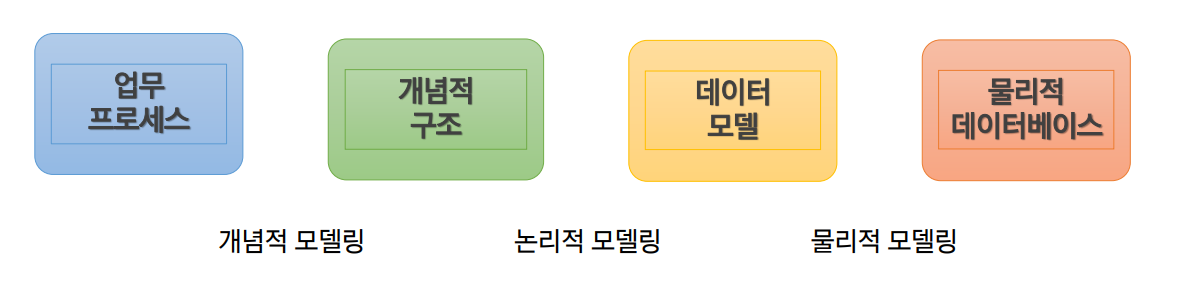
📌 데이터베이스 모델링
🔷 실생활을 DB로 모델링하는 작업을 일컫는다.
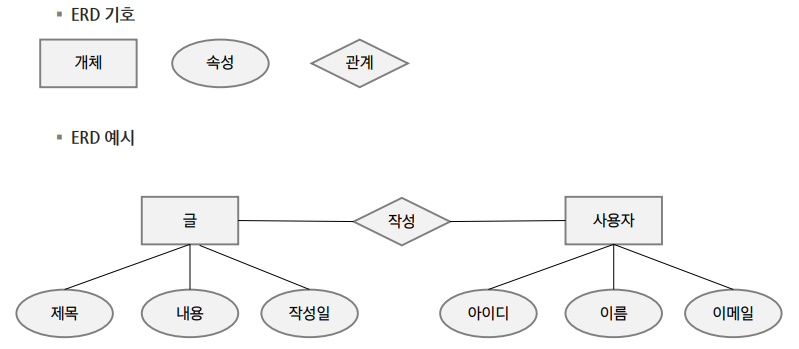
⭐ 개념적 데이터베이스 모델링
- 사용자 부문의 처리현상을 분석한다.
- 중요 실체와 관계를 파악하여
ERD를 작성한다. - 실체에 대한 상세 정의를 한다.
- 식별자를 정의하고, 식별자 업무규칙을 정한다.
- 실체별로 속성을 상세화 한다.
- 필요한 속성 및 영역을 상세 정의한다.
- 속성에 대한 업무규칙을 정의한다.
- 각 단계를 마친 후 사용자와 함께 모델을 검토한다.
🔷 개체 (Entity) : 사용자와 관계가 있는 주요 객체 (데이터로 관리 되어야 하는 것)
🔷 Entity 찾는법
- 영속적으로 존재하는 것
- 새로 식별이 가능한 데이터 요소를 가짐
Entity는Attribute를 가져야 함.
🔷 속성 (Attribute)
- 저장할 필요가 있는 실체에 관한 정보
- 개체(Entity)의 성질, 분류, 수량, 상태, 특성 등을 나타내는 세부사항
- 개체에 포함되는 속성의 숫자는 10개 내외로 하는 것이 바람직함
- 최종 DB 모델링 단계를 통해 테이블의 컬럼으로 활용
ex) 학생 : 학번, 이름, 주민번호, 전화번호, 주소, 입학일자, 학과 / 직원 : 직원ID, 이름, 주민번호, 주소, 입사일자, 소속부서
🔷 식별자 : 한 개체(Entity) 내에서 인스턴스를 구분할 수 있는 단일 속성 또는 속성 그룹
🔷 후보키 (Candidate Key) : 개체내에서 각각의 인스턴스를 구분할 수 있는 속성 (기본키가 될 수 있음)
🔷 기본키 (Primary Key) : 개체(Entity)에서 각 인스턴스를 유일하게 식별하는데 적합한 Key
🔷 대체키 (Alternate Key) : 후보키 중에서 기본키로 선정 되지 않은 Key
🔷 복합키 (Comosite Key) : 하나의 속성으로 기본키가 될 수 없는 경우 둘 이상의 컬럼을 묶어서 식별자로 정의
🔷 대리키 (Surrogate Key) : 식별자가 너무 길거나 여러 개의 속성으로 구성되어 있는 경우 인위적으로 추가
🔷 관계 (Relationship) : 두 Entity간의 업무적인 연관성 또는 관련 사실
- 각 Entity간에 특정한 존재여부 결정.
