TIL
1.[TIL] 자바스크립트 문법 복습

04/12/23
2.[TIL] Leetcode 문제 풀이
04/13/23
3.[TIL] Node의 3가지 특징: Single Thread, Non-blocking I/O, and Event-driven
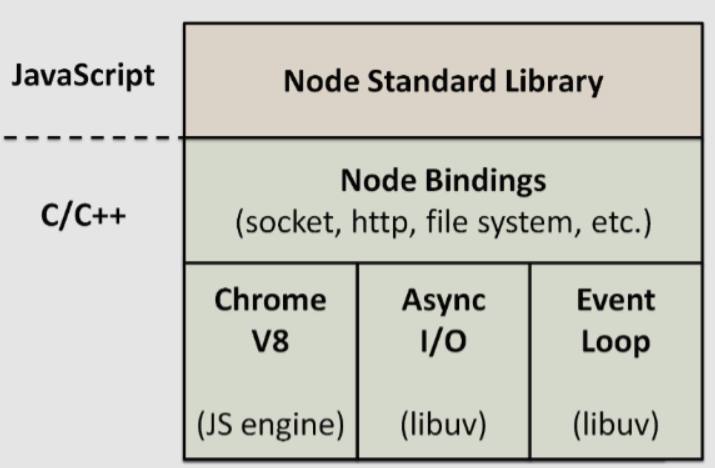
Node 주특기 주차를 시작하며 Node의 특징 3가지에 대한 정리를 해보면 좋을 것 같았다.
4.[TIL] Express Server 연습, 구조 분해 할당

Express 개념 강의 + 노트 정리, MongoDB 개념 강의 + 노트 정리, Express + MongoDB 실습
5.[TIL] Node HW 1
Node Express HW1
6.[TIL] Authentication, SPA_MALL 프로젝트 기능 추가
04.18.23 TIL
7.[TIL] 블로그 만들기 HW2
TIL 04.19.23
8.[TIL] Sequelize

TIL 04/20/23
9.[TIL] 게시판 좋아요 기능 구현, 비동기/동기 함수 처리
TIL 04.22.23
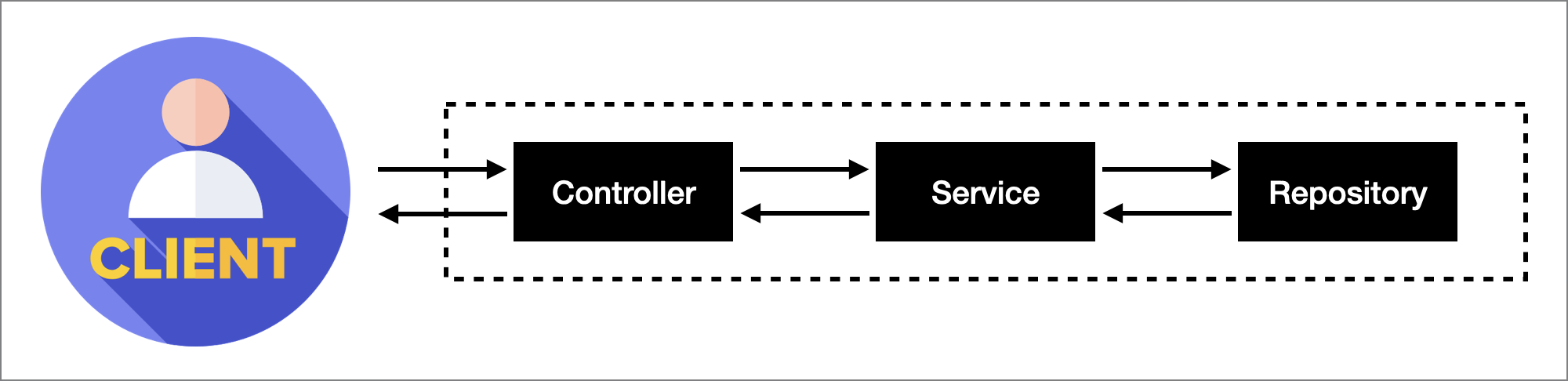
10.[TIL] OOP와 3-Layered Architecture
Transaction OOP in JS3-Layered Architecture와 할 거 왕많다! HW5 낼부터 시작...
