동시성
동시성 vs. 병렬성
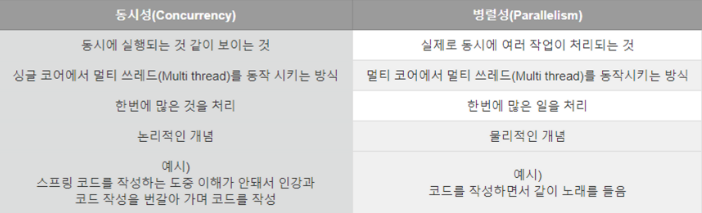
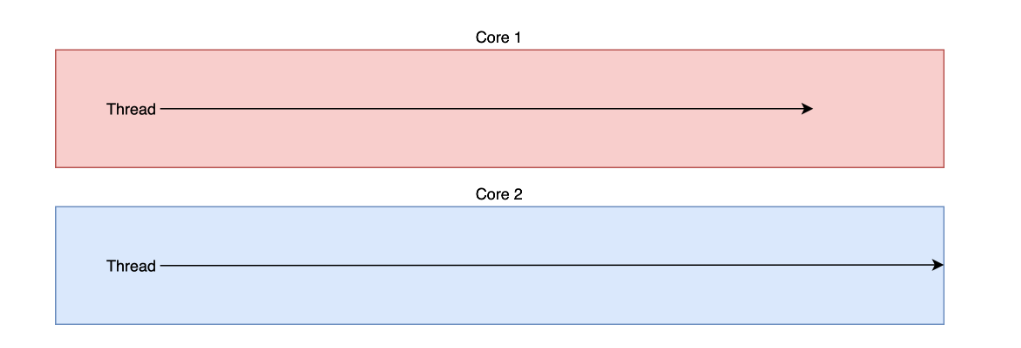
동시성은 싱글 코어에서 context switch를 통해 여러개의 스레드를 번갈아 가면서 실행하며 마치 동시에 동작하는 것처럼 보여주고, 병렬성은 물리적으로 여러개의 멀티코어에서 작업을 나눠서 동시에 처리한다는 차이가 있다.
동시성: 여러 개의 작업들을 동시에 처리하는 것"처럼" 보이게 하는 것
병렬성: 여러 작업을 들 "실제로" 동시에 처리하는 것

- 참고
- 멀티테스킹: 동시성이랑 헷갈리는 개념. 하나의 시스템에서 여러 개의 작업 (task)을 동시에 실행하는 것. 각각의 작업은 독립적이다 (테스크: YouTube 켜놓기, kakaotalk desktop app 업데이트, vscode 켜놓기 등등) => 프로세스의 동작
- 동시성: 하나의 작업 내에서 여러 개의 서브 테스크 (subtask)를 동시에 처리하는 것. 여러 개의 스레드를 생성하여 하나의 작업을 분할하여 처리하거나, 비동기적으로 여러 개의 작업을 처리하는 것을 의미. 각각의 subtask들은 의존성을 가진다. (테스크: YouTube 영상 시청, 서브테스크: 동영상 로딩, 추천, 제어, 재생 등등) => 스레드의 동작
=> 동시성 처리를 통해 여러 스레드 (일꾼)가 동시에 실행되는 것처럼 보이게 할 수 있음
동시성 제어가 필요한 이유
여러 스레드가 동시에 실행되면 공유된 자원에 대한 접근 (진단서 1개에 대한 POST 요청)이 동시에 발생할 수 있으므로, 예상치 못한 결과가 나타나거나 데이터 일관성이 깨지는 상황이 발생 (동기화 문제)
=> 적절한 동기화 기법과 동시성 제어 방법 필요
근데, JS는 싱글스레드잖아?
- JS는 싱글스레드 = JS 엔진이 단일 스레드에서 코드를 실행하고, 하나의 작업을 순차적으로 처리한다
- JS에서 동시성 제어가 필요한 이유는?
- 동시성 제어가 필요한 상황들
1. 비동기 작업: JavaScript는 비동기 작업을 처리하는 데 강점을 가지고 있습니다. 예를 들어, 네트워크 요청, 파일 I/O, 데이터베이스 쿼리 등의 작업은 블로킹하지 않고 비동기적으로 처리됩니다. 동시성 처리를 통해 이러한 비동기 작업을 효율적으로 관리하고 병렬로 실행할 수 있습니다.
2. 이벤트 처리: JavaScript는 이벤트 기반의 프로그래밍 모델을 가지고 있습니다. 웹 브라우저에서 발생하는 이벤트(클릭, 키보드 입력 등)를 처리하거나 서버 측에서 발생하는 이벤트(요청, 응답 등)를 처리해야 할 때, 동시성 처리를 통해 이벤트들을 동시에 관리하고 응답성을 높일 수 있습니다.
