본 내용은 인하대학교 정보통신공학과 홍성은 교수님의 인공지능응용 강의내용을 기반으로 작성한 내용입니다.
Case Studies
- AlexNet
- VGG
- GoogLeNet
- ResNet
AlexNet
- Krizhevsky et al. 2012
- ImageNet Large Scale Visual Recognition Chellenge에서 CNN-based 모델로 우승한 첫 모델
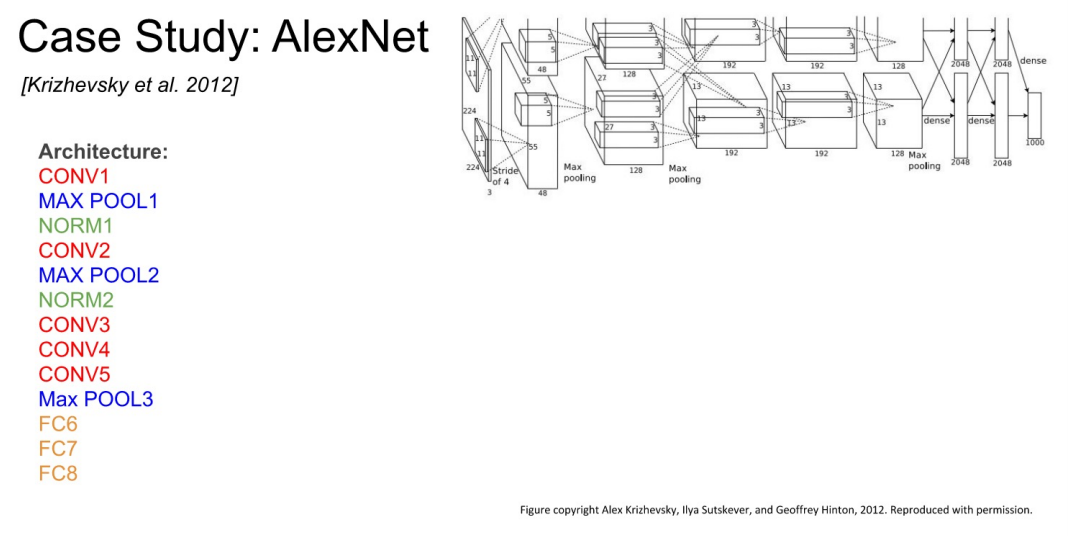
- 구조는 조금 복잡한 느낌.
First Layer
- (CONV1) : 96 11x11 filter(stride 4)
- (227 + 2x0 - 11) / 4 + 1 = 55
- Output Volume : 55x55x96
- Parameters : (11x11x3 + 1) x 96 = 363x96 + (96) = 35K + 96 (96은 bias)
Second Layer
- (Max Pool1) : 3x3 filter(stride 2)
- (55 + 2x0 - 3) / 2 + 1 = 27
- Output Volume : 27x27x96
- Parameters : 0 (Pooling은 Parameters가 0)
ZFNet
- AlexNet에서 Hyperparameter만 변경한 모델
- CONV1을 11x11(stride 4) → 7x7(stride 2)
- CONV 3,4,5를 384, 384, 256 filter → 512, 1024, 512
- error : 16.4% → 11.7%
VGGNet
- 14년도 ILSVRC에서 2nd in classificaiton, 1st in localization
- AlexNet과 비슷한 학습 절차
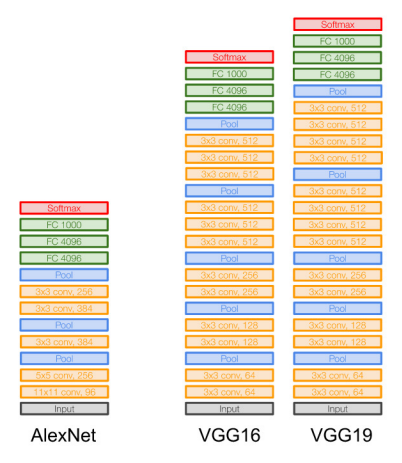
- 8 layers(AlexNet) → 16-19 layers
- error : 11.7%(ZFNet) → 7.3%
All Layer
-
CONV : 3x3 filter(stride 1, pad 1)
-
MAX POOL : 2x2 filter(stride 2)
-
모든 Layer가 같은 구조인 것이 매우 깔끔하다.
-
왜 이렇게 작은 filter(3x3)을 사용할까?
3개의 3x3 CONV의 Stack = 1개의 7x7 CONV의 Stack
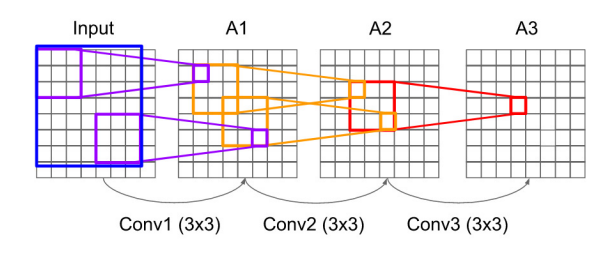
-
3개의 3x3 CONV를 거친 상황이다.