11.[TIL] 주특기 HW 5
TIL 04.25.23
12.[TIL] HW5 Refactoring
TIL 04/26/23
13.[TIL] HW5 리팩토링-2
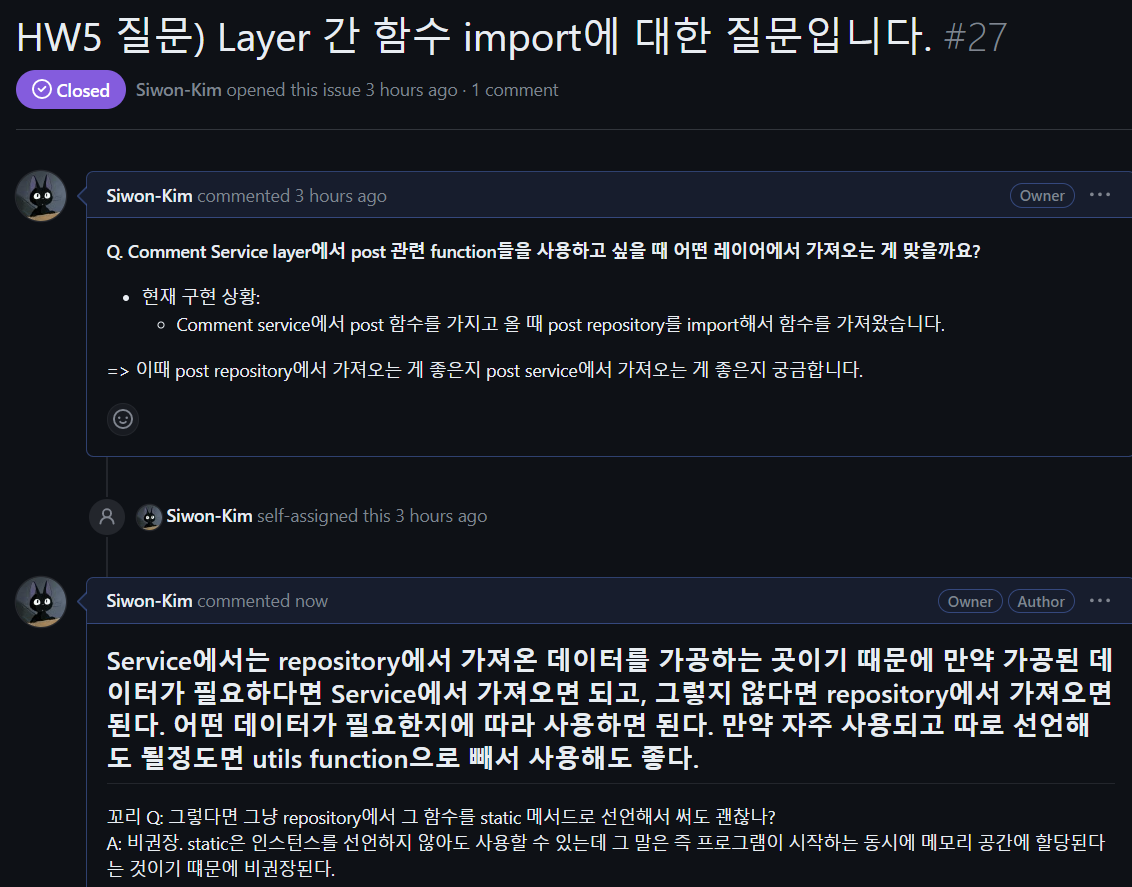
04/27/23
14.[TIL] jest와 supertest 모듈을 이용한 테스트 코드 구현하기
TIL 04-28-23
15.[TIL] DTO, FE&BE 협업
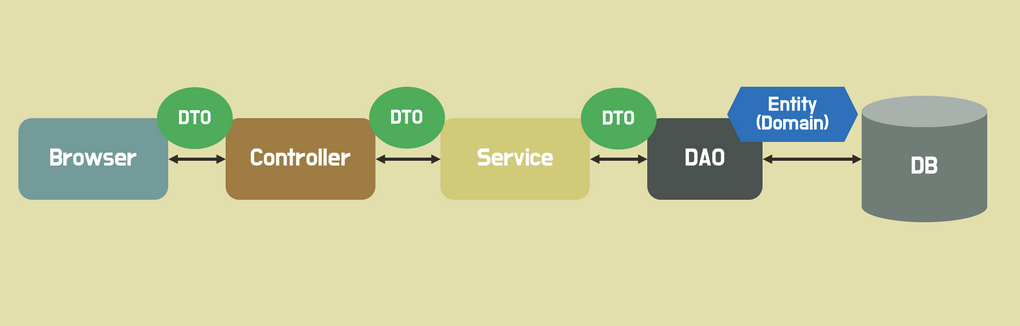
TIL 5/5
16.[TIL] worldcup 관련 API 만들기
TIL 5.6.23
17.[TIL] Worldcup APIs 리팩토링, jest 테스트
TIL 05/08/23
18.[TIL] Service Layer jest Test code, FE 연동시 403 에러
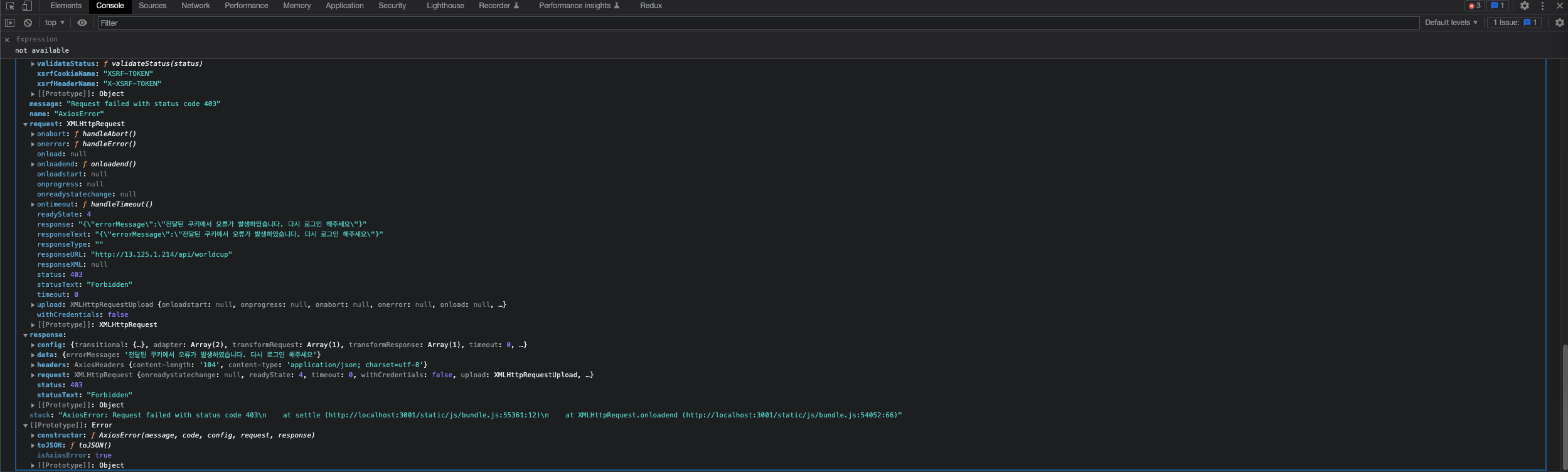
TIL 05/09/23
19.[TIL] supertest로 integration test하기
supertest로 로그인, auth-middleware 검증하기수정, 삭제 권한이 없는 error test case 만들기, 이슈 1과 2에 관련된 리팩토링
20.[TIL] 오늘 새롭게 배웠던 것
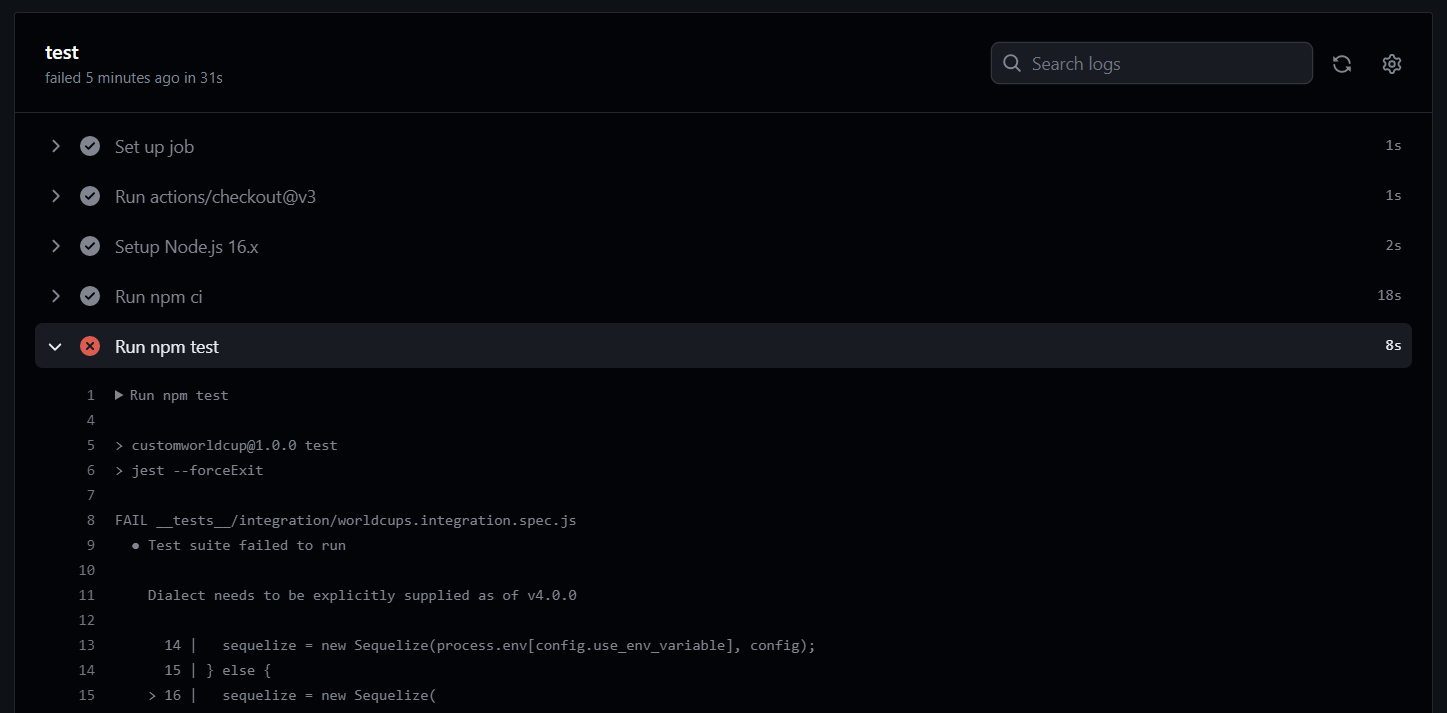
git stash: 변경 사항 임시 저장 git rebase: 한 브랜치의 커밋을 다른 브랜치로 옮기거나, 커밋을 순서를 변경하거나, 삭제하여 이력을 깔끔하게 만드는 작업. 보통 브랜치 간의 커밋 이력을 합치거나 정리할 때 사용. ec2에서 .env 파일 생성