3. 병렬 처리: JavaScript 환경에서 병렬 처리가 필요한 경우가 있습니다. 예를 들어, 대량의 데이터를 동시에 처리해야 할 때, 동시성 처리를 통해 작업을 병렬로 실행하여 처리 속도를 향상시킬 수 있습니다.
4. 다중 스레드 환경과 상호 운용성: JavaScript는 싱글 스레드 기반의 언어이지만, 웹 워커(Web Worker)와 같은 기술을 통해 다중 스레드 환경을 모방할 수 있습니다. 동시성 처리를 통해 다중 스레드 환경에서 작업을 분산하고 상호 운용성을 제공할 수 있습니다.
- web worker란?
- 멀티스레드 처리 지원 => 순서 없이 빠르게 처리
- JS 코드를 백그라운드 스레드에서 실행할 수 있도록 해주며, 메인 스레드와는 별개로 동작하여 병렬로 작업을 처리할 수 있음
- 30만건의 진단서 전송 요청이 있으면, 이를 작은 단위로 분할하여 각 웹 워커에게 작업을 할당
- 각 웹 워커는 할당된 작업을 실제 병렬로 처리하여 동시에 처리할 수 있음
=> 결론: JS는 싱글 스레드 기반 언어이지만 비동기 작업 처리와 이벤트 기반 환경에서의 동시성 처리를 위해 동시성 제어가 필요하다
JS에서 동시성 제어를 하는 법
-
Locking: 하나의 스레드만이 공유 자원에 접근할 수 있도록 제어 => 여러 개의 작업을 순차적으로 처리 => 데이터 무결성
- 뮤텍스 락 (Mutex Lock): 뮤텍스 락은 상호배제(mutual exclusion)를 구현하는 가장 기본적인 락 기법. 오직 하나의 스레드만이 락을 소유하고, 다른 스레드는 해당 락을 얻을 때까지 대기.
- 세마포어 (Semaphore): 세마포어는 뮤텍스 락의 확장으로, 동시에 접근 가능한 리소스의 개수를 제한하는 락 기법. 세마포어는 허용된 리소스 개수를 나타내는 카운터를 가지고 있으며, 이를 통해 여러 스레드가 동시에 접근할 수 있는 리소스의 개수를 제어.
- 리더-라이터 락 (Reader-Writer Lock): 리더-라이터 락은 동시 읽기와 배타적 쓰기를 지원하는 락 기법. 여러 스레드가 동시에 읽기 작업을 수행할 수 있지만, 쓰기 작업은 배타적으로 수행.
- CAS (Compare-and-Swap): CAS는 원자적 연산을 통해 동시성을 제어하는 락 기법. 이는 변수의 현재 값과 기대하는 값을 비교하여 같을 경우에만 새로운 값을 설정하는 방식으로 동작. CAS는 원자적인 연산을 지원하는 하드웨어의 지원이 필요.
-
Apache Kafka: 실시간 대량 데이터 처리, 분산 스트리밍 플랫폼 (microservice)
- 방대한 양의 데이터를 비동기로 처리할 수 있다.
- kafka 자체가 여러 컨슈머 그룹을 통해 메세지를 병렬로 처리하고 동시성을 제어하는 기능을 가지고, 내부적으로 파티셔닝과 복제를 통해 데이터를 분산하고 처리하므로 별도의 locking나 web worker 메커니즘이 필요하지 않다.
- kafka를 통해 메세지 큐를 통해 동시성을 제어하고 원하는 스케일링과 처리 방식을 조정하여 대규모 트래픽을 처리할 수 있다.
- 데이터를 생성하는 프로듀서(Producer)가 Kafka에 메시지를 전송하고, 메시지를 소비하는 컨슈머(Consumer)가 해당 메시지를 읽음. Kafka는 데이터를 토픽(Topic)이라는 단위로 구분하며, 각 토픽은 여러 파티션(Partition)으로 나누어짐. 이렇게 나뉜 파티션은 여러 컨슈머 그룹(Consumer Group)에서 병렬로 처리될 수 있어 확장성과 성능을 보장.
- Kafka는 데이터 유실을 최소화하기 위해 내구성과 복제 기능을 제공. 데이터는 디스크에 영속적으로 저장되므로 안정적인 데이터 보관이 가능하며, 복제를 통해 고가용성과 내결함성을 보장. 또한 Kafka는 실시간 데이터 스트림 처리를 지원하여 실시간 분석, 로그 처리, 이벤트 소싱 등 다양한 분야에서 사용.
- Kafka는 많은 기업에서 대규모 데이터 처리와 실시간 스트리밍에 활용되는 인기 있는 플랫폼으로 알려져 있으며, 데이터 파이프라인 구축이나 대용량 데이터 처리에 유용하게 사용됌
-> 결론: kafka로 병렬 처리 (속도 증가) + 데이터 무결성을 모두 보장할 수 있다 (나름 열심히 찾아봤는데... 아직 많이 부족)
