📌 What I did today
학습 모델로서 BERT의 필요성
BERT는 기본적으로 이미 존재하는 모델을 가져다가 우리의 입맛에 맞게 fine-tuning을 하는 방식으로 모델 학습을 한다. Fine-tuning은 pretrained된 모델을 다운스트림 테스크에 맞게 업데이트하는 기법이다. 이렇게 도메인 특화 데이터로 학습한 모델이 성능이 더 좋다.
BERT huggingface transformers 모델 선정
- bert-base-multilingual-cased
bert-base-multilingual-cased는 100여개의 언어에 특화된 모델이지만, 한국어 단어가 많이 학습되어 있는 것 같지는 않음. 학습된 한국어 어휘는 총 119,546개

- BERT의 쌩 tokenizer 사용시
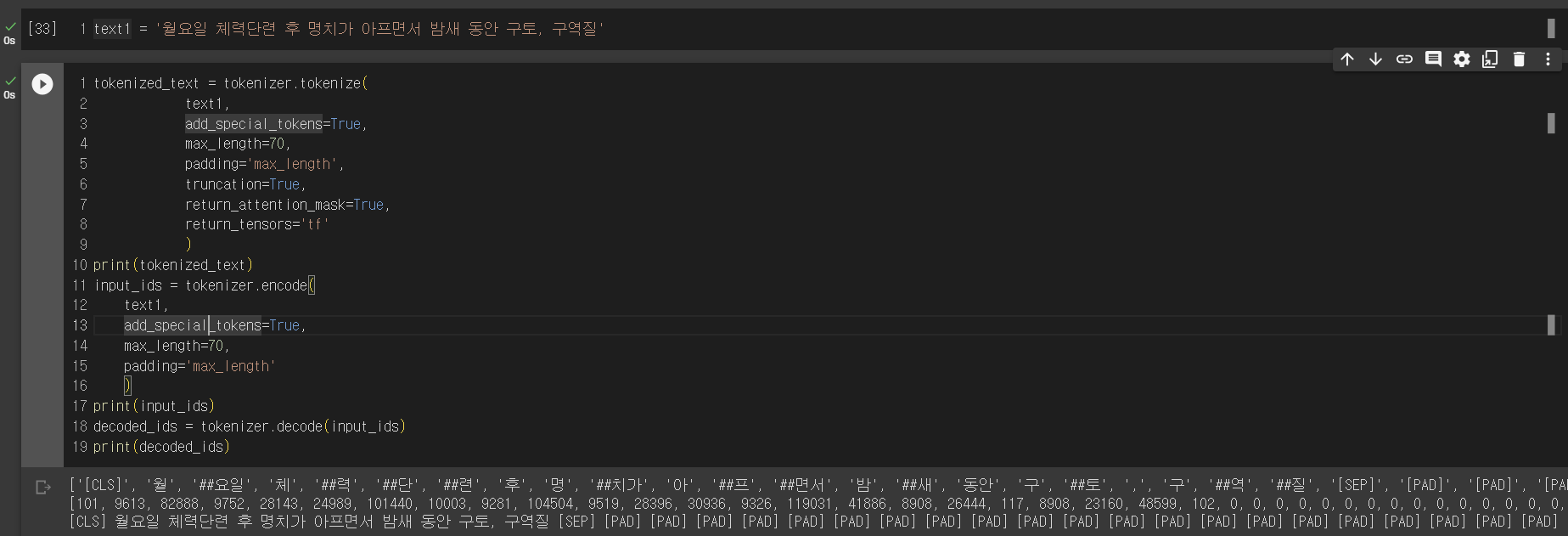
- KoBERT
구글의 bert-base-multilingual-cased의 한국어 성능 한계를 극복한 모델
- 참고 깃허브
https://github.com/SKTBrain/KoBERT/tree/master/kobert_hf
https://github.com/monologg/KoBERT-Transformers
=> KoBERT로 선정 & 구현중
인공지능 학습 진짜 너무 어렵다...
오늘 멘토링때 얻은 피드백 -> accuracy >= 90!!! 적어도 90%는 넘어야 주관식 텍스트 입력이 의미있다.