21.[TIL] socket.io로 실시간 채팅 구현, API 설계
original repository의 main이 아닌 develop branch에 pull request 보내기 \* git flow 전략에서 우리가 필요한 branch인 develop과 feature 브랜치를 원본 repo에서 사용하기로 결정소켓을 통해 실시간으로
22.[TIL] APIs 1차 완료
배열을 type으로 가지는 (사실상 string화 되어서 저장됌) column에 여러개의 객체를 push해서 update하기CORS 에러반복문을 돌면서 repository의 saveChatContents 메서드를 실행시킨다.JSON_ARRAY_APPEND라는 seque
23.[TIL] FE&BE 간 Cookie 전달 이슈
백엔드 서버 배포 후, 프론트엔드 로컬 호스트에서 연결은 잘 되었으나, 쿠키 전달에서 오류가 났다. 로그인 진행을 하면 network 탭의 header -> set-cookie와 application 탭에 쿠키는 잘 저장이 되었지만, 인증을 필요로 하는 (auth-mi
24.[TIL] MySQL -> MongoDB
MySQL로 자신의 전체 채팅 내역을 조회할 때 쿼리 시간이 너무 오래걸린다. Postman으로 테스트시 2.xx초가 걸린다.MongoDB 추가 연결하기MySQL에서 Chats table과 join해아하는 table이 2개나 되고, 전체 채팅 내역을 조회하는 부분은 특
25.[TIL] 당근 마켓 토이 프로젝트 마무리
나는 이번 프로젝트에서 소켓 API와 소켓 백엔드를 구성했지만 중간에 채팅 프론트엔드를 맡은 분께서 하차하셔서 우선순위에서 밀려서 아쉬웠다.