-
A3의 저 한 칸은 Input의 파란색 field(7x7)의 정보가 담겨있음을 알 수 있다.
-
즉, 효과적으로 반영된 field를 가지게 하는데,
-
더 깊고(3 layers vs 1 layer) → 비선형적
-
paramter 수가 적어진다. (3 * (3^C^) vs 7^C^)
-
C : Channel per layer

- 계산된 memory 크기와 parameter 수
- 총 paramters 수 : 137 Million
- 병목이 발생하는 부분을 파악하고 해결하는 것이 문제.
GoogLeNet
- 14년도 ILSVRC에서 classificaiton 우승
- 22Layers, Only 5 million params(VGG-16보다 27배 낮음)
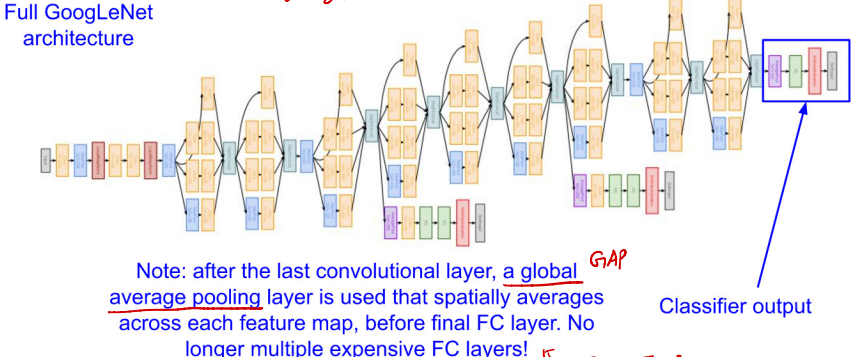
- Inception Module이 반복되는 구조
- 마지막 CONV 이후에 GAP(Global Average Pooling)을 통해 각 feature map의 특성을 포함하면서 차원수를 확 줄여준다.
- 이를 통해 FC Layer에서 계산을 간소화 한다.
- Network 구조가 매우 복잡하다.
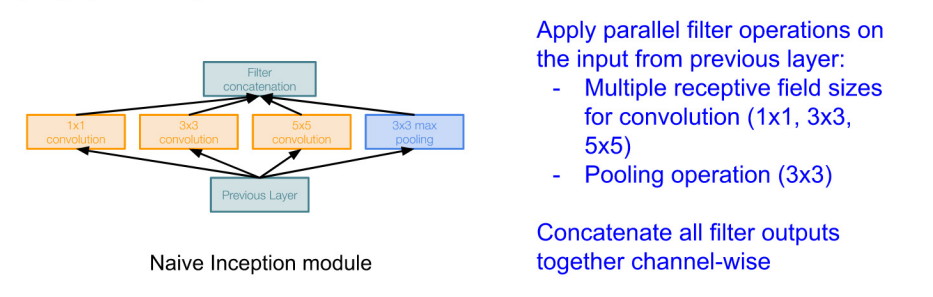
- 병렬적으로 filter를 사용한다. + MaxPool(3x3)
- 1x1 CONV : Channel Size만 바뀐다.
- 다른 CONV도 Channel Size만 변경되게 다른 hyperparameter를 조정한다.
Incetption Module
- 기존 Incetption Module
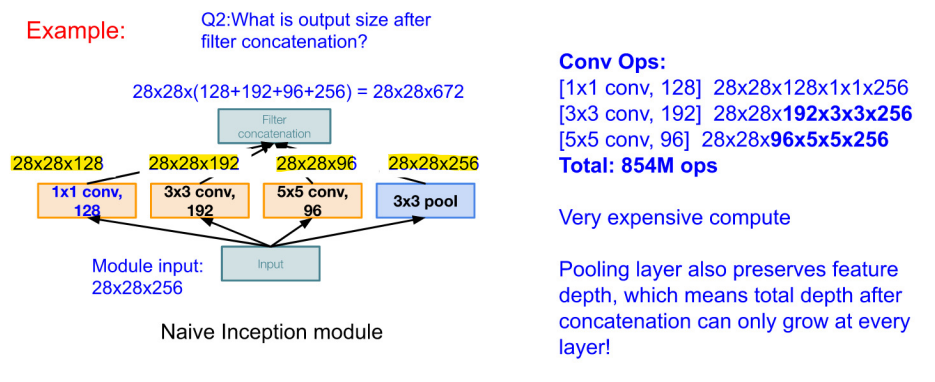
- 각 fileter에서 사용되는 operator 개수는 다음과 같다.