- 현재의 관계 뿐만 아니라 장래에 사용될 경우도 고려
🔷 ERD 관계를 설정하는 순서
- 관계가 있는 두 실체를 실선(점선)으로 연결하고 관계를 부여
- 관계 차수를 표현 (1:1, 1:N, N:M)
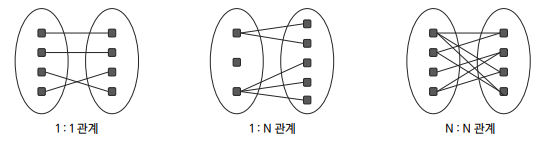
- 선택성을 표시 (
mandatoryoroptional)
⭐ 논리적 데이터베이스 모델링
🔷 개념적 데이터베이스 모델링 단계에서 정의된 ER-Diagram을 Mapping Rule을 적용하여 관계형 데이터베이스 이론에 입각한 스키마를 설계하는 단계와 이를 이용하여 필요하다면 정규화 하는 단계로 구성
🔷 기본키 (Primary Key)
- 후보키 중에서 선택한 주 키.
- 널(Null)의 값을 가질 수 없다 (Not Null).
- 동일한 값이 중복해서 저장될 수 없다 (Unique).
🔷 참조키, 이웃키 (Foreign Key)
- 관계를 맺는 두 엔티티에서 서로 참조하는 릴레이션의 attribute로 지정되는 키
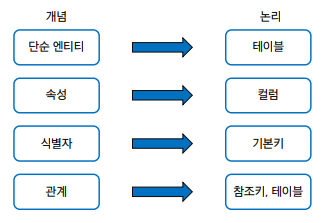
🔷 Mapping Rule
- 개념적 데이터베이스 모델링에서 도출된 개체 타입과 관계 타입의 테이블 정의
🔷 정규화 (Normalization)
- 관계형 데이터베이스 설계에서 중복을 최소화하도록 데이터를 구조화 하는 프로세스를 말한다.
🔷 정규화 (Normalization)의 목적
- 데이터베이스의 변경 시 이상 현상 제거
- 데이터베이스 구조 확장 시 재 디자인 최소화
- 사용자에게 데이터 모델을 더욱 의미 있게 작성하도록 함
- 다양한 질의 지원
- 정규화는 제 1 정규화, 제 2 정규화, 제 3 정규화가 있으며 제 3 정규화를 강화한
BCNF도 있다.
⭐ 물리적 데이터베이스 모델링
🔷 논리적 데이터베이스 모델링 단계에서 얻어진 데이터베이스 스키마를 좀더 효율적으로 구현하기 위한 작업
- DBMS 특성에 맞게 실제 데이터베이스내의 개체들을 정의하는 단계.
- Column의
domain설정(int, varchar, date, …)
- Column의
- 데이터 사용량 분석과 업무 프로세스 분석을 통해서 보다 효율적인 데이터베이스가 될 수 있도록 효과적인 인덱스를 정의 하고 상황에 따른 역정규화 작업을 수행.
- Index, Trigger, 역정규화.
🔷 역정규화 (Denomalization)
- 시스템 성능을 고려하여 기존 설계를 재구성하는 것
- 정규화에 위배되는 행위
- 테이블의 재구성
🔷 역정규화 방법
- 데이터 중복 (컬럼 역정규화)
- 파생 컬럼의 생성
- 테이블 분리
- 요약 테이블 생성
- 테이블 통합
서브 쿼리부터 지끈지끈하지만, 잘 익혀갑시다...