26.[TIL] 동시성 제어
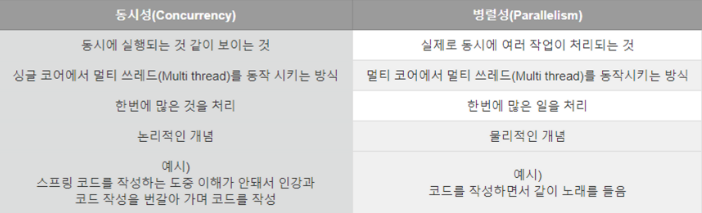
동시성은 싱글 코어에서 context switch를 통해 여러개의 스레드를 번갈아 가면서 실행하며 마치 동시에 동작하는 것처럼 보여주고, 병렬성은 물리적으로 여러개의 멀티코어에서 작업을 나눠서 동시에 처리한다는 차이가 있다.=> 동시성 처리를 통해 여러 스레드 (일꾼)
27.[TIL] Nest.js 공부 기록
router, 에러 핸들링, logging, validation, 데이터 형변환, 3-layered archiecture, auth-middleware에 대한 정답을 제시해주고 프레임워크에서 다 처리해준다.module화 => domain별로 module을 만들어서 co
28.[TIL] Nest.js Repository

Nest.js에서 repository를 의존성 주입하였지만 계속 repository에 정의된 함수가 정의되지 않았다는 에러 메세지가 떴다."EntityRepository is deprecated": typeORM 0.3.x에서 기존에 사용하였든 @EntityReposi
29.[TIL] Nest.js 프로젝트 초기 세팅과 CI/CD
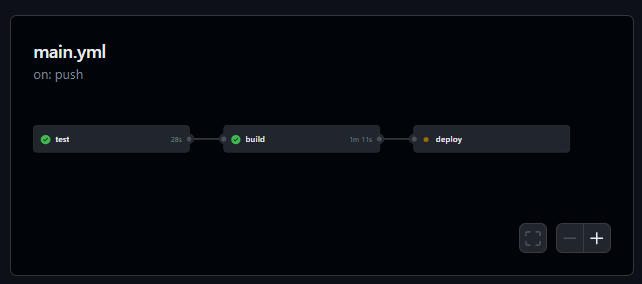
Nest.js 초기 세팅 다시 해보기https://velog.io/@c1madang/Nest.js-%EC%B4%88%EA%B8%B0-%ED%99%98%EA%B2%BD-%EC%84%B8%ED%8C%85더 고민해봐야할 부분: 환경 변수와 config 파일에 대해
30.[TIL] Troubleshooting: permission denied
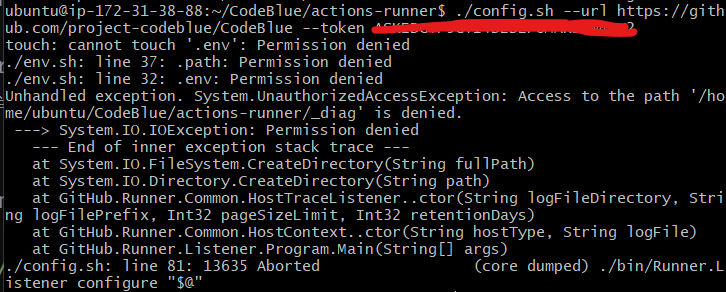
해당 config.sh 파일에 대한 쓰기 권한이 있는지 확인한다.ls -l 명령어 입력가장 왼쪽의 -rwxr-xr-x를 해석해보면, 파일 소유자는 읽기, 쓰기, 실행 권한을 가지고 있지만, 그룹 및 기타 사용자는 읽기, 실행 권한만을 가지고 있다는 것이다. 2\. su