- filter를 거치고 난 뒤의 output size는 28x28x672(뒤로 이어서 붙는 형태)
- 이는 컴퓨팅 자원이 과도하게 발생 (단점)
- 병목 해결한 Inception Module
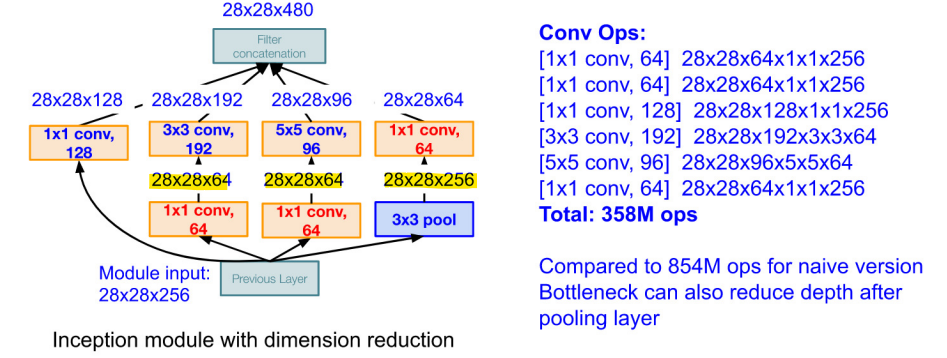
- 1x1 CONV를 사용한 channel size를 감소를 통해 병목 현상을 해결하였고, Inception Modele을 붙여주었다.
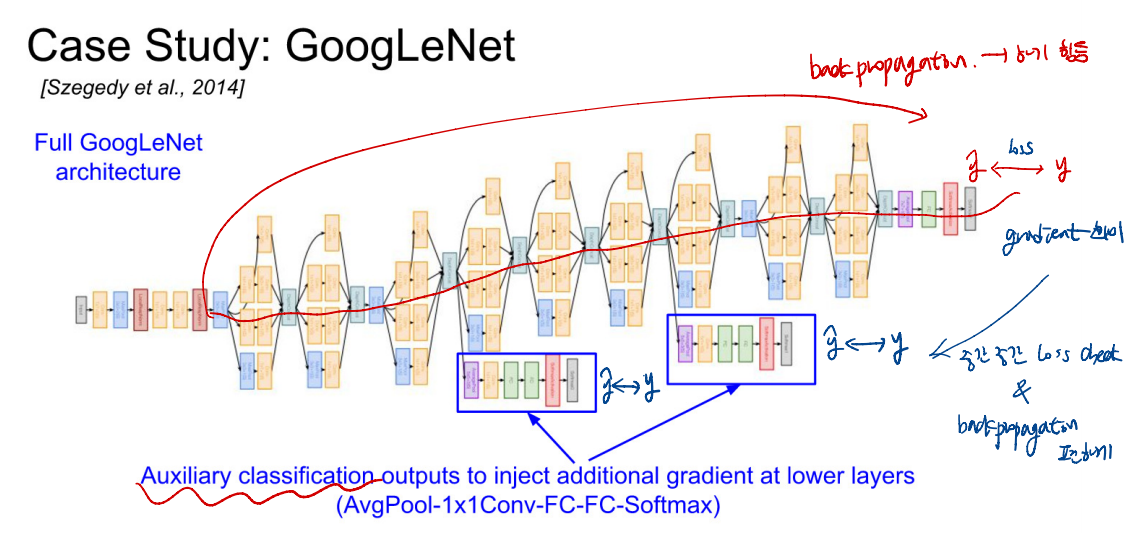
- 모델의 구조가 매우 복잡하므로, Loss를 줄이기 위해 parameter를 변경하는 back-propagation이 힘들다.
- 이를 파악하고, propagation 중간 중간에 Loss를 확인하여 back propagation을 좀 더 쉽게 할 수 있게 한다.