31.[TIL] Unit Testing과 PATCH API

PATCH 요청에서 body 데이터 처리하기Unit testing에서 실제 의존성 주입 대신, mock 객체로 대체하기Transaction callback 함수 mocking하기비동기 함수를 mock할 때 mockResolvedValue()를 사용하였는데 해당 에러가
32.[TIL] Nest.js config와 ScheduleModule, 동시성 제어
npm i --save @nestjs/config cross-env joi를 설치해준다.ConfigModule에서 제공하는 ConfigService와 ConfigType을 통해서 환경 변수에 접근할 수 있다. ConfigType을 사용하면 ConfigSerivce보다
33.[TIL] Nest.js에 KakaoAPI 적용하기

좌표 -> 주소 변경 & 두 지점간 자동차로 이동 시간 구하기: KakaoMap API 적용하기REST API 키를 환경변수에 저장한다.Kakao Map API 관련 메서드들을 정의할 파일을 만들어준다. 메서드들을 사용할 폴더의 module > providers에 Ka
34.[TIL] 지리 공간 좌표 인덱싱, 카카오 API 호출 속도 개선
사용자의 현재 위치 기반 최단 거리 병원 조회 API에서 병원 데이터가 500개가 넘었고, 모든 병원에 대해 haversine으로 거리를 계산하는 부분을 개선하고 싶었다.카카오 모빌리티 API 호출 시간이 너무 오래 걸려, 네트워크 IO에 대한 성능 개선이 필요하다.그
35.[TIL] 코드 리뷰 & API 최종 수정 사항
팀원들과 코드 리뷰환자 이송 신청 API 수정 → 병원 id 설정 추가증상 보고서 환자 정보 수정 PATCH API => update DTO 정의 병원 조회 API 반경 몇 km & max_count 쿼리 파람으로 넘기기 (spatial index & ST_Distan
36.[TIL] Nest.js e2e Test
Nest.js에서 e2e test - test용 db 연결Nest.js에서 e2e test를 위해 테스트용 DB를 연결하는 과정에서 시간이 좀 걸렸다. 사소한 에러였는데, 다른 모듈들을 import할 때 자동 import extension을 설치해서 어떤 모듈들이 im
37.[TIL] custom pipe
Issue #1 주민번호 데이터가 들어오면 pipe로 바로 성별 판별해서 db에 전달하기 📌 What I tried Issue #1 DTO에서 주민번호를 가지고 성별을 판단해서 지정해주기 위해 transform을 사용해보았다. 근데 잘 안됐다. 알고보니 trans
38.[TIL] testing 완료
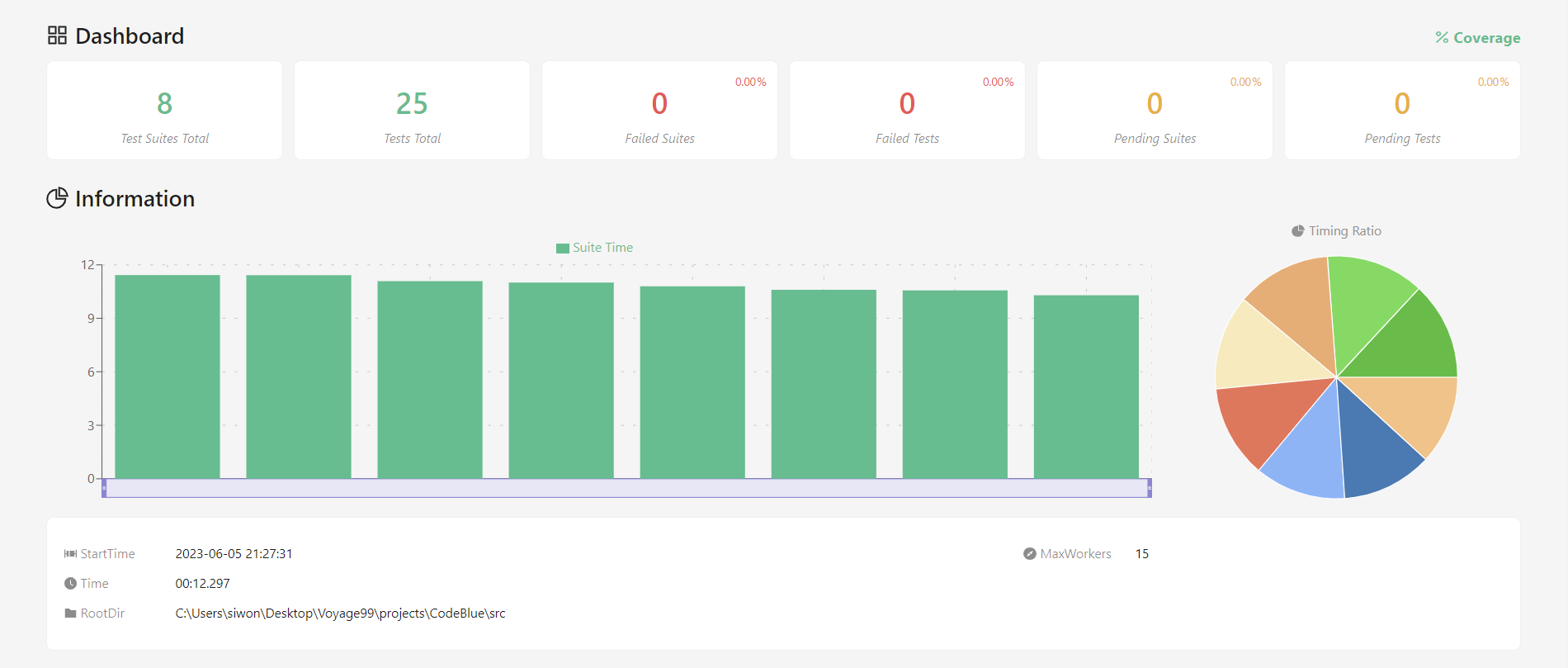
controller & service layer unit test 완료coverage E2E test 완료1차 MVP에 대한 테스팅을 완료하였다. 내가 맡은 API에 대한 단위테스트를 진행해보면서 단위테스트의 의미를 더 확실하게 가져갈 수 있었다. 이번 프
39.[TIL] 동시성 제어 본격 시작
Artillery 사용에 익숙해지는 시간을 가졌다. 간단하게 동시성 제어가 필요한 API에 대해 테스트를 진행하였다.transaction도 추가하지 않은 API에 대해 동시 접속자 30명을 넣으니 결과가 처참했다. 5명까지만 환자 이송 신청이 들어가야하는데 2명 빼고
40.[TIL] BullQueue 동시성 제어
아래와 같은 방식으로 하면 로컬에서 레디스를 사용할 수 있는데 테스트용으로 일단 로컬에서 레디스 연결을 하였고, 이후 배포 인스턴스에서 사용할때는 docker-compose.yml 파일을 정의해서 설정을 해주어야 한다.아래 블로그에서 Nest.js에서 BullQueue
41.[TIL] Redis Caching