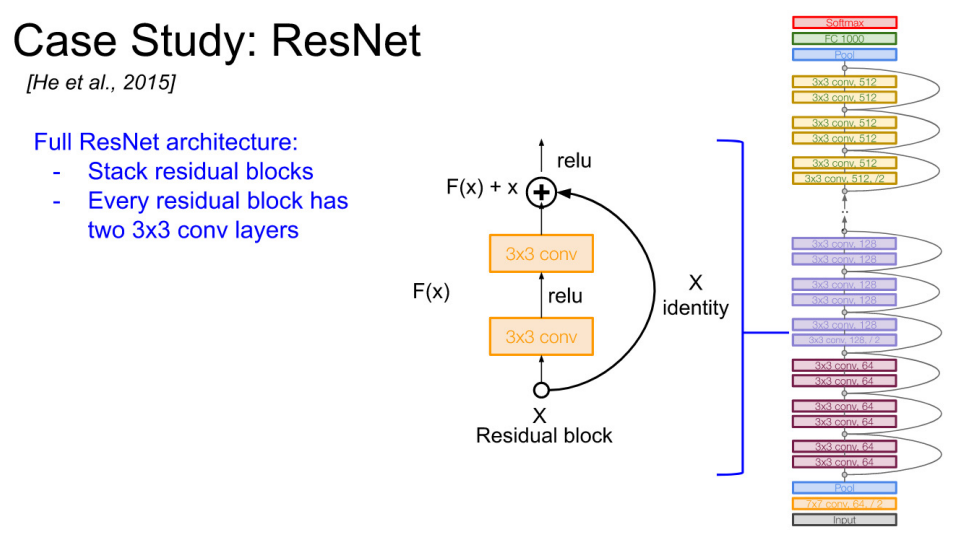
ResNet
- 15년 ILSVRC에서 우승 (3.57%)
- 무려 152 Layers Model
- 단순 CNN을 여러 겹 쌓게 된다면?
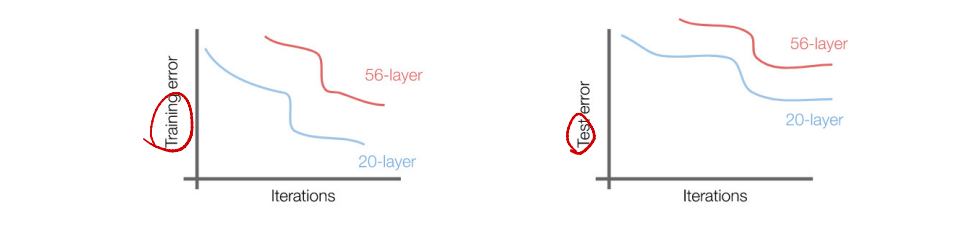
- 더 깊은 모델은 Train과 Test에서 나쁜 성능을 보인다.
- 하지만 이는 overfitting 때문이 아니다!
- 더 깊은 모델은 더 많은 representation(표현력), 더 많은 parameters를 가지고 있다.
- overfitting이 되는 이유는 optimization 때문인데, 깊은 모델에 더욱 강한 optimize를 한다면? overfitting 없이 성능을 극대화 할 수 있지 않을까?
- 구조적인 해결책 : 얕은 모델에서 학습된 레이어를 복사 + ID mapping에 대한 추가 레이어를 설정
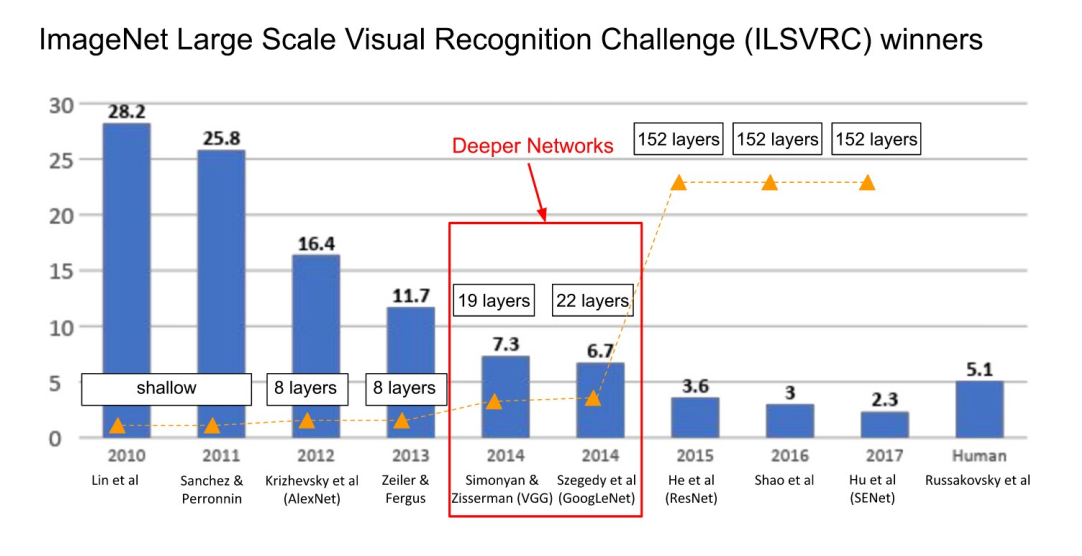
COMPLETED ILSVRC
- 2015 ResNet 이후로, ResNet의 변형 모델들이 우승을 한다.
- error율 3.6%를 달성한 이후로 큰 의미가 없어졌다. Why? Human이 5.1%라서 그 이하로 더 error가 작아지는 것은 큰 의미가 없기 때문에.