=> 위치 기반 추천 병원을 조회하는 API를 호출할때 매번 카카오 모빌리티 API 호출과 실시간 병상 데이터 웹 크롤링을 진행하여, 이를 개선하고자 캐싱을 사용하였다.아무래도 주제가 주제이니만큼 환자의 실시간 위치를 반영한 병원 조회 결과의 정확도가 너무 떨어질 수는
42.[TIL] 인공지능 모델 BERT

BERT는 기본적으로 이미 존재하는 모델을 가져다가 우리의 입맛에 맞게 fine-tuning을 하는 방식으로 모델 학습을 한다. Fine-tuning은 pretrained된 모델을 다운스트림 테스크에 맞게 업데이트하는 기법이다. 이렇게 도메인 특화 데이터로 학습한 모델
43.[TIL] 문장 학습 모델을 위한 데이터셋 생성 자동화
머신 러닝 모델에 문장과 해당 문장의 label을 학습시켜야 했고, 이때 필요한 dataset은 최소 1000여개가 필요했다. RNN 모델은 이미 세팅을 완료하였고, 충분한 학습용 dataset만 구축되면 학습을 진행하고 문장으로 입력된 input에 대해 중증도 레벨을
44.[TIL] 문장 학습 인공지능 문제 직면 & 해결 방향
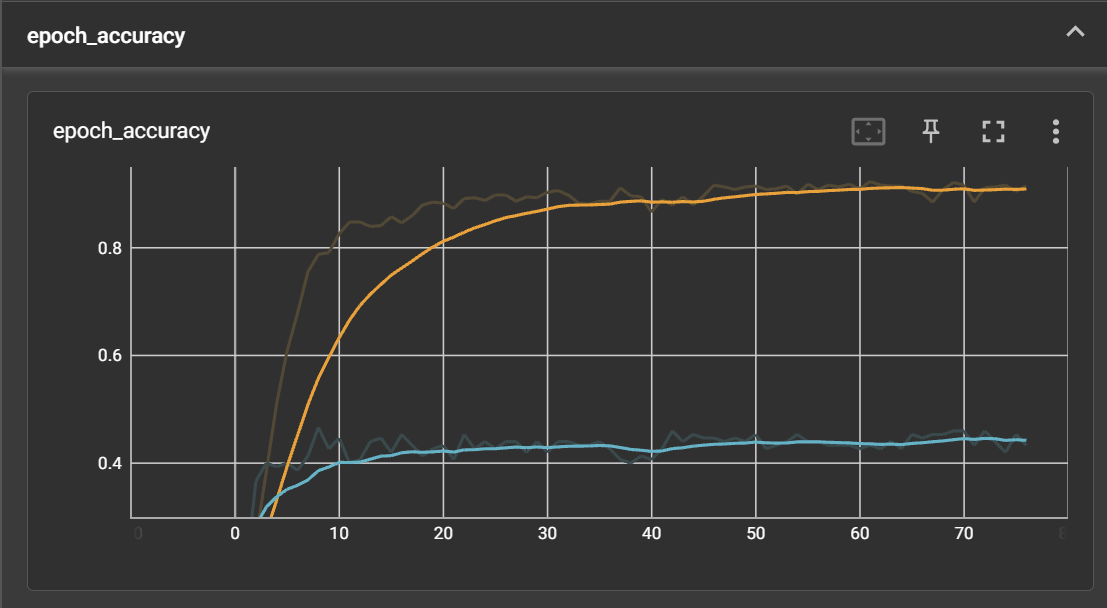
모델 학습에서 중요한 것이 결과로 나온 accuracy와 각 epoch을 수행하면서 변동되는 accuracy의 추이이다. 결과는 훈련이 완료되면 print가 되도록 설정해놓고 terminal에서 파악하기 용이했지만, 그 추이는 시각화 그래프가 없으면 한계가 있어서 Te
45.[TIL] 계속되는 RNN 모델 문장학습
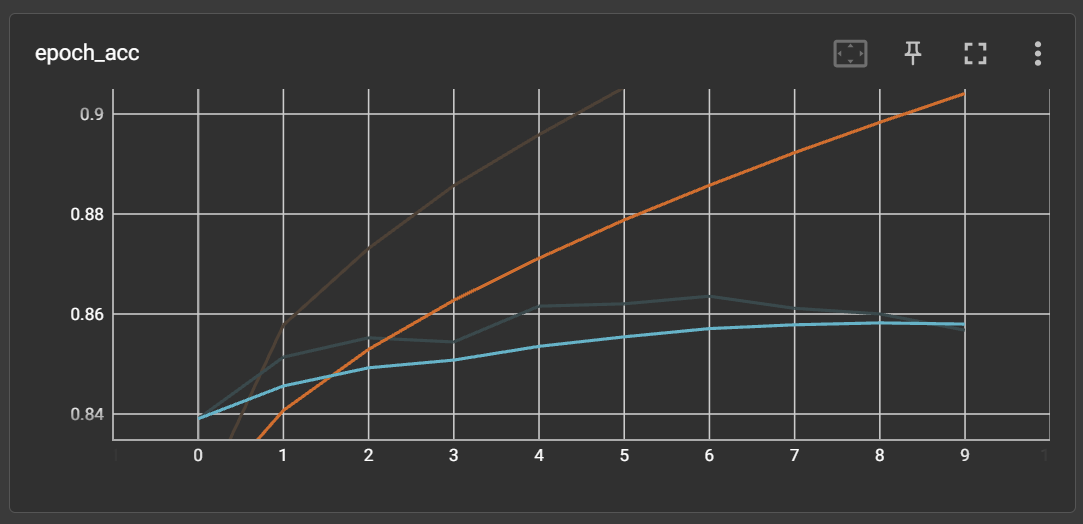
=> 네이버 영화리뷰 데이터셋 (NMRS)으로 감정 분석에 대한 binary label 모델 테스트를 진행하였다.⇒ 정확도가 0.86이 나왔고, 리뷰에 대한 긍정, 부정 판단도 잘 진행하였다. RNN 모델 자체의 문제는 역시나 없다. 그냥 검증이 필요했다. 왜냐면 이걸
46.[TIL] RNN 모델 정확도 높이기
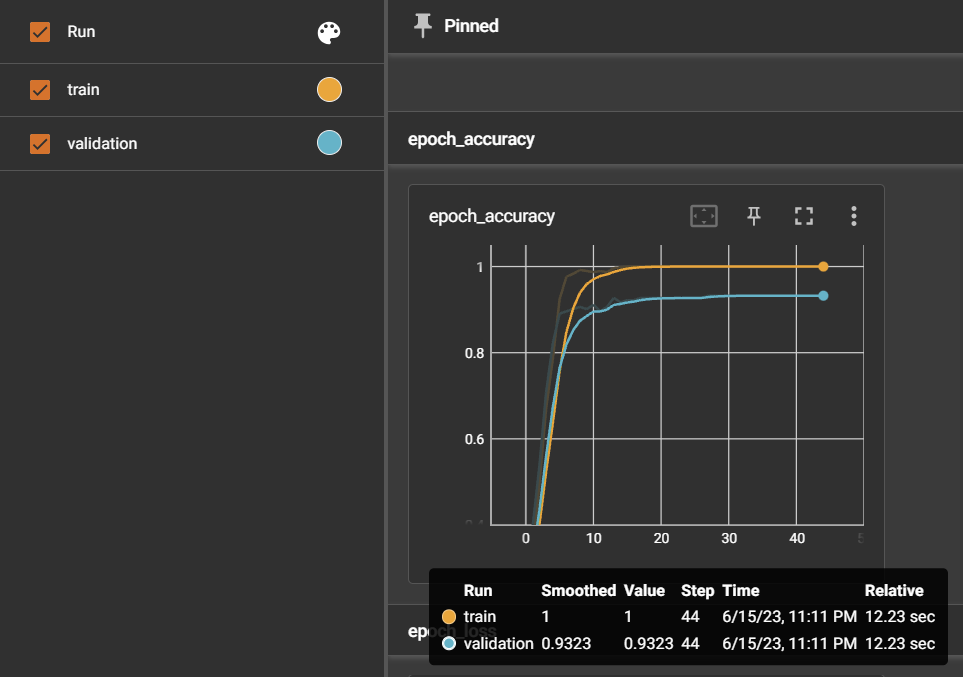
정규화된 데이터셋을 만드니 정확도가 확 높아진걸 알게되었고, 추가적으로 누적학습을 진행해보았다. 4가지 케이스를 실험해보았다.누적학습 ❌: 데이터셋 900여개누적학습 🔺: 초기모델 - 데이터셋 900여개 + 누적모델 - 새로운 데이터셋 800여개누적학습 ❌: 데이터셋
47.[TIL] 문장학습 인공지능 모델 보고서 작성 + ejs로 프론트엔드 페이지
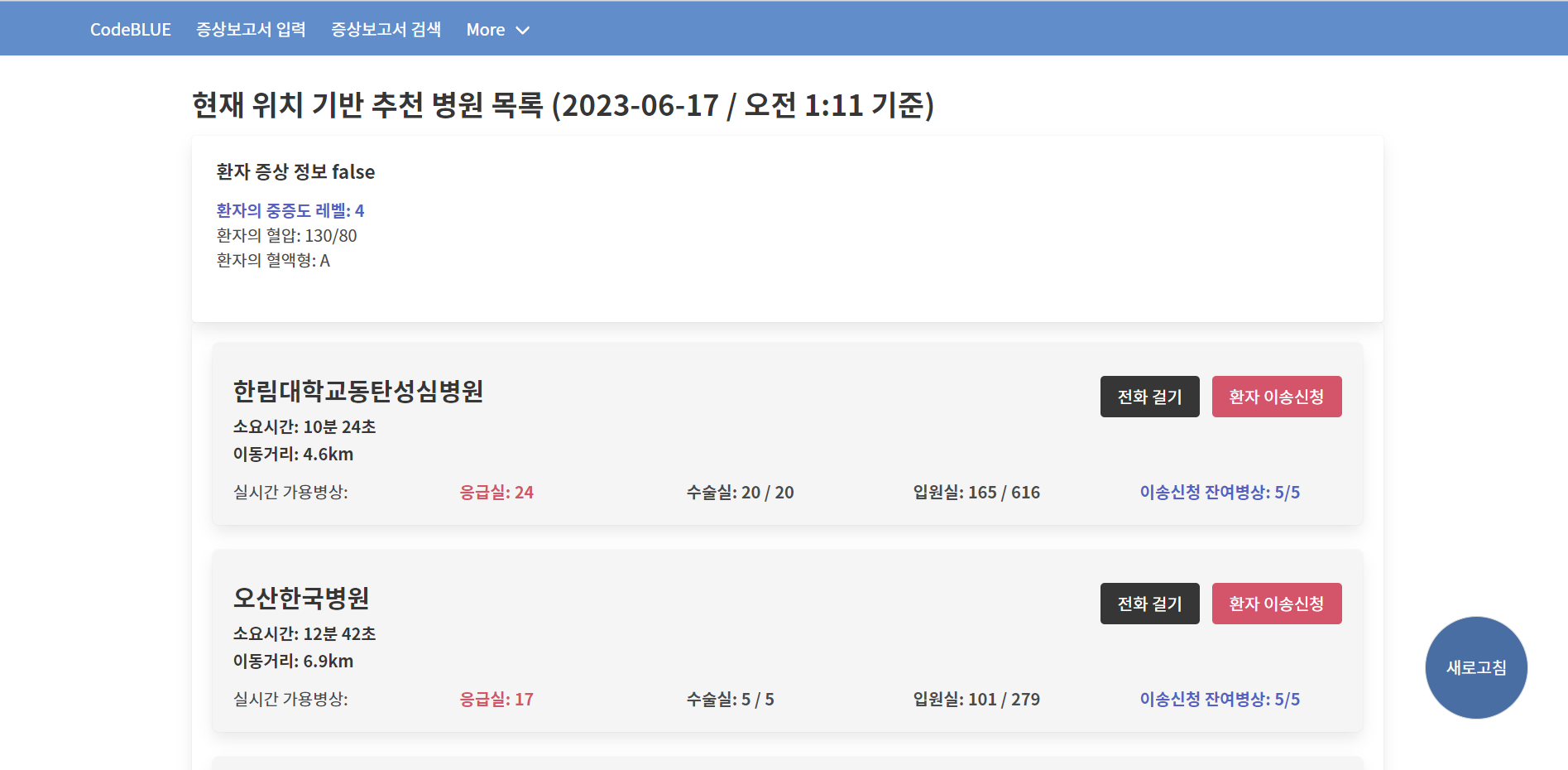
문장학습 인공지능 모델 보고서거리 기반 추천 병원 조회 페이지증상 보고서 검색 페이지증상 보고서 검색 결과 페이지프론트엔드 하루만에 끝냈다! 잘 묵혀놨다가 추가 업데이트에 들어가야겠다.
48.[TIL] 인공지능 모델 Nest 프로젝트에 연동 시도
Node.js 환경에서 .h5 형식의 모델과 .pkl 형식의 토크나이저를 사용할 수 없어, 이를 .json 형식으로 변환하는 과정이 필요위 코드가 .h5 형식의 모델을 tensorflow.js가 인식할 수 있는 .json 파일로 변환하는 코드이다. 이 짧은 코드를 실행
49.[TIL] 인공지능 Flask API 프로젝트 EC2 배포 & 프로젝트 연결
추가로 EC2 인스턴스에 실행한 명령어 / 설치해준 모듈sudo apt updatesudo apt install python3-pipsudo apt-get install python3-venvsudo apt-get install default-jdk ⇒ konlpy를
50.[TIL] 캐시 처리 & 무효화 (interceptor)
❓ 기존 코드에서는 service layer에서 캐싱된 데이터가 있는지 확인하고, 있으면 해당 캐싱 데이터를 return해주고 없으면 비지니스 로직 수행 후 해당 return값을 캐싱해주었다. 그러나, 이는 service layer에서 캐시를 처리하는 부분이 처리하는